Lucebox DFlash + PFlash 7900XTX Qwen3.6-27B ~2.8–3.1x加速 测试数据分享
-
关注 Lucebox 有几周了,终于最近AMD HIP backend 实现了 DFlash
https://github.com/Luce-Org/lucebox-hub
原帖: https://www.lucebox.com/blog/amd然后我本地让opencode跑了下,单卡7900XTX,q8,q4,tq3, 256k ctx,结果如下:
Lucebox DFlash + PFlash 复现报告 (RX 7900 XTX)
硬件环境
项目 规格 GPU AMD Radeon RX 7900 XTX (Navi 31, gfx1100) 显存 24 GiB GDDR6 (~936 GB/s) 系统内存 62 GiB DDR5 ROCm 7.1 系统 Ubuntu 26.04, Linux 7.0.0-14-generic 基准测试结果
模型: Qwen3.6-27B Q4_K_M (15.65 GiB)
Draft模型对比: 测试了两个 DFlash Draft模型:
- Lucebox Q8_0 (1.84 GiB, 官方) —
dflash-draft-3.6-q8_0.gguf - spiritbuun Q4_K_M (1.03 GiB, 社区) —
dflash-draft-3.6-q4_k_m.gguf
结论: Q4 Draft 未带来性能提升。在 7900 XTX 上:
- Draft计算阶段 Q4 反而更慢 (31.43 ms vs 27.46 ms) — Q4 反量化开销 + 可能较差的 kernel 优化
- 验证阶段 (target forward) 完全一致 (~68.8 ms)
- Q4 Draft的接受率略有下降 (AL 4.69 vs 4.93)
所有后续测试均使用官方 Lucebox Q8_0 Draft。
Short-Prompt Decode (HumanEval, ~125 tok prompt, n_gen=128)
配置 KV 缓存 平均 tok/s 平均 AL 加速比 (vs llama.cpp HIP) llama.cpp HIP AR — 28.07 — 1.00x DFlash (标准链式推测) Q8_0 64.23 5.36 2.29x DFlash DDTree budget=8 Q8_0 62.75 4.93 2.24x DFlash DDTree budget=8 tq3_0 68.64 5.57 2.44x DFlash DDTree budget=22 Q8_0 60.94 6.11 2.17x Multi-Context Sweep (PFlash Prefill + DFlash Decode)
在不同上下文长度下,使用 PFlash 预填充(rocWMMA Phase 2)+ DFlash DDTree (budget=8) 解码,对比 llama.cpp HIP AR。
KV cache 使用 Q8_0(4K–64K)或 Q4_0(128K)量化以节省显存。
预填充性能 (tok/s)
上下文 llama.cpp HIP (AR) Lucebox (PFlash) 加速比 备注 128 619.51 312.5 0.50x PFlash 短上下文开销大 4K 734.57 726 (Q8 KV) 0.99x 持平 16K 649.08 735 (Q8 KV) 1.13x 64K —¹ 733 (Q8 KV) — ¹llama.cpp context 创建 OOM 128K —¹ 730 (Q4 KV) — 192K —¹ 730 (Q4 KV) — 256K —¹ 730 (Q4 KV + Q4 draft / tq3_0 KV + Q8 draft / tq3_0 KV + Q4 draft) — ¹ AR prefill 在 64K+ 无法运行,因为 llama.cpp 在 context 创建时就需要分配完整 KV cache(O(n²) 注意力 + 全量 KV 存储),64K Q4 KV 约 8 GiB + 模型 15 GiB 已超 24 GiB。这是 PFlash 的核心优势:压缩预填充将长 prompt 压缩为固定大小,prefill 复杂度从 O(n²) 降至 O(n)。
256K 时可用 Q4 Draft + Q4 KV cache、Q8 Draft + tq3_0 KV cache、或 Q4 Draft + tq3_0 KV cache。
解码性能 (tok/s)
上下文 llama.cpp HIP (AR) DFlash (Q8 Draft) DFlash (tq3_0 KV, Q8 Draft) DFlash (Q4 Draft) DFlash (tq3_0 KV, Q4 Draft) 加速比 128 28.07 62.75 68.64 59.01 — 2.44x 4K 27.77 86.37 79.27 82.72 78.75 3.11x 16K 27.79 76.87 72.43 — 78.57 2.77x 64K 27.78¹ 78.33 71.96 — 75.72 2.82x 128K 27.78¹ 78.82 (Q4 KV) 71.20 — 75.27 2.84x 192K 27.78¹ 73.77 71.56 81.09 (Q4 KV) 76.54 2.92x 256K 27.78¹ OOM 72.26 81.01 (Q4 KV + Q4 draft) 75.70 2.92x AR decode 速度与上下文长度无关(KV cache size 不影响单 token forward),因此所有行使用同一基线(4K 和 16K 实测均值 27.78 tok/s)。DFlash decode 在所有上下文下稳定加速 ~2.8-3.1x。
