Mac M3 Utral 512G 跑AI
-
王思聪说:我喝豆浆就是喝一碗,倒一碗。

所以以下全是一个屌丝 帮 土豪在Mac M3 Utral 512G 上跑 AI。- ds4+ deepseek V4 flash
框架ds4:https://github.com/antirez/ds4.git
deepseek V4 qt2, 本来可以直接用qt4(但我小家子气,怕效果不好)
启动参数:./ds4-server
--ctx 131072
--kv-disk-dir /tmp/ds4-kv
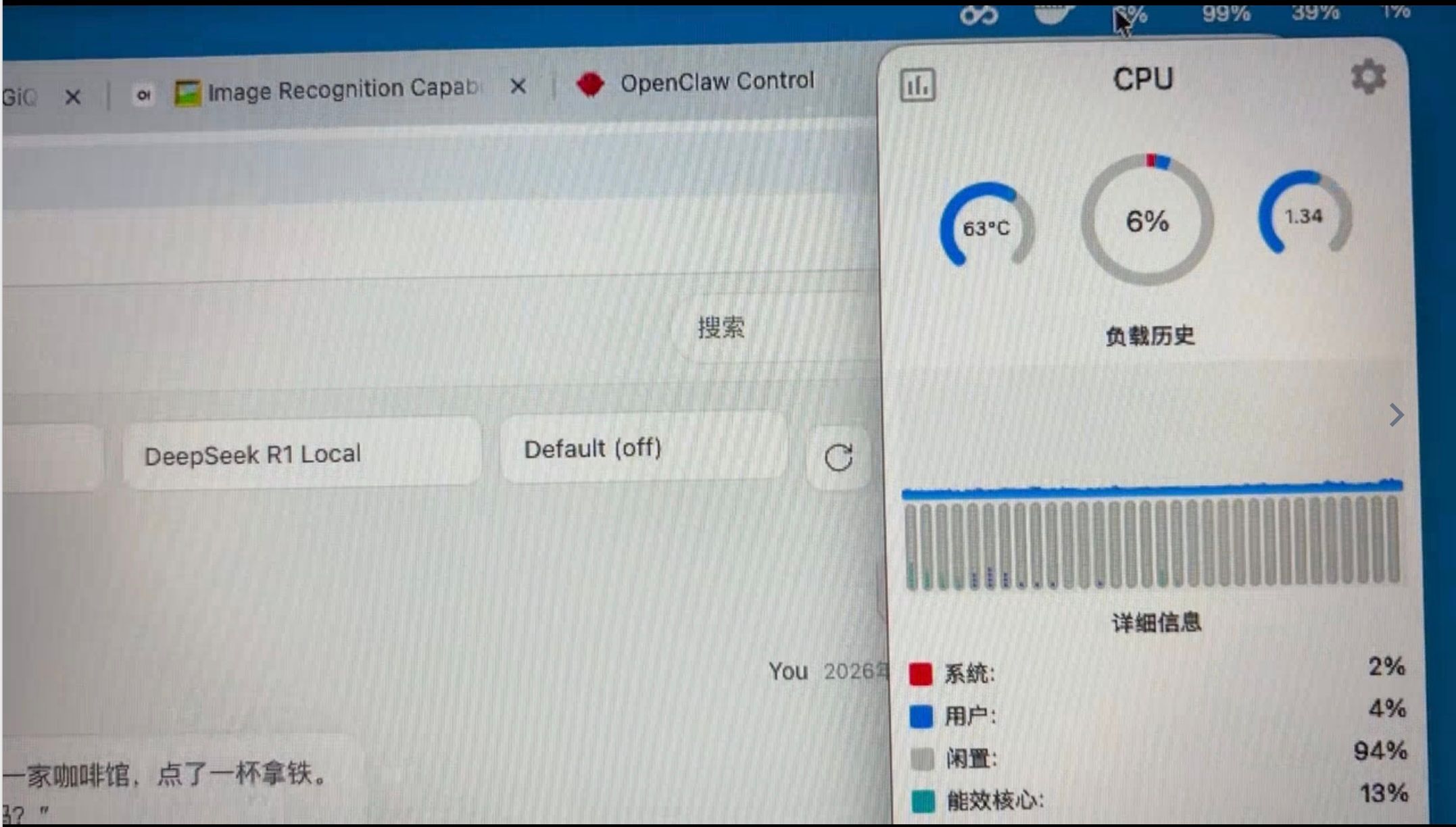
