
部署llm用于写代码,构建本地项目
-
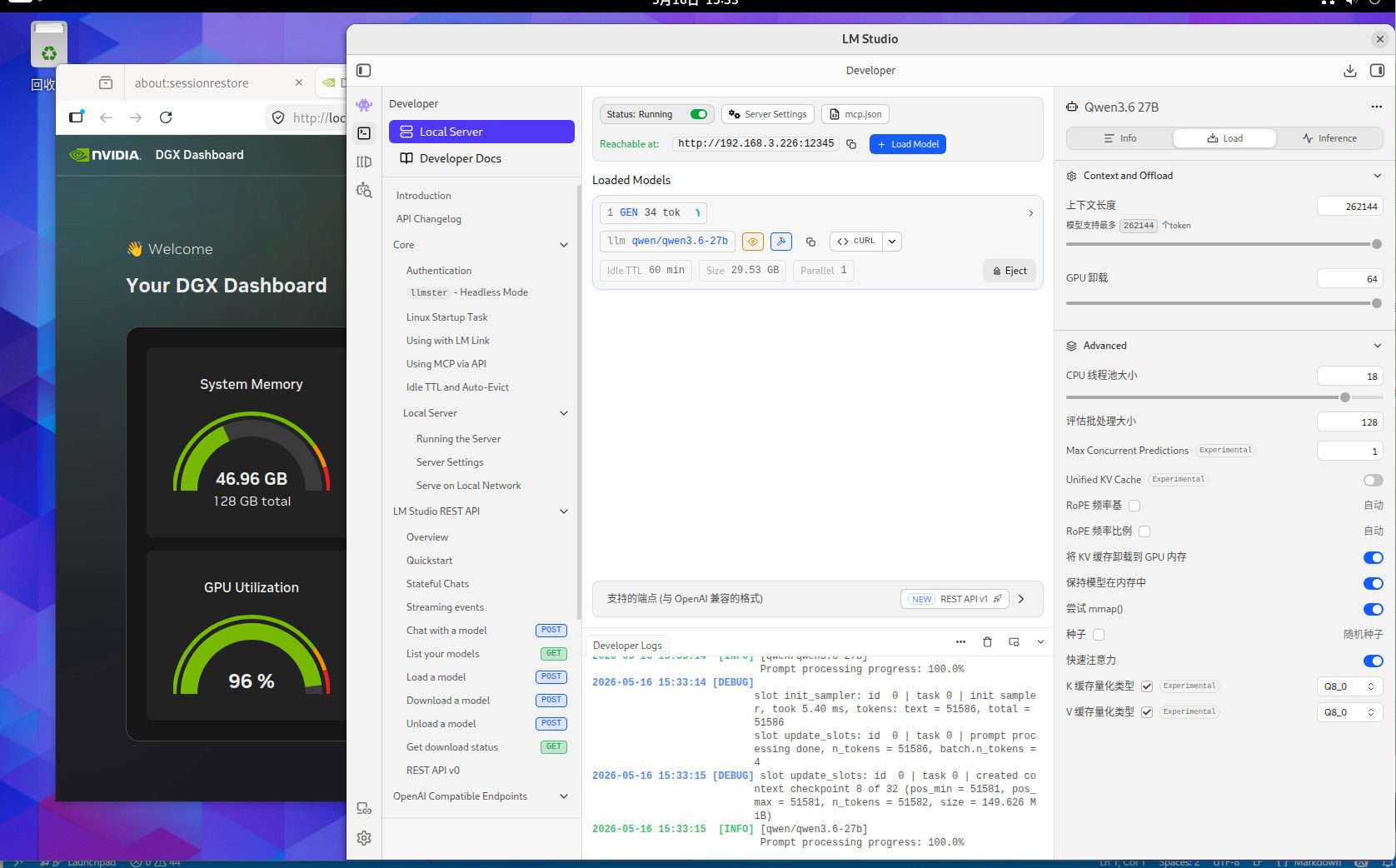
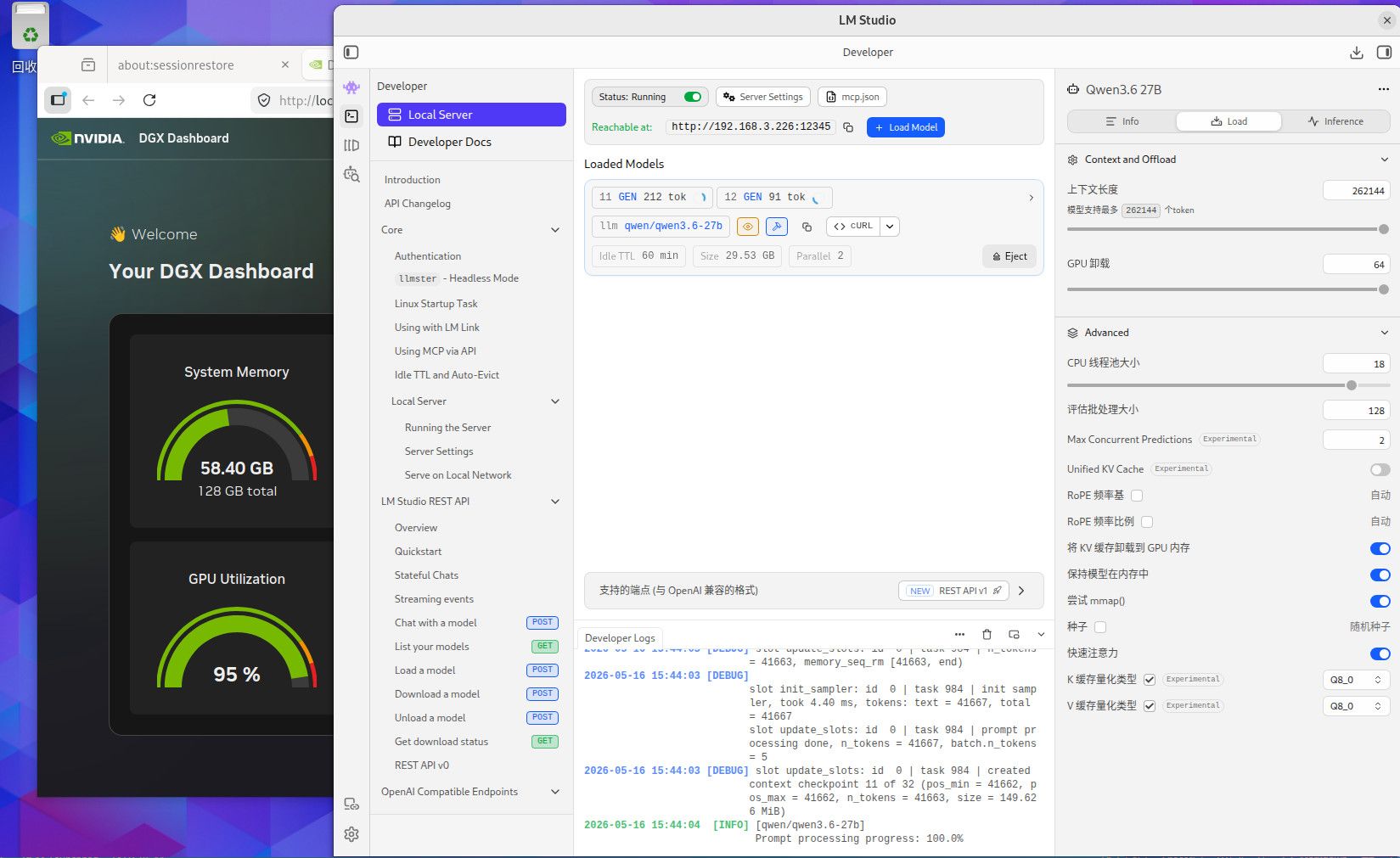
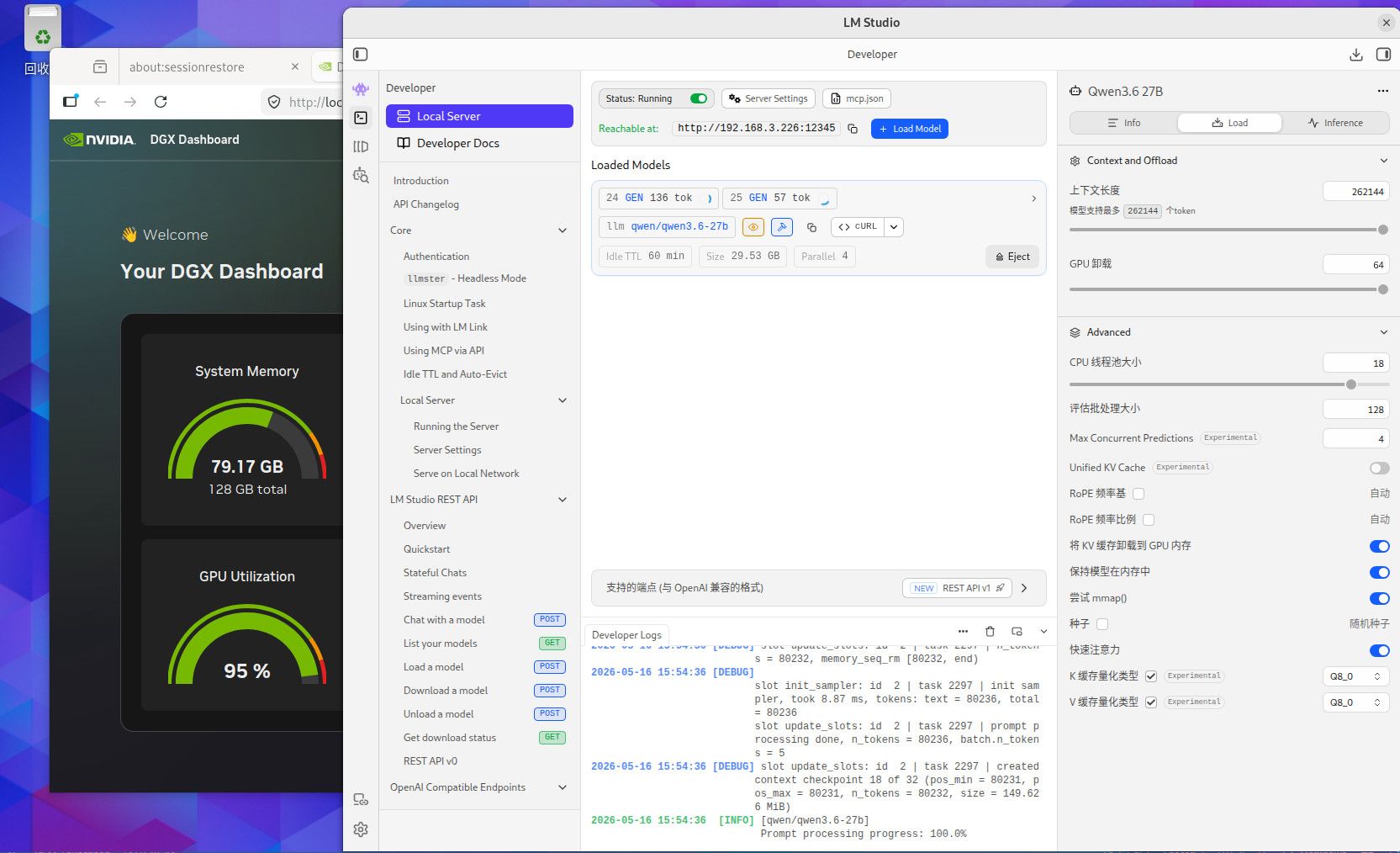
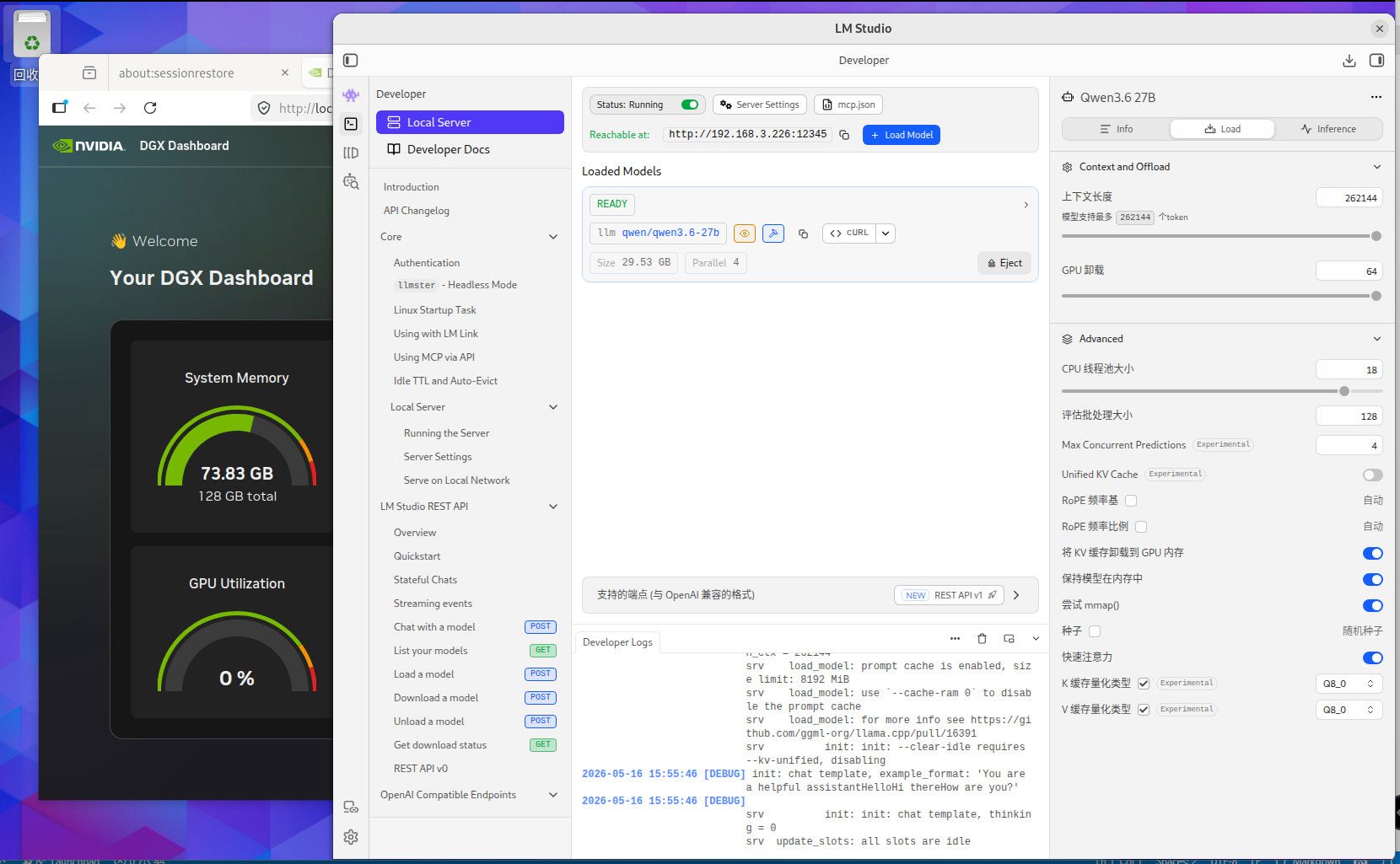
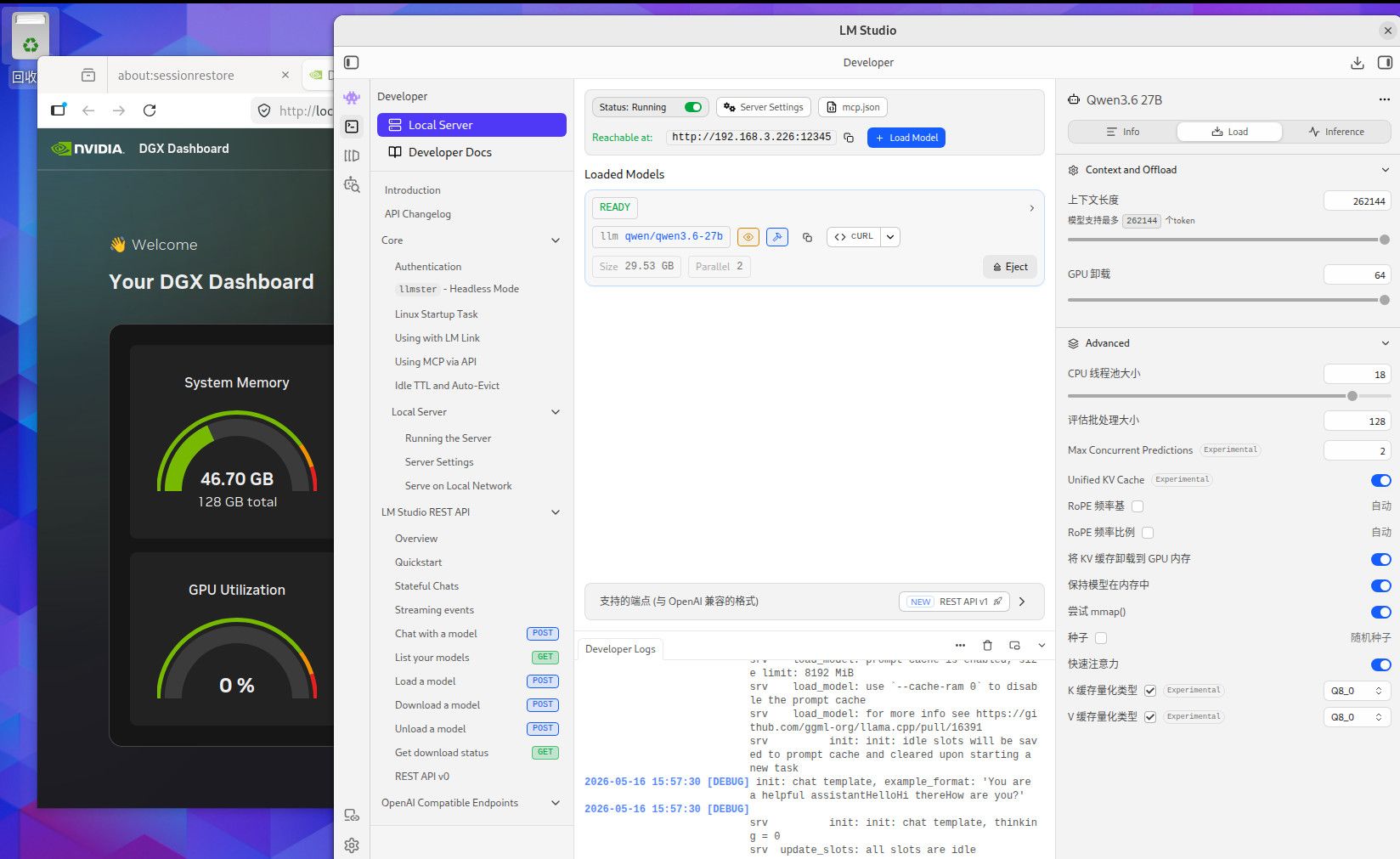
这个是256K TOKEN 全Q8精度的内存使用情况,用你们最爱的qwen3.6-27B,你自己参考吧。这个模型我也不知道你们为什么这么喜欢。要是编程的话,你要用Q4的话就用吧,反正模型要是一本正经的胡说八道,或者长文文本的时候丢失数据,你就会患上精度恐惧症了。当然满血大模型也有这个毛病,只要你能在程序中控制的住就行。