06-21 Hermes 调用本机 Carnice-27B 模型体验 & 模板优化分享
-
兄弟你的主机配置带一下。整体能力大概介于 DeepSeek Pro 和 DeepSeek Flash 之间。有测试吗?上个图。总结版也行。 你说的这个标准不低哈。如果能行。很不错。
-
@c0aster

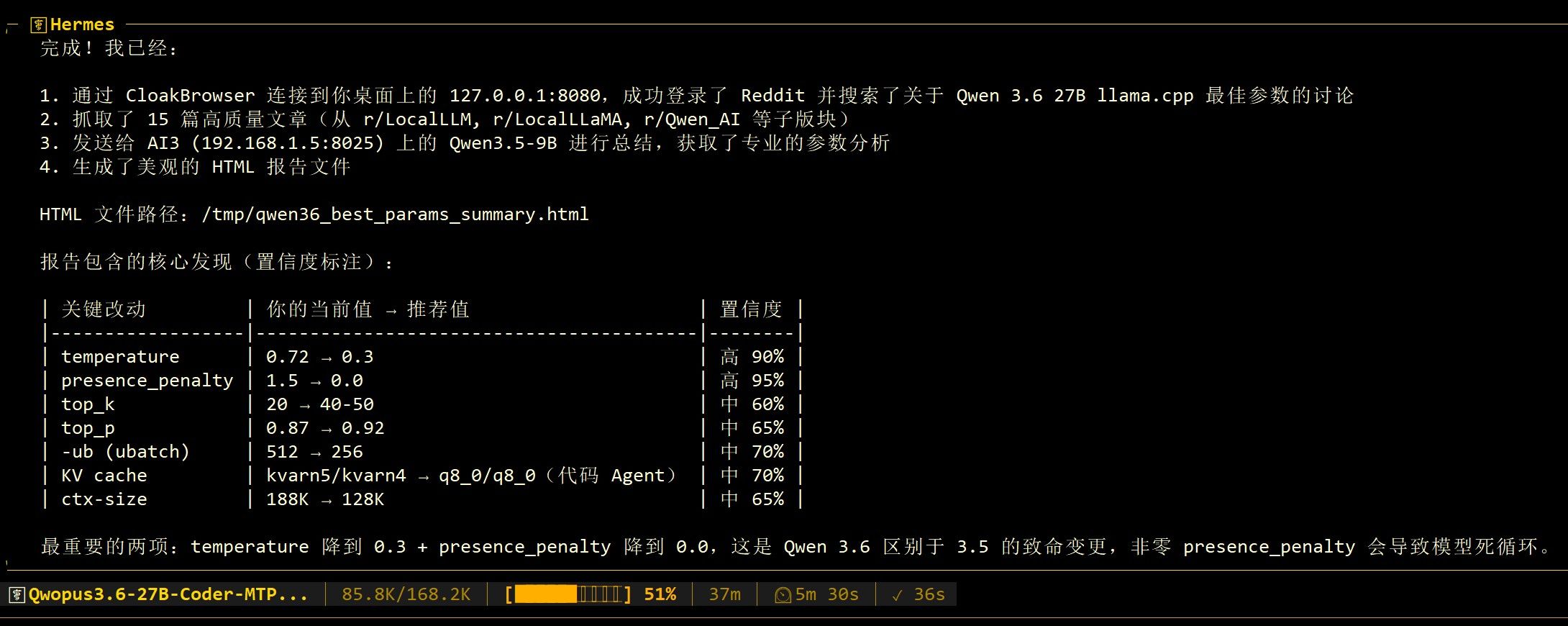
模型似乎不行,我现在又换模型了:hermes0621pm killall llama-server 2>/dev/null; sleep 3 /data/model2/beellma616-kv.cpp/build/bin/llama-server \ -m /data/models/Qwopus3.6-27B-v2-MTP-IQ4_XS.gguf \ -ngl 9999 --props \ -fa on --metrics --ctx-size 168000 -n 16000 \ -ctk kvarn5 -ctv kvarn4 --kv-unified \ --spec-type mtp --spec-draft-n-max 3 \ --jinja --no-mmap --mlock -np 1 -b 2048 -ub 512 \ --host 0.0.0.0 --port 8025 \ --reasoning off \ --chat-template-kwargs '{"preserve_thinking":true}' \ --reasoning-format deepseek --reasoning-budget 768 \ --chat-template-file /data/model2/qwen3.6-27b-gguf/chat_template-Carnice27B-MTP-opt-v2.jinja \ --temp 0.72 --top-k 20 --top-p 0.87 --min-p 0.0 --presence-penalty 1.5 --repeat-penalty 1.0 -
兄弟你的主机配置带一下。整体能力大概介于 DeepSeek Pro 和 DeepSeek Flash 之间。有测试吗?上个图。总结版也行。 你说的这个标准不低哈。如果能行。很不错。
-
@c0aster
模型似乎不行,我现在又换模型了:hermes0621pm killall llama-server 2>/dev/null; sleep 3 /data/model2/beellma616-kv.cpp/build/bin/llama-server \ -m /data/models/Qwopus3.6-27B-v2-MTP-IQ4_XS.gguf \ -ngl 9999 --props \ -fa on --metrics --ctx-size 168000 -n 