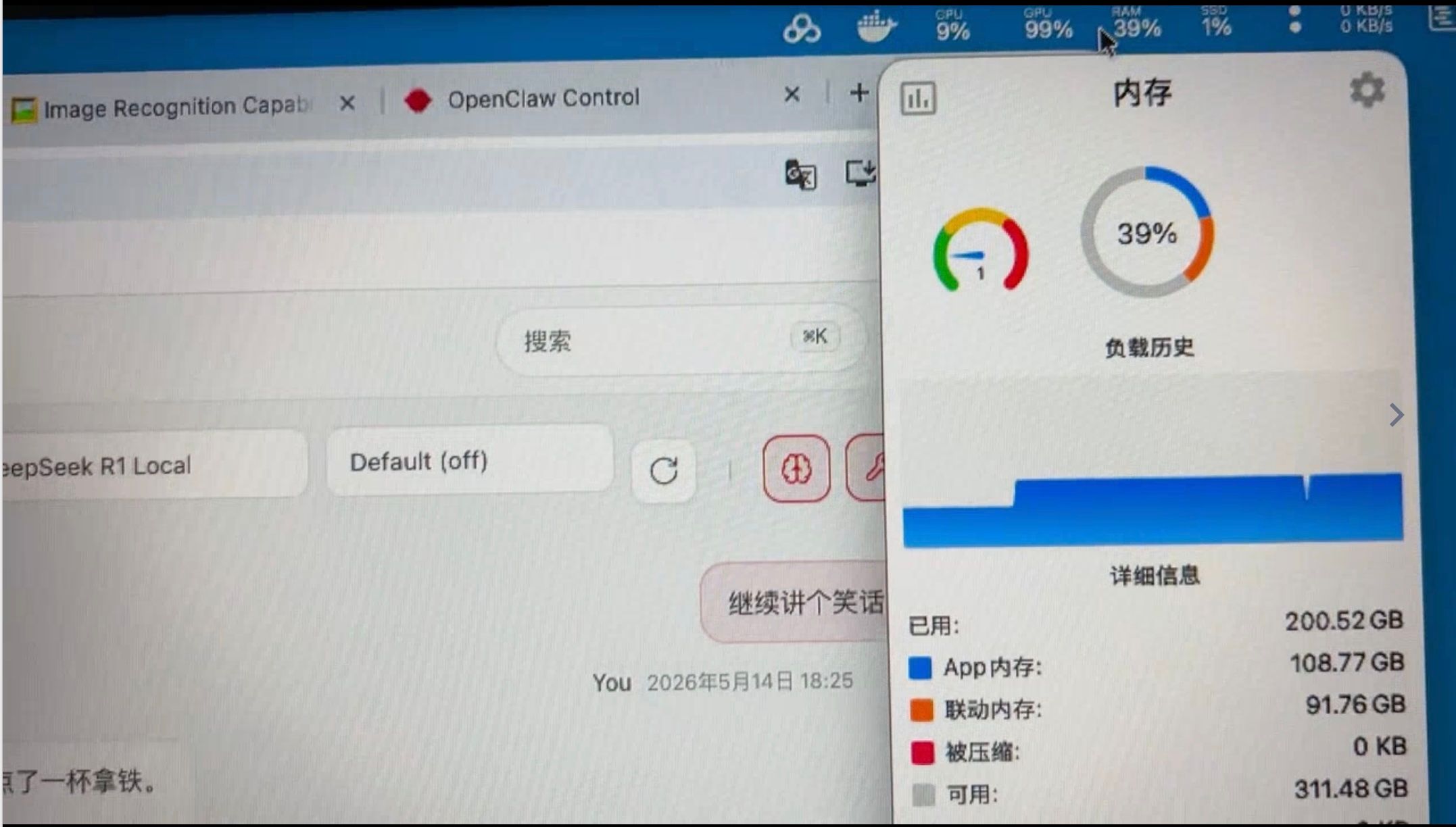
--kv-disk-space-mb 65536- LM studio+ qwen3.6-27B( 同时跑了一下,可以运行,因为内存还有很多空间,但感觉单模型相应速度有下降)
装机过程比较顺利,没有太多暗坑,比较顺利!但也没有过细优化:
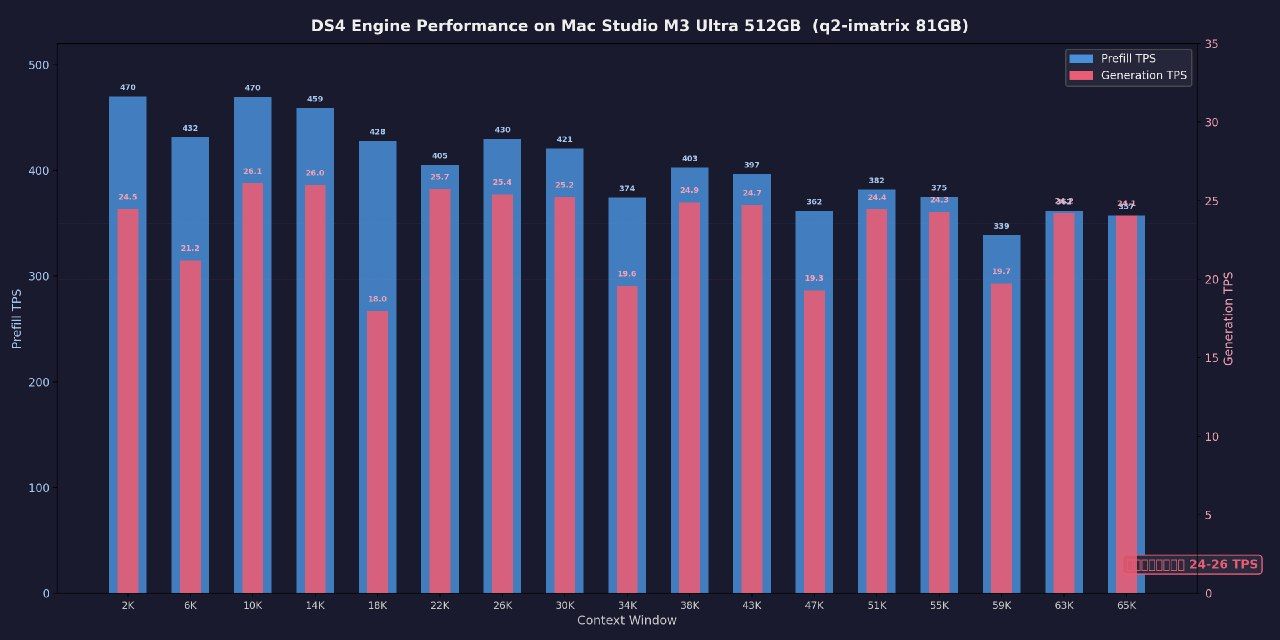
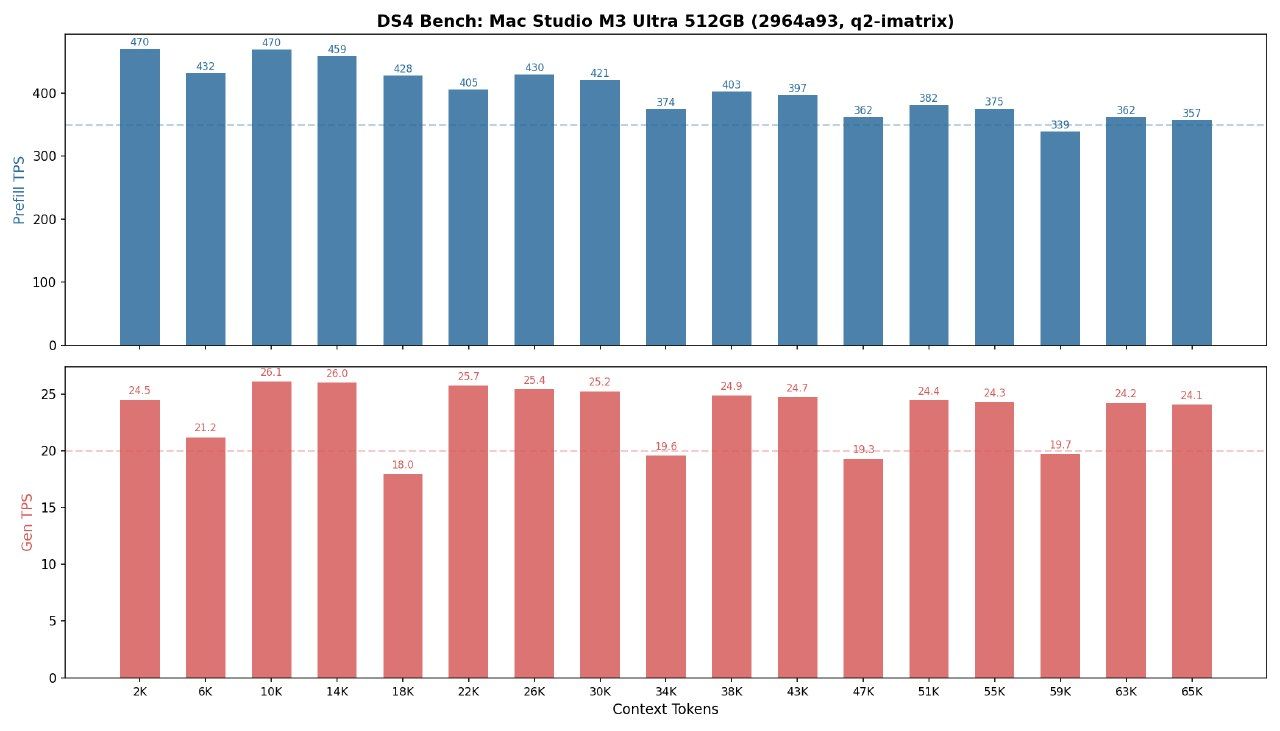
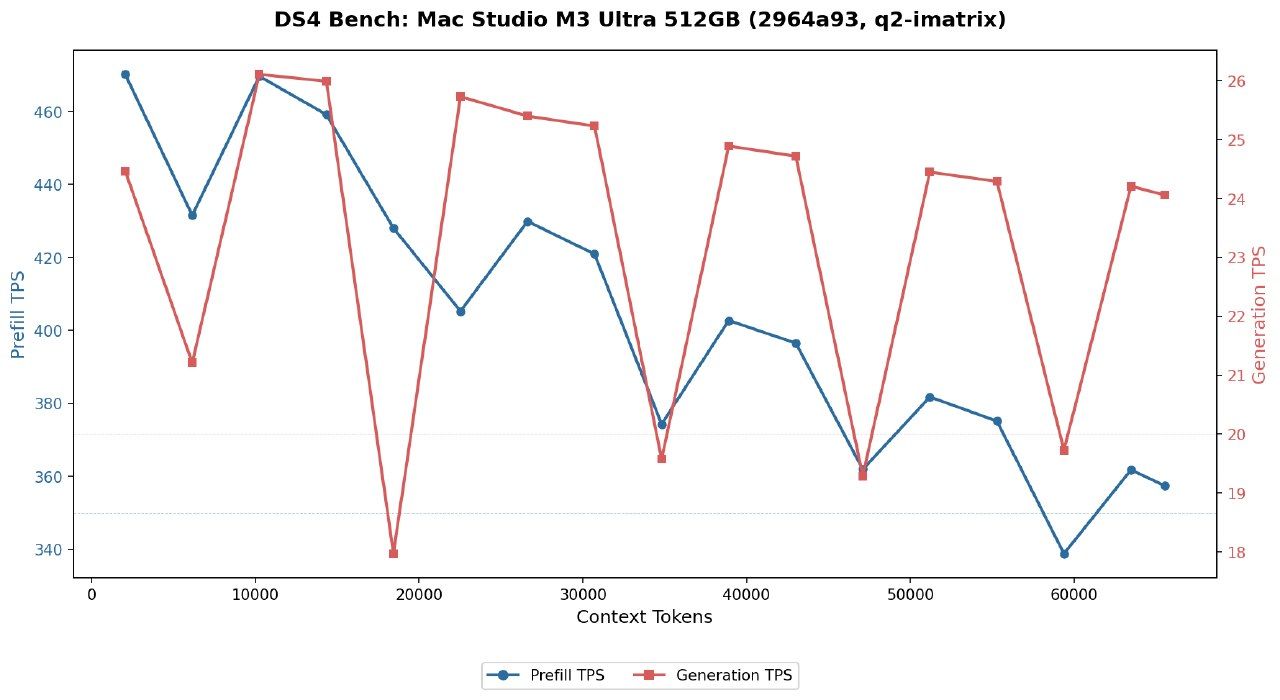
