Llama.cpp如何上传图片
-
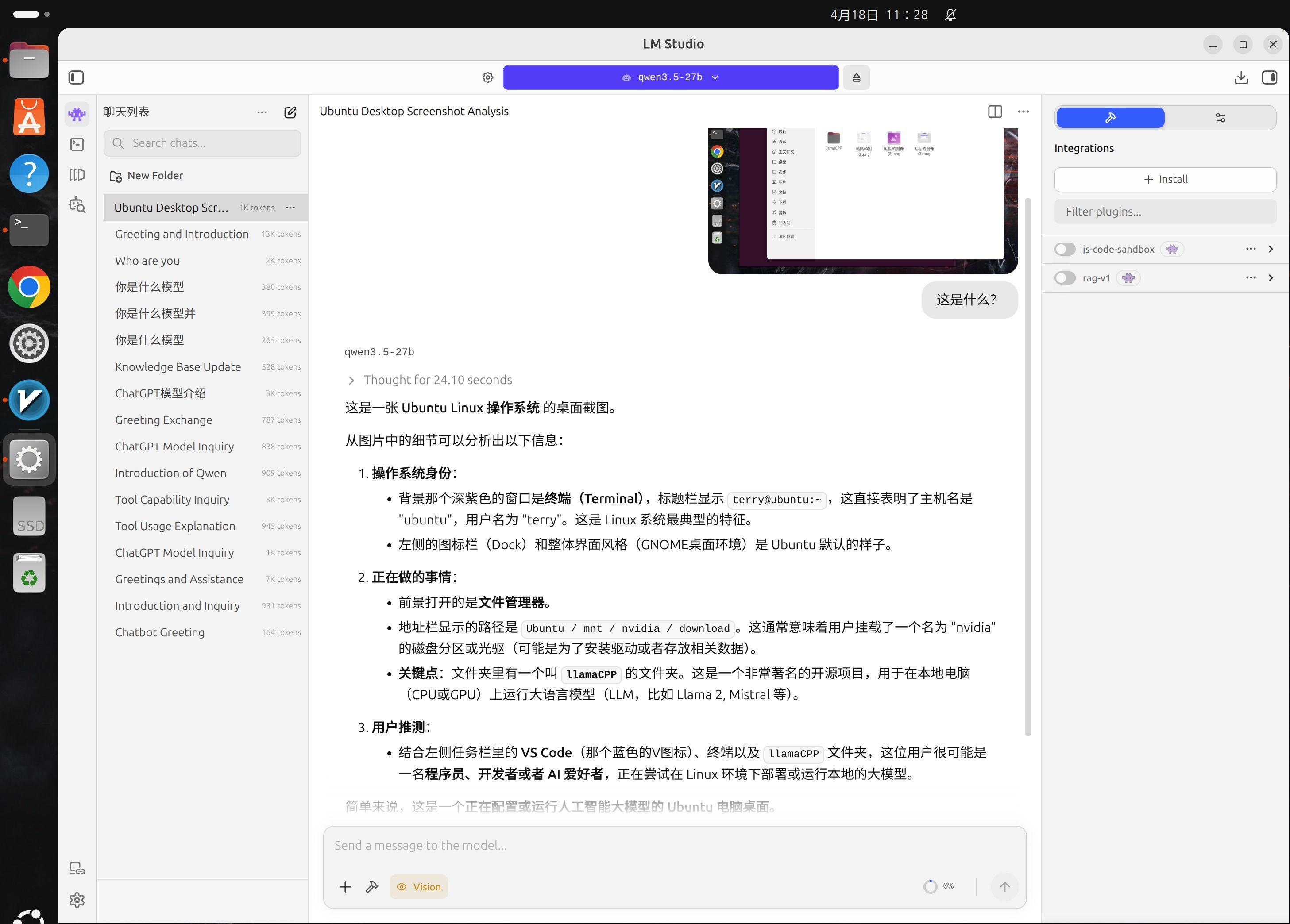
暂时没有测试,我用的是LMStudio,它自带上传图片功能,这是效果图:
ChatBox也支持的,就不上图了。
问了下Gemini,标准的 llama.cpp 本身确实已经内置了对多模态的支持,不需要安装额外的插件,只需通过 llama-server 开启 API 服务即可。
不过,在实际操作中,为了让它“转起来”,有几个关键的技术点需要你留意:
- 核心架构:模型 + 投影器 (CLIP)
虽然你只需发送 API,但 llama-server 在启动时必须加载两个部分:
语言模型 (LLM):负责理解和对话(如 gemma4.gguf)。
视觉投影器 (mmproj):负责把图片“翻译”给模型看(如 gemma4.gguf)。
启动命令示例:
export LD_LIBRARY_PATH=/mnt/nvidia/llama.cpp/build/bin:$LD_LIBRARY_PATH
MODEL_PATH="/mnt/data/ai/lmstudio/.lmstudio/models/lmstudio-community/gemma-4-31B-it-GGUF/gemma-4-31B-it-Q4_K_M.gguf"
/mnt/nvidia/llama.cpp/build/bin/llama-server
-m "$MODEL_PATH"
--host 0.0.0.0 --port 8080
--n-gpu-layers 99
--ctx-size 81920
--parallel 1
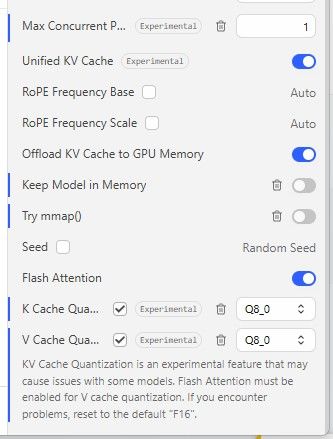
--cache-type-k q8_0
--cache-type-v q8_0
--flash-attn on
--no-mmap
--mlock
--reasoning-budget 0- API 的“标准”格式
llama.cpp 的 API 极力兼容 OpenAI 格式。当你通过代码发送图片时,图片必须转换成 Base64 编码。
一个典型的 Python 调用结构(使用 openai 库):
import base64
from openai import OpenAIclient = OpenAI(base_url="http://localhost:8080/v1", api_key="sk-no-key-required")
图片转为 Base64
with open("image.jpg", "rb") as f:
base64_image = base64.b64encode(f.read()).decode('utf-8')response = client.chat.completions.create(
model="gpt-4-vision-preview", # 这里名字随便写,llama.cpp 会自动对应
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "描述这张图"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}}
],
}
]
)
print(response.choices[0].message.content) - 核心架构:模型 + 投影器 (CLIP)
-
重點是要加載 mmproj 文件,以下是我使用的容器 docker-compose 文件,可以參考 command:
services:
llama-cpp:
image: ghcr.io/ggml-org/llama.cpp:server-cuda
container_name: llama-cpp-cuda
ports:
- "8080:8080"
volumes:
- ~/models:/models
command:
- -m