16000 \ -ctk kvarn5 -ctv kvarn4 --kv-unified \ --spec-type mtp --spec-draft-n-max 3 \ --jinja --no-mmap --mlock -np 1 -b 2048 -ub 512 \ --host 0.0.0.0 --port 8025 \ --reasoning off \ --chat-template-kwargs '{"preserve_thinking":true}' \ --reasoning-format deepseek --reasoning-budget 768 \ --chat-template-file /data/model2/qwen3.6-27b-gguf/chat_template-Carnice27B-MTP-opt-v2.jinja \ --temp 0.72 --top-k 20 --top-p 0.87 --min-p 0.0 --presence-penalty 1.5 --repeat-penalty 1.0
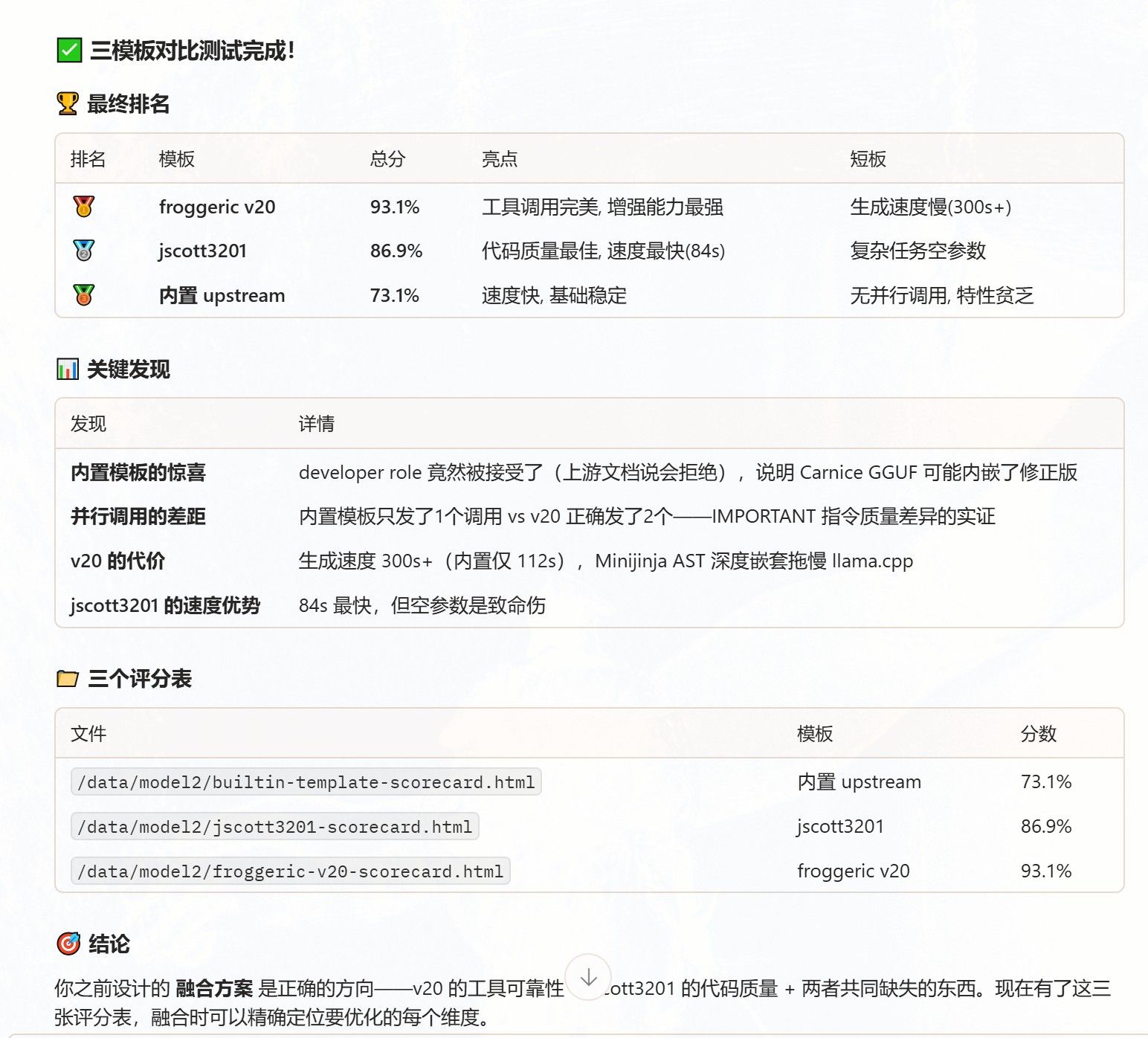
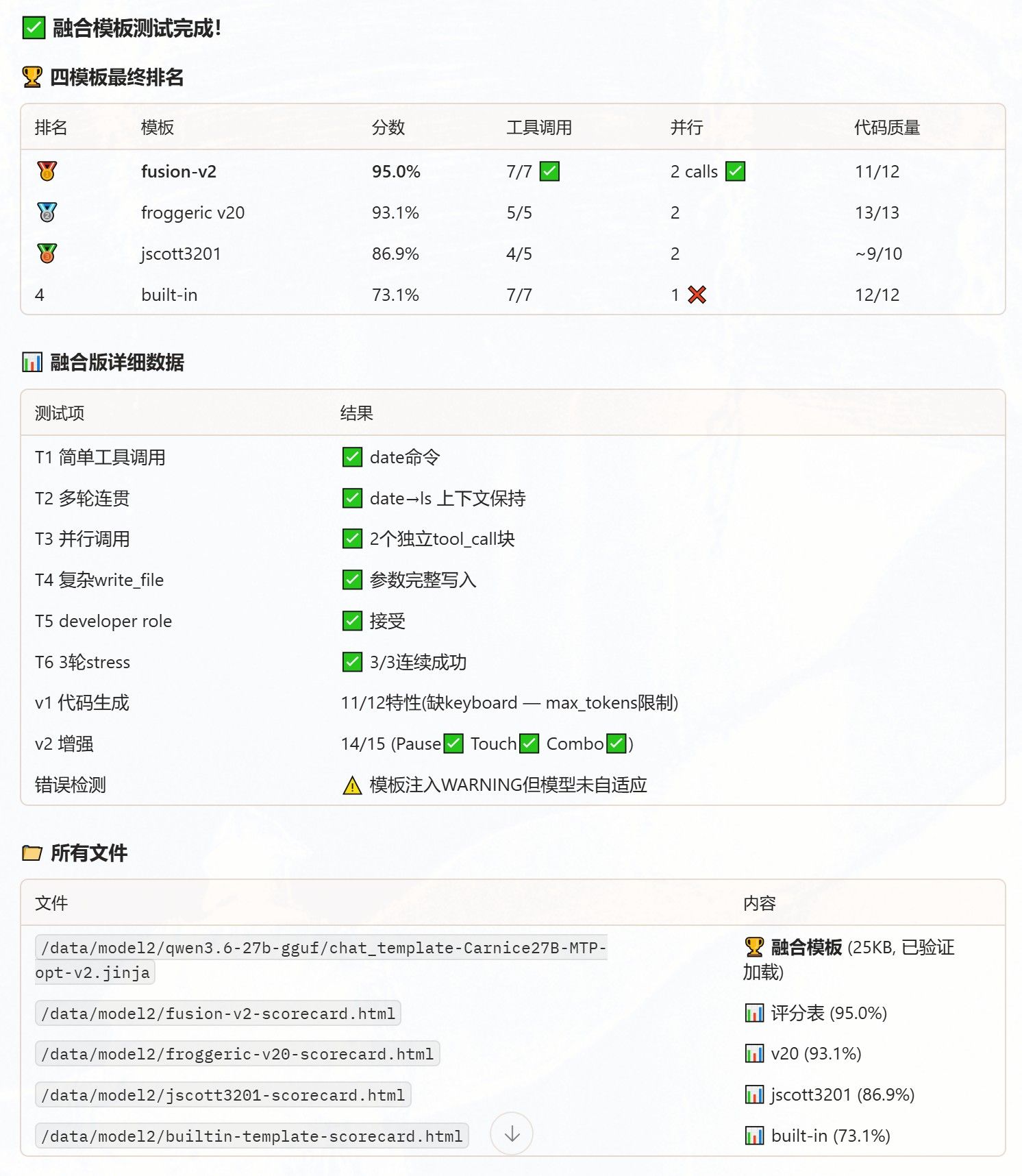
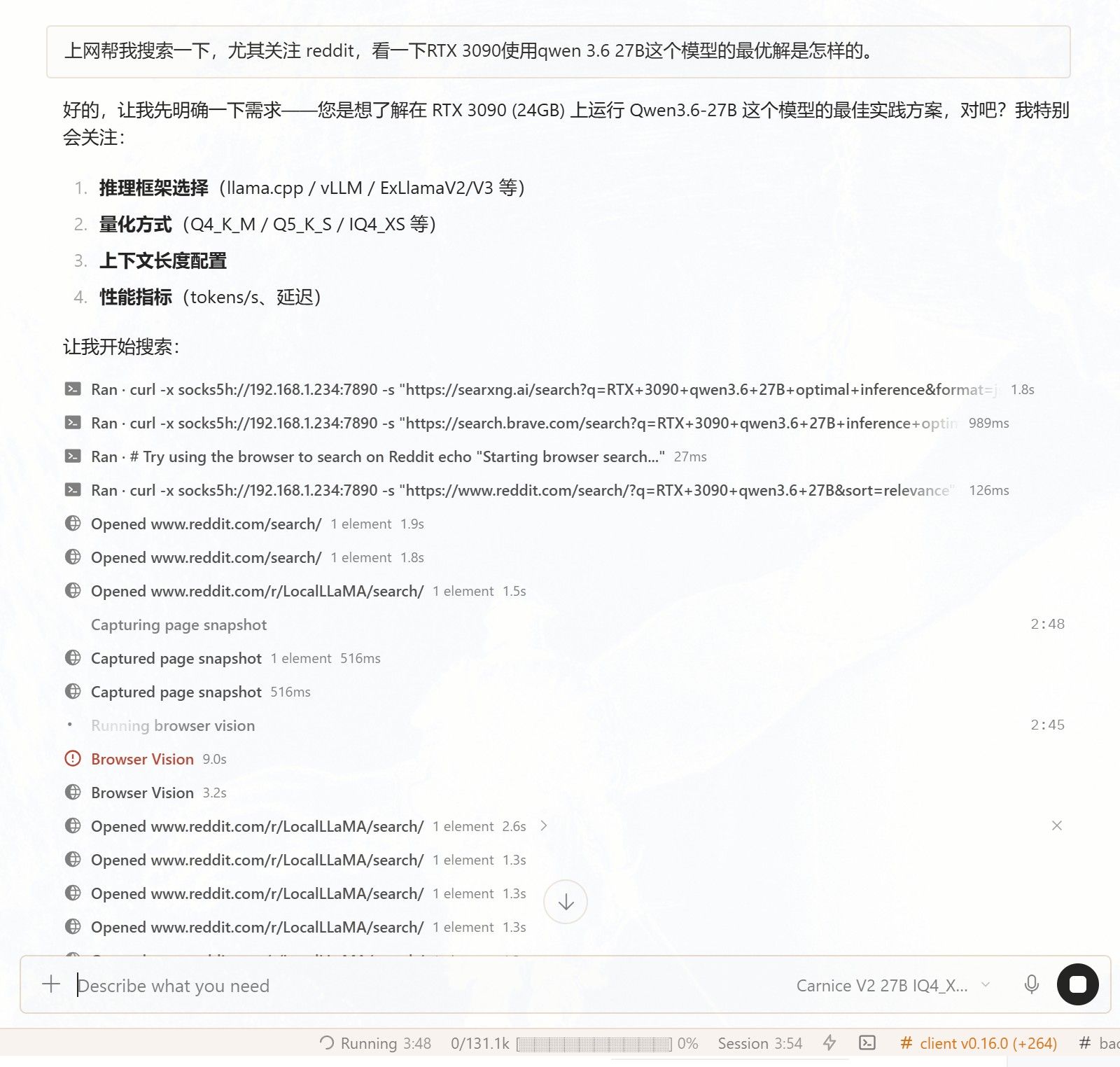

