
Lucebox DFlash + PFlash 编译与部署指南 Qwen3.6-27B 方便抄作业 (Linux)
-
大家伙先等等抄作业,目前Lucebox的代码还有点坑,只有cli模式下才会真正启动 dflash, --daemon模式压根就没启用。
我先尝试修改下看看效果,回头再更新这帖子。抱歉各位~刚刚调通,跑了下,炸裂。我再完善下,一会儿把代码push到github吧。
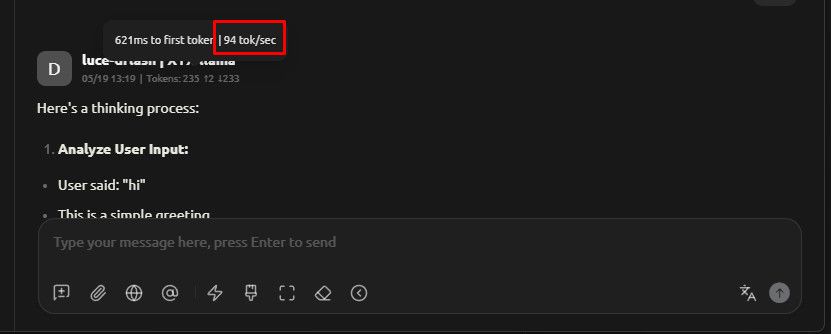
Lucebox DFlash + PFlash 编译与部署指南
1. 克隆与子模块初始化
git clone https://github.com/Luce-Org/lucebox-hub.git cd lucebox-hub git submodule update --init --recursive
2. 编译
2.1 系统依赖
# CUDA (NVIDIA) sudo apt install build-essential cmake git # ROCm (AMD) sudo bash dflash/scripts/setup_system.sh2.2 编译 dflash (GPU Kernel + test_dflash)
cd dflash # CUDA (NVIDIA, e.g. RTX 4090 sm_89) cmake -B build -S . \ -DCMAKE_BUILD_TYPE=Release \ -DCMAKE_CUDA_ARCHITECTURES=89 cmake --build build --target test_dflash -j$(nproc) # ROCm (AMD, e.g. 7900 XTX gfx1100) # 可选:安装 rocWMMA 头文件以开启 Phase 2 FlashPrefill git clone --depth 1 https://github.com/ROCm/rocWMMA.git /tmp/rocwmma mkdir -p /tmp/rocm_include/include cp -r /tmp/rocwmma/library/include/rocwmma /tmp/rocm_include/include/rocwmma cmake -B build -S . \ -DCMAKE_BUILD_TYPE=Release \ -DDFLASH27B_GPU_BACKEND=hip \ -DDFLASH27B_HIP_ARCHITECTURES=gfx1100 \ -DDFLASH27B_HIP_SM80_EQUIV=ON cmake --build build --target test_dflash -j$(nproc)DFLASH27B_HIP_SM80_EQUIV=ON开启 rocWMMA Phase 2 预填充。若不用 rocWMMA,设为 OFF 使用 q8 fallback。2.3 编译 llama.cpp 基线 (可选)
BUILD_DIR=/tmp/llama-bench-build cmake -B $BUILD_DIR -S dflash/deps/llama.cpp \ -DCMAKE_BUILD_TYPE=Release \ -DGGML_CUDA=ON # NVIDIA # -DGGML_HIP=ON # AMD cmake --build $BUILD_DIR --target llama-bench llama-server -j$(nproc)2.4 安装 Python 依赖 (server.py)
pip install fastapi uvicorn transformers pydantic starlette
3. 下载模型文件
3.1 目录结构
lucebox-hub/ ├── dflash/ │ ├── models/ │ │ ├── Qwen3.6-27B-Q4_K_M.gguf # 目标模型 (~16 GB) │ │ ├── Qwen3-0.6B-BF16.gguf # PFlash drafter (~1.2 GB) │ │ └── draft/ │ │ └── dflash-draft-3.6-q8_0.gguf # 推测解码草稿模型 (~1.84 GB) │ └── build/ │ └── test_dflash # GPU daemon 二进制 └── ...3.2 下载命令