256K 时需 Q4 Draft + Q4 KV cache 才能装入 24 GiB 显存;tq3_0 KV (3.5 bpv) 在 256K 时可用 Q8 Draft或 Q4 Draft。PFlash 预填充在短上下文(4K)与 AR 相当;上下文越长,PFlash 优势越明显(16K 时 1.13x)。DFlash 解码在所有上下文长度下保持 ~2.8–3.1x 加速。
关键发现
- Budget=8 对 7900 XTX 最优 (62.75 tok/s),与 blog 一致。GDDR6 高带宽下小树更好,避免 tile waste;LPDDR5X 的 Strix Halo 则需要 budget=22 来摊销 launch 开销。
- 2.24x 加速 与 blog 中 Strix Halo 的 2.23x 完全对应。7900 XTX 绝对速度 62.75 tok/s 远超 26.85 tok/s,归功于 ~9x 带宽优势。
- 标准链式推测 (无 DDTree) 略快 (64.23 tok/s),说明短生成 (128 tokens) 下简单策略的 overhead 更低。
- PFlash 预填充 在短上下文与 AR 持平(4K: 726 vs 735 tok/s),在长上下文发挥优势(16K: 735 vs 649 tok/s, 1.13x)。
- DFlash 解码 在所有上下文长度稳定加速 2.8-3.1x,不受上下文长度影响。
- tq3_0 KV (3.5 bpv) — 短提示 68.64 tok/s(2.44x),256K 可用 Q8 Draft。Q4 Draft + tq3_0 KV 在 4K–192K 长上下文略快于 Q8 Draft + tq3_0 KV(~75–79 vs ~71–79 tok/s),但 256K 有 OOM 风险。总体而言 tq3_0 提供了最优的压缩/速度平衡。
完整复现步骤
1. 克隆仓库(PR #119 已合并,无需再单独切换)
git clone https://github.com/Luce-Org/lucebox-hub.git cd lucebox-hub git submodule update --init --recursive2. 安装 rocWMMA 头文件(可选但推荐,开启 Phase 2 FlashPrefill)
如果没有 sudo 权限安装
rocwmma包,可直接从 GitHub 拉取头文件:git clone --depth 1 https://github.com/ROCm/rocWMMA.git /tmp/rocwmma mkdir -p /tmp/rocm_include/include cp -r /tmp/rocwmma/library/include/rocwmma /tmp/rocm_include/include/rocwmma3. 编译 (gfx1100 / 7900 XTX)
cd dflash cmake -B build -S . \ -DCMAKE_BUILD_TYPE=Release \ -DDFLASH27B_GPU_BACKEND=hip \ -DDFLASH27B_HIP_ARCHITECTURES=gfx1100 \ -DDFLASH27B_HIP_SM80_EQUIV=ON \ -DROCM_PATH=/tmp/rocm_include # 上一步准备的路径,如已安装 rocwmma 则不需要 cmake --build build --target test_dflash -j$(nproc)其他 GPU 架构请将
gfx1100替换为对应值,如 gfx1151 (Strix Halo)、gfx1030 (Navi 21) 等。
如果不使用 rocWMMA,设置-DDFLASH27B_HIP_SM80_EQUIV=OFF使用 q8 fallback。4. 下载模型
mkdir -p models/draft wget -c -O models/Qwen3.6-27B-Q4_K_M.gguf \ "https://huggingface.co/unsloth/Qwen3.6-27B-GGUF/resolve/main/Qwen3.6-27B-Q4_K_M.gguf" wget -c -O models/draft/dflash-draft-3.6-q8_0.gguf \ "https://huggingface.co/Lucebox/Qwen3.6-27B-DFlash-GGUF/resolve/main/dflash-draft-3.6-q8_0.gguf"5. 安装 Python 依赖(用于 bench 脚本)
