最終版 AMD RX 7900XTX 24GB 跑 Qwen3.6-27B Hermes Agent — 從 Win11 Vulkan 到 Ubuntu ROCm 的完整實戰與踩坑全紀錄含雙卡
-

 # RX 7900 XTX 跑 Qwen3.6-27B Hermes Agent — 從 Win11 Vulkan 到 Ubuntu ROCm 的完整實戰與踩坑全紀錄
# RX 7900 XTX 跑 Qwen3.6-27B Hermes Agent — 從 Win11 Vulkan 到 Ubuntu ROCm 的完整實戰與踩坑全紀錄原本已經優化的差不了,看到大神Dflash60-80t/s我又折騰了快三天,出動codex cloude code 最終把dflash修成可以用hermes的版本,但速度最終提不上,最終棄坑,最後還是走最早之前的win11 +vulken的腳本 mtp投機,抄該腳本得到一個還不錯的結論,分享給大家,讓大家少走歪路,從中也學了許多,歡迎大家多分享發文,才會一起更懂這個新世界。
一張 7900 XTX、一個 27B 稠密模型、一個接 Telegram 的 Hermes agent,目標 45+ tok/s。
這篇把所有試過的路、所有踩過的坑、所有真實數據攤出來分享。結論可能跟你想的相反:
繞了一大圈、研究了 DFlash 等各種花招,最後贏在把設定拉回最樸素的「純 MTP n=3」。
0. TL;DR(先給結論)
- 可用解:
llama.cpp(HIP/ROCm)+ Qwen3.6-27B-Q4_K_M + 純 MTP 投機解碼(--spec-type draft-mtp --spec-draft-n-max 3)。在真實 Hermes 加密分析 agent 上 decode 37–51 tok/s,工具調用尤其快。 - 最大教訓:RDNA3 上 MTP 投機 n=3 是甜點,n=4 過度投機反而把接受率壓垮。這點被 Win11 報告、Lucebox DFlash 社群報告、跟我自己的真實 log 三方獨立印證。
- 走錯的路:(a) 疊 ngram 草稿器(對中文分析輸出沒貢獻還拉低整體接受率);(b) 改用 DFlash(block-diffusion 草稿器,benchmark 數字漂亮但不適合長系統提示的 agent,詳見第 4 節)。
- 戰略真相:ROCm 單卡相對 Win11 Vulkan 是「側升」不是「提升」。而且實測兩張 7900 XTX 跑 llama.cpp 雙卡,generation 反而更慢(28 vs 單卡 37 t/s,無 NVLink、每步 decode 走 PCIe 同步)——雙卡只贏 prefill。要真的破 50–60 天花板,唯一沒測過的路是 vLLM tensor-parallel(理論 120–150,但那是跟 llama.cpp 雙卡完全不同的機制)。
1. 硬體與目標
項目 內容 GPU 撼訊 地獄犬 丐版 雙8Pin 以後比較好處理? 哈 AMD Radeon RX 7900 XTX 24GB ×2(Navi 31 / gfx1100 / RDNA3),顯存帶寬 ~960 GB/s/卡;兩卡走 PCIe 4.0 x16、無 NVLink/fabric 直連。LLM 日常用單卡,另一張平時跑 ComfyUI CPU AMD Ryzen 9 7950X 照片是洋垃圾 最終的設備主板是 ASUS TUF X670E-PUS WIFI 可雙卡pcie-x8+x8 32G DDR5-6000 OS / 驅動 Ubuntu,ROCm 7.2.0(gfx1100 需 HSA_OVERRIDE_GFX_VERSION=11.0.0)模型 Qwen3.6-27B 稠密 Q4_K_M(~16 GB),含 MTP 層 用途 Hermes Agent 接 Telegram,跑加密貨幣盤勢分析、工具調用 目標 decode ≥ 45 tok/s、context 32K→64K、工具調用要正常、不能 OOM 限制 第二張卡跑 ComfyUI(port 8188)不能動;既有 production fallback 腳本不能覆蓋
2. 完整速度數據(最終可用配置:純 MTP n=3)
全部是 RX 7900 XTX 單卡、ROCm 7.2.0、Q4_K_M、KV q4_0、真實工作負載實測。
2-1 Hermes agent(接 Telegram,含 6.6k token 系統提示 + 工具)