因为是多次反复长文本交互,基本上就是精度越低毛病越多。这些128G MAC AMD NV的小机方案就是让你满血跑本地小模型用的,别的也没什么用。要是和这个本地满血小模型死磕了就加10000 买NV的128G机器,反正最后程序不成功你也赖不到模型。你要是说你想兼顾的话,显卡怎么也要有48G把,amd 和MAC的小机的话, AMD 的小机基本符合你的预算。64G 和128G 的问题 ,就是别让显存成为瓶颈。显存直接卡死了你的模型和精度,GPU 慢点就慢点,至少高精度还能跑。你单线程跑64G你随意,要是多线程跑128G基本是必须,当然咱们这些丐版设备也支持不了几个并发,只是多一个并发不就是多平分了一部分成本吗。
-
还有一点值得补充,Coding这个场景,算是对于量化比较敏感的场景。有个对于量化质量的专用参数:Mean KL Divergence。可以理解为量化后的模型和全尺寸模型的“差异”
根据unsloth的数据,Qwen3.6系列的量化失真,大概是下图中绿色的点:
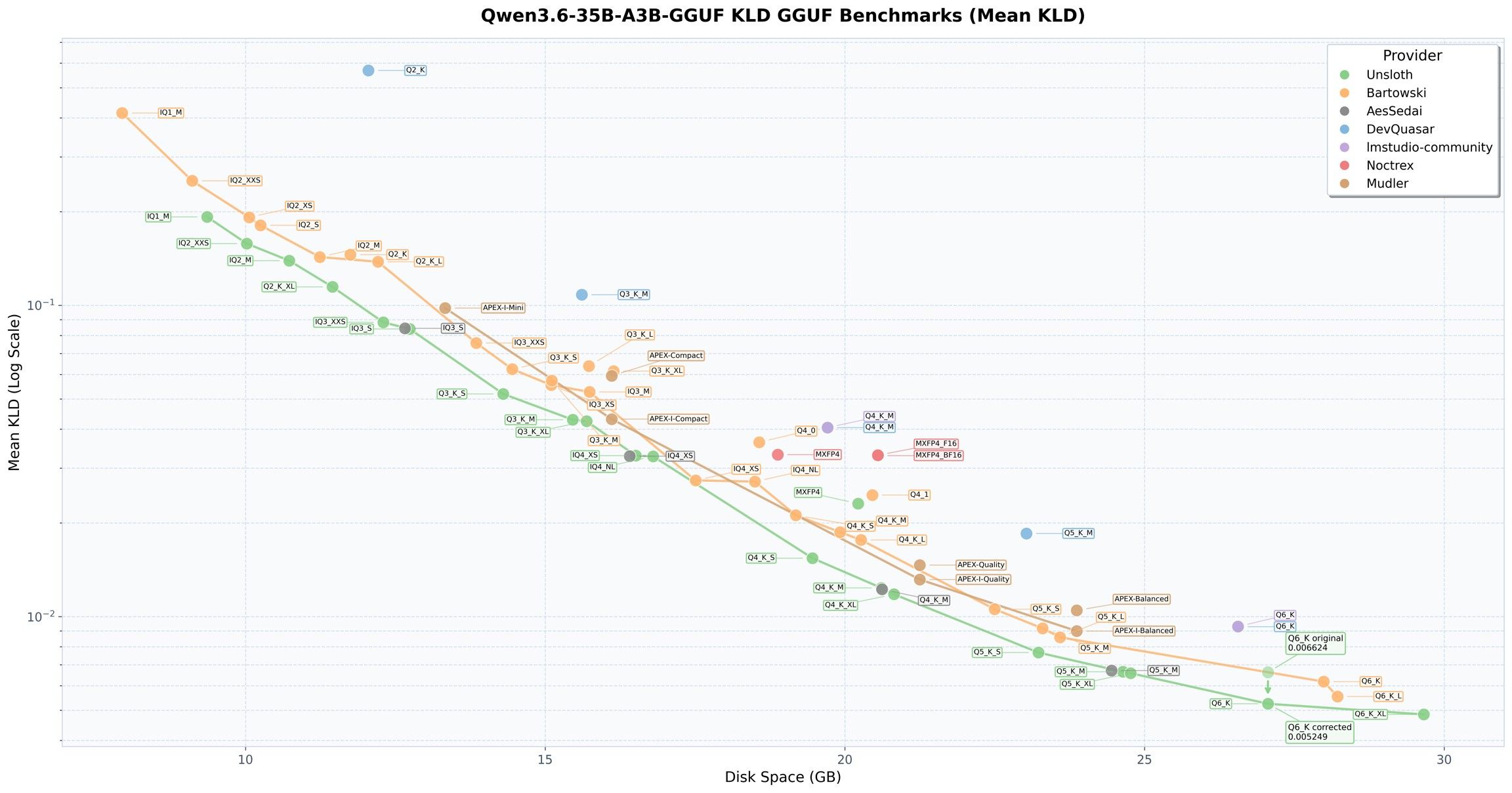
可以理解为,Q2量化和Q6量化之间,插了一个数量级的差异。当然,严谨来讲,这个“差异”也不完全是往坏的差异。就跟你买彩票,你输错了号码也一样能中奖。
但是从控制变量,生产环境的稳定性的角度,还是要以贴近全量模型为目标。 -
问下,我的笔记本mac他的显存可以给到23gb左右,我发现4bit量化的qwen 3.6 27b明显强于qwen 3.5 9b 8bit换成3.5也类似。我只有2w rmb的预算是在买个mac 64gb还是上英伟达显卡,算了装台湾人上辉达显卡还是mac,2w人民币预算。我不想折腾Claude,封号太严重了,Gemini确实生成代码质量不太高,而且客户要求隐私。