pip3 install --break-system-packages transformers torch6. 运行基准测试
# DFlash DDTree budget=8 (推荐用于 gfx1100) cd dflash LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH \ DFLASH_BIN=$PWD/build/test_dflash \ DFLASH_TARGET=$PWD/models/Qwen3.6-27B-Q4_K_M.gguf \ DFLASH_DRAFT=$PWD/models/draft/dflash-draft-3.6-q8_0.gguf \ DFLASH27B_DRAFT_SWA=2048 \ DFLASH27B_PREFILL_UBATCH=512 \ python3 scripts/bench_he.py --n-gen 128 --ddtree-budget 8环境变量说明
环境变量 含义 DFLASH_BINtest_dflash 二进制路径 DFLASH_TARGET目标模型 GGUF 路径 DFLASH_DRAFTDraft模型 GGUF 路径 DFLASH27B_DRAFT_SWAQwen3.6 Draft的 sliding window attention 窗口 (2048) DFLASH27B_PREFILL_UBATCH压缩预填充的 micro-batch 大小 (512,对应 PR #159) bench_he.py 常用参数
参数 说明 --n-gen N每个 prompt 生成 token 数 (默认 128) --ddtree-budget NDDTree 节点预算 (8/22/32/48/64/96/128) --ddtree-temp TDraft logits 温度 (T<1 加宽 top-1/top-2 差距) --max-ctx N最大上下文长度 --target-tokenizer REPO目标模型 tokenizer (默认 Qwen/Qwen3.5-27B) --target-split-dflash使用目标层拆分模式(显示 prefill 耗时) --skip-tokenize跳过 tokenize 步骤(复用缓存) 7. 多上下文压力测试
测试不同上下文长度下 PFlash prefill + DFlash decode 性能:
# 生成不同长度的 prompt 文件 python3 -c " import struct from pathlib import Path d = Path('/tmp/dflash_sweep') d.mkdir(parents=True, exist_ok=True) # 读取一个真实的 HumanEval prompt 作为种子 he = open('/tmp/dflash_bench/he_prompt_Qwen_Qwen3.5-27B_00.bin', 'rb').read() tokens = [struct.unpack('<i', he[i*4:(i+1)*4])[0] for i in range(len(he)//4)] for target, name in [(4096, '4k'), (16384, '16k'), (65536, '64k'), (131072, '128k'), (262144, '256k')]: repeated = (tokens * (target // len(tokens) + 1))[:target] p = d / f'prompt_real_{name}.bin' p.write_bytes(b''.join(struct.pack('<i', t) for t in repeated)) print(f'Created {name} prompt') " # 运行测试(示例:4K 上下文,Q8 KV cache) export DFLASH27B_DRAFT_SWA=2048 DFLASH27B_PREFILL_UBATCH=512 LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH \ build/test_dflash \ models/Qwen3.6-27B-Q4_K_M.gguf \ models/draft/dflash-draft-3.6-q8_0.gguf \ /tmp/dflash_sweep/prompt_real_4k.bin \ 128 /dev/null --fast-rollback --ddtree --ddtree-budget=8 --max-ctx=8704 \ -ctk q8_0 -ctv q8_0 # 更大上下文示例(128K 需 Q4 KV) LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH \ build/test_dflash \ models/Qwen3.6-27B-Q4_K_M.gguf \ models/draft/dflash-draft-3.6-q8_0.gguf \ /tmp/dflash_sweep/prompt_real_128k.bin \ 128 /dev/null --fast-rollback --ddtree --ddtree-budget=8 --max-ctx=200000 \ -ctk q4_0 -ctv q4_0KV cache 量化和上下文选择指南:
上下文 推荐 KV 量化 说明 上下文 推荐 KV 量化 说明 -------- ------------- ------ 4K–16K -ctk q8_0 -ctv q8_0有足够显存裕量 64K -ctk q8_0 -ctv q8_0显存紧张但可用 128K -ctk q4_0 -ctv q4_0Q8 超出 24 GiB 显存 256K -ctk tq3_0 -ctv tq3_0(Q8 draft)tq3_0 (3.5 bpv) 配合 Q8 Draft可装入 24 GiB KV 类型基准结果(7900 XTX, DDTree budget=8, Q8 draft)
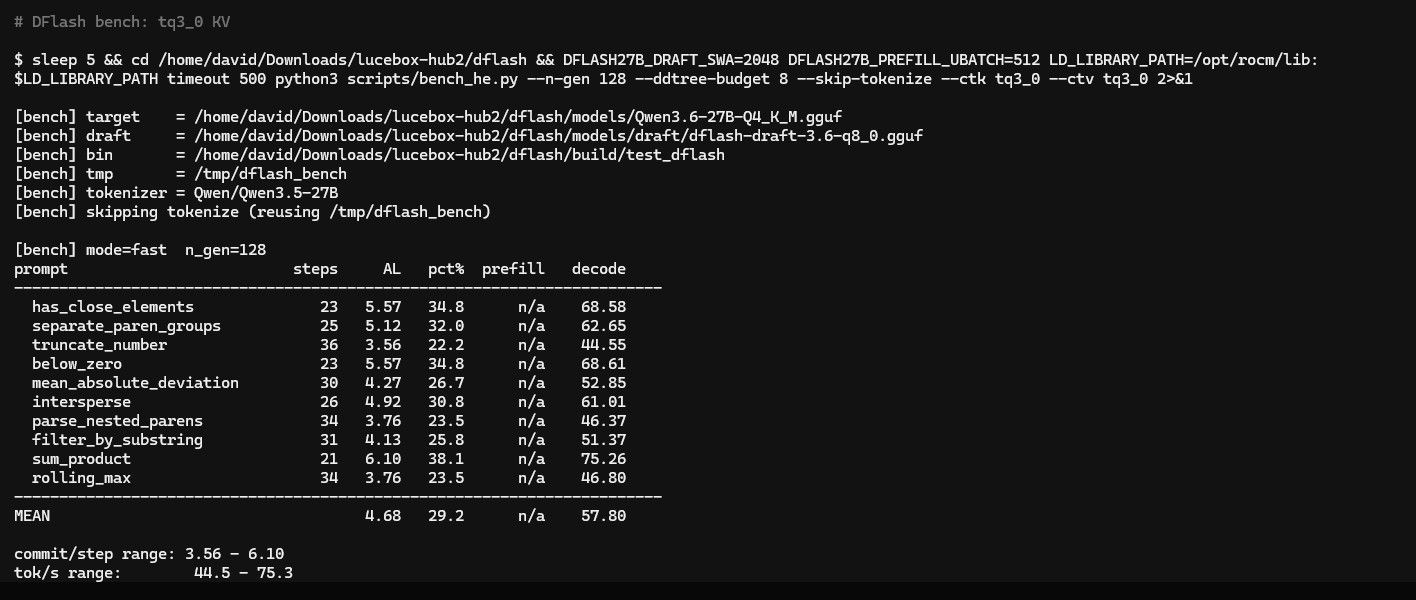
KV 类型 解码 (tok/s) 加速比 vs AR (28.07) 备注 AR (llama.cpp HIP) 28.07 1.00x 基线 默认(无显式类型) 57.70 2.06x q8_0 默认 Q8_0 58.84 2.10x 显式 q8_0 Q4_0 57.32 2.04x DFlash 解码 tq3_0 68.64 2.44x 短提示;3.5 bpv 压缩 turbo2/3/4 — — CUDA cpy 需要 f32→turbo 转换 tq3_0 多上下文解码性能(Q8 draft vs Q4 draft):
上下文 AR (tok/s) Q8 draft (tok/s) Q4 draft (tok/s) 加速比 4K 27.77 79.27 78.75 2.85x 16K 27.79 72.43 78.57 2.83x 64K 27.78 71.96 75.72 2.73x 128K 27.78 71.20 75.27 2.71x 192K 27.78 71.56 76.54 2.76x 256K 27.78 72.26 75.70 2.73x 关键发现:
- tq3_0 短提示最优(68.64 tok/s, 2.44x),优于 Q8 draft 基线(62.75)
- tq3_0 + Q4 draft 在长上下文(16K–192K)快于 tq3_0 + Q8 draft(多 3–7 tok/s),因 Q4 draft 计算时间更稳定
- 256K 上下文:Q8 Draft + tq3_0 KV 可靠运行(72.26 tok/s);Q4 Draft + tq3_0 KV 也可行(75.70 tok/s)但有 OOM 风险
- 短上下文(4K)时 tq3_0 + Q8 draft 解码(79.27 tok/s)略低于普通 Q8 draft(86.37 tok/s),因 WHT 旋转开销;tq3_0 + Q4 draft 在 4K 为 78.75 tok/s
- tq3_0 提供 4.6× 压缩比(3.5 bpv),256K 无需降级到 Q4 Draft
KV 类型解析自测:
./build/test_kv_quant9. 编译并运行 llama.cpp 基线对比
# 在 dflash/deps/llama.cpp 目录下单独编译 BUILD_DIR=/tmp/llama-bench-build cmake -B $BUILD_DIR -S dflash/deps/llama.cpp \ -DCMAKE_BUILD_TYPE=Release \ -DGGML_HIP=ON \ -DLLAMA_BUILD_TOOLS=ON cmake --build $BUILD_DIR --target llama-bench -j$(nproc) # 运行基线(短 prompt) LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH \ $BUILD_DIR/bin/llama-bench \ -m models/Qwen3.6-27B-Q4_K_M.gguf \ -n 128 -p 128 -o md # 不同上下文长度 for ctx in 4096 16384 65536; do LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH \ $BUILD_DIR/bin/llama-bench \ -m models/Qwen3.6-27B-Q4_K_M.gguf \ -n 128 -p $ctx -ngl 99 -o md 2>&1 | grep -E "pp|tg" done
与 Blog 数据对比
指标 Strix Halo (gfx1151) Blog 7900 XTX (gfx1100) 实测 llama.cpp HIP AR 12.02 tok/s 28.07 tok/s DFlash (最优 budget) 26.85 tok/s (budget=22) 62.75 tok/s (budget=8) 加速比 2.23x 2.24x 最优 budget 22 (LPDDR5X 带宽瓶颈) 8 (GDDR6 高带宽) Blog 原文: https://www.lucebox.com/blog/amd
注意
