
-
我也是在纠结这个问题,comfyui也不是全天都在跑,闲置的时候就感觉挺浪费的,如果再装一台来分任务感觉又多花了钱。如果用PRO 6000跑comfyui,然后hermes直接接入DEEPSEEK V4的话,这样是不是就舒坦多了,主要是DEEPSEEK费用比较便宜。或者说是跑comfyui的时候hermes就调用DEEPSEEK API,不跑的时候就调用本地QWEN3.6 27B。
-
我也是在纠结这个问题,comfyui也不是全天都在跑,闲置的时候就感觉挺浪费的,如果再装一台来分任务感觉又多花了钱。如果用PRO 6000跑comfyui,然后hermes直接接入DEEPSEEK V4的话,这样是不是就舒坦多了,主要是DEEPSEEK费用比较便宜。或者说是跑comfyui的时候hermes就调用DEEPSEEK API,不跑的时候就调用本地QWEN3.6 27B。
-
这个问题也是我这两天一直在折腾的问题,现在已经初步有了个眉目。先说结论:
结论是可以,架构是vLLM + qwen3.6-27b-NVFP4(3并行)+ ComfyUI(Qwen-Image-Edit-BF16)
或者vLLM + qwen3.6-27b-FP8(2并行)+ ComfyUI(Qwen-Image-Edit-FP8)我的提示词是这样的:
我现在要在本地部署vLLM运行qwen3.6-27b来推理Hermes也就是你。在飞书远程工作的同时,还要用到本地的ComfyUI工作流进行文生图或者图改生图,大多是Qwen-Image-2512,少量用到Qwen-Image-Edit,这些模型都在/home/bentonyi/ComfyUI-master/models/unet,你可以自己看。目前的qwen3.6-27b模型情况是有一个NVFP4量化,一个FP8量化。
以上是具体现状,我的底线要求是:
1,任何条件下不能触发把KV Cache放到内存里交换让CPU跑的情况;
2,上下文128k满载、并发2倍冗余以内、mtp种子为4的极端情况下vLLM不得oom;
3,在qwen3.6-27b和comfyUI工作流并行任务期间,假设一旦出现显存吃紧或者占满,崩溃运行失败的只能是comfyUI,vLLM不得受到任何影响(因为我要远程处理,vLLM和hermes必须在线);
