
-
 前言
前言看到這個區開了幾天也沒貼文,作為煉丹妹就發個小測試拋磚引玉一下吧

Ai-Toolkit 是一個較易入門的生圖模型 LoRA 訓練工具。作者 Jaret Burkett 大神將它設計得對弱雞系統非常友善(16 GB–32 GB 內存、<24 GB 顯存的系統皆可使用)。
不過,它的模型 Layer Offloading 採用循序執行。當 Rank 達到 512 時,每層的權重矩陣可達數百 MB,未經優化的循序傳輸速度高達 37+ s/it,效率相當低落。
最近,我在 GitHub 上發現了 OrakulStudio 製作的 Viking Engine 補丁(即 patch 安裝包)。它利用「雙緩衝非同步 CUDA 記憶體管理器」加上「強制 bf16 精度」兩大技術,聲稱訓練 Rank 512 LoRA 時可提速 6 倍,而且不會 OOM。
目前討論度不高,GitHub 星數只有可憐的 2 顆(其中 1 顆還是我給的,哈)。但對煉丹妹來說,在同等品質下:
省時間 = 省電費 = 賺更多

一箭三雕的事,當然要去試試看

 適用對象
適用對象 這個補丁適合什麼人?
這個補丁適合什麼人?- 顯存 > 24 GB 的 N 卡用家(支援 bf16 精度)
