
7900XTX + llama.cpp Qwen3.6 27B TurboQuant + MTP 测试结果分享
-
最近刚入手了 7900xtx,本地跑llm, 为opencode, pi.dev 提供本地llm api 解决客户的代码隐私焦虑。
花了亿点点时间跑了下性能,结果如下,供各位参考。流水账,先不贴llama-bench 结果了,太多。
先发 老特 这里了,回头有空了再发个reddit
回头等DFlash + HIP(ROCM) 成熟了再跑下看看。1. Rocm + turboquant,
repo: https://github.com/domvox/llama.cpp-turboquant-hip
性能: 256k上下文, pp: 970t/s tg: 29t/s
Comment:目前测试,除了反应没在线api 快,生成代码的质量不比在线api 差。~/llama.cpp-turboquant-hip/rocm/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-Q4_K_P.gguf --mmproj ~/model/llm/qwen3.6-27b/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf --alias qwen3.6-27b --host 0.0.0.0 --port 8080 --n-gpu-layers 999 --ctx-size 262144 --batch-size 2048 --ubatch-size 768 --threads 8 --temp 1.0 --top-p 0.95 --top-k 20 --min-p 0.00 --presence_penalty 1.5 --cache-type-k turbo3 --cache-type-v turbo32. Vulkan
repo: https://github.com/ggml-org/llama.cpp
性能: 256k上下文, kv-cache-type: Q4_0, pp: 730t/s tg: 47t/s, (Q8_0会慢一丢丢)~/Downloads/llama.cpp/vulkan/bin/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Q4_K_M-mtp.gguf --alias qwen3.6-27b --cache-type-k q4_0 --cache-type-v q4_0 -np 1 -c 262144 --temp 0.7 --top-k 20 -ngl 99 --port 8080 --host 0.0.0.0 -fa 1 -ub 2562.1 Vulkan + turboquant,
repo: https://github.com/TheTom/llama-cpp-turboquant
性能: 256k上下文, kv-cache-type: Q4_0, tg: 10t/s, decoding 时 GPU 使用率不到 30%,速度拉跨。开MTP 也 差不多。~/llama.cpp/build/bin/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Q4_K_M-mtp.gguf --alias qwen3.6-27b --cache-type-k turbo3 --cache-type-v turbo3 -np 1 -c 262144 --temp 0.7 --top-k 20 -ngl 99 --port 8080 --host 0.0.0.0 -fa 1 -ub 2563. Vulkan + MTP
repo/pr:
https://github.com/ggml-org/llama.cpp/pull/22673
性能: 256k上下文, kv-cache-type: Q4_0, pp: 730t/s tg: 67t/s, VRAM 占用跟不开MTP 差不多,~/Downloads/llama.cpp/vulkan/bin/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Q4_K_M-mtp.gguf --alias qwen3.6-27b --spec-type mtp --spec-draft-n-max 3 --cache-type-k q4_0 --cache-type-v q4_0 -np 1 -c 262144 --temp 0.7 --top-k 20 -ngl 99 --port 8080 --host 0.0.0.0 -fa 1 -ub 2563. Rocm + MTP
repo/pr: https://github.com/ggml-org/llama.cpp/pull/22673
性能: 4k上下文, kv-cache-type: Q4_0, pp: 730t/s tg: 67t/s