請求類型 decode tok/s MTP 接受率 備註 工具調用(結構化 JSON 輸出) 47–51 80–88% 最快,JSON 超好預測 長篇中文盤勢分析(10k+ context) 36–37 54–56% 長 context + novel 輸出 prefill(冷啟動 9.5k tokens) 734 tok/s — ~13s prefill(checkpoint 復用) ~600 tok/s — 新 token 才算,~2s 2-2 純模型回應速度(無工具、短提示、自由生成,各跑一次)
內容 decode tok/s 接受率 中文散文 38.9 56% 中文文章(區塊鏈介紹) 39.6 58% 中文條列清單 39.7 58% 中文對話問答 40.3 59% 中文翻譯改寫 43.7 67% 程式碼生成(Python + 測試) 42.2 64% 英文散文 41.7 62% 英文技術說明 41.1 61% 平均 ~41 56–67% 反直覺但真實的發現:純對話(~41)比工具調用(47–51)慢。原因是 MTP 投機解碼的速度跟「輸出可預測性」直接掛勾——固定格式的 JSON 工具調用接受率 80–88%,自由中文/英文散文只有 56–67%,所以反而慢。速度不是固定值,是隨輸出內容浮動的。
2-3 長 context 速度(重要:幾乎不掉速)
context 長度 decode tok/s 接受率 prefill ~10K 37–51 54–88% 734 tok/s ~38K 37.5 69% 578 tok/s 補一個更高的點(~60K context):decode 34.1 tok/s、接受率 70%——從 10K 到 60K 只掉約 8%,不是斷崖。推到 128K 滿載約 ~28–32 tok/s。
context decode tok/s ~10K 37–51 ~38K 37.5 ~60K 34.1 128K(推估) ~28–32 長 context decode 速度掉得很慢——Qwen3.6 是 hybrid SSM 架構,64 層裡只有 16 層有 attention(會隨長度變貴),其餘 48 層是 SSM 遞推(無 KV、成本與長度無關),加上 q4_0 KV 極省。因此 ctx-size 開到 128K 也只是極限長度才略降速。
VRAM 實測:
--ctx-size 131072(128K)在 24GB 7900 XTX 上啟動佔用 21GB(含預配的 128K KV cache),留 ~3.5GB 餘裕,可行。跑超長對話時建議瞄rocm-smi,逼近 24GB 就降到 96K(--ctx-size 98304)。這也呼應 Win11 當時「80K–128K 速度沒差多少」的觀察。2-4 實戰補充:128K 腳本多輪真實 session(telegram 加密 agent)
實際用 128K 腳本連續跑了 12 輪真實 Telegram 加密分析請求(ctx-size 設 128K,實際對話長度落在 13K–20K token)。體感很順,數據如下:
輸出型態 接受率 decode tok/s 樣本 工具調用 / 結構化 71–93% 42–51 51.0 / 48.7 / 47.2 / 46.2 / 41.8 … 自由中文分析(長文) 50–57% 34–36 34.7 / 34.0 / 34.5 / 36.2 … prefill(後續輪次):靠 llama-server 的 context-checkpoint 自動復用,後續每輪只 prefill 新 token(459–568 tok/s,約 1–7 秒),不是每次重算整個 prompt。每個 checkpoint ~158–172 MiB、隨位置緩慢長大,restore 僅 ~17–20 ms。
三個結論:
- 128K ctx-size 在實際 13–20K 對話下完全不拖慢 decode——預先配置的 128K KV 不影響 decode 速度,decode 只付「實際 context 長度」的注意力成本(不是 ctx-size 上限)。設大 ctx-size 是免費的保險。
- 速度雙峰、由輸出型態決定:工具調用 JSON 接受率 71–93% → 42–51 tok/s;自由中文分析接受率 50–57% → 34–36 tok/s。這就是「體感不錯」的原因——agent 互動主力是工具調用,正好落在快的那一檔。