- 高內存系統(>64 GB,128 GB 更佳)
- 訓練大型模型(FLUX.2、Qwen-Image-Edit、XL 系模型等)
- 使用 Ai-Toolkit 架構作煉丹的用家
- 煉丹時開始遇到不明死機或 OOM 的人
 這個補丁不適合什麼人?
這個補丁不適合什麼人?- A 卡、I 卡等非 N 卡用家(華為的卡能不能用,就等論壇大佬們測試了)
- 低內存系統(16–32 GB)
- 非使用 Ai-Toolkit 架構(如 Kohya_ss)的用家
- 訓練小型模型(不需 Layer Offloading)
- 對現有配置已感到滿意的用家
這個補丁我已經實裝一個多星期,訓練了好幾個 LoRA,提升了不少速度。
但在論壇發文若只貼連結、把原文翻譯成中文,這種 Grok、Gemini 也會做的事感覺沒啥意思,倒不如做個小測試吧。順便驗證一下不同平台間的差異(畢竟作者大神只展示了他在 128 GB RTX 4090 Linux 系統上的結果)

 ️ 安裝方法
️ 安裝方法 ️ 重要聲明:備份!備份!備份!
️ 重要聲明:備份!備份!備份!
請先備份好你的 Ai-Toolkit 工作環境,或建立全新的工作環境再進行操作。下列以 Windows 系統下建立新工作環境作介紹。1. 安裝 Ai-Toolkit
在 CMD 中執行:
cd C:\Projects # 你想運行的目錄 git clone https://github.com/ostris/ai-toolkit.git cd ai-toolkit conda create --name ai-toolkit python=3.12 conda activate ai-toolkit pip install --no-cache-dir torch==2.9.1 torchvision==0.24.1 torchaudio==2.9.1 --index-url https://download.pytorch.org/whl/cu128 pip install -r requirements.txt 原作者使用的是
原作者使用的是 venv,但我個人習慣用conda。2. 備份原檔案
copy jobs\process\BaseSDTrainProcess.py jobs\process\BaseSDTrainProcess_backup.py copy toolkit\memory_management\manager_modules.py toolkit\memory_management\manager_modules_backup.py3. 