Comment: Rocm的backend + MTP 有问题,VRAM 在开始 对话时 暴增 5G,具体原因不明,所以 最多8k上下文, Rocm目前的好处 是由 turbo quant 集成。~/llama.cpp/build/bin/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Q4_K_M-mtp.gguf --alias qwen3.6-27b --spec-type mtp --spec-draft-n-max 3 --cache-type-k q4_0 --cache-type-v q4_0 -np 1 -c 4096 --temp 0.7 --top-k 20 -ngl 99 --port 8080 --host 0.0.0.0 -fa 1 -ub 2564.Hipfire (DFlash) v0.1.20
repo: https://github.com/Kaden-Schutt/hipfire
性能: 4k上下文, pp: 930t/s tg: 46t/s,
Comment: 只能chat聊天,速度很快,默认开启 DFlash, 但是 上下文8k 以上就会卡死,或者崩溃, 没法给 opencode 或者pi 使用,等三个月半年再看看。5. 老卡 P40 24G,
repo: https://github.com/TheTom/llama-cpp-turboquant
pr: https://github.com/ggml-org/llama.cpp/pull/22673不开MTP
性能: 196k 上下文,tg: 10t/s,
~/llama.cpp-mtp/build/bin/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Q4_K_M-mtp.gguf --alias qwen3.6-27b --cache-type-k turbo3 --cache-type-v turbo3 -c 196608 --temp 0.7 --top-k 20 -ngl 99 --port 8080 --host 0.0.0.0 -fa 1 -ub 256开MTP
性能: 196k上下文,tg: 17t/s,
~/llama-cpp-turboquant/build/bin/llama-server -m ~/model/llm/qwen3.6-27b/Qwen3.6-27B-Q4_K_M-mtp.gguf --alias qwen3.6-27b --spec-type mtp --spec-draft-n-max 3 --cache-type-k turbo3 --cache-type-v turbo3 -np 1 -c 196608 --temp 0.7 --top-k 20 -ngl 99 --port 8080 --host 0.0.0.0 -fa 1 -ub 256
opencode + deepseek v4 帮我跑了一把,结果如下
- 如果追求性能 Vulkan + MTP 效果最好,
- MTP的性能不是恒定的,不同的上下文或者任务,可能存在很大的差别,你让他写小说,规划日常,写代码,性能提升可能会不一样,跑分仅供参考。
- MTP 目前只能单个对话session,没法并行。
- Vuklan 后端对 Turbo quant的支持还有存在问题, GPU利用率不够,还得优化。
- Rocm + MTP 存在 VRAM问题,会无端暴涨5G占用,导致跑起来最多8k多一点。
llama-bench 测试结果
环境
- MTP 模型: Qwen3.6-27B-Q4_K_M-mtp.gguf (15.82 GiB) https://huggingface.co/froggeric/Qwen3.6-27B-MTP-GGUF/
- 非MTP 模型: Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-Q4_K_P.gguf (17 GiB) https://huggingface.co/HauhauCS/Qwen3.6-27B-Uncensored-HauhauCS-Aggressive
- GPU: AMD Radeon RX 7900 XTX (24,560 MiB 显存)
- CPU: Genuine Intel(R) 13900hk ES
- 线程数: 8
- n-gpu-layers: 999 (完全卸载到 GPU)
- 温度: 0.7, top-k: 20
ROCm (HIP) - KV缓存类型对比 (非MTP)
二进制:
~/llama.cpp/rocm/bin/llama-bench(build 9046)KV缓存类型 pp1024 (token/s) tg128 (token/s) f16 (默认) 904.50 28.99 q4_0 898.01 28.81