- context-checkpoint 讓多輪對話的首 token 延遲很低,這對 Telegram 即時互動比「純 decode 峰值速度」更重要。
3. 時間線:每個階段做了什麼
階段 0 — 起點:Win11 + Vulkan,本來就有 50–80 tok/s
最早在 Windows 11 原生 + llama.cpp Vulkan 上就跑得很好,配置極簡:
llama-server.exe -m Qwen3.6-27B-Q4_K_M-mtp.gguf(froggeric 版,含 MTP 層) --device Vulkan0 -ngl 999 -c 65536 -ctk q4_0 -ctv q4_0 -np 1 --spec-type draft-mtp --spec-draft-n-max 3 ← 關鍵:純 MTP,n=3 --reasoning off -fa 1實測(Hermes 結構化輸出):
場景 TG MTP 接受率 系統提示暖機(14k) 62.8 95.6% Telegram 指令 60–74 72–98% 直接 API 短句 79.9 — 關鍵調參結論(當時就驗證過):
- KV cache q8_0 → q4_0:Vulkan 後端 q8_0 有嚴重 prefill 瓶頸,q4_0 沒有(prefill 273→730 tok/s)。
- n=3 是甜點,n=4 過度投機反降(n=2→43.3、n=3→47.3、n=4→40.7)。
--reasoning off:不關的話 Qwen3 thinking budget 預設無限,會生 8000+ token 卡死整個 queue。
Hybrid SSM 架構(Qwen3.6)的 KV cache 無法跨對話複用,每次都要重跑全部 prompt,這是正常現象。
階段 1 — 為何想搬到 ROCm(遷移研究)
當時想突破 50–80,做了 WSL2/ROCm/vLLM 升級研究。研究結論(事後看完全命中):
路線 速度預估 對 Hermes 現狀 Vulkan + MTP 單卡 60–80  已夠用
已夠用ROCm llama.cpp 單卡 無 MTP 29  太慢
太慢ROCm llama.cpp 單卡 有 MTP 67 當時有 context 只剩 4K 的 bugvLLM ROCm 單卡 80–100  ️ 64K 壓線、長對話 OOM 風險
️ 64K 壓線、長對話 OOM 風險vLLM ROCm 雙卡 tensor-parallel 120–150 真正的提升「WSL2/ROCm 單卡對 Hermes 是側升不是提升」——白紙黑字寫在研究裡。真正提升要雙卡 vLLM。
ROCm 遷移的三個地雷(避免重蹈):
- 不設
HSA_OVERRIDE_GFX_VERSION=11.0.0→No AMD GPUs found(gfx1100 預設識別失敗)。 - ROCm 版本要鎖,別讓 apt 亂升。
- (WSL2)vLLM 的 amdsmi 不通,要改用 PyTorch 偵測 GPU;且絕不能在 WSL2 裡裝 amdgpu kernel driver。
階段 2 — 搬到 ROCm 後反而變慢:設定「漂移」
搬到 Ubuntu + ROCm 後,配置不知不覺從證明過的「純 MTP n=3」漂移成:
--spec-type draft-mtp,ngram-mod,ngram-map-k4v(疊了兩個 ngram 草稿器)--spec-draft-n-max 4(不是 3)
結果真實加密 agent 只剩 ~22–25 tok/s。比 Win11 還慢。
階段 3 — 一頭栽進 DFlash(漂亮的 benchmark,錯的方向)
詳見第 4 節。簡言之:DFlash 社群報告在 7900 XTX 上跑出 68.8 tok/s,看了手癢,花了大把時間在它身上 debug、改 code、修 bug……最後發現它的數字是短程式碼 benchmark,套到長系統提示的 hermes agent 上只有 ~23 tok/s。
階段 4 — 找回速度:拉回 Win11 配方
翻出當年的 Win11 報告,發現答案一直都在:純 MTP n=3。把 ROCm 的設定拉回去(去掉 ngram、n=4→3),真實 agent 立刻從 ~22 跳到 ~43 tok/s(工具調用 47–51),接受率從 36% 回到 54–88%。問題就是設定漂移,根因解決。