此主題已被删除! -
还有一点值得补充,Coding这个场景,算是对于量化比较敏感的场景。有个对于量化质量的专用参数:Mean KL Divergence。可以理解为量化后的模型和全尺寸模型的“差异”
根据unsloth的数据,Qwen3.6系列的量化失真,大概是下图中绿色的点:
可以理解为,Q2量化和Q6量化之间,插了一个数量级的差异。当然,严谨来讲,这个“差异”也不完全是往坏的差异。就跟你买彩票,你输错了号码也一样能中奖。
但是从控制变量,生产环境的稳定性的角度,还是要以贴近全量模型为目标。 -
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
编程的话还是不建议用本地模型,尤其是对接 claude code 或 open code 这类编程代理工具,prefill 的速度慢的让人无法忍受。即使上 5090 ,prefill 3000+ , 本地编程模型的水平也实在一般,即使是 qwen3.6-27B 的编程水平也只是凑乎能用而已。
编程的话还是不建议用本地模型,尤其是对接 claude code 或 open code 这类编程代理工具,prefill 的速度慢的让人无法忍受。即使上 5090 ,prefill 3000+ , 本地编程模型的水平也实在一般,即使是 qwen3.6-27B 的编程水平也只是凑乎能用而已。
这个说的很对啊,你有什么理由必须在本地部署编程模型呢。现在所有的小模型都算上,你本地部署就算是满血的,你也要对这些小模型做高度的限制适配,能力也就那样。就那点隐私,人家大公司我觉得才不在乎这个呢。唯一的需求就是云端没有这个模型,你偏要用。那你本地用,就回到了精度和适配上来了。搞了设备仅仅只是开始,我现在什么都没干,每次先填进100K的流程和限制文档,尤其是我用的这种越狱模型他抹除的不是你认为的限制,是真正模型中的所有限制。