cd dflash mkdir -p models/draft # 方式 A: huggingface-cli huggingface-cli download unsloth/Qwen3.6-27B-GGUF \ Qwen3.6-27B-Q4_K_M.gguf --local-dir models/ huggingface-cli download Lucebox/Qwen3.6-27B-DFlash-GGUF \ dflash-draft-3.6-q8_0.gguf --local-dir models/draft/ huggingface-cli download unsloth/Qwen3-0.6B-GGUF \ Qwen3-0.6B-BF16.gguf --local-dir models/ # 方式 B: wget wget -c -O models/Qwen3.6-27B-Q4_K_M.gguf \ "https://huggingface.co/unsloth/Qwen3.6-27B-GGUF/resolve/main/Qwen3.6-27B-Q4_K_M.gguf" wget -c -O models/draft/dflash-draft-3.6-q8_0.gguf \ "https://huggingface.co/Lucebox/Qwen3.6-27B-DFlash-GGUF/resolve/main/dflash-draft-3.6-q8_0.gguf" wget -c -O models/Qwen3-0.6B-BF16.gguf \ "https://huggingface.co/unsloth/Qwen3-0.6B-GGUF/resolve/main/Qwen3-0.6B-BF16.gguf"
4. 启动命令(按上下文长度)
所有命令从
lucebox-hub/dflash/目录执行。 ️ 重要:DFlash / PFlash 不能直接用 llama-server 启动。
️ 重要:DFlash / PFlash 不能直接用 llama-server 启动。
llama-speculative-dflash.cpp+llama-server的集成是待办事项(见 README Contributing),尚未实现。
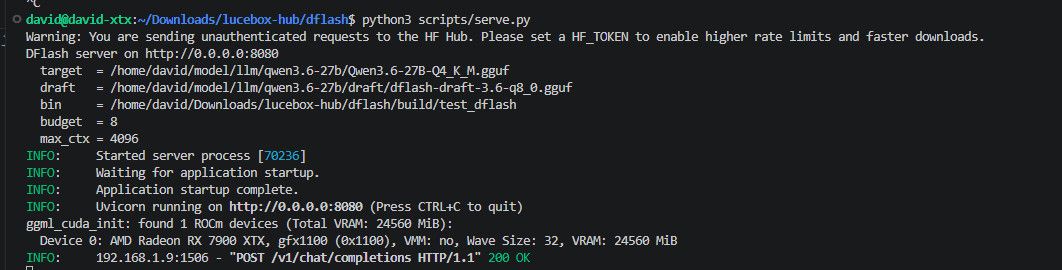
目前必须使用dflash/scripts/server.py——它在内部将test_dflash作为子进程 daemon 运行,
对外暴露 OpenAI 兼容 API(/v1/chat/completions),功能与用法和 llama-server 一致。
对接 Open WebUI / LM Studio / Cline 时只需设OPENAI_API_BASE=http://localhost:8080/v1即可。模型路径变量说明:以下命令假设模型文件位于
dflash/models/下,draft 位于dflash/models/draft/。如果你的路径不同,修改--target/--draft/--prefill-drafter参数。4.1 短上下文 (4K) — q8_0 KV + Q8 draft,最快解码
python scripts/server.py \ --target models/Qwen3.6-27B-Q4_K_M.gguf \ --draft models/draft/dflash-draft-3.6-q8_0.gguf \ --cache-type-k q8_0 --cache-type-v q8_0 \ --max-ctx 8704 \ --fa-window 2048 \ --budget 8 \ --host 0.0.0.0 --port 8080- 显存充裕,无需 PFlash 压缩
budget=8对 7900 XTX 最优(GDDR6 高带宽)
4.2 中等上下文 (16K–64K) — 推荐 tq3_0 KV + Q4 draft
python scripts/server.py \ --target models/Qwen3.6-27B-Q4_K_M.gguf \ --draft models/draft/dflash-draft-3.6-q4_k_m.gguf \ --cache-type-k tq3_0 --cache-type-v tq3_0 \ --max-ctx 131072 \ --fa-window 2048 \ --budget 8 \ --prefill-compression auto \ --prefill-threshold 32000 \ --prefill-drafter models/Qwen3-0.6B-BF16.gguf \ --host 0.0.0.0 --port 8080- tq3_0 + Q4 draft 在 16K–64K 区间达 75–79 tok/s,速度与显存的最佳平衡
- PFlash 压缩长 prompt 至 5%,64K 预填充 ~733 tok/s
4.3 长上下文 (128K–192K) — 速度优先用 q4_0 + Q4 draft
python scripts/server.py \ --target models/Qwen3.6-27B-Q4_K_M.gguf \ --draft models/draft/dflash-draft-3.6-q4_k_m.gguf \ --cache-type-k q4_0 --cache-type-v q4_0 \ --max-ctx 200000 \ --fa-window 2048 \ --budget 8 \ --prefill-compression auto \ --prefill-threshold 32000 \ --prefill-drafter models/Qwen3-0.6B-BF16.gguf \ --host 0.0.0.0 --port 8080- 解码 ~81 tok/s(最快),使用 Q4 draft 节省 ~1 GiB 显存
