
廉頗老矣,尚能飯否? 測試tesla V100 32Gx2 部署Qwen 3.6 27B Q8模型
-
前幾天看著平常編程在用的洋垃圾, 突然想搞個顯卡來跑跑qwen 3.6 27B. 看了半天, 台灣這邊魔改卡不好買, 也都是天價. 7900XTX基本沒人在賣, R9700兩張又太貴, 就入了兩張Nvidia TESLA v100 32G來試試.
電腦本來只有BMC顯示, 所以驅動啥的都沒裝, 只有裝ubuntu 26.04.
各論壇看了看, 鎖定llama.cpp + Qwen3.6-27B-UD-Q8_K_XL.gguf , 然後把相關資料交給gemini cli去安裝, 大概一個小時它就把NVIDIA 驅動,CUDA其他相依軟件及設定搞好, llama.cpp編譯完成, 該避的坑避掉, 模型下載完然後就跑起來了, 全程無干預.
再來就是跟它花了大概兩個小時測試調整, 主要是一開始的prefill慘不忍睹, 花很多時間在長文本測試優化. 調到一個滿意的設定, 就差不多了, 整個過程還挺順利的.
底下是我電腦的基本資訊:系統與硬體狀態
- 作業系統: Ubuntu 26.04 LTS
- CPU: AMD EPYC 7K62
- RAM: 128GB DDR4
- GPU 硬體: 2x NVIDIA Tesla V100-SXM2-32GB
- PCIe 連線: Gen3 x16 (狀態良好)
- 平均溫度: Idle 35°C / 滿載 ~45°C
- 功耗限制: 300W
目前的狀態大概是這樣:
服務運行狀態
- 服務名稱:
qwen36-llama.service - 執行引擎:
llama.cpp(CUDA 70架構優化編譯版) - 載入模型:
Qwen3.6-27B-UD-Q8_K_XL.gguf
當前模型參數配置 (終極優化版)
- 總 Context 空間:
524,288tokens - 併發能力 (Parallel):
2路 (每路262,144tokens) - KV Cache 精度:
q8_0 - MTP 加速: 啟用 (
draft-mtp, 最大預測數:2) - Batching 設定: Batch 1024, UBatch 256
效能與資源佔用指標
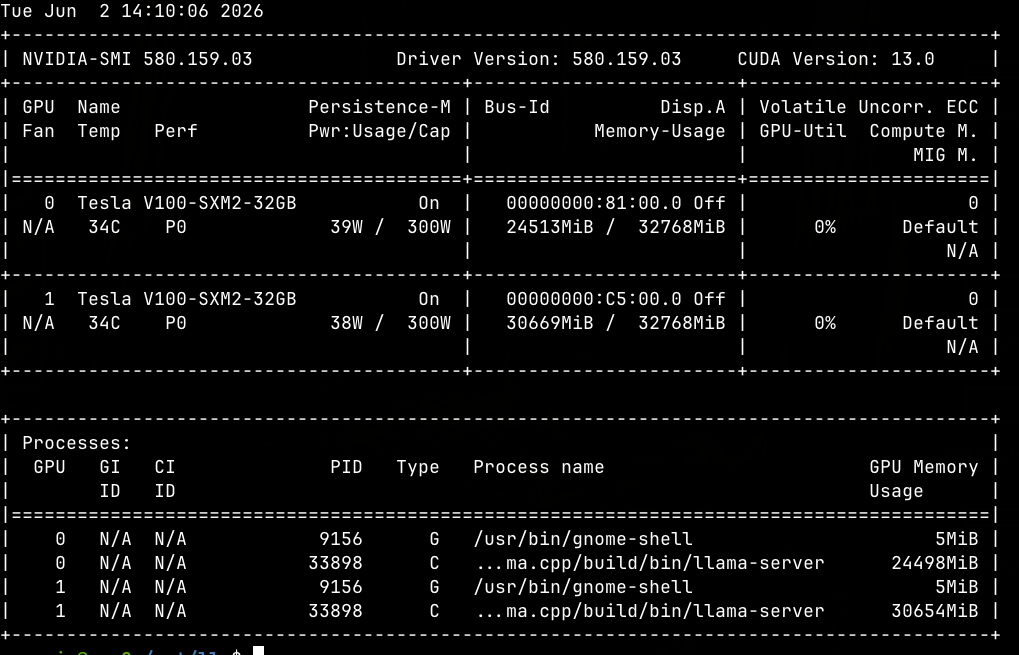
VRAM 記憶體佔用
系統已確保 100% 的權重與 KV Cache 駐留於 VRAM 中,完全不依賴系統 RAM 進行 offload,徹底解除 PCIe 頻寬瓶頸。
- GPU 0 佔用: ~24.3 GB
- GPU 1 佔用: ~30.3 GB
- 總計佔用: 54.6 GB
