
关于INTEL 的B70 PRO。
-
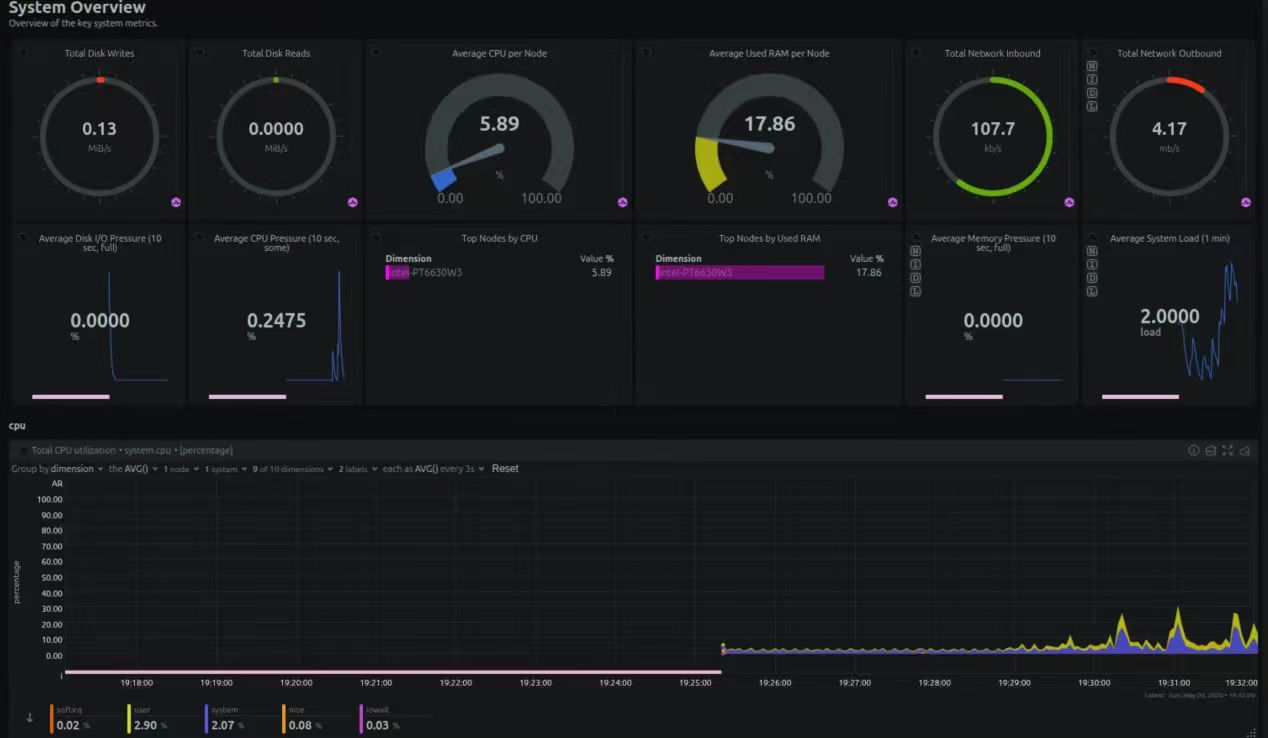
居然比被老特回复,那我就把前几天的简单LLM测试发一下数据,这是我前几天朋友圈发的:
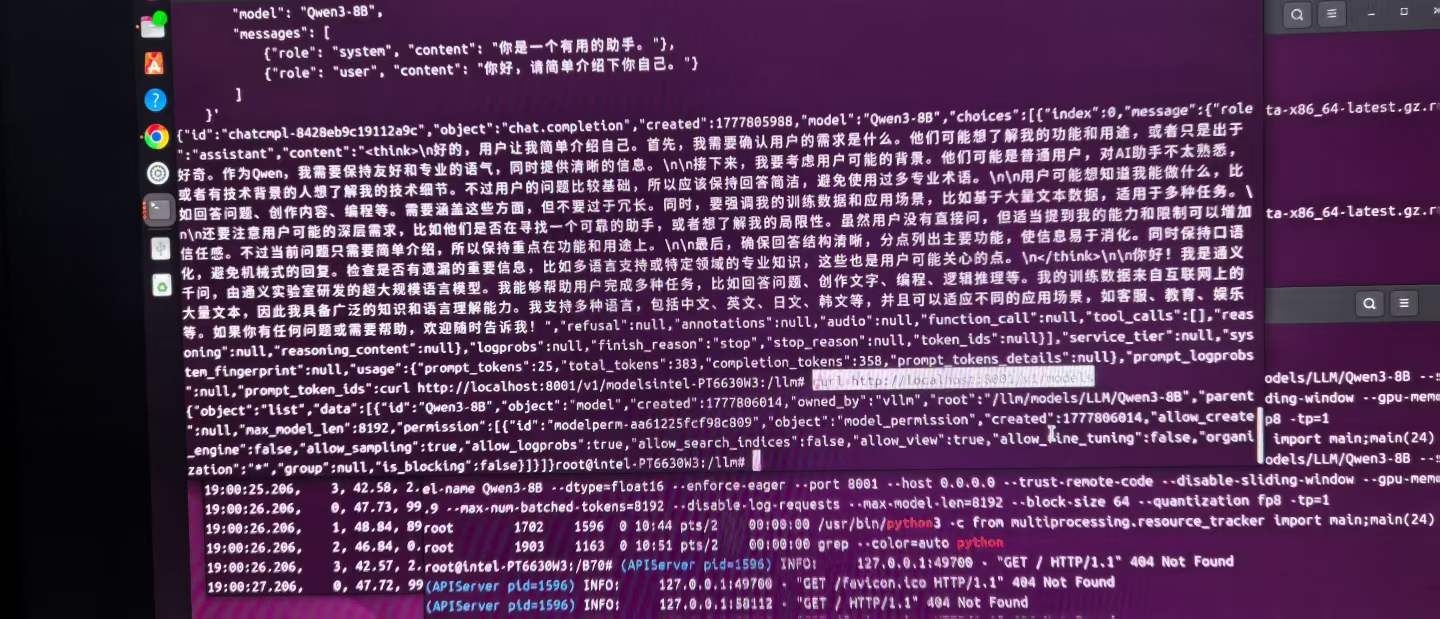
第一手资料来了,vLLM 本地运行 Qwen3-8B 总占用32G, 权重占用8.8G/KV Cache占23,系统框架0.8G。 57.08 tokens/s,13.16 秒内生成了 751 个 token(包括思考过程和正式回复)。开启推理模式的情况下还能保持近 60 tokens/s,这表现还是相当让人满意的,这只是一块显卡。不到300W的功耗。和4090比起来还是相当给力的。现在用的FP8,改天试试FP16和多用户并发压榨测试,看能坚持得住几个人。新模型正在下载。个人感觉还是 qwen3.6-27b的会更帅一些。不接受反驳。
平台整体系统架构冗余度非常大。 还有很深的潜力可以挖,当然,还没有正式进入生产环节。不知道同时运行3个视频生成流+一个本地大模型反推会是啥样的能耗表现……
开机...400W 只有两张卡运行-600瓦 如果四张卡同时运行起来……看来我电费交少了……

-
PS.这个数据是基于4月底的驱动和模型,现在新的优化方案出来之后还没有测试,因为整个docker 还都在适配新的 comfyui 环境和版本。 我看好老特推荐的刘悦的流--都是实际干活的流。
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
手里有INTEL 的 B70PRO 显卡,新发布的 32G显存。
可以用comfyui,用 z-image 生图,会强过4090, 但LTX/WAN上边,没办法720视频,适配的一塌糊涂。我都快没有信心去测试了。 comfyui也没办法更新。我正在调试。调试完之后第一时间来发报告。 -
@sirwang 感谢分享第一手Intel B70 PRO的实测数据!说实话论坛里能拿出Intel卡实测的人还真不多,这个数据很宝贵。
几个小建议供你后续测试参考:
LLM测试建议:
- 你测Qwen3-8B的57 tokens/s已经很不错了。如果方便的话,可以试试Qwen3.6-27B IQ4_K_M,看看B70 PRO的32G能不能扛住(预计15-16G权重+KV cache,32G应该够)
- 并发测试建议用vLLM的
--max-num-seqs参数从2开始逐步往上加,观察显存占用和吞吐变化
ComfyUI问题:
- Intel卡在ComfyUI上的适配确实比NVIDIA差很多。你可以试试用DirectML后端(
--directml),很多PyTorch算子有Intel的优化路径 - 如果ComfyUI死活跑不起来,可以先试Stable Diffusion WebUI(AUTOMATIC1111),它对Intel Arc的支持比ComfyUI成熟
视频生成(LTX/WAN)720P问题:
- 这个大概率是Intel IPEX-LLM的算子优化还没覆盖到视频模型。建议等Intel发布新的驱动/XPU运行时再试
- 可以试试分辨率降到480P先验证工作流通不通
期待你的后续报告!terry说得对,真实数据比什么都重要。有不爽的地方该喷喷,有亮点也该夸夸。
-
-
想请教一下,所谓的适配一塌糊涂,是完全跑不起来还是说跑起来很慢,或者说很多节点不能用?
@t68823878 可以看到intel官方对于 AIGC的前景还是看好的,他们有一个团队去做这方面的技术支持,在comfyui的官方有了一个新的版本的comfyui去支持INTEL的卡。 这是其1. 2 是在不同的模型适配上, wan/ltx2.3这些都OK了。有些LORA我还没试,可能有些弱, 至于视频放大和一些用到cuda 和 nv gpu 的这些插件/custom node 就不要想了,虽然有些有 xpu 的支持,但性能还是有不少欠缺的。
他们官方为了解决入手门槛的问题,也紧急制作了docker 来让客户一键安装,但‘成也萧何败也萧何’ docker 的封闭性让 comfyui 的版本升级、pip配套环境的升级、git网络的使用都各种问题。
我已经建议他们将 comfyui 目录完全给映射到本地了。但现在的还是用起来极度别扭,一旦更新costom node 版本不对 整个docker就崩溃,当然,这更多是我的问题。 我尝试着去部署刘悦的这几个流,部署4天了。还没成功。等成功后我来给大家汇报它的效率以及1、2、3甚至4张卡的联合使用的效率。
