
AMD 5700G 32G 7900XTX windows11 llama.cpp Windows x64 (Vulkan)跑Qwen3.6-35B-A3B-UD-Q4_K_S交作业
-
32k上下文
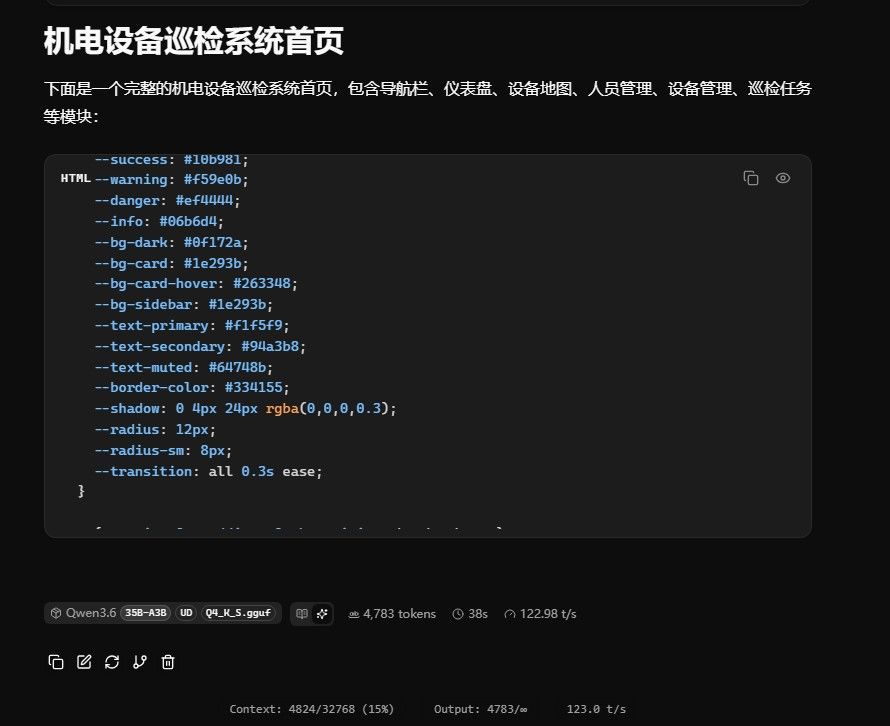
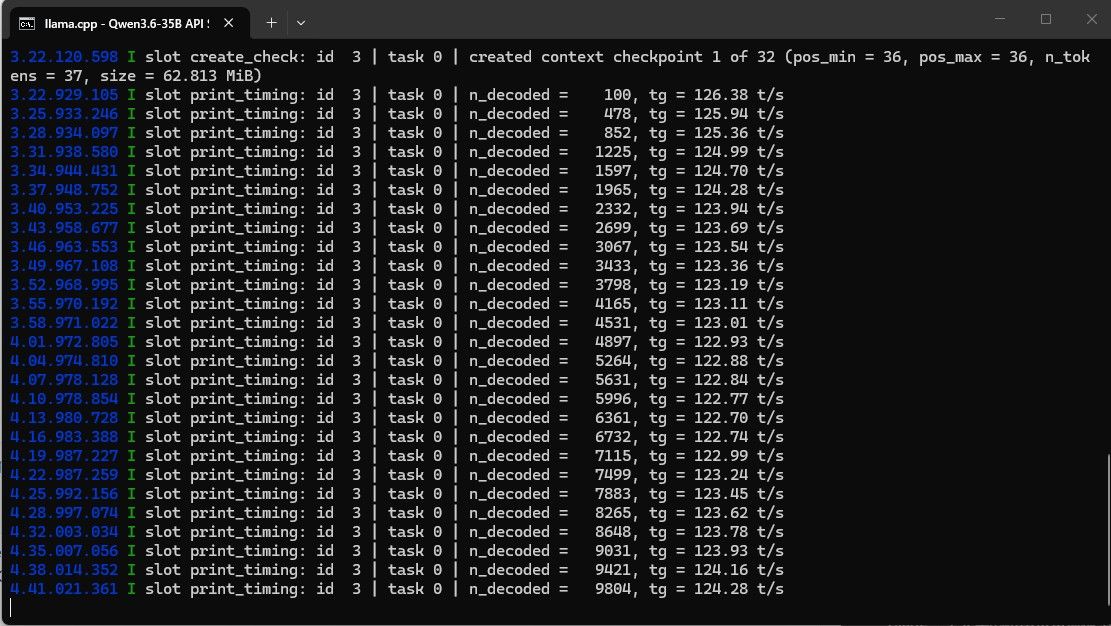
128k上下文
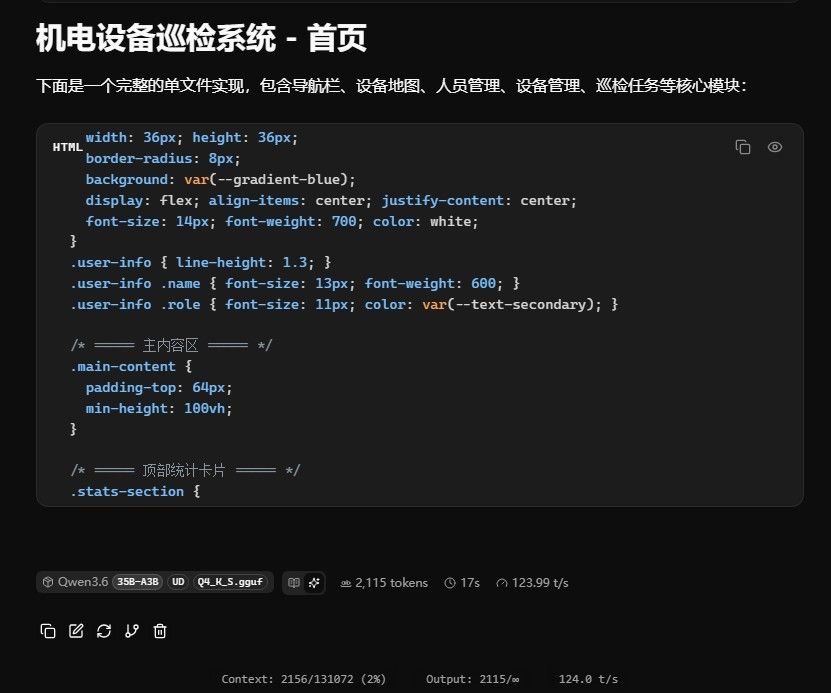
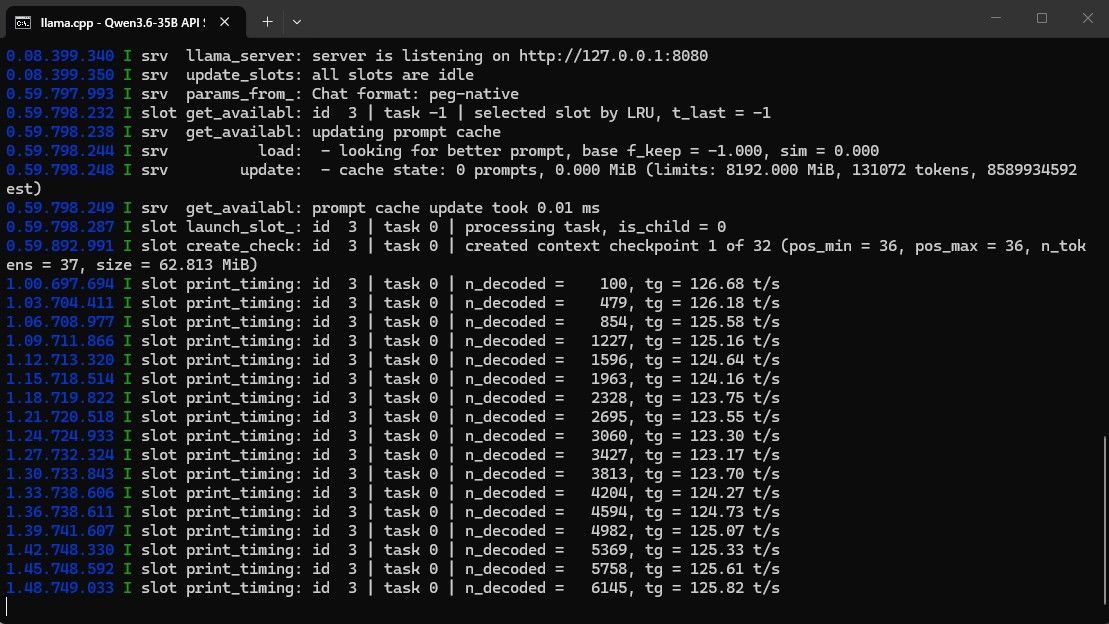

测不动了,感觉128k还不是上限,反正就是越跑系统内存占用越来越大,吐字速度逐渐变慢! -
@echo off
chcp 65001 >nul
title llama.cpp - Qwen3.6-35B API Serverset "SCRIPT_DIR=%~dp0"
set "MODEL=%SCRIPT_DIR%models\Qwen3.6-35B-A3B-UD-Q4_K_S.gguf"if not exist "%MODEL%" (
echo [Error] Model file not found
pause
exit /b 1
)cls
echo ============================================
echo Qwen3.6-35B-A3B -- Select Context Length
echo 256 Experts MoE ^| Only 3B active/token
echo RX 7900 XTX (24GB) ^| 32GB RAM
echo --cpu-moe: experts on CPU, frees VRAM
echo ============================================
echo.
echo # Context VRAM Speed Note
echo -- ------- ------ ------ ---------------------------
