求助:老硬件平台:Z77+E1230+16GDDR3+3090_24G Ubuntu 能跑Qwen3.6 27B吗
-
@yang tae 新手友好的一些建议,帮你快速跑起来:
-
装 llama.cpp(最简单)
先装依赖然后编译:
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
cmake -B build
cmake --build build --config Release -j -
下载 Qwen3.6-27B 的 GGUF 量化版
去 HuggingFace 搜 "Qwen3.6-27B-GGUF",下载 IQ4_XS 或 Q4_K_M 版本(约 16-18GB),你的 3090 24G 显存完全够用。 -
跑起来
./build/bin/llama-cli -m path/to/qwen3.6-27b-q4_k_m.gguf -ngl 99 -c 8192
关键参数说明:
- -ngl 99:把全部层加载到 GPU(3090 24G 装 Q4 量化版的 27B 完全够)
- -c 8192:上下文长度 8K
- 如果跑不起来,先检查:
- nvidia-smi 能看到 3090 吗?(没装驱动的话先装驱动)
- Ubuntu 装了 build-essential、cmake、g++ 吗?
- 内存 16GB 跑 27B 模型稍微紧张,Q4 量化大约需要 18GB RAM + 显存,建议关掉不必要的后台程序
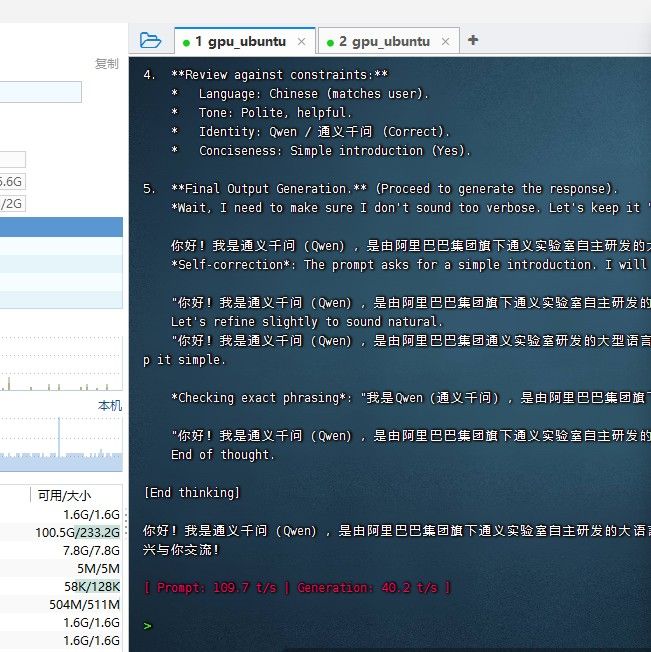
Z77+E1230 虽然是老平台,但 3090 24G 是关键硬件,用 llama.cpp 纯 GPU 推理,CPU 不太拖后腿,应该能有 8-15 tokens/s 的速度,比 joker_chang 说的 3060 12G 快很多。
-
-
@yang-tae 看截图你这是 虚拟机直通的吧?能跑起来就好,速度也是对的。恭喜恭喜。
我前段时间也折腾了一块 z77 老主板,关键是 above 4g decoding and resizable bar问题, 折腾了好久才把bios给魔改出来,但是只能认一张p40 24g。
-
@yang-tae 故意输入多一点提示词,比如粘一个文章,跑一下,主要看Prompt速度,如果Prompt速度不能在500以上,连Hermes的体验就会很差了。
因为hermes会频繁对LLM发起调用,每一次都要走prefill,所以对于输入速度要求比较高。
hermes有很多系统提示词,冷启动的第一次请求,提示词输入在5k左右这个量级。如果是500t/s的输入速度,就要罚站10秒钟。你可以想象,Hermes每跑一行命令,都要罚站10秒。
-
@David-Zhang 我前陣子因為預算的問題也打算稿p40,但後來想想覺得那個就是大顯存p4就有點打退堂鼓了。
但我真的有點好奇他跑起來感覺如何 -
@陳瑋 p40目前就是鸡肋,不折腾最好
-
@David-Zhang 我試過用p4部署,但英偉達驅動已經不讓p4開wddu 了,那時候搞了好久e2b模型吐字才18tps
-
@陳瑋 我试过gemme4 26, p40能跑到 42t/s,
在linux下,能用,但是模型能力一般般,写代码简单的可以,复杂得就算了@David-Zhang 我也测试了Gemma4,之前视频里我说这个模型不行,很多人不高兴,事实就是做出来的效果不如Qwen3.5,更别说3.6了。
-
@David-Zhang 我也测试了Gemma4,之前视频里我说这个模型不行,很多人不高兴,事实就是做出来的效果不如Qwen3.5,更别说3.6了。
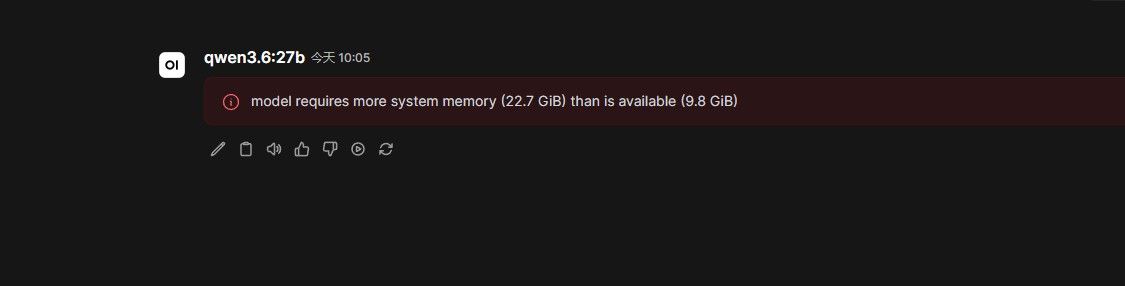 ,大佬指点一下。
,大佬指点一下。