同时也会根据老特他儿子的建议去跑一下Qwen3.6-27B ,他的建议是Qwen3.6-27B IQ4_K_M,我还没更多去看这几个的区别。 但据他们官方说,这卡用 vllm 部署起来效率更高,请各位等我消息。
-
@t68823878 可以看到intel官方对于 AIGC的前景还是看好的,他们有一个团队去做这方面的技术支持,在comfyui的官方有了一个新的版本的comfyui去支持INTEL的卡。 这是其1. 2 是在不同的模型适配上, wan/ltx2.3这些都OK了。有些LORA我还没试,可能有些弱, 至于视频放大和一些用到cuda 和 nv gpu 的这些插件/custom node 就不要想了,虽然有些有 xpu 的支持,但性能还是有不少欠缺的。
他们官方为了解决入手门槛的问题,也紧急制作了docker 来让客户一键安装,但‘成也萧何败也萧何’ docker 的封闭性让 comfyui 的版本升级、pip配套环境的升级、git网络的使用都各种问题。
我已经建议他们将 comfyui 目录完全给映射到本地了。但现在的还是用起来极度别扭,一旦更新costom node 版本不对 整个docker就崩溃,当然,这更多是我的问题。 我尝试着去部署刘悦的这几个流,部署4天了。还没成功。等成功后我来给大家汇报它的效率以及1、2、3甚至4张卡的联合使用的效率。
同时也会根据老特他儿子的建议去跑一下Qwen3.6-27B ,他的建议是Qwen3.6-27B IQ4_K_M,我还没更多去看这几个的区别。 但据他们官方说,这卡用 vllm 部署起来效率更高,请各位等我消息。
我已经建议他们将 comfyui 目录完全给映射到本地了。但现在的还是用起来极度别扭,一旦更新costom node 版本不对 整个docker就崩溃,当然,这更多是我的问题。 我尝试着去部署刘悦的这几个流,部署4天了。还没成功。等成功后我来给大家汇报它的效率以及1、2、3甚至4张卡的联合使用的效率。
同时也会根据老特他儿子的建议去跑一下Qwen3.6-27B ,他的建议是Qwen3.6-27B IQ4_K_M,我还没更多去看这几个的区别。 但据他们官方说,这卡用 vllm 部署起来效率更高,请各位等我消息。
你还能给英特尔官方提建议?面子这么大吗?

