
基于RAG-WIKI 理论,我做了一套本地知识库,用于客服机器人.
-
忙乎了一周 , 终于 完工了.
首先 验证了 LLM Wiki(也被称为 RAG Wiki)可行性.
我基本没用chunk和Embedding,纯纯的本地Index搜索,找出相关性的文章.这个必须感谢 Andrej Karpathy(OpenAI 联合创始人、前特斯拉 AI 总监),提出的理论, 2026 年 4 月 3-4 日 , 他提出在 GitHub Gist 上发布了《llm -wiki .md》文档(https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f)
我可以说 RAG, 就是个垃圾, 可以扔到历史垃圾堆了. 很多公司,请了软件工程师,就是骗老板钱的.
首先传统的RAG,chunk分块 和Embedding向量化, 简直就是脱了裤子放屁.
痛点:
- 公司的很多文档,主要是不规范,很多pdf有幻影,还有很多ppt里面重复内容太多.
- 如果 把一些文档,切分成 不规范的分块, 再用向量 ,求相似性.
这就是垃圾堆找吃的, 你投入进去垃圾,他吐出来垃圾, 然后你说RAG 垃圾.
这不是RAG 垃圾, 你给他吃的是垃圾,他吐出来当然是垃圾.
你不管reranker ,怎么都是垃圾.核心是老板和程序员,不感觉这是错的, 一直在 错误的技术路线上,舍命狂奔.
核心思路 必须 清洗数据, 把精饲料喂给 Wiki ,然后Index索引, 查找相关的知识.
这才是王道. 否则 吃了垃圾,发给LLM ,吐出来垃圾.
如果让我总结的话,我认为大家的技术都差不多. 核心是文档精准和提示词工程.
------ 2026年6月28日------