Vulkan - KV缓存类型对比 (非MTP)
标准构建 (
~/Downloads/llama.cpp/build-vulkan/bin/llama-bench)KV缓存类型 pp512 (token/s) tg128 (token/s) f16 765.94 37.06 Q4_0 769.82 37.17 Q8_0 273.25 37.13 Turboquant 构建 (
~/Downloads/llama-cpp-turboquant/build-vulkan/bin/llama-bench)KV缓存类型 pp512 (token/s) tg128 (token/s) turbo2 193.43 ± 1.49 23.79 ± 0.17 turbo3 128.44 ± 1.31 21.88 ± 0.14 turbo4 178.94 ± 2.03 23.00 ± 0.25 注意:turboquant 测试期间 GPU 使用率仅约 30%,未能充分利用 GPU。瓶颈可能在 CPU 端的量化/反量化操作。
q4_0/q8_0 在 turboquant 构建的 llama-bench 中仍然失败。
Vulkan + MTP
二进制:
~/llama.cpp/vulkan/bin/llama-cli
命令:--spec-type mtp --spec-draft-n-max 3 --parallel 1 -p "tell me a jok" -n 128 -ngl 999注意:MTP 使用
-np 1(单并行序列),因此无法并行处理。草稿模型顺序执行,限制了吞吐量。配置 生成速度 (token/s) 非MTP (f16) 39.5 MTP (q4_0) 81.2 MTP (q8_0) 77.5
ROCm + MTP
二进制:
~/llama.cpp/rocm/bin/llama-cli配合LD_LIBRARY_PATH配置 生成速度 (token/s) 非MTP (f16) 29.4 MTP (q4_0) 53.6 MTP (turbo3) 47.4 MTP (turbo4) 57.2
总结
非MTP (llama-bench)
KV缓存类型 pp (token/s) tg128 (token/s) 后端 f16 904.50 28.99 ROCm (pp1024) q4_0 898.01 28.81 ROCm (pp1024) f16 765.94 37.06 Vulkan 标准 (pp512) Q4_0 769.82 37.17 Vulkan 标准 (pp512) Q8_0 273.25 37.13 Vulkan 标准 (pp512) turbo2 193.43 23.79 Vulkan turboquant (pp512) turbo4 178.94 23.00 Vulkan turboquant (pp512) turbo3 128.44 21.88 Vulkan turboquant (pp512) MTP (llama-cli)
配置 生成速度 (token/s) 后端 MTP (q4_0) 81.2 Vulkan MTP (q8_0) 77.5 Vulkan MTP (turbo4) 57.2 ROCm MTP (q4_0) 53.6 ROCm MTP (turbo3) 47.4 ROCm 非MTP (f16) 39.5 Vulkan 非MTP (f16) 29.4 ROCm 关键观察
- ROCm 上的 q4_0 性能与 f16 几乎相同 (898 vs 905 token/s) — 差异可忽略。
- Turboquant 类型 仅适用于 turboquant Vulkan 构建。turbo2 的提示处理最快 (193 token/s @ pp512)。各 turbo 变体的生成速度相近 (~22-24 token/s)。
- 标准 Vulkan 构建 支持 Q4_0/Q8_0 — Q4_0 与 f16 速度相当 (~770 token/s pp512),Q8_0 提示处理慢约 2.8 倍 (273 token/s) 但生成速度相同 (~37 token/s)。Turbo 类型仅适用于 turboquant 构建。
- MTP 显著提升生成速度:Vulkan+q4_0 达到 81.2 token/s(比非MTP 提升 +106%),Vulkan+q8_0 达到 77.5 token/s (+96%),ROCm+turbo4 达到 57.2 token/s (+95%)。
-
上述测试,都是自己编译对吧?
另外,你有试过这个 修复MTP多模态的吗(需要cherrypick)?
https://github.com/ggml-org/llama.cpp/issues/22867@jenaflex 对,开个opencode,你让它给你搞完了,不难
-
上述测试,都是自己编译对吧?
另外,你有试过这个 修复MTP多模态的吗(需要cherrypick)?