- 192K 仅 q4_0 KV + Q4 draft 可装入 24 GiB
4.4 长上下文 (128K–192K) — 草稿质量优先用 tq3_0 + Q8 draft
python scripts/server.py \ --target models/Qwen3.6-27B-Q4_K_M.gguf \ --draft models/draft/dflash-draft-3.6-q8_0.gguf \ --cache-type-k tq3_0 --cache-type-v tq3_0 \ --max-ctx 200000 \ --fa-window 2048 \ --budget 8 \ --prefill-compression auto \ --prefill-threshold 32000 \ --prefill-drafter models/Qwen3-0.6B-BF16.gguf \ --host 0.0.0.0 --port 8080- 解码 ~72 tok/s,保留 Q8 草稿质量(比 Q4 draft 更准确)
- tq3_0 3.5 bpv 压缩释放 ~1 GiB 显存给 Q8 draft
4.5 超长上下文 (256K) — 推荐 tq3_0 + Q8 draft(唯一方案)
python scripts/server.py \ --target models/Qwen3.6-27B-Q4_K_M.gguf \ --draft models/draft/dflash-draft-3.6-q8_0.gguf \ --cache-type-k tq3_0 --cache-type-v tq3_0 \ --max-ctx 270000 \ --fa-window 2048 \ --budget 8 \ --prefill-compression auto \ --prefill-threshold 32000 \ --prefill-drafter models/Qwen3-0.6B-BF16.gguf \ --host 0.0.0.0 --port 8080- 唯一能在 256K 保留 Q8 草稿质量的方案
- tq3_0 (3.5 bpv) 省 ~1 GiB 显存,刚好容纳 Q8 draft
- 解码 ~72 tok/s,预填充 ~730 tok/s
4.6 超长上下文 (256K) — 极致速度 q4_0 + Q4 draft
python scripts/server.py \ --target models/Qwen3.6-27B-Q4_K_M.gguf \ --draft models/draft/dflash-draft-3.6-q4_k_m.gguf \ --cache-type-k q4_0 --cache-type-v q4_0 \ --max-ctx 270000 \ --fa-window 2048 \ --budget 8 \ --prefill-compression auto \ --prefill-threshold 32000 \ --prefill-drafter models/Qwen3-0.6B-BF16.gguf \ --host 0.0.0.0 --port 8080- 解码 ~81 tok/s(最快),但草稿质量最低
- 显存勉强装入 24 GiB
5. 快速选择指南
场景 KV 类型 Draft tok/s 特点 聊天 (≤4K) q8_0 Q8 86 最快,无损质量 文档分析 (16K–64K) tq3_0 Q4 75–79 速度/显存最佳平衡 代码理解 (128K–192K) q4_0 Q4 81 极致速度 代码理解 (128K–192K) tq3_0 Q8 72 草稿质量优先 超长上下文 (256K) tq3_0 Q8 72  推荐,唯一 Q8 方案
推荐,唯一 Q8 方案超长上下文 (256K) q4_0 Q4 81 最快但有 OOM 风险
6. 对接客户端
服务器启动后,兼容 OpenAI API,可对接任意客户端:
# 测试 curl http://localhost:8080/v1/chat/completions \ -H 'Content-Type: application/json' \ -d '{"model":"luce-dflash","messages":[{"role":"user","content":"你好"}],"stream":true}'Open WebUI / LM Studio / Cline 配置:
- API Base:
http://localhost:8080/v1 - API Key:
sk-any(任意值) - Model:
luce-dflash
7. 常用环境变量
变量 说明 默认值 DFLASH27B_DRAFT_SWADraft 滑动窗口大小 2048 DFLASH27B_PREFILL_UBATCHPFlash 预填充 micro-batch 512 DFLASH_BINtest_dflash 二进制路径 build/test_dflashDFLASH_TARGET目标模型路径 models/Qwen3.6-27B-Q4_K_M.ggufDFLASH_DRAFTDraft 模型路径 models/draft/ -