安裝補丁(即 patch)
curl -o jobs\process\BaseSDTrainProcess.py https://raw.githubusercontent.com/OrakulStudio/ai-toolkit-Ostris-bonememory/refs/heads/main/core/BaseSDTrainProcess.py curl -o toolkit\memory_management\manager_modules.py https://raw.githubusercontent.com/OrakulStudio/ai-toolkit-Ostris-bonememory/refs/heads/main/core/manager_modules.py4. 修改
BaseSDTrainProcess.py用 Notepad++(或其他編輯器)打開
jobs\process\BaseSDTrainProcess.py,找到第 22 行:from huggingface_hub import HfApi, Repository, interpreter_login更改為:
from huggingface_hub import HfApi, interpreter_login try: from huggingface_hub import Repository except ImportError: Repository = None try: from huggingface_hub.utils import HfFolder except ImportError: HfFolder = None5. 運行 Ai-Toolkit WebUI
需要先安裝 Node.js(版本 > 20)
conda install -c conda-forge nodejs cd ui npm run build_and_start
 測試平台
測試平台項目 規格 主板 永擎 ASRock ASRack X570D4I-2T ITX CPU AMD Ryzen 9 3900X 內存 128 GB DDR4 2400 MHz GPU Nvidia RTX 4090 48 GB 儲存 NVMe 4 TB SSD 系統 Windows 10 Pro 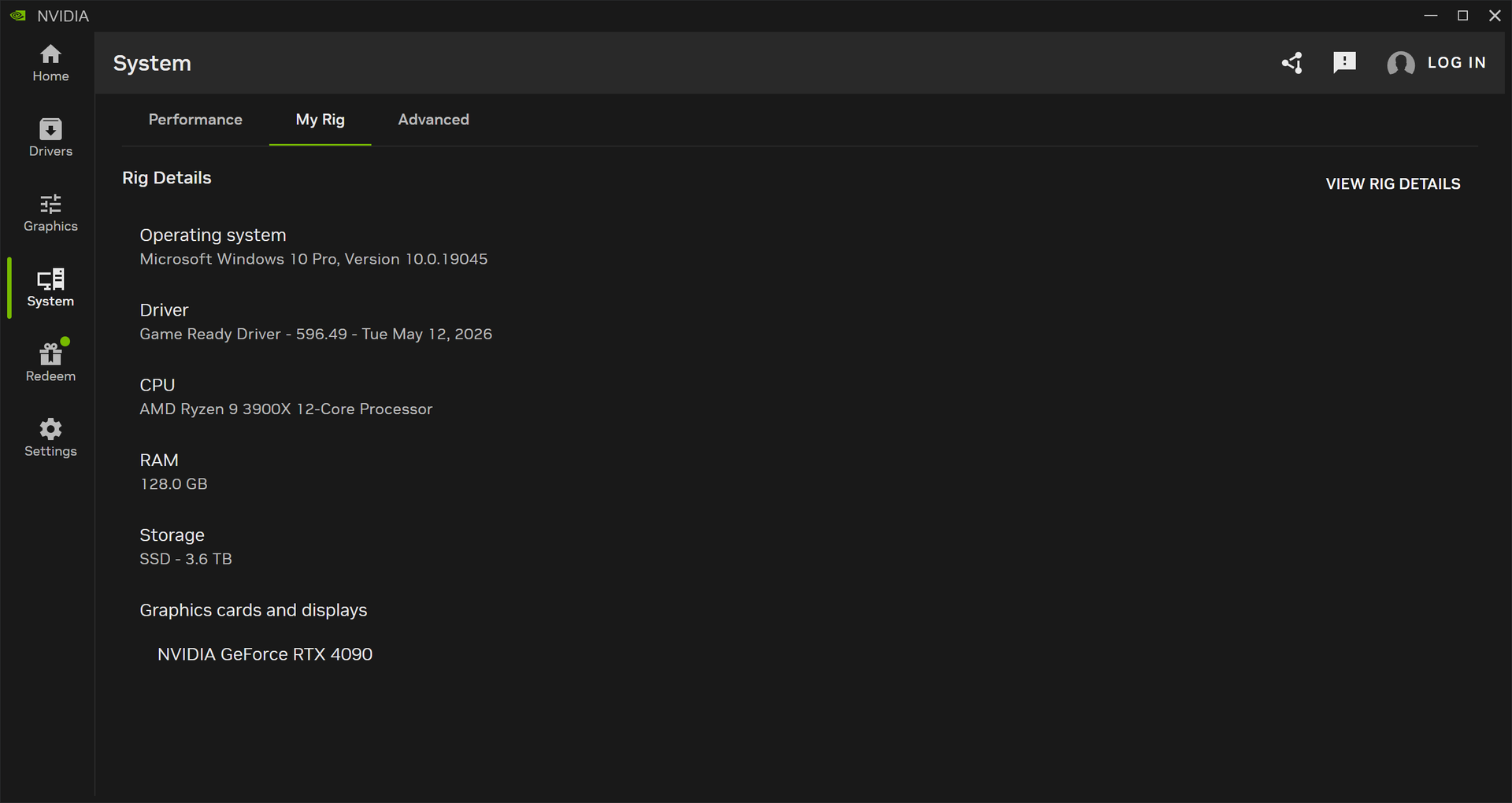