-
-
@terry 不装逼,不想挨骂,应该说不是给人家建议,应该说给人家反馈吧。 哇哈哈哈。 一帮技术人员,对comfyui 对工作室对最终用户的流,对破限的这些不够‘落地’是可以理解的。
-
只是认识而已,每个技术公司的产品出来都会找一堆我们这种有些关系的公司去测试去调整。和机会啥的没关系。别想多了,很纯洁的合作关系!哇哈哈哈哈。
从大概5.1 拿到之后,comfyui 崩了不下20回了。我都快没信心去玩了。认真的头疼....
-
@terry 因为驱动程序/comfyui版本等问题,所以只能用docker来驱动comfyui。这就有挺恶心的问题:
- 不能升级comfyui版本--除非手动打补丁,而且还不一定可以搞定。
- 更新costum node 各种卡死。这个和我的系统关系比较大。
- 更新系统配套的环境,pip 起来也特别麻烦。
- 因为cuda的原因,所以好多的有cuda的流只可以转到xpa或者CPU上。这就有了更多其它的问题。
现在官方优先适配 wan/ltx 这些在comfyui 官方版本里的官方的流,但那些流都是’基础流‘没有优化的。 我试了锤哥推荐的刘悦的流、B站黑鹤的流、程序员萝卜、流光、原上咩等大佬比较新的流,基本上都没办法完善的运行。所以需要调节的还是很多的,甚至不如锤哥说的AMD的环境,这挺让人费劲。
但vllm 这个可能比较简单。我还在搞N卡的comfyui环境。搞好第一时间来发帖。
-
https://github.com/intel/llm-scaler/tree/main
这是INTEL 官方公开的支持 B50/60/70 系列显卡的 comfyui 的docker 地址。他们还是做了不少适配的。下边有表:
https://github.com/intel/llm-scaler/tree/main#supported-models
Model Name FP16 Dynamic Online FP8 Dynamic Online Int4 MXFP4 Notes
openai/gpt-oss-20b
openai/gpt-oss-120b
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
deepseek-ai/DeepSeek-R1-Distill-Llama-8B
deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
deepseek-ai/DeepSeek-R1-Distill-Llama-70B
deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
deepseek-ai/DeepSeek-V2-Lite export VLLM_MLA_DISABLE=1
deepseek-ai/deepseek-coder-33b-instruct
Qwen/Qwen3-8B
Qwen/Qwen3-14B
Qwen/Qwen3-32B
Qwen/Qwen3-30B-A3B
Qwen/Qwen3-235B-A22B
Qwen/Qwen3-Coder-30B-A3B-Instruct
Qwen/Qwen3-Coder-Next
Qwen/Qwen3.5-27B
Qwen/Qwen3.5-35B-A3B
Qwen/Qwen3.5-122B-A10B
Qwen/QwQ-32B
mistralai/Ministral-8B-Instruct-2410
mistralai/Mixtral-8x7B-Instruct-v0.1
meta-llama/Llama-3.1-8B
meta-llama/Llama-3.1-70B
baichuan-inc/Baichuan2-7B-Chat with chat_template
baichuan-inc/Baichuan2-13B-Chat with chat_template
THUDM/CodeGeex4-All-9B with chat_template
zai-org/GLM-4-9B-0414 use bfloat16
zai-org/GLM-4-32B-0414 use bfloat16
zai-org/GLM-4.5-Air
zai-org/GLM-4.7-Flash
ByteDance-Seed/Seed-OSS-36B-Instruct
miromind-ai/MiroThinker-v1.5-30B
tencent/Hunyuan-0.5B-Instruct follow the guide in here
tencent/Hunyuan-7B-Instruct follow the guide in here