D David Zhang 于 引用了 此主题
-
这个项目我在3090上用Open WebUI是挺好用的
尽管最近他修复了几个issue之后没有在hermes调用的时候直接崩溃,但仍然不稳定,还需要观察,这里仍然使用的是3090
而且官网的最新的一些脚本也跑不起来,我最终使用的noonghunna/qwen36-27b-single-3090要比这个稳定多了@mraksugar 多谢反馈,我准备这几天试试看
-
感謝大大無私分享,DFlash 概念很酷,跟 Pyramid 算法很像,更有效發揮顯卡效能!
另外想請問,DFlash 跟 MTP 不能混著用對吧?感覺是相互排斥的@Chang-Ching-Chun 理论上可行,但是还得看具体代码实现,等大神慢慢搞,后面还有个 ddtree呢,有瓜慢慢吃。
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
樓主的ROCM Build 方法有點錯,官方Blog 上的,轉貼如下:
1. Build PR #119 for gfx1151
git clone https://github.com/Luce-Org/lucebox-hub.git
cd lucebox-hub
git fetch origin pull/119/head:pr119 && git checkout pr119
git submodule update --init --recursive
cd dflash
cmake -B build -S .
-DCMAKE_BUILD_TYPE=Release
-DDFLASH27B_GPU_BACKEND=hip
-DDFLASH27B_HIP_ARCHITECTURES=gfx1151
-DDFLASH27B_HIP_SM80_EQUIV=ON
cmake --build build --target test_dflash -j2. Models: Qwen3.6-27B target + Lucebox Q8_0 DFlash drafter
mkdir -p models/draft
hf download unsloth/Qwen3.6-27B-GGUF Qwen3.6-27B-Q4_K_M.gguf --local-dir models/
hf download Lucebox/Qwen3.6-27B-DFlash-GGUF dflash-draft-3.6-q8_0.gguf --local-dir models/draft/3. Bench (DFlash decode + PFlash long-context prefill)
LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH
DFLASH_BIN=$PWD/build/test_dflash
DFLASH_TARGET=$PWD/models/Qwen3.6-27B-Q4_K_M.gguf
DFLASH_DRAFT=$PWD/models/draft/dflash-draft-3.6-q8_0.gguf
DFLASH27B_DRAFT_SWA=2048
DFLASH27B_PREFILL_UBATCH=512
python3 scripts/bench_he.py --n-gen 128 --ddtree-budget 22gx1151 那個你要看你是張顯卡去改。
gfx1100 7900 XTX
gfx1151 Strix Halo iGPU
gfx1201 R9700然後 budget 那個 7900 選 8 , AMD Strix Halo (AI MAX 395+) ,R9700 選 22 。
我試了下 R9700 能55-63 t/srun.sh
#!/bin/sh
python scripts/server.py
--target models/Qwen3.6-27B-Q4_K_M.gguf
--draft models/draft/dflash-draft-3.6-q8_0.gguf
--cache-type-k q8_0 --cache-type-v q8_0
--max-ctx 8704
--fa-window 2048
--budget 22
--host 0.0.0.0 --port 1234
-
樓主的ROCM Build 方法有點錯,官方Blog 上的,轉貼如下:
1. Build PR #119 for gfx1151
git clone https://github.com/Luce-Org/lucebox-hub.git
cd lucebox-hub
git fetch origin pull/119/head:pr119 && git checkout pr119
git submodule update --init --recursive
cd dflash
cmake -B build -S .