🧪 測試方法
使用 Ai-Toolkit,以 Qwen-image-edit 材質應用資料集 訓練 Qwen-image-edit 2511 LoRA 模型。
訓練參數:
- 精度:bf16
- 解析度:1024 像素
- Learning Rate:1e-4
- 分別在小 Rank(16、32)及高 Rank(64、128)進行比較
 測試結果(模型:Qwen-image-edit 2511)
測試結果(模型:Qwen-image-edit 2511)LoRA Rank 補丁前 補丁後 提升幅度 Rank 16 ~33.73 s/it ~17.63 s/it  ~91%
~91%Rank 32 ~33.66 s/it ~17.50 s/it ~92%Rank 64 ~33.71 s/it ~17.43 s/it ~94%Rank 128 ~34.32 s/it ~28.08 s/it ~22% 測試截圖
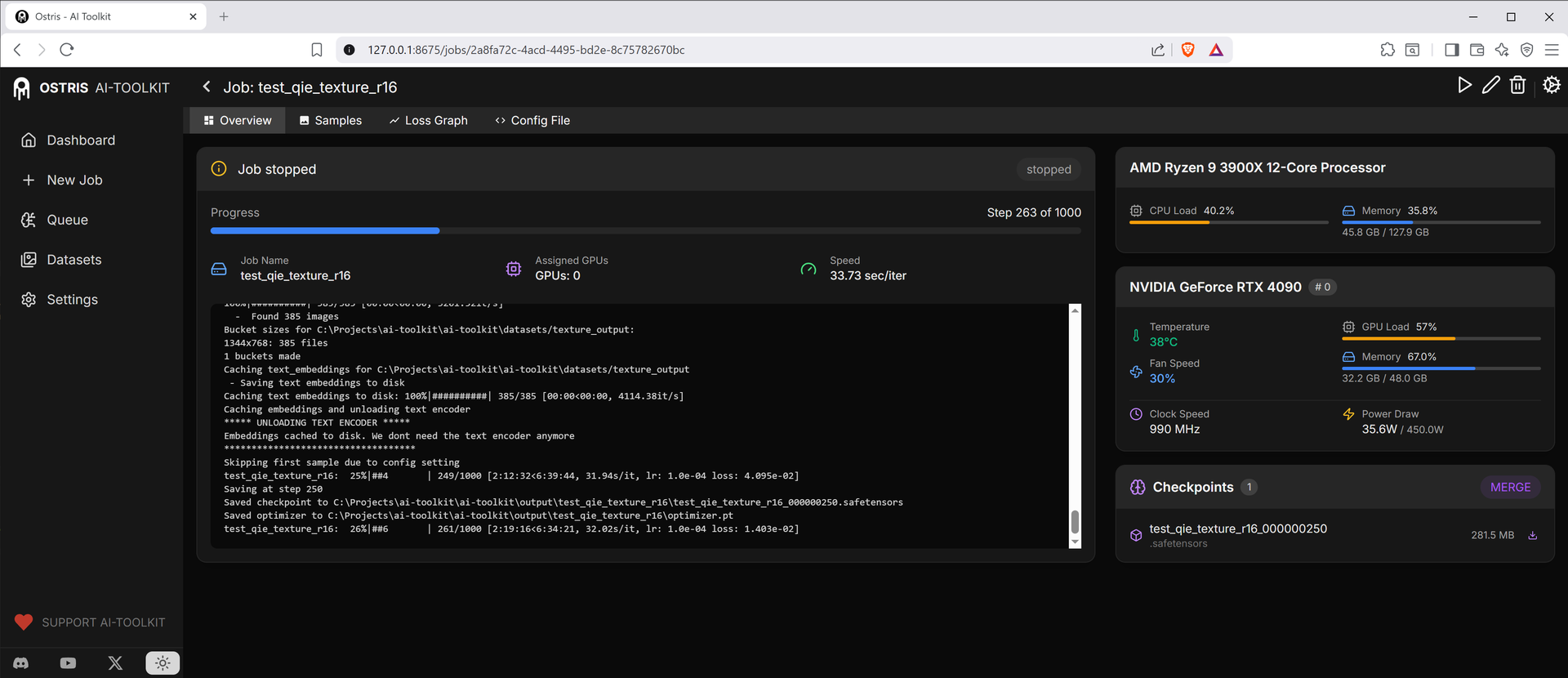
補丁前 Rank 16,平均 ~33.73 s/it
