VoxCPM2 語音克隆 TTS 生成音色不穩定
-
想請教一下各位大神,前幾天嘗試部署 VoxCPM2
並使用語音克隆功能來給我的 Hermes 妹妹發聲
提供了約一分鐘的 wav 音頻當 reference
但是每次生成的語音音色都不太一樣,聽著很不舒服
使用極致克隆好像有 bug 更慘,生成多次後音色都變了
不知道大神們有沒有遇上這種狀況,又是如何解決?@linax777 請問你 Ultimate Clone 一段話時間大概多長?
我用粵語的 沒加載LoRa情況下每句不能超過10秒
10秒開始他就變成一種新的方言了 -
@linax777 請問你 Ultimate Clone 一段話時間大概多長?
我用粵語的 沒加載LoRa情況下每句不能超過10秒
10秒開始他就變成一種新的方言了 -
@0xsltomorrow Ultimate Clone 沒試過太多次
使用 HTTP API 調用 生成幾次之後就變成隨機音色 女聲變男聲
再試幾天沒有改善可能要換成使用 Qwen3-TTS -
我是才开始接触AI音视频,综合对比了一下,我用的刘悦大神的QWEN TTS 1.7B文字转语音整合包,除了长篇幅几千字会出现吞字外,感觉音频质量还是在线的。而且你是不是参考语音片段太长了,都1分钟了,一般不都是10秒左右吗?
-
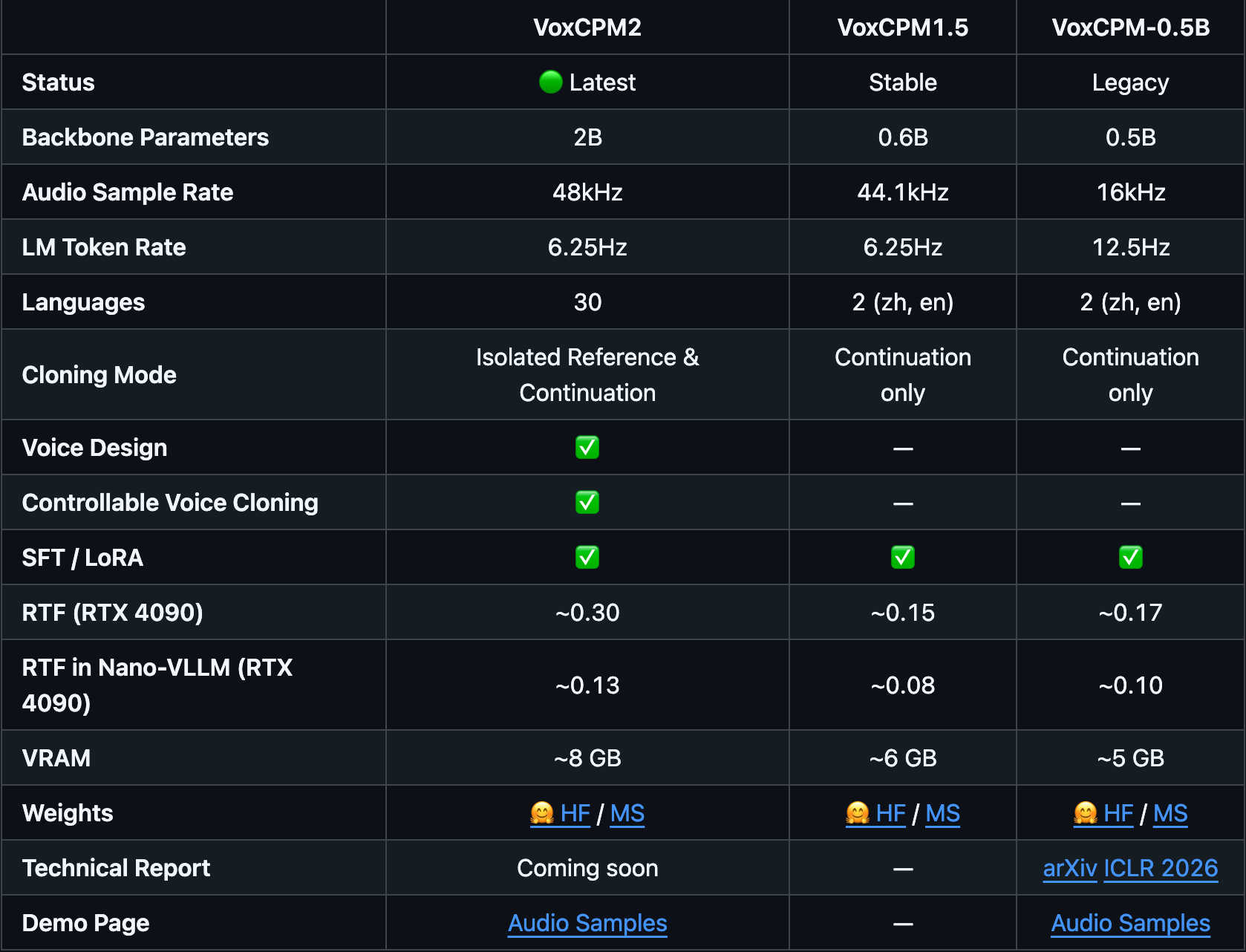
@terry 2.0 可以抽卡設計音色 但不一定抽到好卡
另外增加了日語、韓語及多種方言支援(其他方言我不懂,但日、韓、粵語聽起來都是怪怪的) -
@t68823878 刘悦的包好不好用,我下载了,没怎么测试,主要是voxcpm太好用了,发个帖子分享下啊,付出一点。