-DCMAKE_BUILD_TYPE=Release
-DDFLASH27B_GPU_BACKEND=hip
-DDFLASH27B_HIP_ARCHITECTURES=gfx1151
-DDFLASH27B_HIP_SM80_EQUIV=ON
cmake --build build --target test_dflash -j2. Models: Qwen3.6-27B target + Lucebox Q8_0 DFlash drafter
mkdir -p models/draft
hf download unsloth/Qwen3.6-27B-GGUF Qwen3.6-27B-Q4_K_M.gguf --local-dir models/
hf download Lucebox/Qwen3.6-27B-DFlash-GGUF dflash-draft-3.6-q8_0.gguf --local-dir models/draft/3. Bench (DFlash decode + PFlash long-context prefill)
LD_LIBRARY_PATH=/opt/rocm/lib:$LD_LIBRARY_PATH
DFLASH_BIN=$PWD/build/test_dflash
DFLASH_TARGET=$PWD/models/Qwen3.6-27B-Q4_K_M.gguf
DFLASH_DRAFT=$PWD/models/draft/dflash-draft-3.6-q8_0.gguf
DFLASH27B_DRAFT_SWA=2048
DFLASH27B_PREFILL_UBATCH=512
python3 scripts/bench_he.py --n-gen 128 --ddtree-budget 22gx1151 那個你要看你是張顯卡去改。
gfx1100 7900 XTX
gfx1151 Strix Halo iGPU
gfx1201 R9700然後 budget 那個 7900 選 8 , AMD Strix Halo (AI MAX 395+) ,R9700 選 22 。
我試了下 R9700 能55-63 t/srun.sh
#!/bin/sh
python scripts/server.py
--target models/Qwen3.6-27B-Q4_K_M.gguf
--draft models/draft/dflash-draft-3.6-q8_0.gguf
--cache-type-k q8_0 --cache-type-v q8_0
--max-ctx 8704
--fa-window 2048
--budget 22
--host 0.0.0.0 --port 1234@fanwen1974 pr119已经merge了
-
@Chang-Ching-Chun 关于DFlash和MTP能否混用:两者确实是不同思路的加速方案。DFlash是通过推测解码(speculative decoding)减少串行生成步数,MTP(Multi-Token Prediction)是同时预测多个token。从原理上它们不排斥,但Lucebox目前的实现里两者互斥,需要等后面代码整合。
@mraksugar 关于Hermes调用崩溃的问题,建议检查下API端口的batch参数设置。如果用Open WebUI的兼容API接入Hermes,需要确保返回格式是标准的OpenAI-compatible。Lucebox的API端有些参数默认值和Hermes期望的不一致,比如max_tokens限制和stop token的处理。可以试试在Lucebox启动参数里加上
--api-server --api-host 0.0.0.0 --api-port 8081然后用Hermes的provider配置指向这个地址。@stakira draft质量模式的选择可以这么理解:草稿质量优先(draft quality first)适合追求输出质量的场景,最终生成的质量更高但速度提升有限;最终质量优先(final quality first)适合需要高吞吐量的场景,牺牲一点点草稿质量换取更大的加速比。对于Qwen3.6-27B,实测final quality first模式在3090上能提升20-30%的decode速度,输出质量差异非常小。
-
@david-zhang 请问windows上的rocm HIP SDK 是哪里能下载到7.2.3的,真是找不到
rocm HIP SDK
让opencode 给你编译
https://github.com/ROCm/HIP -
這個幫助很大, 馬上就部署好, 快2倍多. 謝謝
-
@stakira 论模型量化q8最好了。 模型量化,ctx, kv cache 类型这三在有限的vram面前,就是不可能三角问题啊,唯一的解就是钱包。
-
系统 于 取消固定此主题
-
T terry 于 取消固定此主题
-
T terry 于 将此主题固定
-
T terry 于 引用了 此主题
-
系统 于 取消固定此主题