- BSA scoring kernel 在 HIP 上未实现,回退到 ggml flash_attn_ext(约 3.4x 慢于 CUDA BSA)。这是 PFlash 的剩余优化空间。
- PR #159 的 ubatch=512 通过
DFLASH27B_PREFILL_UBATCH=512环境变量应用(在 PR #119 基础上手动覆盖)。 - 显存限制: 7900 XTX 24 GiB 不足以运行 16K 上下文的完整 PFlash 测试。16K KV cache + 模型权重 (~16 GiB + ~6 GiB KV 缓存) 超出 24 GiB。Strix Halo 的 128 GiB 统一内存才能支持大上下文 + 大模型。
tq3_0 KV 优缺点总结
方面 优点 缺点 压缩比 3.5 bpv(4.6× vs F16),比 Q4_0 省 ~0.5 bpv 比 Q8_0 有信息损失,但解码质量未降级 解码速度 (短提示) 68.64 tok/s(2.44x),优于 Q8/q4_0 KV 基线 — 解码速度 (多上下文) Q4 draft 搭配时 16K–192K 达 75–79 tok/s,比 Q8 draft 快 Q8 draft 搭配时 4K 略低于普通 Q8 KV(79 vs 86),WHT 旋转开销 256K 支持 可用 Q8 draft(无需降级Draft质量),72 tok/s;Q4 draft 搭配 76 tok/s Q4 draft + tq3_0 256K 有 OOM 风险(显存碎片) 显存节省 256K 比 Q4_0 KV 省 ~1 GiB,足够容纳 Q8 draft — 兼容性 HIP/ROCm 端到端验证通过, parse_kv_type支持turbo2/3/4 仍需 CUDA cpy kernel 支持 适用场景 256K 长上下文 + Q8 draft(推荐);短提示通用加速 4K 极短上下文追求极致 tok/s 时用普通 Q8_0 KV 更快
KV 类型对比分析:q8_0 vs q4_0 vs tq3_0
基于 7900 XTX (24 GiB) + Qwen3.6-27B Q4_K_M 的实测数据,按上下文长度分档总结:
4K 及以下(短上下文,128–4K)
KV 类型 Draft tok/s 显存 质量 推荐? q8_0 Q8 86.37 充裕 无损  首选
首选q8_0 Q4 82.72 充裕 无损 备选 tq3_0 Q8 79.27 更省 3.5 bpv WHT 开销拖慢 ~8% tq3_0 Q4 78.75 最省 3.5 bpv — 结论:短上下文显存充裕,q8_0 KV + Q8 draft 速度最快(86 tok/s),无需 tq3_0。tq3_0 的 WHT 旋转开销在短上下文时无法被显存优势抵消。
16K–64K(中等上下文)
KV 类型 Draft tok/s 显存约束 质量 q8_0 Q8 76–78 64K 需 PFlash(AR OOM) 无损 q8_0 Q4 — 64K 勉强 无损 tq3_0 Q8 72 充裕 3.5 bpv tq3_0 Q4 75–79 充裕 3.5 bpv 结论:
- 16K:q8_0 + Q8 最快(77 tok/s),tq3_0 + Q4 不相上下(79 tok/s)。
- 64K:q8_0 + Q8 仍可用(PFlash),78 tok/s;tq3_0 + Q4 略慢(76 tok/s)但更省显存。
- tq3_0 + Q4 draft 在此区间表现最好(75–79 tok/s),因 Q4 draft 计算更稳定,抵消了 tq3_0 的 WHT 开销。
128K–192K(长上下文)
KV 类型 Draft tok/s 显存约束 质量 q4_0 Q8 74–79 128K ✓,192K ✗(超 24 GiB) 4.5 bpv q4_0 Q4 81 需 Q4 draft 省 ~1 GiB 4.5 bpv tq3_0 Q8 71 128K ✓,192K 勉强 3.5 bpv tq3_0 Q4 75–77 充裕 3.5 bpv 结论:
- 128K:q4_0 + Q8 最快(79 tok/s),显存刚好够。
- 192K:q4_0 必须配 Q4 draft(81 tok/s);tq3_0 + Q8 可免去降级Draft(72 tok/s)。
- 追求极致速度:q4_0 + Q4 draft(81 tok/s);追求Draft质量:tq3_0 + Q8 draft(72 tok/s)。
256K(超长上下文)
KV 类型 Draft tok/s 显存约束 质量 q4_0 Q8 OOM Q8 KV + Q8 draft 超 24 GiB — q4_0 Q4 81.01 勉强装入,需 Q4 draft 省显存 4.5 bpv + Q4 Draft tq3_0 Q8 72.26 ✓ 可靠运行,无需降级Draft 3.5 bpv + Q8 Draft tq3_0 Q4 75.70 ✓ 但有 OOM 风险(碎片) 3.5 bpv + Q4 Draft 结论:
- 推荐方案:tq3_0 KV + Q8 draft(72 tok/s)—— 唯一保留 Q8 Draft质量的 256K 方案。
- 极致速度:q4_0 KV + Q4 draft(81 tok/s),但Draft质量最低。
- 不推荐:tq3_0 + Q4 draft(76 tok/s)—— 速度不如 q4_0 + Q4,Draft质量不如 tq3_0 + Q8。