- 安全餘裕: 剩餘約 9.4 GB,足以應付 Batch 1024 運算時產生的動態 Scratch Buffer 需求。
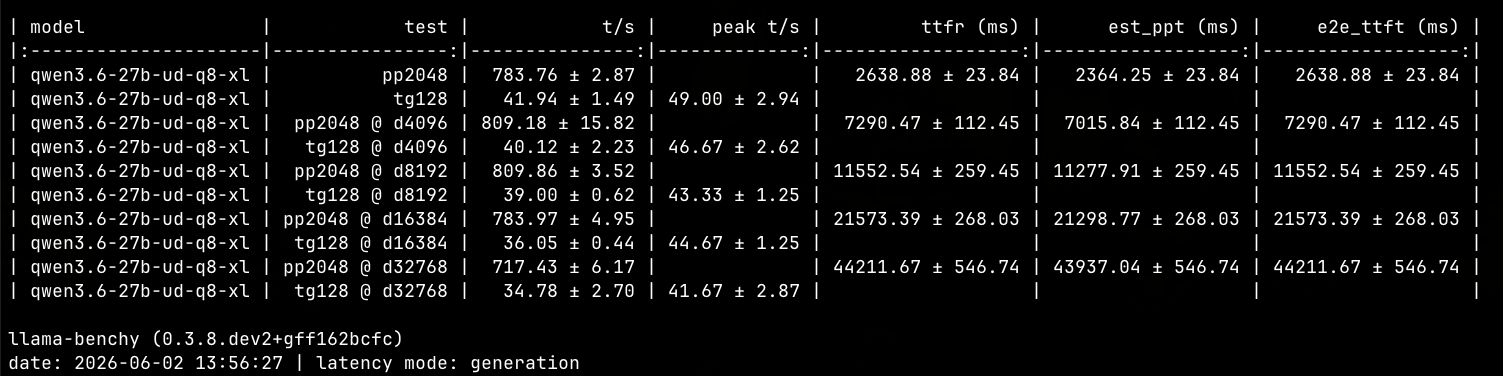
推理速度 (實測)
- Prompt Processing (Prefill): 最高可達 ~611 tokens/second (長文測試)。
- Generation (Decode): 穩定於 ~40 tokens/second。
- MTP 接受率: 約 79% ~ 100% (極高效率)。
以上是Gemini寫的報告, 中間有多次參數設定調整, 比較如下:
效能測試結果總表
測試組合 3路 256K (無MTP) 2路 256K (MTP 2) 1路 256K (B256, mtp2) 1路 256K (B512,mtp2) 1路 256K (B1024,mtp2) 2路 256K (B1024,mtp2) 1. 成功啟動 是 是 是 是 是 是 2. VRAM Used (GPU0/1) 27.8/31.2 GB 23.7/29.1 GB 19.3/23.8 GB 19.6/24.5 GB 19.9/25.1 GB 24.3/30.3 GB 3. Prefill (t/s) 90.31 42.02 (短文) 263.93 395.94 611.04 23.01 (短文) 4. Generation (t/s) 20.87 37.24 46.64 43.09 40.65 40.06 5. MTP 接受率 N/A 79% 100% 100% 100% 87.5% 6. 是否 OOM 否 否 否 否 否 否 7. 數據位置 部分 RAM 部分 RAM 純 VRAM 純 VRAM 純 VRAM 純 VRAM 8. GPU Power (0/1) 51W/49W 51W/49W ~50W/50W 52W/52W 53W/53W 51W/49W 9. GPU Temp (0/1) 35°C/35°C 34°C/33°C 35°C/35°C 39°C/40°C 39°C/41°C 34°C/34°C 定案之後看了一下vram占用狀態跟跑一下benchmark:
心得:
- 一樣是qwen3.6 27B Q8模型, 實際使用速度約比雙spark高出5~10 token/s, prefill速度也還行. 不過雙spark可以容納約15路並行, 這台電腦礙於vram容量, 只能兩路.
- 渦輪風扇實在太吵, 必須關到小房間... 早知道不要嫌麻煩買個水冷...
-
 T terry 固定了该主题
T terry 固定了该主题
-
系统 取消固定了该主题