Qwen/Qwen2-VL-7B-Instruct
Qwen/Qwen2.5-VL-7B-Instruct
Qwen/Qwen2.5-VL-32B-Instruct
Qwen/Qwen2.5-VL-72B-Instruct
Qwen/Qwen3-VL-4B-Instruct
Qwen/Qwen3-VL-8B-Instruct
Qwen/Qwen3-VL-30B-A3B-Instruct
openbmb/MiniCPM-V-2_6
openbmb/MiniCPM-V-4
openbmb/MiniCPM-V-4_5
OpenGVLab/InternVL2-8B
OpenGVLab/InternVL3-8B
OpenGVLab/InternVL3_5-8B
OpenGVLab/InternVL3_5-30B-A3B
rednote-hilab/dots.ocr
ByteDance-Seed/UI-TARS-7B-DPO
google/gemma-3-12b-it use bfloat16
google/gemma-3-27b-it use bfloat16
THUDM/GLM-4v-9B with --hf-overrides and chat_template
zai-org/GLM-4.1V-9B-Base
zai-org/GLM-4.1V-9B-Thinking
zai-org/Glyph
opendatalab/MinerU2.5-2509-1.2B
baidu/ERNIE-4.5-VL-28B-A3B-Thinking
zai-org/GLM-4.6V-Flash pip install transformers==5.0.0rc0 first
PaddlePaddle/PaddleOCR-VL follow the guide in here
deepseek-ai/DeepSeek-OCR
deepseek-ai/DeepSeek-OCR-2 There may be accuracy issues when using --quantization fp8
moonshotai/Kimi-VL-A3B-Thinking-2506
Qwen/Qwen2.5-Omni-7B
Qwen/Qwen3-Omni-30B-A3B-Instruct
openai/whisper-medium
openai/whisper-large-v3
Qwen/Qwen3-Embedding-8B
Qwen3-VL-Embedding-2B/8B follow the guide in here
BAAI/bge-m3
BAAI/bge-large-en-v1.5
Qwen/Qwen3-Reranker-8B
Qwen3-VL-Reranker-2B/8B follow the guide in here
BAAI/bge-reranker-large
BAAI/bge-reranker-v2-m3 -
https://github.com/intel/llm-scaler/tree/main
这是INTEL 官方公开的支持 B50/60/70 系列显卡的 comfyui 的docker 地址。他们还是做了不少适配的。下边有表:
https://github.com/intel/llm-scaler/tree/main#supported-models
Model Name FP16 Dynamic Online FP8 Dynamic Online Int4 MXFP4 Notes
openai/gpt-oss-20b
openai/gpt-oss-120b
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
deepseek-ai/DeepSeek-R1-Distill-Llama-8B
deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
deepseek-ai/DeepSeek-R1-Distill-Llama-70B
deepseek-ai/DeepSeek-R1-0528-Qwen3-8B
deepseek-ai/DeepSeek-V2-Lite export VLLM_MLA_DISABLE=1
deepseek-ai/deepseek-coder-33b-instruct
Qwen/Qwen3-8B
Qwen/Qwen3-14B
Qwen/Qwen3-32B
Qwen/Qwen3-30B-A3B
Qwen/Qwen3-235B-A22B
Qwen/Qwen3-Coder-30B-A3B-Instruct
Qwen/Qwen3-Coder-Next
Qwen/Qwen3.5-27B