4. DFlash 深入研究:為什麼社群的 68 tok/s 用不到 Hermes agent
這節獻給所有看到 Reddit/論壇「DFlash 在 7900 XTX 跑 68 tok/s」而心動的人。
4-1 DFlash 是什麼
Lucebox DFlash 是一種投機解碼法,用輕量 block-diffusion 草稿模型並行起草,再用 DDTree 樹狀驗證。社群(lcz.me / Reddit)在 7900 XTX + Qwen3.6-27B 上實測:
方案 tok/s 說明 純自回歸基線 30.8 — ROCm MTP n=3 47.3 純 MTP(就是我們最後用的) DFlash Q8 draft + budget=8 68.8  社群最佳
社群最佳DFlash Q4 draft + budget=22 27.0 Q4 反量化拖慢 + 樹太大 4-2 致命前提:那 68.8 是怎麼測的
社群用
bench_he.py——10 道 HumanEval 程式題,prompt 只有 ~300 token,純解碼,binary 熱機。- 程式碼輸出超好預測(接受率 30–40%,AL 4.8)
- prompt 短 → 草稿每步只處理 ~300 token、驗證 context 短
- 同一份報告也寫:用
run.py單 prompt(含 prefill)只剩 56 tok/s
4-3 為什麼套到 Hermes agent 就崩
Hermes agent 是三重不利,跟 HumanEval 完全相反:
因素 HumanEval bench Hermes 加密 agent 系統提示 ~300 token 6,600 token 輸出性質 程式碼(好預測) 中文盤勢分析(novel) context 短 10k–14k 實測 DFlash daemon 在真實 agent 上:18–25 tok/s,接受率只有 11–18%。比純 MTP(~43)還慢一半。
4-4 過程中挖出的 DFlash 真實 bug(修了也救不回)
DFLASH27B_DRAFT_CTX_MAX=512從沒生效過:程式碼是min(ring_cap, max(2048, draft_ctx_max)),那個max(2048,…)把任何 <2048 的設定強制拉回 2048。改成讓明確設定值生效後,draft 每步成本下降,decode 從 13 拉到 23——但還是不到 45。- 長系統提示讓 draft 成本爆炸:DFlash 草稿每步處理
min(committed, draft_ctx_max)個 token。6.6k 系統提示後就是每步重算數千 token,draft_compute 從 ~12ms(短 prompt)暴增到 ~160ms。這是 13.6× 差距的根源。 DFLASH27B_CHUNKED=1是毒藥:號稱能並行 SSM 加速,實測造成 loopy/畸形輸出、接受率腰斬。別開。- per-request 重載:用 Python 包的 server 每個請求都重新 spawn 進程、
--no-mmap重載 16GB 模型,互動式 Telegram 每則訊息付數十秒延遲——直接「沒回應」當掉。要用常駐 daemon。
結論:DFlash 適合「短 context + 程式碼/結構化」的 batch 工作,不適合「長系統提示 + 自由中文 + 即時互動」的 agent。 它的 block-diffusion 草稿在我們的場景反而是負擔。
5. 雙卡實驗(2× 7900 XTX):為什麼日常還是用單卡
既然有兩張 7900 XTX,自然想用雙卡加速。花了最多時間做的就是「分割模式決戰」,結論非常反直覺。
5-1 分割模式實測(128K context,tg = 生成速度)
模式 tg(生成) prefill(輸入) 備註 --split-mode layer --tensor-split 1,1~30 ~350 VRAM 分攤好,生成有跨 GPU 等待 --split-mode tensor --tensor-split 6,5~32 ~420 prefill 快,生成有 all-reduce 開銷 --device ROCm0,ROCm1 --tensor-split 6,5~28 ~445 prefill 最快,tg 最慢 單卡(GPU0 only) ~37 ~380 tg 最快 5-2 結論:雙卡贏 prefill、輸 generation