-
@terry 就是挺简单根据刘悦那个视频教程来就行了,https://www.youtube.com/watch?v=HUPxh1sCDpA
主要优势就是声音比较自然,AI味不明显,用来设计音色也是很不错的,我弄的语音音色就是用它抽卡抽出来的;
当然我也试了用comfyui工作流来QWEN3 TTS,出来的效果比不上整合包,具体原因我也没有深入研究,整合包出来效果就是要好很多。@t68823878 不要用comfyui部署,直接在linux下就可以部署Qwen TTS, 改天我测试下,上次我记得跑过整合包,稍微体验了下。过几天试试看。
-
@0xsltomorrow 多谢,那意义不大,我不想升级。1.5挺好的,我只做中英文,我感觉够强了,过犹不及。
@terry 對啊 我選他主要是可以本地運行廣東話TTS
而且音色不像Elevenlabs 有點機械音的感覺
用幾十分鐘的內容訓練個LoRa就連上面講會走音的問題也秒殺掉
但有些字他總是讀錯 還在研究怎樣解決 哈 -
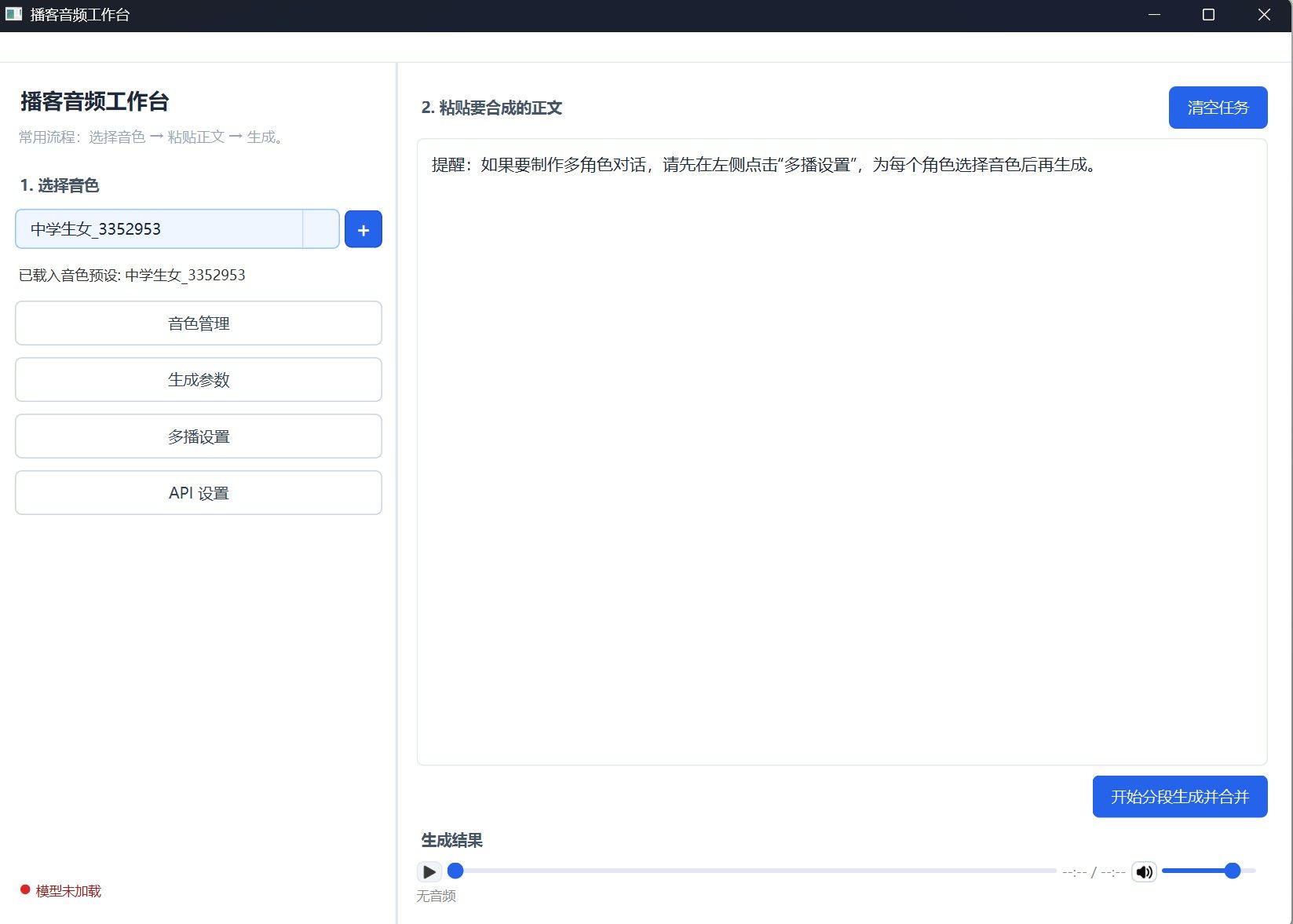
刚刚前几天做了这个项目,我对它进行了很多的魔改,当时也遇到了克隆声音效果不好,必须把参数调得很高,那样的话渲染的时间又很长!
然后通过音色设计,抽卡一个比较靠谱的声音,记住它的种子号!然后又遇到了长文爆显存,后来就变成了分段渲染(刚好可以修改不满意的部分,而不用整段渲染),但是分段渲染,又遇到了同一个种子声音发出了不同的声音!最后想了一个办法,分段渲染时,先渲染一段相同的语句作为参考点(不显示)强制让它分段渲染的声音一致!反正这个项目折腾了很久!总算可以商用的版本!