我更新了 chunk+ embedding 路线, 我也做了一个版本. 证实了 我的结论,单纯是向量化是不如索引的技术,目前我的样本是这样的.https://lcz.me/topic/728/凌晨三点起床-忙乎一天-本地知识库rag的-chunk-embedding弄完了.
不服技术的,来贴上你的作品和代码. 别怼没完.

索引:
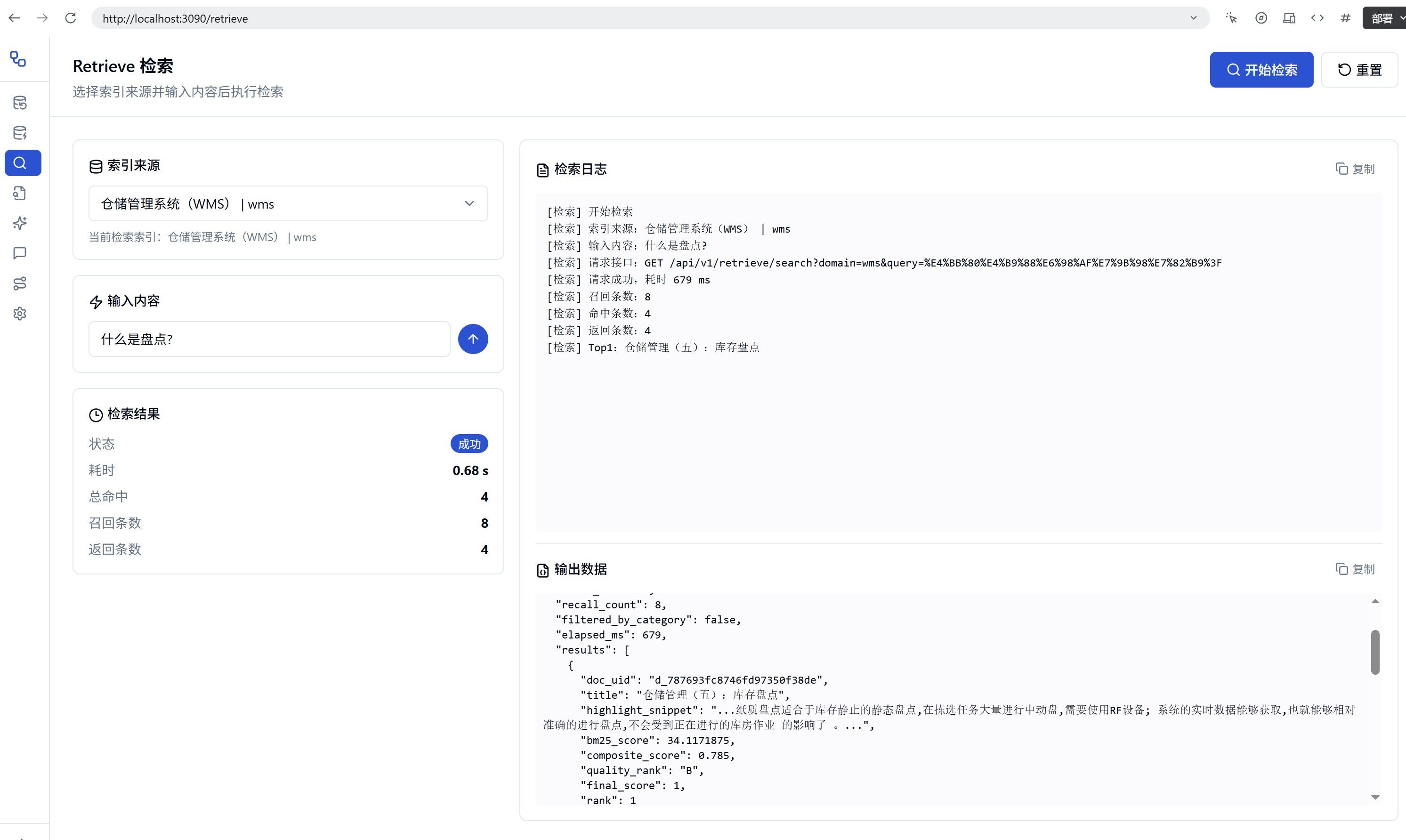
LLM效果:
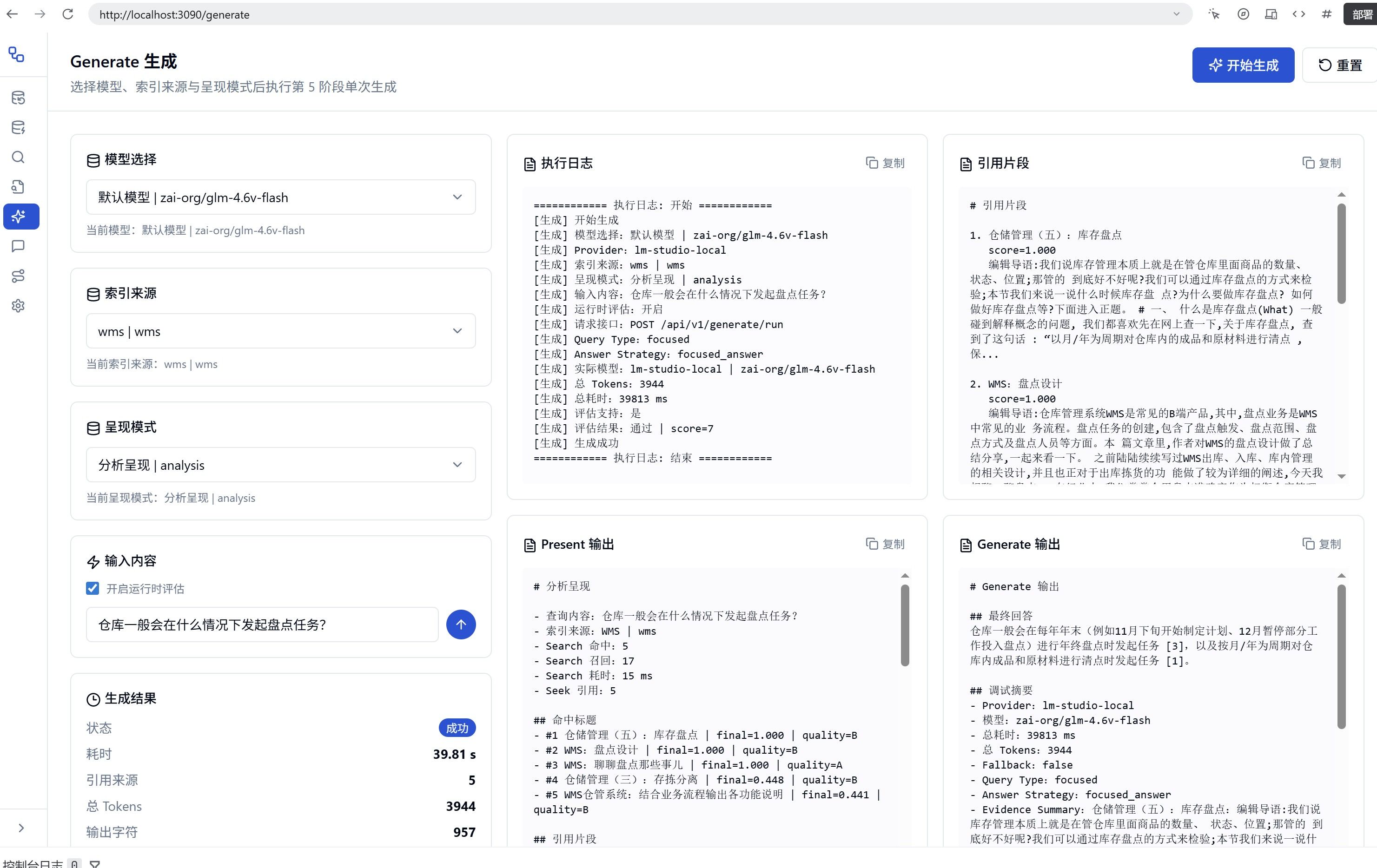
-
其实Hermes Agent就是如此的理念,但是这个理念的难点始终在于执行:
1、到底什么时候需要去维护记忆。维护的太频繁,内容量爆炸且费效比极低。维护的太少,wiki和现实的信息鸿沟又太大。2、记忆和现实的矛盾应该靠修改还是新增来解决。(比如,你以前都去盒马买西瓜,今天去的七鲜,那这段描述:“主人每周五要去盒马买西瓜”应该修改还是应该新增?)
3、如何界定一个事的边界。“我今天崴了脚,我媳妇儿晚上请我吃好吃的”,这两件事之间到底有没有逻辑关联?如果有且写入wiki,就会给LLM极大的误导。反之,如果认为没有关联,就是信息的遗失,就会造成wiki和现实的统计学偏差。
网上充斥着类似“Hermes越用越难用”,“我建立了好几个Hermes用于不同的工作流才能提升其精准度”,本质上其实就是以上三者的不停误差累积,导致最终memery从一个正向增益变成了负面噪声。
-
吃了垃圾,发给LLM ,吐出来垃圾.
这句话极其赞同. 但整个结论我不能完全同意.
我现在也在用LLM Wiki, 配合我的Obsidian一起工作, 效果非常好. 但是前提是我一样要给它高质量的内容. 而且它比较适合做专题的分析.