兩張 7900 XTX 沒有 NVLink / Infinity Fabric 直連,雙卡資料交換得走 CPU
 PCIe。 每個 decode 步驟都要跨卡同步,所以:
PCIe。 每個 decode 步驟都要跨卡同步,所以:- prefill(一次處理整個 prompt):雙卡能並行,445 vs 單卡 380,快 ~18%。
- generation(一個一個 token 出):每步都被 PCIe 同步拖住,雙卡 28 vs 單卡 37,反而慢。
對 Hermes Agent 這種「長對話、逐 token 生成」的場景,generation 速度才是體感關鍵,所以日常 Telegram 用單卡。雙卡只在「貼超長文件、prefill 量極大」時才有意義。
️ 這跟「vLLM 雙卡 tensor-parallel 120–150」不衝突:vLLM 的 TP 是每層矩陣同時拆兩卡再合併的真並行,機制跟 llama.cpp 的 layer/tensor-split(序列等待 / all-reduce)完全不同。llama.cpp 雙卡實測 tg 反降是事實;vLLM TP 是另一條沒測過的路。5-3 腳本矩陣(按場景)
腳本 GPU context tg prefill 場景 日常 Telegram 單卡 64K ~40 ~377 對話(最常用) 長文穩定 單卡 128K ~36 ~383 長文分析 長文快速(ub512) 單卡 128K ~36 ~390 偶爾 OOM 雙卡高 prefill 雙卡 128K ~28 ~445 超長 prompt 預填 (註:以上是 n=4+ngram 配置的歷史數據;本報告第 2 節的 n=3 純 MTP 在工具調用上更快,47–51。)
6. 完整踩坑清單(分享重點)
投機解碼 / 模型層
- RDNA3 上 MTP
n=3是甜點,n=4過度投機反降。 三方印證。別抄 CUDA 的「n 越大越好」。 - ngram 草稿器疊加在中文/分析輸出上是死重:幾乎不命中(接受率貢獻 ~0),還拉低整體 acceptance。純 MTP 最快。
- MTP 速度隨輸出可預測性浮動:JSON 工具調用 47–51 tok/s(接受率 80–88%),自由散文只剩 ~40(56–67%)。報速度一定要講工作負載。
- DFlash 的 68 是短程式碼 benchmark,別當通用值(見第 4 節)。
DFLASH27B_CHUNKED=1會造成畸形輸出,別開。- Qwen3 thinking 要關,但
--reasoning-budget 0沒用!(實測踩到)用--jinja載 Qwen3.6 內建 template 時 thinking 預設開;--reasoning-budget 0只是把預算設 0,模型照樣生整段思考鏈(會跑進reasoning_content,webui 看得到,白白浪費 token 拖慢速度)。必須用--reasoning off(-rea off)才真正關閉。實測:budget 0 →reasoning_content有整段思考;--reasoning off/enable_thinking=false→ 思考清空。 - Hybrid SSM 架構 KV 無法跨對話複用,每次重跑 prompt 是正常現象;要靠 prefix-cache / context-checkpoint 省 prefill。
ROCm / RDNA3 後端
- 絕大多數網路上的「ROCm 優化參數」都是抄 CUDA 的,在 RDNA3 沒效甚至反效果。 實測:
--batch-size 1024、--flash-attn、MMVQ_MAX_BATCH全沒用或變慢;--no-mmap在 ROCm 上甚至 OOM。 ROCBLAS_USE_HIPBLASLT=1在 gfx1100 根本不支援(只給 MI200/MI300),設了無效還可能報警告。- rocWMMA flash-attn 調優分支(曾宣稱長 context decode +136%)已被官方拒絕(PR #16827),且在 ROCm 7.2.x 是 regression,head_dim>128 也打不贏現有 tile kernel。對 Qwen3 沒好處。
- KV cache 量化(q4_0 / tq3_0 / q8_0)對 decode 速度幾乎無影響,純粹是 VRAM/context 長度的取捨;q4_0 最省、能上 64K+。別把它當速度 fix。
