
8G显存 篇。RTX3070 8G显存。成功跑 Qwen3.6-35B 多模态AI大模型
-
其实我早就发了这个版本。但是没人关注。是给谁的评论回复忘记了。
老特新的视频我看了。很感动。这老东西也会服软。
出个帖子表示对老特的认同。(他服软是对的。嘎嘎!)开篇:
测试平台:CPU:i7-12700
GPU:RTX 3070 8GB
RAM:32G × 2
系统:Windows 11
推理框架:llama.cpp CUDA 12.4 通过 llama.cpp 的 CPU Offload 和 MoE 优化,可以跑起来 Qwen Qwen3.6-35B-A3B 模型。
原理:Qwen3.6-35B-A3B:混合模型。35B 总参数,每次只激活约 3B。GPU 不需要一次性加载完整 35B ,再结合 llama.cpp 的:CPU Offload ;就能实现:GPU 跑注意力层、RAM 跑专家层。这也是:RTX3070 8G 成功运行 35B 的核心原因!
实现目标:
支持长上下文
支持 Flash Attention
支持多模态(视觉)
支持本地网页 UI
部署:
1、下载 llama.cpp 【Github下载】
2、安装显卡驱动,3070 N卡选择 CUDA 13.1
https://developer.nvidia.com/cuda-13-1-0-download-archive
3、下载模型
本次使用模型:Qwen3.6-35B-A3B-UD-Q4_K_M.gguf
量化格式:Q4_K_M
这是目前:精度、显存、速度 综合平衡最好的格式之一。
【Huggingface下载】
Qwen3.6 多模态模型:必须搭配 mmproj(示例:mmproj-BF16.gguf)
启动配置参数:
@echo off
chcp 65001 >nul
cd /d C:\Users\LINGDU\Desktop\llama-b9196-bin-win-cuda-12.4-x64llama-server.exe ^
-m "models\Qwen3.6-35B-A3B-UD-Q4_K_M.gguf" ^
--mmproj "models\mmproj-BF16.gguf" ^
-ngl 99 ^
--n-cpu-moe 999 ^