- /models/Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-Q4_K_P.gguf
- --alias
- Qwen3.6-27B-Q4_K_P
- --host
- 0.0.0.0
- --port
- "8080"
- --mmproj
- /models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
- --n-gpu-layers
- "999"
- --jinja
- --ctx-size
- "131072"
- --chat-template-kwargs
- '{"enable_thinking": false}'
- --metrics
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu] -
重點是要加載 mmproj 文件,以下是我使用的容器 docker-compose 文件,可以參考 command:
services:
llama-cpp:
image: ghcr.io/ggml-org/llama.cpp:server-cuda
container_name: llama-cpp-cuda
ports:
- "8080:8080"
volumes:
- ~/models:/models
command:
- -m
- /models/Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-Q4_K_P.gguf
- --alias
- Qwen3.6-27B-Q4_K_P
- --host
- 0.0.0.0
- --port
- "8080"
- --mmproj
- /models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
- --n-gpu-layers
- "999"
- --jinja
- --ctx-size
- "131072"
- --chat-template-kwargs
- '{"enable_thinking": false}'
- --metrics
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu] -
重點是要加載 mmproj 文件,以下是我使用的容器 docker-compose 文件,可以參考 command:
services:
llama-cpp:
image: ghcr.io/ggml-org/llama.cpp:server-cuda
container_name: llama-cpp-cuda
ports:
- "8080:8080"
volumes:
- ~/models:/models
command:
- -m
- /models/Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-Q4_K_P.gguf
- --alias
- Qwen3.6-27B-Q4_K_P
- --host
- 0.0.0.0
- --port
- "8080"
- --mmproj
- /models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
- --n-gpu-layers
- "999"
- --jinja
- --ctx-size
- "131072"
- --chat-template-kwargs
- '{"enable_thinking": false}'
- --metrics
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu] -
这个图片识别是不是跟模型有关,qwen3.6-27B我问AI说Q4.GGUF是文本模型,让我下载带VL的,我下载了确实能识别
,也不知道是量化作者脱了图片识别能力还是模型本身就不支持