你给我推荐一个建议运行的qwen3.6模型版本,以及相对应vLLM的运行参数(尤其是留足comfyUI工作显存后的推荐并发上限)这是智力密集型的plan类工作,我直接祭出了deepseek-v4-pro连hermes。中间查硬件,查模型,查量化版本以及把量化的详细过程算给我看的过程就省略了,各位可以以自己的实际情况对应的提示词去deepseek在线问。最后hermes给出了最前面的结论。还给我画了显存分配明细:
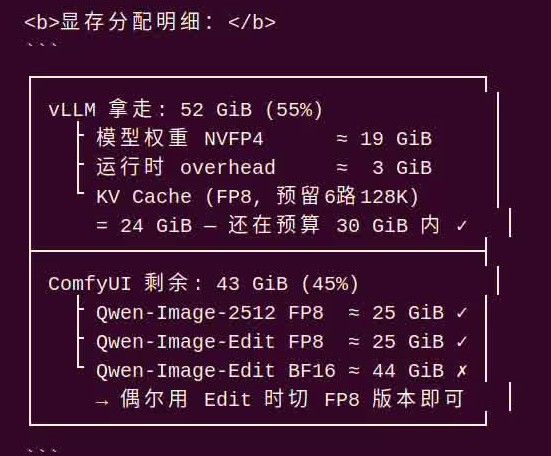 │
│
而且已经经过底线验证: 不触发 CPU swap — KV Cache 全在 GPU,48 层 SSM 不吃 KV
不触发 CPU swap — KV Cache 全在 GPU,48 层 SSM 不吃 KV- 128K × 6 并发 × MTP=3 → KV 24 GiB < 预算 30 GiB,不会 OOM
- ComfyUI 先崩 — 它的 43 GiB 上限比 vLLM 的 52 GiB 硬限制先到
- MTP=4 对本模型的 KV 影响极小(MTP 只有 1 层额外 full_attn,开销 < 100 MiB)
- Qwen-Image-Edit BF16 只在切换使用 FP8 版本时可保平安
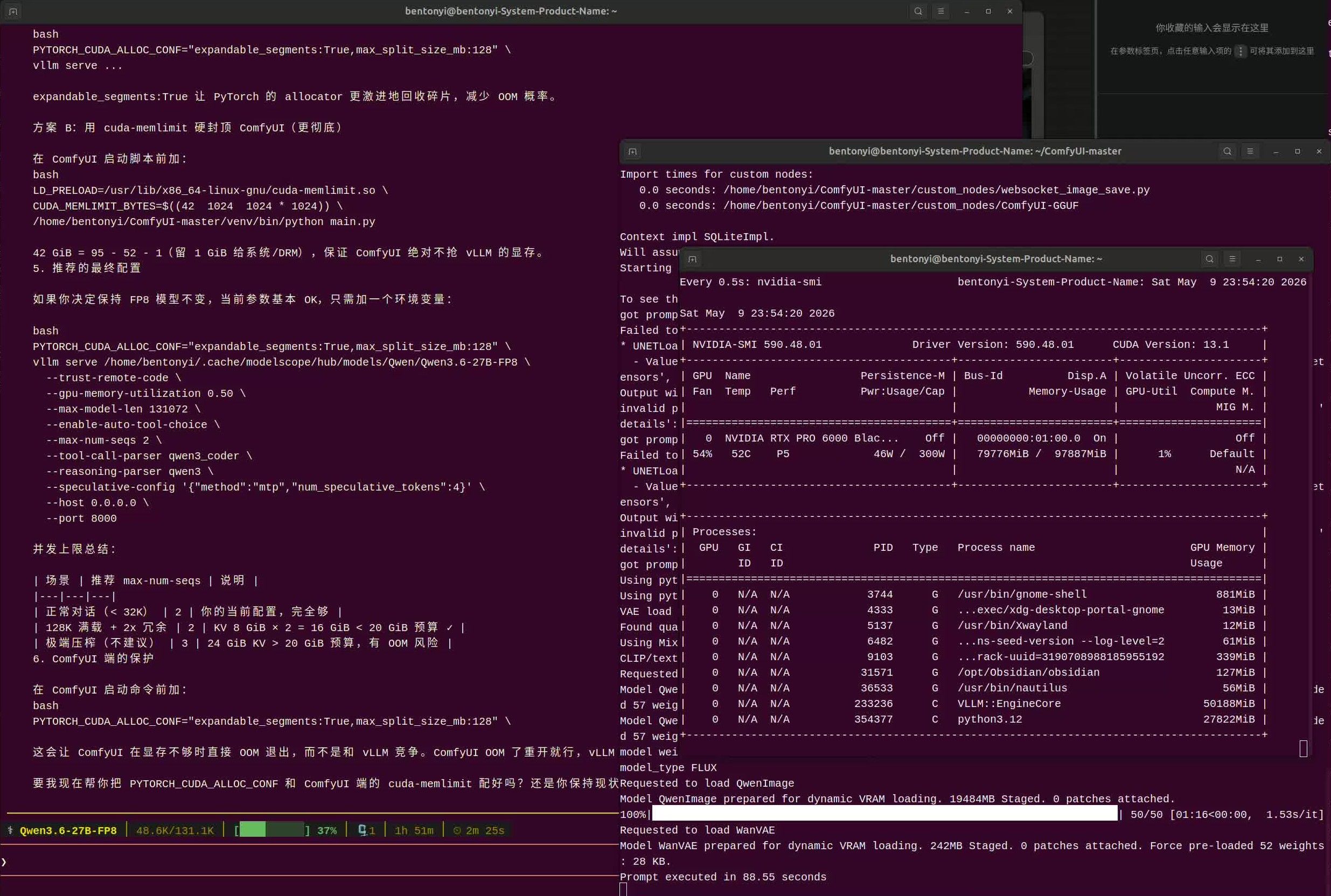
最后这张图是我的实际测试,显存占用和ds说得几乎一模一样。 -
pro6000 虽然有96gb显存,常规部署vllm+qwen3.6-27B-FP8 上下文128k 没怎么优化,显存占用大概89GB,再部署comfyui 跑视频,就爆显存了;如果改为qwen3.6-27B-Q4量化版,256K 上下文才34GB,同时可以部署comfyui音视频;问题来了,请教,同时部署,跑视频的时候,本地模型会不会卡,hermes 做复杂任务的时候会有会有问题,如何有问题,是再部署一台,模型和音视频分开?还是可以再加一块32GB 的显卡,把模型跑再32GB显卡上,comfyui跑在pro6000上?求大神指导!