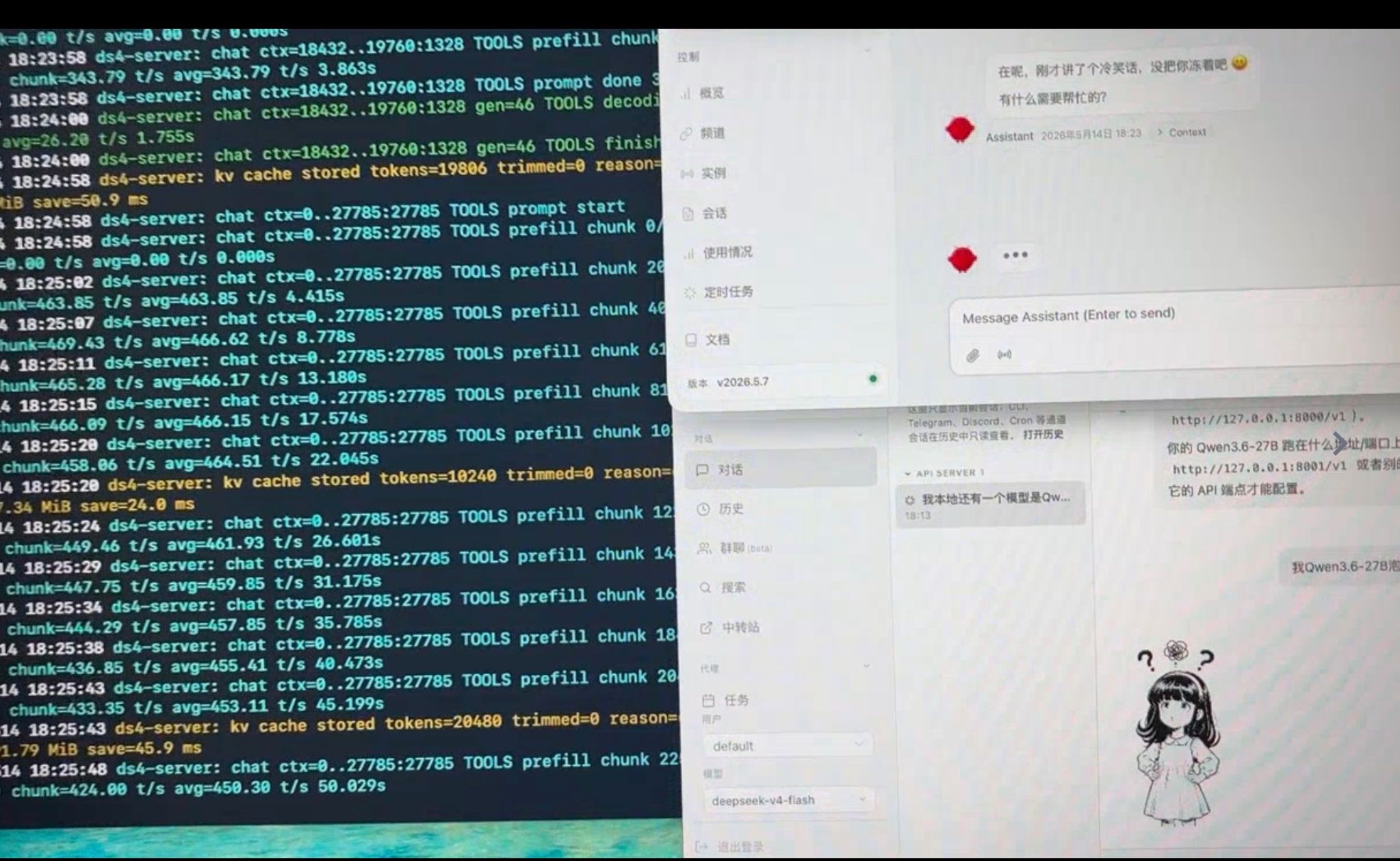
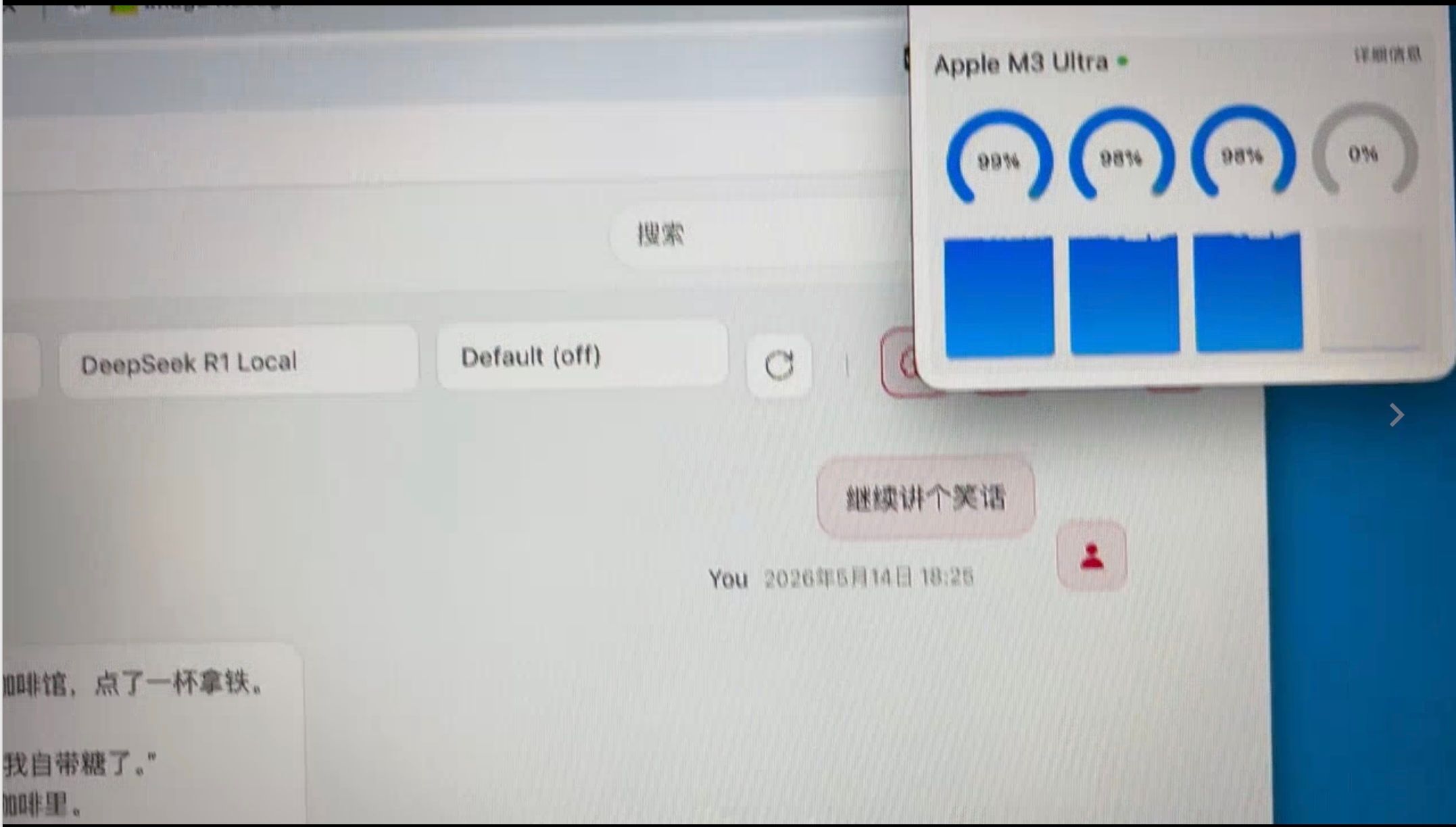
效果: 30Token/秒 ,虽然不是非常慢,但还是慢(和云端比),即便时同时多开(同时跑 Qwen和DSV4),只会更慢,没有明显的提升。因为GPU已经到了100%
- ds4+ deepseek V4 flash
-
为啥我有bug 修了好久才好
-
关键是prefill的速度比API慢太多了。chat场景不明显,Agent场景动不动冷启动就是10k的token输入。直接就罚站30秒。