我不知道你具体用什么方法做索引, 好像是BM25 + composite(?)+ quality rank. 除了关键词, 向量检索肯定也是搜索相关内容的很好的方法. 用多种方法混合做检索, 效果应该更好. 比如我搜索 "车险" , BM25很可能不能命中 "车辆保险", "机动车保险" ..., 而向量检索应该更容易命中这种语义相近的内容.
我的Obsidian里面有5500篇笔记, 大部分是 .md, 还有相当一部分 pdf, ppt, word, 少量图片. 这些内容如果全部放在 LLM wiki 里, 上下文是撑不住的.
还有一种情况, 我这里没有, 但是企业知识库里往往有, 就是一个文档包含了多方面的内容. Chunk 不准确肯定是垃圾, 但是不相关内容一样是垃圾, 它会占用你宝贵的显存.
其实我觉得, 你这套系统, 就是一个自研的RAG, 只是你没有用传统的embedding和固定长度chunk. 或者说, 你的chunk变成了一个个完整文档.
所以, 我觉得不要轻易全面否定RAG的价值. 从经济性和效果的平衡出发, 还有很长的路要走. 包括RAG, 长上下文LLM, 知识图谱等技术应该长期共存,逐步融合, 更可能是一种混合策略.
个人浅见, 欢迎拍砖
")
-
吃了垃圾,发给LLM ,吐出来垃圾.
这句话极其赞同. 但整个结论我不能完全同意.
我现在也在用LLM Wiki, 配合我的Obsidian一起工作, 效果非常好. 但是前提是我一样要给它高质量的内容. 而且它比较适合做专题的分析.
我不知道你具体用什么方法做索引, 好像是BM25 + composite(?)+ quality rank. 除了关键词, 向量检索肯定也是搜索相关内容的很好的方法. 用多种方法混合做检索, 效果应该更好. 比如我搜索 "车险" , BM25很可能不能命中 "车辆保险", "机动车保险" ..., 而向量检索应该更容易命中这种语义相近的内容.