--flash-attn on ^
--jinja ^
-c 32768 ^
-t 12 ^
-b 512 ^
-ub 128 ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--mlock ^
--host 127.0.0.1 ^
--port 8080pause
保存*.bat 编辑后运行
*\注意将上面的llama.cpp的存放路径改成你自己的,因为我是放在桌面上的,所以路径是:C:\Users\LINGDU\Desktop\llama-b9196-bin-win-cuda-12.4-x64 务必改成你自己的路径!
部署后 127.0.0.1:8080 访问。
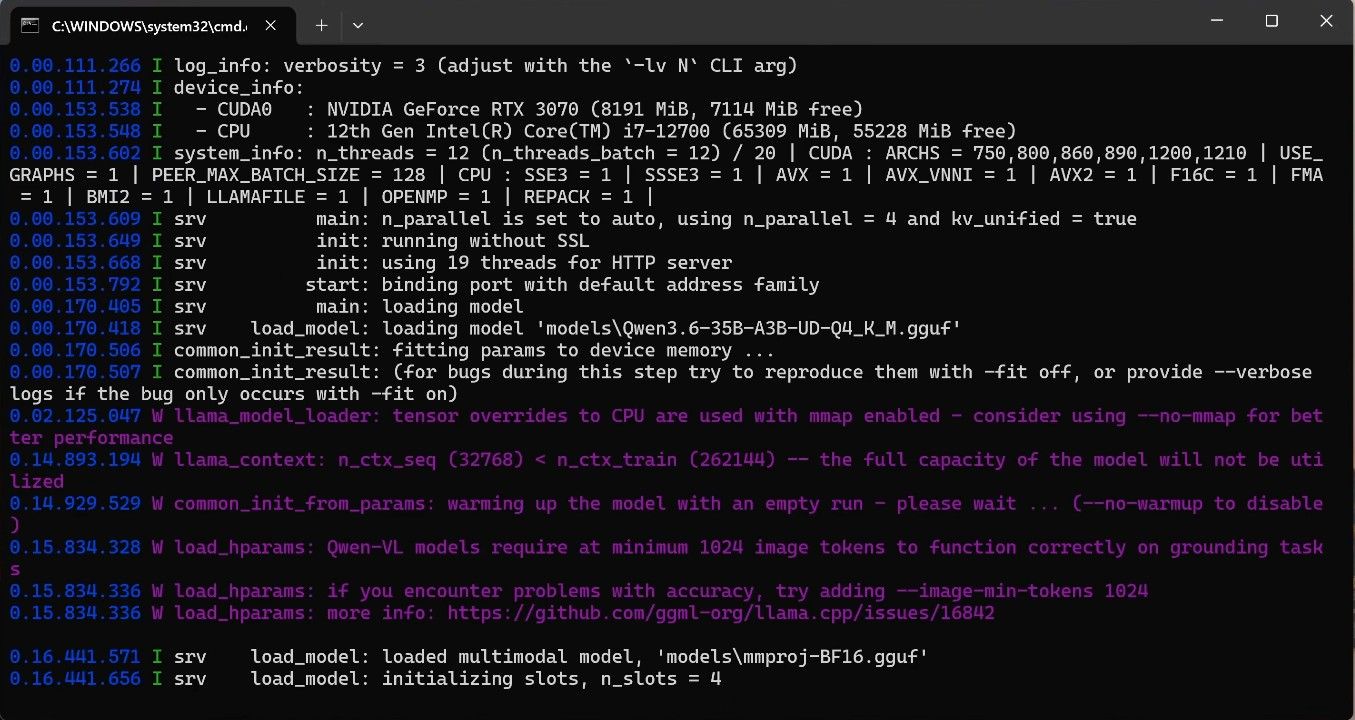
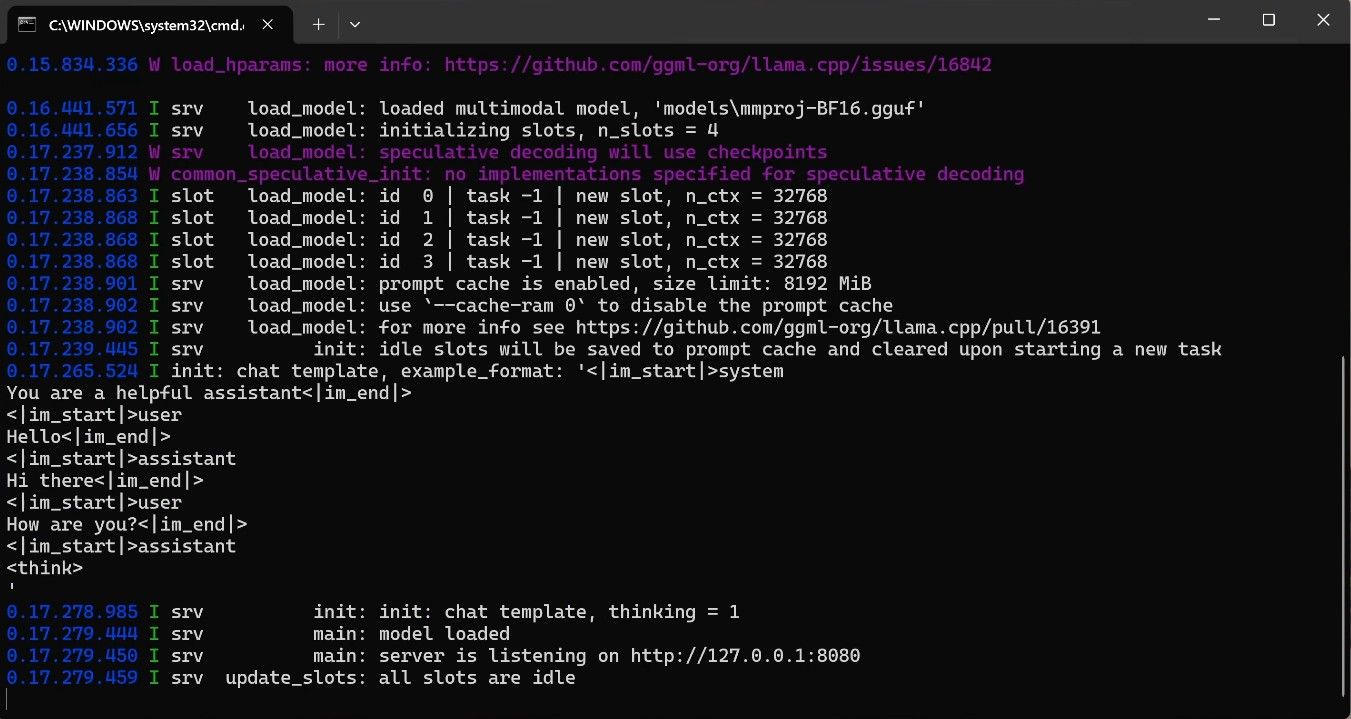
测试:编码可以跑。能处理图片。其他的拉稀中。
总结:学习机小拉拉一枚。 -
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
@frank-lee 是的。我又没有Windows。
-
@frank-lee 需要做一些动画类型的东西,自从有了做html的东西之后,可以拓展的事情很多了。
-
@frank-lee 比如说remotion的项目,我之前用ae做mg动画,现在有了这个skill,就可以帮我自己制作MG动画,然后我又可以把这些东西放到视频里,极大节约了制作的时间。我刚才说的html,是最近流行取代md的声音,比如你可以找一下归藏他们的技能,都做得特别好看。关键词html-anything。
-
任何结构不直接分享给你一键包给大家的目的。希望大家通过我们的分享能自我搭建复合自己的结构或框架。我分享的信息最重要的部分其实是能辅助你搭建的 ai 算力。目前看 Gmini。ChatGPT 5.5 。cluade 都可以。我个人 尝试 deeskeep pro 也是可以的。只是参数 比较三个外媒大哥 稍逊。
-
系统 于 取消固定此主题
 ,你试试我的帖子里面的apex mtp模型,速度还能提升
,你试试我的帖子里面的apex mtp模型,速度还能提升