-
王思聪说:我喝豆浆就是喝一碗,倒一碗。
所以以下全是一个屌丝 帮 土豪在Mac M3 Utral 512G 上跑 AI。- ds4+ deepseek V4 flash
框架ds4:https://github.com/antirez/ds4.git
deepseek V4 qt2, 本来可以直接用qt4(但我小家子气,怕效果不好)
启动参数:./ds4-server
--ctx 131072
--kv-disk-dir /tmp/ds4-kv
--kv-disk-space-mb 65536- LM studio+ qwen3.6-27B( 同时跑了一下,可以运行,因为内存还有很多空间,但感觉单模型相应速度有下降)
装机过程比较顺利,没有太多暗坑,比较顺利!但也没有过细优化:
效果: 30Token/秒 ,虽然不是非常慢,但还是慢(和云端比),即便时同时多开(同时跑 Qwen和DSV4),只会更慢,没有明显的提升。因为GPU已经到了100%
- ds4+ deepseek V4 flash
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
deepseek v4 flash 的推理速度理论上确实应该比Qwen3.6 27B快的,因为它是个MoE模型,激活参数只有13B,比27B稠密模型确实是快一些。我估计27B稠密在这个机器上能跑到20t/s就挺不错了(如果不开MTP或者DFLASH这类)。
但是ds4.c这个框架确实值得关注,因为作者太牛逼,如果我没看错的话,他是Redis的作者,在码农眼里属于现象级的人物。他觉得能拿出手的东西,那就肯定是NB的。 -

-
Fred大佬提到的ds4c框架确实是亮点。这里补充几句:ds4c全称是「DeepSeek4Coder」,它的核心优化是在内存带宽利用率上做了大量工作,对于M3 Ultra这种统一内存架构(512GB带宽)来说特别适配。M3 Ultra的带宽虽然比不上H100那些专用卡,但胜在显存超大且CPU/GPU共享内存——跑ds4c这种对内存带宽敏感的框架,效果会比其他框架好不少。
另外,Devin Hi可以试一下ds4c跑DeepSeek V4 Flash,因为ds4c本身就是针对DeepSeek系列模型做优化的,应该能发挥出M3 Ultra的最大潜力。等你的测试结果!
-
-
系统 于 取消固定此主题
-
T terry 于 将此主题固定
-
ds4引擎已经用ssd做kv cache 最近有更新 不重复prefill 等下我测试下更新后的效果
-
系统 于 取消固定此主题