https://github.com/ggml-org/llama.cpp/issues/22867@jenaflex
https://github.com/ggml-org/llama.cpp/issues/22867 这里提到的change:
https://github.com/am17an/llama.cpp/pull/5
不管用,再 Rocm下照样爆VRAM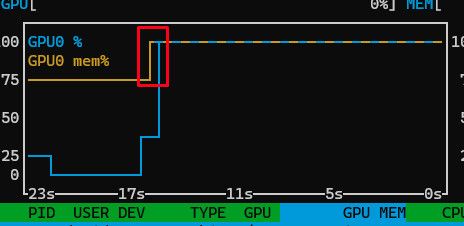
-
 T terry 固定了该主题
T terry 固定了该主题
-
下班开始折腾
-
这个太棒了
 ,先顶再抄作业。
,先顶再抄作业。 -
没有完全按楼主提供的模型,只是增加了mmproj,感觉7900 不到30t/s,不知道Hermis怎么样。“/home/devin/work/llama.cpp-turboquant/build/bin/llama-server
-m /home/devin/work/models/Qwen3.6-27B-Q4_K_M.gguf
--mmproj /home/devin/work/models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
--host 0.0.0.0
--port 8081
--n-gpu-layers 999
--ctx-size 262144
--batch-size 2048
--ubatch-size 768
--threads 8
--temp 1.0
--top-p 0.95
--top-k 20
--min-p 0.00
--presence_penalty 1.5
--cache-type-k turbo3
--cache-type-v turbo3” -
没有完全按楼主提供的模型,只是增加了mmproj,感觉7900 不到30t/s,不知道Hermis怎么样。“/home/devin/work/llama.cpp-turboquant/build/bin/llama-server
-m /home/devin/work/models/Qwen3.6-27B-Q4_K_M.gguf
--mmproj /home/devin/work/models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
--host 0.0.0.0
--port 8081
--n-gpu-layers 999
--ctx-size 262144
--batch-size 2048
--ubatch-size 768
--threads 8
--temp 1.0
--top-p 0.95
--top-k 20
--min-p 0.00
--presence_penalty 1.5
--cache-type-k turbo3
--cache-type-v turbo3”绝大多数量化后的模型把mtp layer 给砍掉了,你得下载代mtp的量化模型才有效果
-
@terry 没问题,我有空了发截图和数据。
-
Rocm 不开MTP
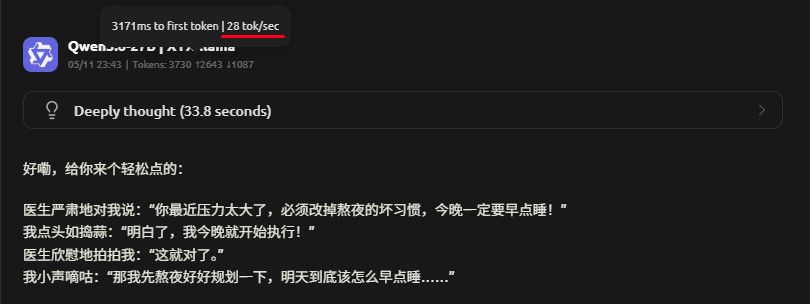
Rocm 开MTP
Vulkan 不开MTP
Vulkan 开MTP
ctx:256k
 `
`
ctx:4k
@David-Zhang 我靠发力了啊。
-
-
我只希望没买卡的 规避7900XTX。小霸王学习机吗?
@williamlouis 分享下遇到的坑,让大伙吃个瓜
-
@iamvirus 我最近也再测 omnicoder-9b,目前效果不错,前端后端 指哪打哪,速度也很快。干复杂的屎山目前看还是得 27b,慢就慢点,只能同时多开几个任务。
-
我只希望没买卡的 规避7900XTX。小霸王学习机吗?
@williamlouis
为啥?
我感觉挺好,这是穷人玩AI的最佳选择
玩3090 怕遇到矿卡
再往上就不是穷人了。 -
没有完全按楼主提供的模型,只是增加了mmproj,感觉7900 不到30t/s,不知道Hermis怎么样。“/home/devin/work/llama.cpp-turboquant/build/bin/llama-server
-m /home/devin/work/models/Qwen3.6-27B-Q4_K_M.gguf
--mmproj /home/devin/work/models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
--host 0.0.0.0
--port 8081
--n-gpu-layers 999
--ctx-size 262144
--batch-size 2048
--ubatch-size 768
--threads 8
--temp 1.0
--top-p 0.95
--top-k 20
--min-p 0.00
--presence_penalty 1.5
--cache-type-k turbo3
--cache-type-v turbo3”