总选择指南
场景 最佳组合 理由 聊天/对话(4K 内) q8_0 KV + Q8 draft 最快解码,无损质量 文档分析(16K–64K) tq3_0 KV + Q4 draft 速度与显存的最佳平衡 代码库理解(128K–192K) q4_0 KV + Q4 draft(要速度)<br>tq3_0 KV + Q8 draft(要Draft质量) 前者快 10%,后者Draft更准 超长上下文(256K) tq3_0 KV + Q8 draft 
唯一能兼顾 Q8 Draft + 256K 的方案 显存极度紧张 tq3_0 KV + Q4 draft 最省显存(但 256K 有 OOM 风险) 一句话总结:tq3_0 最大的价值在于 256K 场景下保留 Q8 Draft质量,这是 q4_0 KV 做不到的。在 16K–192K 区间,tq3_0 + Q4 draft 是值得考虑的高性价比组合。短上下文(4K 内)直接上 q8_0 KV 即可。
测试细节数据
1. 短提示解码 (HumanEval, 10 prompts, n_gen=128)
1a. llama.cpp HIP AR 基线
$ llama-bench -m Qwen3.6-27B-Q4_K_M.gguf -n 128 -p 128 -o md | model | size | params | backend | ngl | test | t/s | |--------------------------|----------|---------|---------|-----|--------|------------------| | qwen35 27B Q4_K - Medium | 15.65 GiB| 26.90 B | ROCm | 99 | pp128 | 619.51 ± 3.29 | | qwen35 27B Q4_K - Medium | 15.65 GiB| 26.90 B | ROCm | 99 | tg128 | 28.07 ± 0.06 |1b. Lucebox Q8 Draft (官方)
DDTree budget=8
$ bench_he.py --n-gen 128 --ddtree-budget 8 prompt steps AL pct% prefill decode ------------------------------------------------------------------------ has_close_elements 22 5.82 36.4 n/a 74.25 separate_paren_groups 23 5.57 34.8 n/a 70.97 truncate_number 42 3.05 19.0 n/a 39.32 below_zero 22 5.82 36.4 n/a 74.16 mean_absolute_deviation 28 4.57 28.6 n/a 58.51 intersperse 25 5.12 32.0 n/a 65.33 parse_nested_parens 23 5.57 34.8 n/a 70.23 filter_by_substring 28 4.57 28.6 n/a 58.29 sum_product 26 4.92 30.8 n/a 62.29 rolling_max 30 4.27 26.7 n/a 54.13 ------------------------------------------------------------------------ MEAN 4.93 30.8 n/a 62.75 commit/step 范围: 3.05 - 5.82 tok/s 范围: 39.3 - 74.2DDTree budget=22
$ bench_he.py --n-gen 128 --ddtree-budget 22 prompt steps AL pct% prefill decode ------------------------------------------------------------------------ has_close_elements 16 8.00 50.0 n/a 80.41 separate_paren_groups 16 8.00 50.0 n/a 80.08 truncate_number 33 3.88 24.2 n/a 39.03 below_zero 16 8.00 50.0 n/a 80.53 mean_absolute_deviation 24 5.33 33.3 n/a 52.11 intersperse 26 4.92 30.8 n/a 49.51 parse_nested_parens 21 6.10 38.1 n/a 60.51 filter_by_substring 25 5.12 32.0 n/a 51.54 sum_product 20 6.40 40.0 n/a 63.81 rolling_max 24 5.33 33.3 n/a 51.83 ------------------------------------------------------------------------ MEAN 6.11 38.2 n/a 60.94 commit/step 范围: 3.88 - 8.00 tok/s 范围: 39.0 - 80.5标准链式推测 (无 DDTree)