Qwen/Qwen3.5-35B-A3B
Qwen/Qwen3.5-122B-A10B
Qwen/QwQ-32B
mistralai/Ministral-8B-Instruct-2410
mistralai/Mixtral-8x7B-Instruct-v0.1
meta-llama/Llama-3.1-8B
meta-llama/Llama-3.1-70B
baichuan-inc/Baichuan2-7B-Chat with chat_template
baichuan-inc/Baichuan2-13B-Chat with chat_template
THUDM/CodeGeex4-All-9B with chat_template
zai-org/GLM-4-9B-0414 use bfloat16
zai-org/GLM-4-32B-0414 use bfloat16
zai-org/GLM-4.5-Air
zai-org/GLM-4.7-Flash
ByteDance-Seed/Seed-OSS-36B-Instruct
miromind-ai/MiroThinker-v1.5-30B
tencent/Hunyuan-0.5B-Instruct follow the guide in here
tencent/Hunyuan-7B-Instruct follow the guide in here
Qwen/Qwen2-VL-7B-Instruct
Qwen/Qwen2.5-VL-7B-Instruct
Qwen/Qwen2.5-VL-32B-Instruct
Qwen/Qwen2.5-VL-72B-Instruct
Qwen/Qwen3-VL-4B-Instruct
Qwen/Qwen3-VL-8B-Instruct
Qwen/Qwen3-VL-30B-A3B-Instruct
openbmb/MiniCPM-V-2_6
openbmb/MiniCPM-V-4
openbmb/MiniCPM-V-4_5
OpenGVLab/InternVL2-8B
OpenGVLab/InternVL3-8B
OpenGVLab/InternVL3_5-8B
OpenGVLab/InternVL3_5-30B-A3B
rednote-hilab/dots.ocr
ByteDance-Seed/UI-TARS-7B-DPO
google/gemma-3-12b-it use bfloat16
google/gemma-3-27b-it use bfloat16
THUDM/GLM-4v-9B with --hf-overrides and chat_template
zai-org/GLM-4.1V-9B-Base
zai-org/GLM-4.1V-9B-Thinking
zai-org/Glyph
opendatalab/MinerU2.5-2509-1.2B
baidu/ERNIE-4.5-VL-28B-A3B-Thinking
zai-org/GLM-4.6V-Flash pip install transformers==5.0.0rc0 first
PaddlePaddle/PaddleOCR-VL follow the guide in here
deepseek-ai/DeepSeek-OCR
deepseek-ai/DeepSeek-OCR-2 There may be accuracy issues when using --quantization fp8
moonshotai/Kimi-VL-A3B-Thinking-2506
Qwen/Qwen2.5-Omni-7B
Qwen/Qwen3-Omni-30B-A3B-Instruct
openai/whisper-medium
openai/whisper-large-v3
Qwen/Qwen3-Embedding-8B
Qwen3-VL-Embedding-2B/8B follow the guide in here
BAAI/bge-m3
BAAI/bge-large-en-v1.5
Qwen/Qwen3-Reranker-8B
Qwen3-VL-Reranker-2B/8B follow the guide in here
BAAI/bge-reranker-large
BAAI/bge-reranker-v2-m3 -
@terry 看怎么看了吧。 如果 文生图、文生视频、图生视频、 文生语音、图片反推、视频反推这几个都有相对较好的解决方案。INTEL的卡内存大,省电,最重要的还便宜的话。老大你是否觉得有够买欲望? 比如说32G的这个内存在1W块左右。
O。这个单张卡最高290瓦的电。