现在看来咱们这些消费级设备,就能干两件事事情比较靠谱:1,用显卡生成视频,2,用128G小机满血跑自定义模型。 用128G小机满血跑自定义模型,其实这个绝大数编程的人也根本用不到。 -
还有一点值得补充,Coding这个场景,算是对于量化比较敏感的场景。有个对于量化质量的专用参数:Mean KL Divergence。可以理解为量化后的模型和全尺寸模型的“差异”
根据unsloth的数据,Qwen3.6系列的量化失真,大概是下图中绿色的点:
可以理解为,Q2量化和Q6量化之间,插了一个数量级的差异。当然,严谨来讲,这个“差异”也不完全是往坏的差异。就跟你买彩票,你输错了号码也一样能中奖。
但是从控制变量,生产环境的稳定性的角度,还是要以贴近全量模型为目标。感謝大大,數據非常詳盡

-
我可以这么搞吗,本地Hermes用本地部署的qwen 3.6 27b -4bit,然后computer use 云端的比如Gemini,财力有限不敢搞opus和chatgpt,我觉着不能让AI主导。
-
还有一点值得补充,Coding这个场景,算是对于量化比较敏感的场景。有个对于量化质量的专用参数:Mean KL Divergence。可以理解为量化后的模型和全尺寸模型的“差异”
根据unsloth的数据,Qwen3.6系列的量化失真,大概是下图中绿色的点:
可以理解为,Q2量化和Q6量化之间,插了一个数量级的差异。当然,严谨来讲,这个“差异”也不完全是往坏的差异。就跟你买彩票,你输错了号码也一样能中奖。
但是从控制变量,生产环境的稳定性的角度,还是要以贴近全量模型为目标。@王一民 最低Q4以下的不要尝试,问题太多,我踩过坑。
-
系统 于 取消固定此主题