我的Obsidian里面有5500篇笔记, 大部分是 .md, 还有相当一部分 pdf, ppt, word, 少量图片. 这些内容如果全部放在 LLM wiki 里, 上下文是撑不住的.
还有一种情况, 我这里没有, 但是企业知识库里往往有, 就是一个文档包含了多方面的内容. Chunk 不准确肯定是垃圾, 但是不相关内容一样是垃圾, 它会占用你宝贵的显存.
其实我觉得, 你这套系统, 就是一个自研的RAG, 只是你没有用传统的embedding和固定长度chunk. 或者说, 你的chunk变成了一个个完整文档.
所以, 我觉得不要轻易全面否定RAG的价值. 从经济性和效果的平衡出发, 还有很长的路要走. 包括RAG, 长上下文LLM, 知识图谱等技术应该长期共存,逐步融合, 更可能是一种混合策略.
个人浅见, 欢迎拍砖
-
吃了垃圾,发给LLM ,吐出来垃圾.
这句话极其赞同. 但整个结论我不能完全同意.
我现在也在用LLM Wiki, 配合我的Obsidian一起工作, 效果非常好. 但是前提是我一样要给它高质量的内容. 而且它比较适合做专题的分析.
我不知道你具体用什么方法做索引, 好像是BM25 + composite(?)+ quality rank. 除了关键词, 向量检索肯定也是搜索相关内容的很好的方法. 用多种方法混合做检索, 效果应该更好. 比如我搜索 "车险" , BM25很可能不能命中 "车辆保险", "机动车保险" ..., 而向量检索应该更容易命中这种语义相近的内容.
我的Obsidian里面有5500篇笔记, 大部分是 .md, 还有相当一部分 pdf, ppt, word, 少量图片. 这些内容如果全部放在 LLM wiki 里, 上下文是撑不住的.
还有一种情况, 我这里没有, 但是企业知识库里往往有, 就是一个文档包含了多方面的内容. Chunk 不准确肯定是垃圾, 但是不相关内容一样是垃圾, 它会占用你宝贵的显存.
其实我觉得, 你这套系统, 就是一个自研的RAG, 只是你没有用传统的embedding和固定长度chunk. 或者说, 你的chunk变成了一个个完整文档.
所以, 我觉得不要轻易全面否定RAG的价值. 从经济性和效果的平衡出发, 还有很长的路要走. 包括RAG, 长上下文LLM, 知识图谱等技术应该长期共存,逐步融合, 更可能是一种混合策略.
个人浅见, 欢迎拍砖
-
这个RAG ,就不是 一次性成型的. 我尝试过.
每一套知识库,必须配置 一套评估规则.
只有当知识密度够我的阈值,才能出来,否则再召回.以下是我为 wms 配置的评估规则:
运行时评估
- Supported:true
- Rule:WMS 生成评估规则 v1
- Passed:true
- Score:7
- Answer OK:true
- Answer Terms OK:true
- Source Count OK:true
- Citation OK:true
- Grounded OK:true
- Actual Sources:5
- Citation Count:1
- Required Terms:盘点, 库存, 差异
- Hit Terms:盘点
- Missing Source Titles:(none)
- Forbidden Terms:(none)
-
我理解了,你这套系统已经做得很完善了。我觉得还可以继续往通用性方向拓展一些。

比如,Rule 是人工配置的,还是 AI 也能够协助生成或维护?
再比如,语义相关性的处理。像 “美签”、“美国签证”、“美国学生签”、“美国工签” 这些词,我觉得 Embedding 这种语义检索会比较容易命中。而传统关键词搜索,可能还需要配置同义词规则,或者结合一些语义相关性的搜索策略。
另外, 就是整篇文档召回, 我觉得会有浪费显存的状况.
我个人还是觉得,不同的检索方式各有优缺点,最终更可能还是一种混合策略。
-
@Tony-Wang 你说的我理解了. 我可以用 双路,一个是index+search ,一个是chunk+embedding.
我尝试下, 应该不难. 我想想 怎么接线.
但是我想提升,文档的输入的质量 和 提示词优化.
如果还不行,我尝试下双路, 我就怕,双路之后, 我自己都不知道哪里错了.