@Dalu-Fama 回你这个显存占用89G的问题,你vLLM启动参数一定没有加 --gpu-memory-utilization 0.50 参数,你不加参数就默认是0.9。划掉你显存的90%给vLLM专用。影响实际显存占用的因素有:
--gpu-memory-utilization 0.50 \ #预设显存池
--max-model-len 131072 \ #上下文长度
--max-num-seqs 2\ #最大并发数
实际上我就是跑的FP8量化,MTP投机种子设4的时候显存占用也就52G,用来跑BF16的Qwen-Image-Edit也不会oom。 -
这个问题也是我这两天一直在折腾的问题,现在已经初步有了个眉目。先说结论:
结论是可以,架构是vLLM + qwen3.6-27b-NVFP4(3并行)+ ComfyUI(Qwen-Image-Edit-BF16)
或者vLLM + qwen3.6-27b-FP8(2并行)+ ComfyUI(Qwen-Image-Edit-FP8)我的提示词是这样的:
我现在要在本地部署vLLM运行qwen3.6-27b来推理Hermes也就是你。在飞书远程工作的同时,还要用到本地的ComfyUI工作流进行文生图或者图改生图,大多是Qwen-Image-2512,少量用到Qwen-Image-Edit,这些模型都在/home/bentonyi/ComfyUI-master/models/unet,你可以自己看。目前的qwen3.6-27b模型情况是有一个NVFP4量化,一个FP8量化。
以上是具体现状,我的底线要求是:
1,任何条件下不能触发把KV Cache放到内存里交换让CPU跑的情况;
2,上下文128k满载、并发2倍冗余以内、mtp种子为4的极端情况下vLLM不得oom;
3,在qwen3.6-27b和comfyUI工作流并行任务期间,假设一旦出现显存吃紧或者占满,崩溃运行失败的只能是comfyUI,vLLM不得受到任何影响(因为我要远程处理,vLLM和hermes必须在线);
你给我推荐一个建议运行的qwen3.6模型版本,以及相对应vLLM的运行参数(尤其是留足comfyUI工作显存后的推荐并发上限)这是智力密集型的plan类工作,我直接祭出了deepseek-v4-pro连hermes。中间查硬件,查模型,查量化版本以及把量化的详细过程算给我看的过程就省略了,各位可以以自己的实际情况对应的提示词去deepseek在线问。最后hermes给出了最前面的结论。还给我画了显存分配明细:
│
而且已经经过底线验证:- 不触发 CPU swap — KV Cache 全在 GPU,48 层 SSM 不吃 KV
- 128K × 6 并发 × MTP=3 → KV 24 GiB < 预算 30 GiB,不会 OOM
- ComfyUI 先崩 — 它的 43 GiB 上限比 vLLM 的 52 GiB 硬限制先到
- MTP=4 对本模型的 KV 影响极小(MTP 只有 1 层额外 full_attn,开销 < 100 MiB)
- Qwen-Image-Edit BF16 只在切换使用 FP8 版本时可保平安
最后这张图是我的实际测试,显存占用和ds说得几乎一模一样。 -
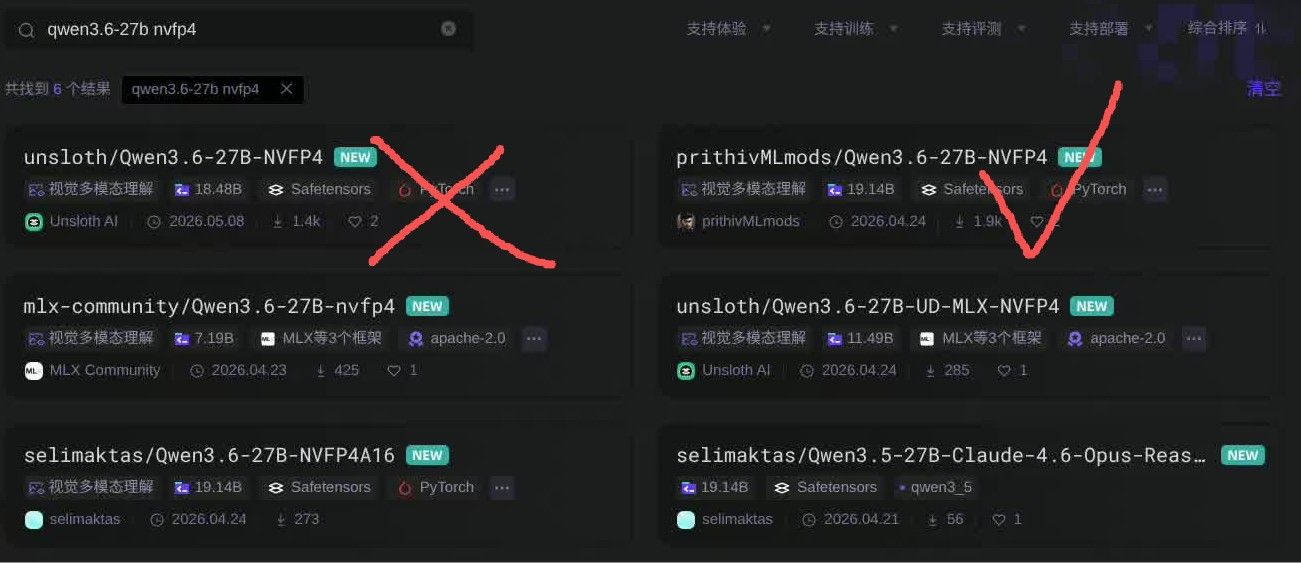