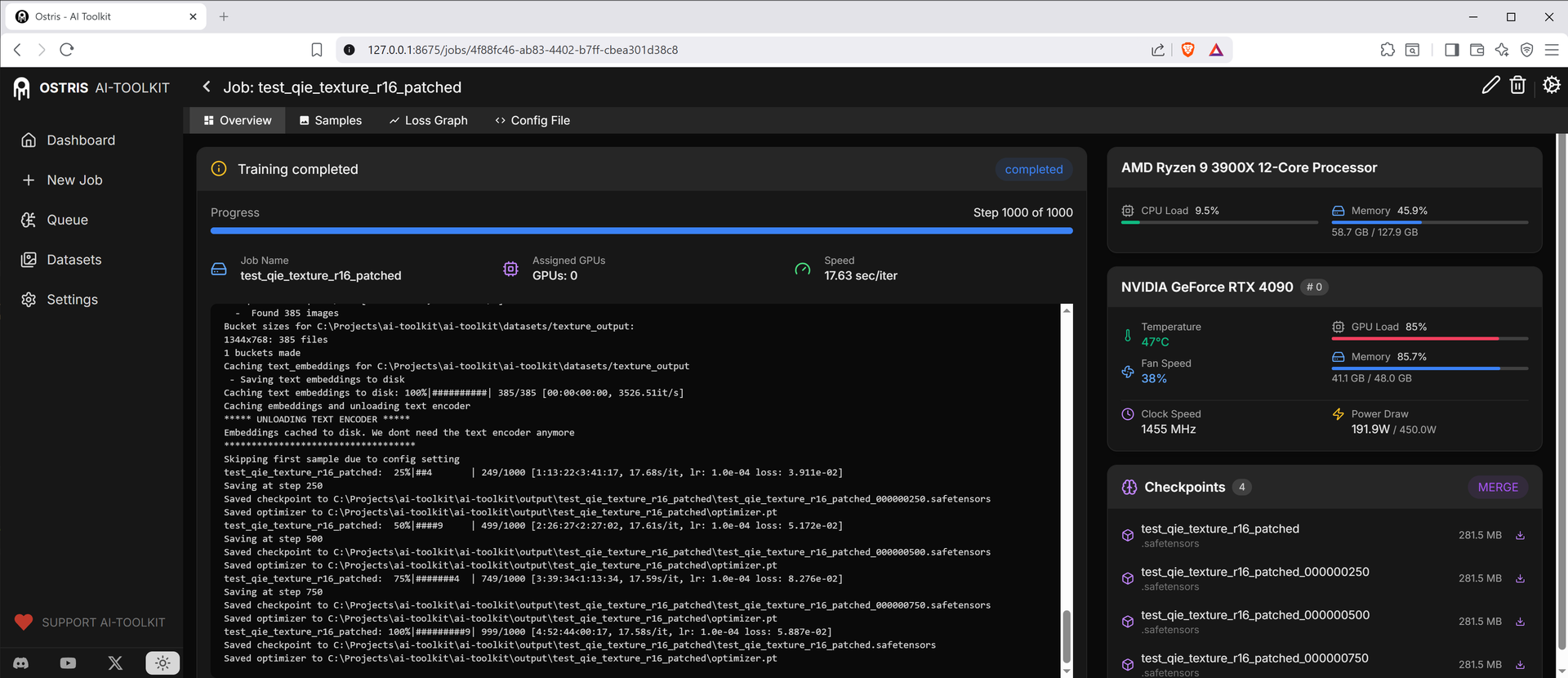
補丁後 Rank 16,平均 ~33.66 s/it
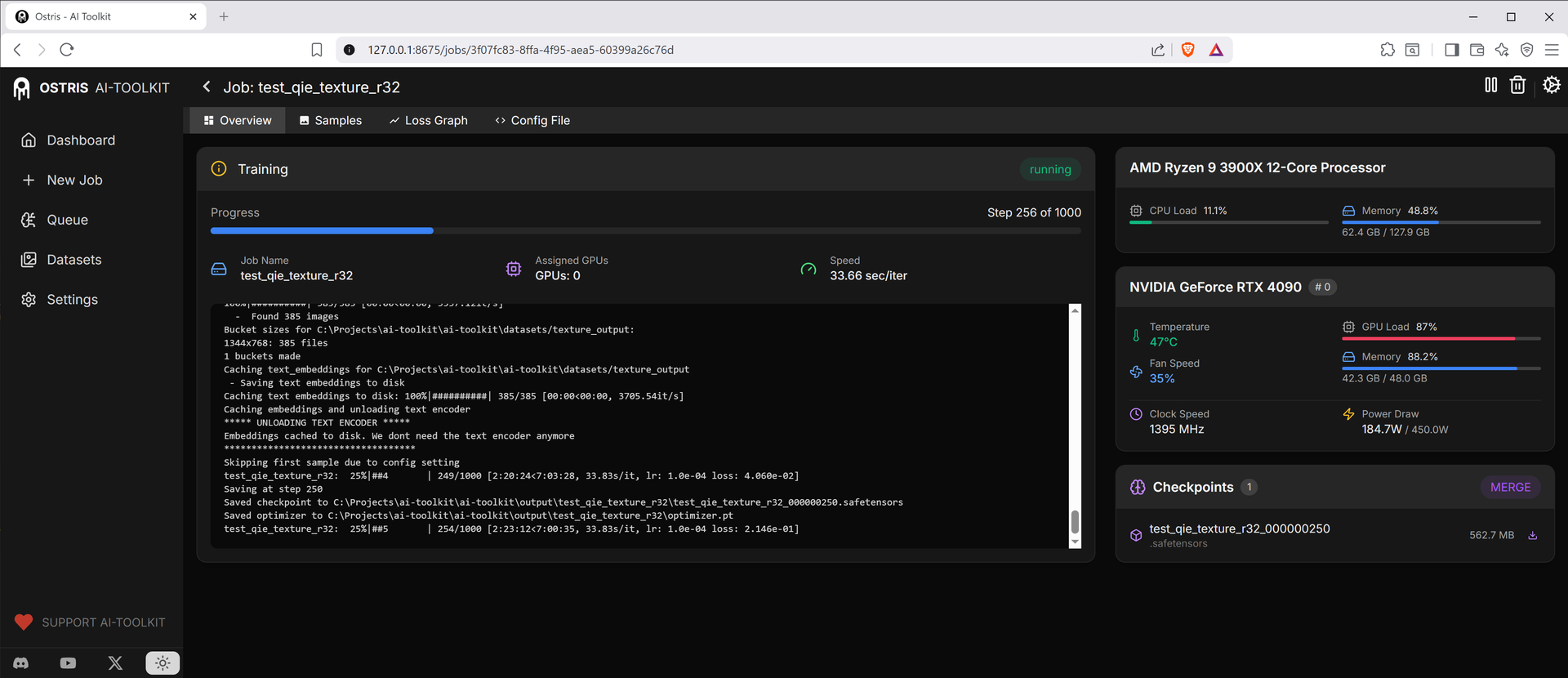
補丁前 Rank 32,平均 ~33.66 s/it
補丁後 Rank 32,平均 ~17.50 s/it
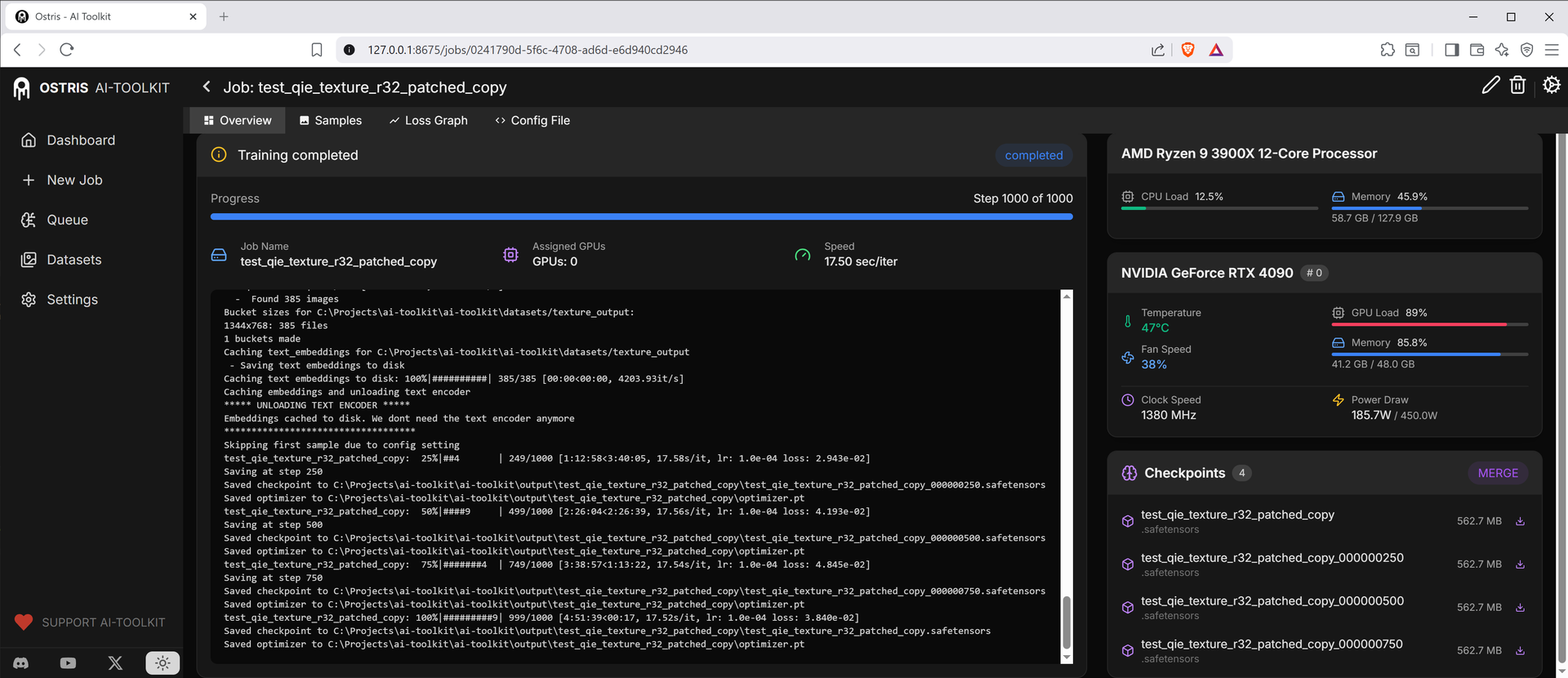
補丁前 Rank 64,平均 ~33.71 s/it
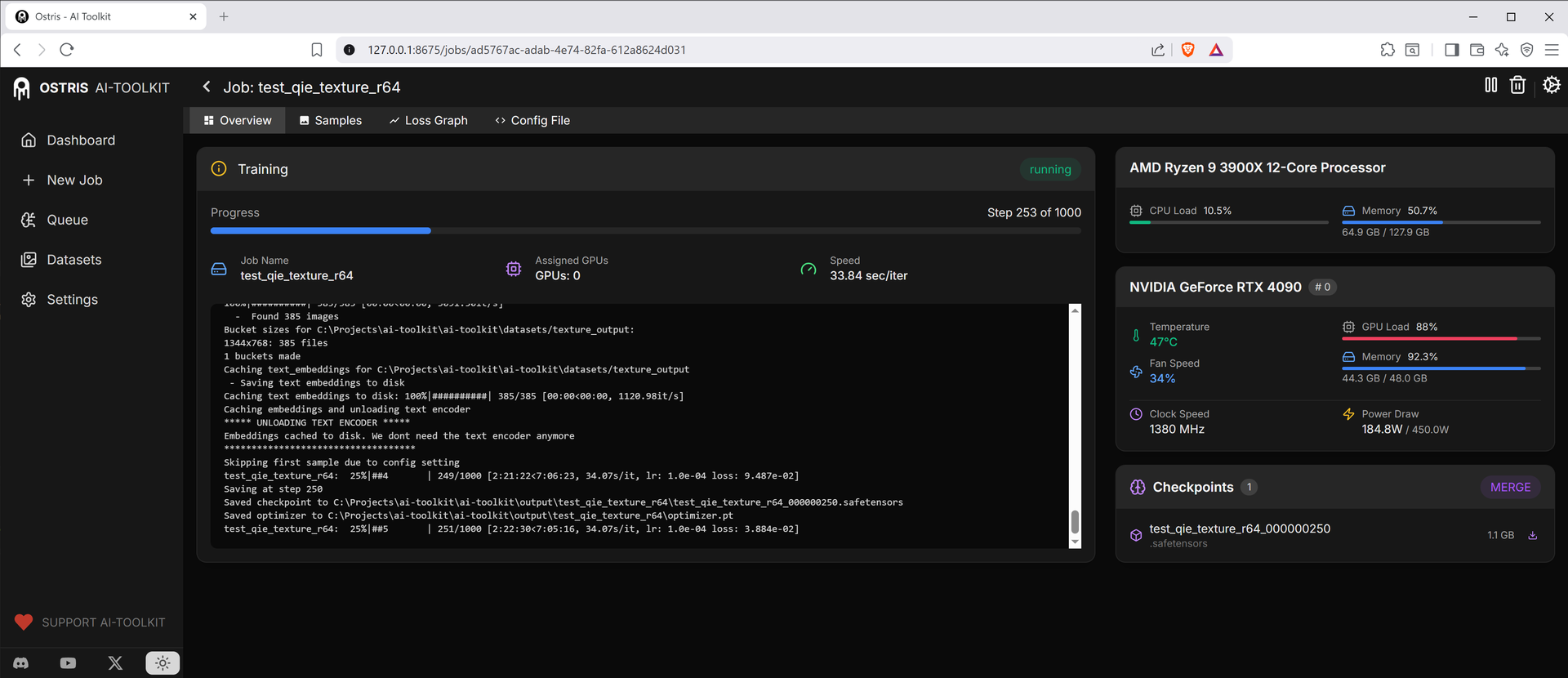
補丁後 Rank 64,平均 ~17.43 s/it
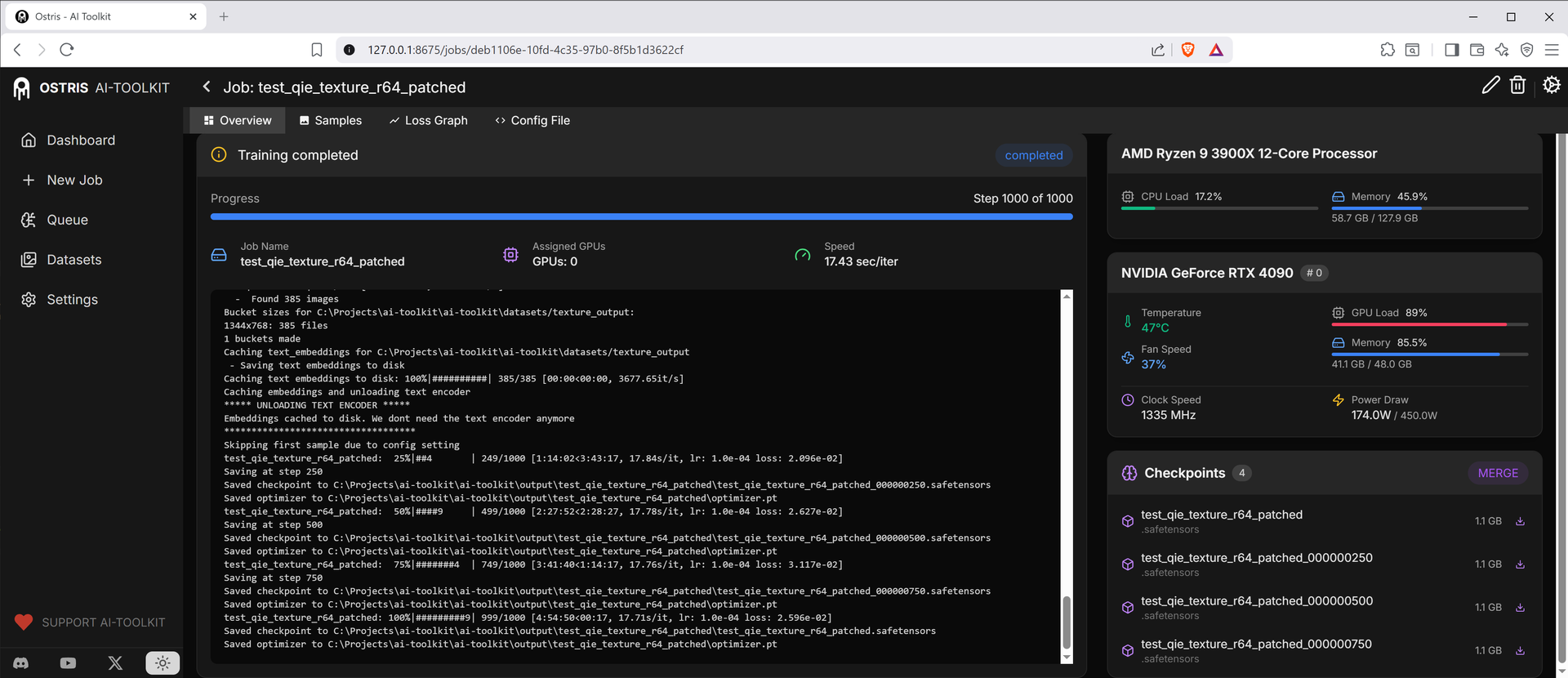
補丁前 Rank 128,平均 ~34.32 s/it
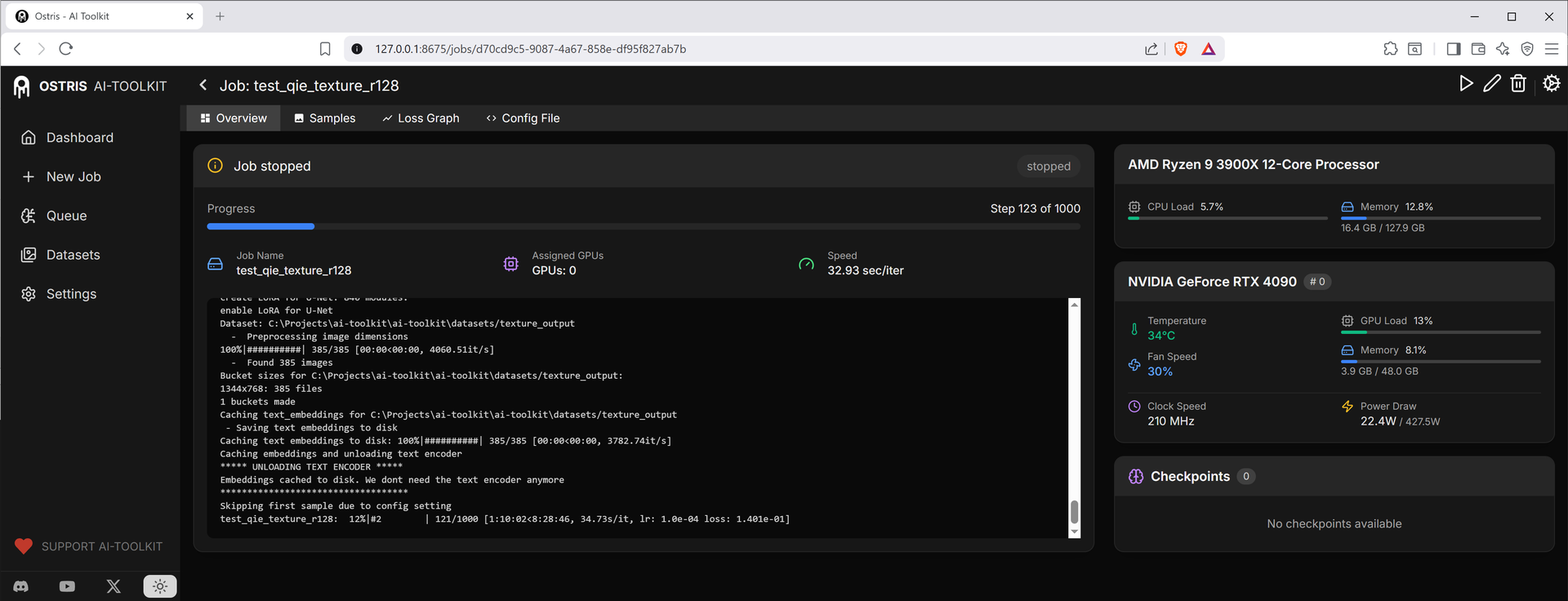
補丁後 Rank 128,平均 ~28.08 s/it
 結論
結論雖然速度上有顯著改善,但為什麼不能達到原作者所宣稱的大幅度提升呢?
翻查 作者的訓練紀錄 後發現,他是用 512 像素作訓練測試,與本次測試使用的 1024 像素相差約 4 倍運算量。
雖然未能達到原作者數倍的提升,但在較常用的 Rank 32、Rank 64 上仍有接近 90% 的速度提升,對煉丹來說絕對是一個值得折騰的修改!
 適用建議
適用建議- 如果你主要訓練 1024 解析度的 LoRA,建議搭配此補丁,可獲得約 90% 的速度提升。
- 如果你主要跑 512 解析度,提升幅度會更為驚人(依作者實測可達六倍)。
如果有更多測試結果,歡迎在留言區交流分享~祝大家煉丹愉快!

 ️ 後記
️ 後記可能你會問:為什麼沒有測試 Rank 512 呢?其實我有測試過,但因為 CUDA Error 而沒有得出結果。跟 AI 交流幾輪後發現,應該是 Windows + PyTorch 的相容性問題,有時間再轉移到 Linux 系統試試吧

最後呢,本技術之教學純屬研究性質,獲得本技術後的所有生成產物(包括但不限於文字、圖片,音訊、影片等),皆與技術提供者無關。
修合無人見,存心有天知。
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
4090.。。48G 真的很能打。一代神卡了。
-
系统 于 取消固定此主题
-
,T terry 将此主题从 Mark专区 移至此处