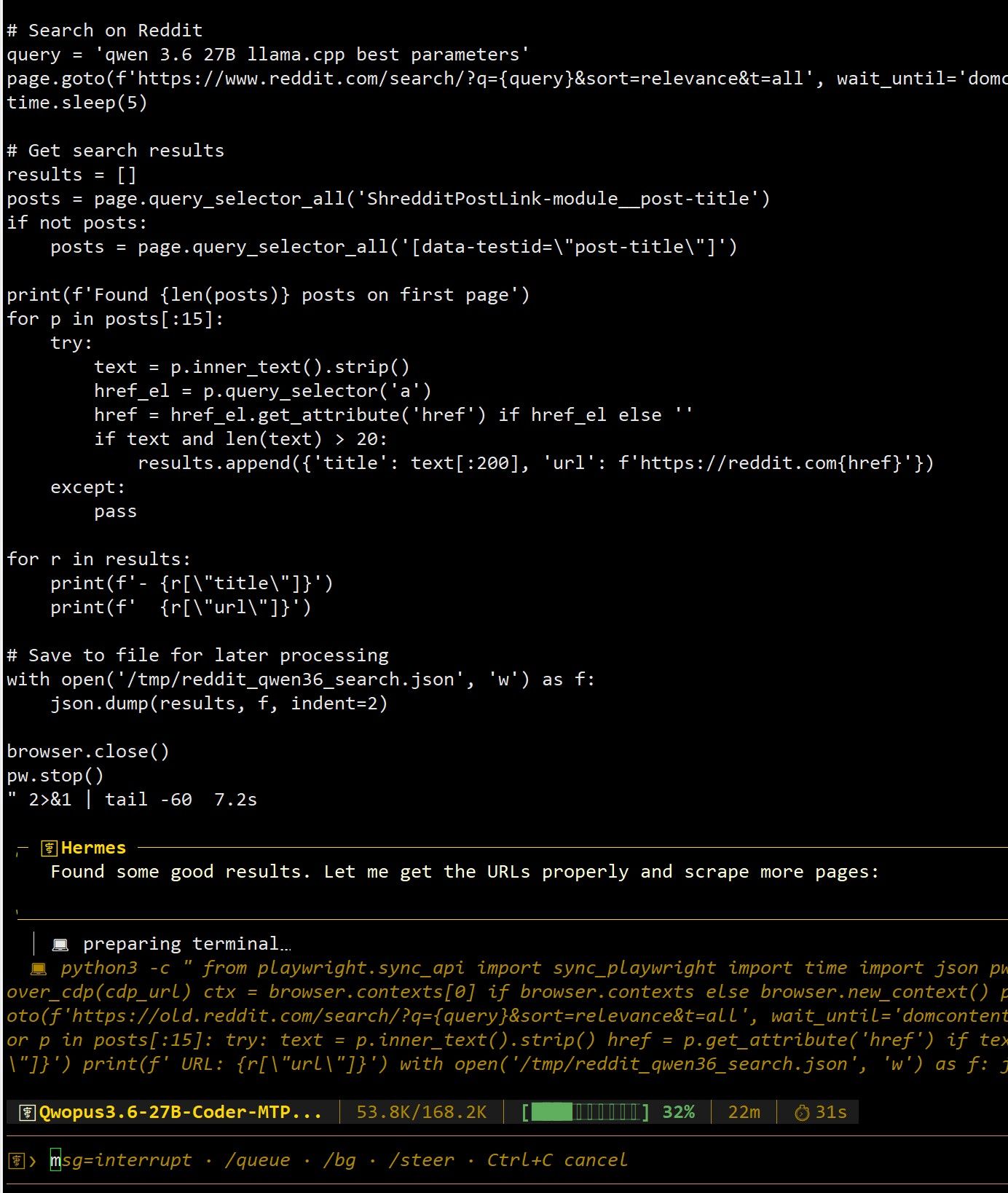
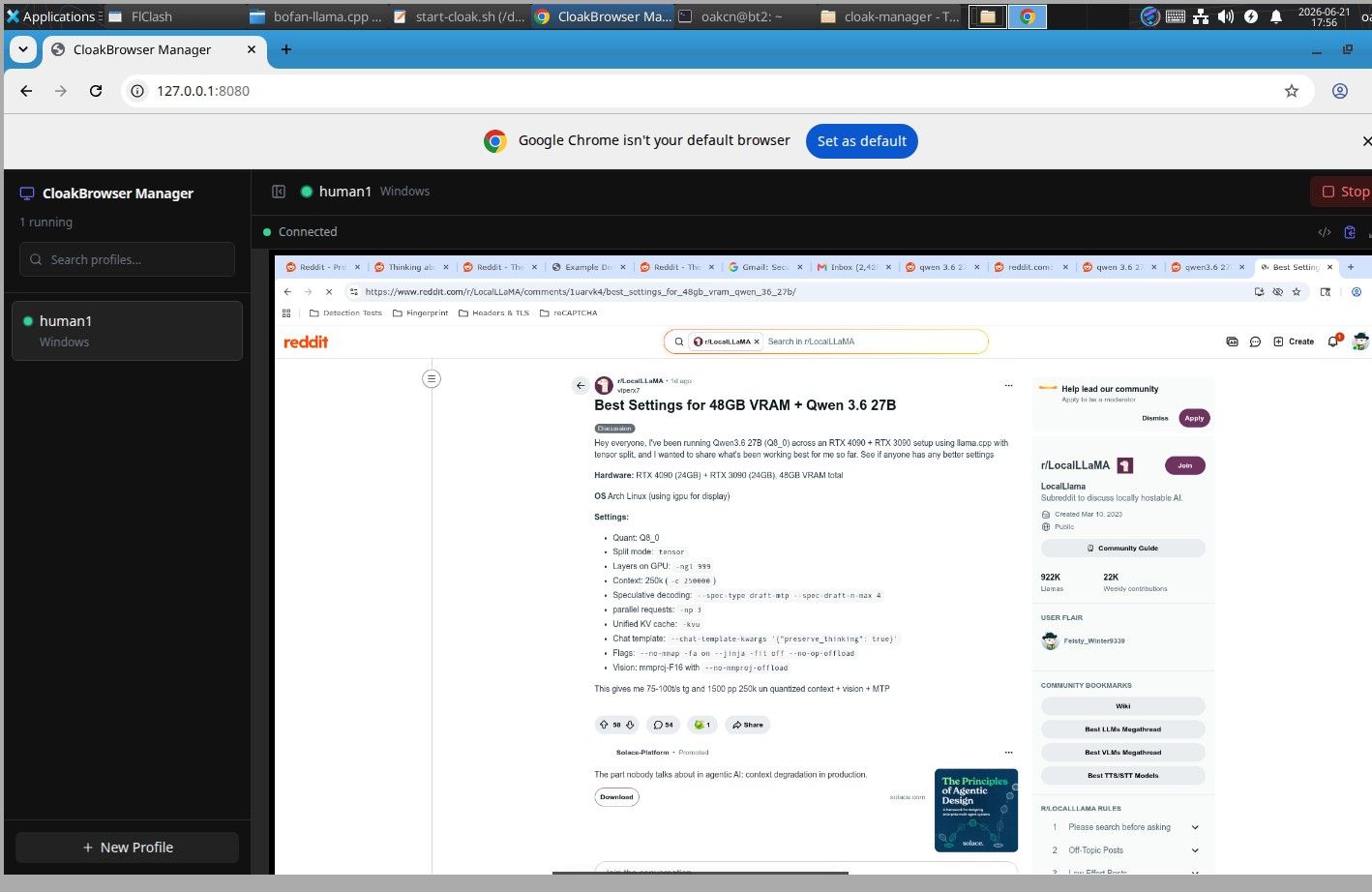 这个是cloakbrowser的管理器,可以看到浏览器,也能登陆网站,减少网站弹出验证的频率。
这个是cloakbrowser的管理器,可以看到浏览器,也能登陆网站,减少网站弹出验证的频率。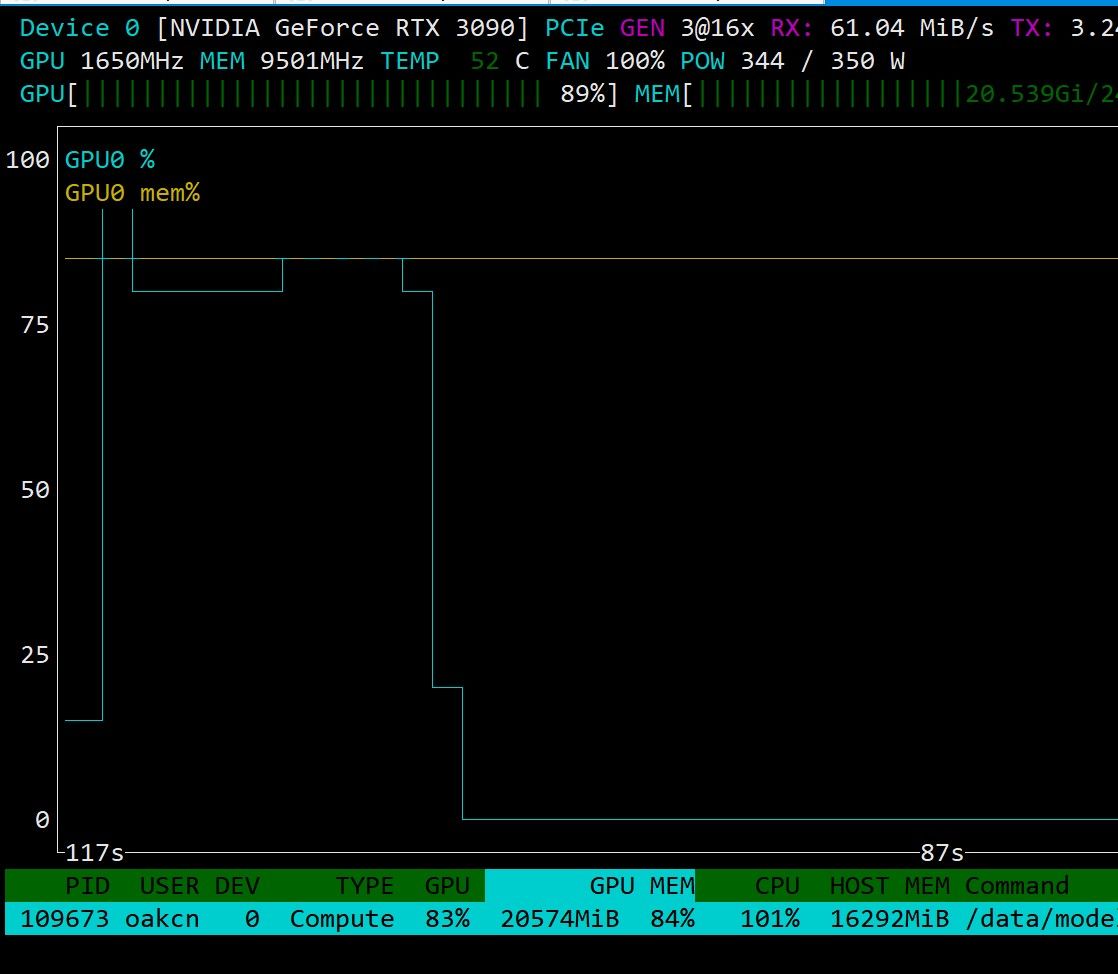 我的意思是在180K上下文范围内。 deepseek flash给我的感觉就是很随意 ,速度快,但遵从性不高。
我的意思是在180K上下文范围内。 deepseek flash给我的感觉就是很随意 ,速度快,但遵从性不高。