-
認同GIGO的概念, 如果沒理解錯的話提到應該就是Naive RAG在應對錯誤資訊的痛處: 大學生在開書考試帶錯書了
希望這個比喻沒錯但不太認同一棍子打掉所有RAG, 先不說RAG有分很多類型, 這裏說幾個比較常見的: FLARE, DRAGIN, Adaptive, Probing
Naive RAG自己也有不同的變種來增加搜索準確率吧, RRR (Rewrite-Retrieve-Read) 跟 RRF (Reciprocal Rank Fusion), 上面kop大提到的語意搜尋應該就是RRF中的語意搜尋 (Semantic Search) + 關鍵字搜索 (Lexical Search, BM25)吧?
我在目前測量公司弄的就是RRR
Naive RAG永遠只適合在陳述事實的場合, 也就是媽媽是女人, 或者沒什麽人知道的冷知識
因爲之前在幫忙架構RAGFlow, 所以有跑去研究了一下幾個不同設計方向的RAG, 基本上也是針對著Naive RAG不同方面進行改進 (何時檢索, 如何查)
框架 思路 優勝點 FLARE 按需觸發 + 預測性查詢:僅在低置信度 token 時檢索,以「預測下一句」構造查詢 避免長生成過程中的無效檢索 DRAGIN 全域智慧決策:RIND 綜合評估不確定性/語義/上下文影響;QFS 基於完整歷史自注意力權重構建查詢 打破靜態規則與窄上下文限制 Adaptive 難度分級路由:分類器預判複雜度,動態分配「免檢索/單次/多步迭代」策略 解決「一刀切」帶來的計算浪費 Probing 內省式知識評估:隱藏狀態探針直讀 LLM 內部認知,判斷「是否已知情」 消除冗餘檢索與知識覆蓋衝突 最近好像也出了個Skill RAG, 不過我還沒去看Paper所以也不知道設計思路是什麽, 只在Twitter上知道是關於失敗後如何修復
無意引戰, 單純抛磚引玉 + 避免一刀切XXX沒用這種説法
技術 + 設計思路是需要時間成熟, 慢慢進步的要知道Naive RAG已經是2023年的產物了, 當時還單純叫RR, Retrieve-Read
突然覺得時間飛得有點快 -
学习中。知识增长了些许。我主要还是对 这个技术了解太少。拜读。
-
認同GIGO的概念, 如果沒理解錯的話提到應該就是Naive RAG在應對錯誤資訊的痛處: 大學生在開書考試帶錯書了
希望這個比喻沒錯但不太認同一棍子打掉所有RAG, 先不說RAG有分很多類型, 這裏說幾個比較常見的: FLARE, DRAGIN, Adaptive, Probing
Naive RAG自己也有不同的變種來增加搜索準確率吧, RRR (Rewrite-Retrieve-Read) 跟 RRF (Reciprocal Rank Fusion), 上面kop大提到的語意搜尋應該就是RRF中的語意搜尋 (Semantic Search) + 關鍵字搜索 (Lexical Search, BM25)吧?
我在目前測量公司弄的就是RRR
Naive RAG永遠只適合在陳述事實的場合, 也就是媽媽是女人, 或者沒什麽人知道的冷知識
因爲之前在幫忙架構RAGFlow, 所以有跑去研究了一下幾個不同設計方向的RAG, 基本上也是針對著Naive RAG不同方面進行改進 (何時檢索, 如何查)
框架 思路 優勝點 FLARE 按需觸發 + 預測性查詢:僅在低置信度 token 時檢索,以「預測下一句」構造查詢 避免長生成過程中的無效檢索 DRAGIN 全域智慧決策:RIND 綜合評估不確定性/語義/上下文影響;QFS 基於完整歷史自注意力權重構建查詢 打破靜態規則與窄上下文限制 Adaptive 難度分級路由:分類器預判複雜度,動態分配「免檢索/單次/多步迭代」策略 解決「一刀切」帶來的計算浪費 Probing 內省式知識評估:隱藏狀態探針直讀 LLM 內部認知,判斷「是否已知情」 消除冗餘檢索與知識覆蓋衝突 最近好像也出了個Skill RAG, 不過我還沒去看Paper所以也不知道設計思路是什麽, 只在Twitter上知道是關於失敗後如何修復
無意引戰, 單純抛磚引玉 + 避免一刀切XXX沒用這種説法
技術 + 設計思路是需要時間成熟, 慢慢進步的要知道Naive RAG已經是2023年的產物了, 當時還單純叫RR, Retrieve-Read
突然覺得時間飛得有點快 -
,M mark 引用了 此主题