echo 1) 32K ~10 GB full GPU, fastest
echo 2) 65K ~12 GB balanced
echo 3) 96K ~14 GB
echo 4) 128K ~16 GB
echo 5) 196K ~19 GB
echo 6) 262K ~22 GB max native context
echo.
set /p ctx="Select (1-6): "if "%ctx%"=="1" set CTX=32768
if "%ctx%"=="2" set CTX=65536
if "%ctx%"=="3" set CTX=98304
if "%ctx%"=="4" set CTX=131072
if "%ctx%"=="5" set CTX=200704
if "%ctx%"=="6" set CTX=262144if "%CTX%"=="" (
echo Invalid selection
pause
exit /b 1
)echo.
echo Starting: %CTX% context
echo http://127.0.0.1:8080
echo."%SCRIPT_DIR%llama-server.exe" ^
-m "%MODEL%" ^
-c %CTX% ^
-fa on ^
-ctk q4_0 ^
-ctv q4_0 ^
-t 8 ^
-b 1024 ^
--no-mmap ^
--no-op-offload ^
--host 127.0.0.1 ^
--port 8080echo.
pause -
@sospda 核显还是差点儿事儿,刚开始学习,以后多提宝贵意见
-
我个人理解楼主这套有几个改进的方向。
1、Q4量化用Q4_K_M的性价比相对K_S更高一些。
2、再对模型吞吐性能要求不高的前提下,可以尝试以下qwen3.6-27B Q4_K_M。理论上讲,配合使用q8的kv量化,可以做到128K上下文。这样能力更好。
3、对于性能参考,楼主可以以llamabench来测试下速度,主要是要综合prefill和decode两个性能一起参考。仅供参考。
@kop-wang 嗯嗯,有时间我试试