对了,如果有blackwell架构想要极致省显存想选择NVFP4量化的朋友,别选unsloth的版本(截至5月8号),这个版本没有MTP投机权重文件vLLM下无法开启MTP(SGLang可开因为用的是NextN模块)。下右边这个版本就行。 @benton-yi 非常感谢大佬分享!
@benton-yi 非常感谢大佬分享! -
@Dalu-Fama 回你这个显存占用89G的问题,你vLLM启动参数一定没有加 --gpu-memory-utilization 0.50 参数,你不加参数就默认是0.9。划掉你显存的90%给vLLM专用。影响实际显存占用的因素有:
--gpu-memory-utilization 0.50 \ #预设显存池
--max-model-len 131072 \ #上下文长度
--max-num-seqs 2\ #最大并发数
实际上我就是跑的FP8量化,MTP投机种子设4的时候显存占用也就52G,用来跑BF16的Qwen-Image-Edit也不会oom。 -
@benton-yi 后来我--gpu-memory-utilization 0.7,mtp没设置,256k上下,大概占用70多,虽然NVFP4要小很多,但是感觉还是fp8才是王者,有时候会比deepseek flash版本还要好,重度任务多时候Fp8从来没卡壳过,dp卡过几次,你的优化以及感觉极至了,并发 只有2或者3,多agent感觉还是有点难,我感觉如果要用的爽,极至生产力,不如再加一张4090或者2张ai pro r9700 并行,
-
VLLM_ATTENTION_BACKEND=FlashInfer VLLM_PROFILER_ESTIMATE_CUDAGRAPHS=1 python3 -m vllm.entrypoints.openai.api_server
--model /models/qwen/Qwen3.6-27B-FP8
--trust-remote-code
--max-model-len 102400
--kv-cache-dtype fp8_e4m3
--gpu-memory-utilization 0.55
--enable-chunked-prefill
--enable-prefix-caching
--max-num-batched-tokens 8192
--max-num-seqs 2
--speculative-config '{"method": "mtp", "num_speculative_tokens": 3}'
--served-model-name "Qwen-27B-FP8"
--enable-auto-tool-choice
--tool-call-parser qwen3_coder
--reasoning-parser qwen3
--host 0.0.0.0
--port 8000
我用的这个参数,然后comfyui做的生成视频工作流,研究了一晚上暂时没有崩过,comfyui跑起来的额时候能到40GB左右的样子通常不会超过40GB。vllm我之前设置的0.58也不会崩,后面为了保险降到了0.55;不过我这是100K上下文,暂时就我一个人在用。
不清楚如果后面有并发了会不会崩。 -
 T terry 于 将此主题从 AI硬件 移至此处
T terry 于 将此主题从 AI硬件 移至此处