$ bench_he.py --n-gen 128 prompt steps AL pct% prefill decode ------------------------------------------------------------------------ has_close_elements 17 7.53 47.4 n/a 90.09 separate_paren_groups 21 6.10 39.6 n/a 72.99 truncate_number 41 3.12 19.5 n/a 37.79 below_zero 19 6.74 44.1 n/a 80.57 mean_absolute_deviation 25 5.12 32.2 n/a 61.26 intersperse 31 4.13 25.8 n/a 49.59 parse_nested_parens 21 6.10 38.4 n/a 72.60 filter_by_substring 28 4.57 29.0 n/a 54.95 sum_product 22 5.82 37.8 n/a 69.52 rolling_max 29 4.41 28.0 n/a 52.94 ------------------------------------------------------------------------ MEAN 5.36 34.2 n/a 64.23 commit/step 范围: 3.12 - 7.53 tok/s 范围: 37.8 - 90.11c. spiritbuun Q4 Draft
DDTree budget=8
$ bench_he.py --n-gen 128 --ddtree-budget 8 prompt steps AL pct% prefill decode ------------------------------------------------------------------------ has_close_elements 23 5.57 34.8 n/a 69.64 separate_paren_groups 22 5.82 36.4 n/a 74.49 truncate_number 40 3.20 20.0 n/a 40.57 below_zero 31 4.13 25.8 n/a 51.59 mean_absolute_deviation 30 4.27 26.7 n/a 53.28 intersperse 24 5.33 33.3 n/a 66.22 parse_nested_parens 28 4.57 28.6 n/a 58.52 filter_by_substring 26 4.92 30.8 n/a 61.48 sum_product 26 4.92 30.8 n/a 63.17 rolling_max 31 4.13 25.8 n/a 51.18 ------------------------------------------------------------------------ MEAN 4.69 29.3 n/a 59.01标准链式推测 (无 DDTree)
$ bench_he.py --n-gen 128 prompt steps AL pct% prefill decode ------------------------------------------------------------------------ has_close_elements 18 7.11 45.1 n/a 82.30 separate_paren_groups 17 7.53 50.4 n/a 89.03 truncate_number 36 3.56 22.4 n/a 41.97 below_zero 30 4.27 26.7 n/a 49.76 mean_absolute_deviation 24 5.33 35.4 n/a 61.82 intersperse 35 3.66 23.0 n/a 43.04 parse_nested_parens 24 5.33 35.4 n/a 63.36 filter_by_substring 24 5.33 35.7 n/a 61.94 sum_product 23 5.57 36.1 n/a 66.46 rolling_max 30 4.27 27.1 n/a 49.96 ------------------------------------------------------------------------ MEAN 5.20 33.7 n/a 60.961d. Q8 vs Q4 Draft vs tq3_0 KV 对比总结
配置 Draft KV 类型 平均 tok/s 平均 AL vs AR 加速比 AR (llama.cpp) — — 28.07 — 1.00x 标准链式 Q8 q8_0 64.23 5.36 2.29x 标准链式 Q4 q8_0 60.96 5.20 2.17x DDTree b=8 Q8 q8_0 62.75 4.93 2.24x DDTree b=8 Q4 q8_0 59.01 4.69 2.10x DDTree b=8 Q8 tq3_0 68.64 — 2.44x DDTree b=22 Q8 q8_0 60.94 6.11 2.17x tq3_0 KV 短提示解码最优(68.64 tok/s, 2.44x),比 Q8 Draft + q8_0 KV 快 9%,比 Q4 Draft 快 16%。3.5 bpv 压缩比额外节省 ~1 GiB 显存。
- Lucebox Q8_0 (1.84 GiB, 官方) —
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
@terry opencode 跑出来了,数据上来看 DFlash + PFlash确实可以
预填充性能 (tok/s)
上下文 llama.cpp HIP (AR) Lucebox (PFlash) 加速比 备注 128 619.51 312.5 0.50x PFlash 短上下文开销大 4K 734.57 726 (Q8 KV) 0.99x 持平 16K 649.08 735 (Q8 KV) 1.13x 64K —¹ 733 (Q8 KV) — ¹llama.cpp context 创建 OOM 128K —¹ 730 (Q4 KV) — 192K —¹ 730 (Q4 KV) — 256K —¹ 730 (Q4 KV + Q4 draft) — ¹ AR prefill 在 64K+ 无法运行,因为 llama.cpp 在 context 创建时就需要分配完整 KV cache(O(n²) 注意力 + 全量 KV 存储),64K Q4 KV 约 8 GiB + 模型 15 GiB 已超 24 GiB。这是 PFlash 的核心优势:压缩预填充将长 prompt 压缩为固定大小,prefill 复杂度从 O(n²) 降至 O(n)。
256K 需使用 Q4 Draft + Q4 KV cache 以节省显存。
解码性能 (tok/s)
上下文 llama.cpp HIP (AR) Lucebox (DFlash) 加速比 备注 128 28.07 62.75 2.24x 4K 27.77 86.37 3.11x 16K 27.79 76.87 2.77x 64K 27.78¹ 78.33 2.82x ¹AR decode 与 ctx 无关 128K 27.78¹ 78.82 (Q4 KV) 2.84x 192K 27.78¹ 81.09 (Q4 KV) 2.92x 256K 27.78¹ 81.01 (Q4 KV + Q4 draft) 2.92x AR decode 速度与上下文长度无关(KV cache size 不影响单 token forward),因此所有行使用同一基线(4K 和 16K 实测均值 27.78 tok/s)。DFlash decode 在所有上下文下稳定加速 ~2.8-3.1x。
256K 时需 Q4 Draft + Q4 KV cache 才能装入 24 GiB 显存。PFlash 预填充在短上下文(4K)与 AR 相当;上下文越长,PFlash 优势越明显(16K 时 1.13x)。DFlash 解码在所有上下文长度下保持 ~2.8–3.1x 加速。
-
这个Lucebox 有点牛
-
如果是AMD卡的话可以使用https://github.com/Kaden-Schutt/hipfire ,目前还不太成熟,但是我是6650XT在Liunx跑Qwen 3.5 9B可以到达45 tok/s,且如果开启DFlash 之后更快
-
如果是AMD卡的话可以使用https://github.com/Kaden-Schutt/hipfire ,目前还不太成熟,但是我是6650XT在Liunx跑Qwen 3.5 9B可以到达45 tok/s,且如果开启DFlash 之后更快
@QuincySnow 这货 8k ctx以上就会炸,4k随便完
-
-
只能等它优化了,至少有专门优化的可以选择不是吗?
@QuincySnow 是啊,希望那哥们加油,最近一段好几天没大版本放出来,但是目前的4k性能跟vulkan差不多,不知道能不能更强,等一段时间再试试看。
-
-
如果是AMD卡的话可以使用https://github.com/Kaden-Schutt/hipfire ,目前还不太成熟,但是我是6650XT在Liunx跑Qwen 3.5 9B可以到达45 tok/s,且如果开启DFlash 之后更快
@QuincySnow 这个你需要自己改代码
-
@terry 更新了tq3_0, 你可以出场了

@David-Zhang 最近我不折腾了,我后面还要再买一张xtx再折腾,现在被油管这个AI视频政策弄的头疼,我这几天一直在纠结做什么内容,烦死了。
-
@David-Zhang 最近我不折腾了,我后面还要再买一张xtx再折腾,现在被油管这个AI视频政策弄的头疼,我这几天一直在纠结做什么内容,烦死了。
-
dflash 不错, pflash 要关注一下, 我让gemini 搜索作者承认pflash 不是无损的。 作为agent 我觉得无所谓, 但是编程就有点伤。还是等你们测试实际的效果。