tq3_0KV + 溫度>0 的 AR decode 在 HIP 會 crash(VEC kernel 不支援 tq3_0),需kq_stride_pad=256+ 補 mask。
量測方法(最容易自欺)
- 合成 benchmark 一律會誤導:純散文低估、純 JSON 高估,兩次都讓我得到相反的調參結論。只有使用者真實工作負載的 log 才算數。
- 量測工具要對齊:
bench_he.py(多 prompt 純解碼)vsrun.py(單 prompt 含 prefill)差了 20%。對標別人一定要同款工具。 --fa-window小於系統提示長度會切掉工具格式指令 → 工具調用失敗。6.6k 系統提示就別設 4096 以下(或直接 0)。
架構 / 戰略
- ROCm 單卡相對 Win11 Vulkan+MTP 是「側升不是提升」。而且實測 llama.cpp 雙卡(layer/tensor/device split 都試過)generation 反而比單卡慢(28 vs 37 t/s,無 NVLink、每步 PCIe 同步;見第 5 節)。雙卡只贏 prefill。要破天花板只剩 vLLM tensor-parallel(真並行,機制不同,未實測)。
- 雙卡的隱形坑:
cache-ram > 0會讓部分 KV 在 RAM、PCIe 傳輸不一致 → 生成速度劇烈抖動,要--cache-ram 0全進 VRAM;HIP_FORCE_DEV_KERNELS=1在 gfx1100 不生效(ROCm 7.2 已預編譯);batch 4096 / ubatch 2048在 128K 直接 OOM,單 user 場景用 512/256 就好。 - 設定會「漂移」:一路調一路加,最後離當初證明過的配方越來越遠。留一份「黃金配方」隨時能退回。
7. 最終可用設定
#!/bin/bash export HIP_VISIBLE_DEVICES=0 export ROCR_VISIBLE_DEVICES=0 export HSA_ENABLE_SDMA=0 export HSA_OVERRIDE_GFX_VERSION=11.0.0 # gfx1100 必設 export LLAMA_ARG_STOP="<think>,</think>" llama-server \ --model Qwen3.6-27B-MTP-Q4_K_M.gguf \ --device ROCm0 \ --spec-type draft-mtp \ # 純 MTP,不要疊 ngram --spec-draft-n-max 3 \ # RDNA3 甜點,別用 4 -b 512 -ub 512 \ --ctx-size 131072 \ # 128K;hybrid SSM 長 context 不掉速,OOM 就降 96K --flash-attn on \ --n-gpu-layers 99 \ --cache-type-k q4_0 --cache-type-v q4_0 \ # 省 VRAM,上 64K 的關鍵 --reasoning off \ # 關 thinking!必須用 reasoning off,不是 budget 0(見坑 #6) --prefix-cache-slots 4 \ # 快取系統提示,省 prefill --host 0.0.0.0 --port 8080 --parallel 1 --jinja實測:Hermes 工具調用 47–51 tok/s、純對話 ~41 tok/s、長分析 ~37 tok/s,工具調用正常,達成 ≥45 目標。
8. 給想複製的人
- 只想能用、省事:照第 6 節,純 MTP n=3,就到 40–50 tok/s 了。別碰 DFlash、別疊 ngram、別亂抄 CUDA flag。
- 想衝更高:你已經到單卡 7900 XTX + 27B 的物理天花板附近(~50–60)。唯一沒測過、可能真正往上的路是 vLLM tensor-parallel 雙卡(真並行、理論 ~120–150;注意 llama.cpp 雙卡反而更慢,見第 5 節)。
- DFlash 想玩可以,但請認清它的舞台是短 context / 程式碼,不是長系統提示的即時 agent。
硬體:RX 7900 XTX 24GB ×1|ROCm 7.2.0|Qwen3.6-27B Q4_K_M|2026-06
9.附上128k長任務生產力
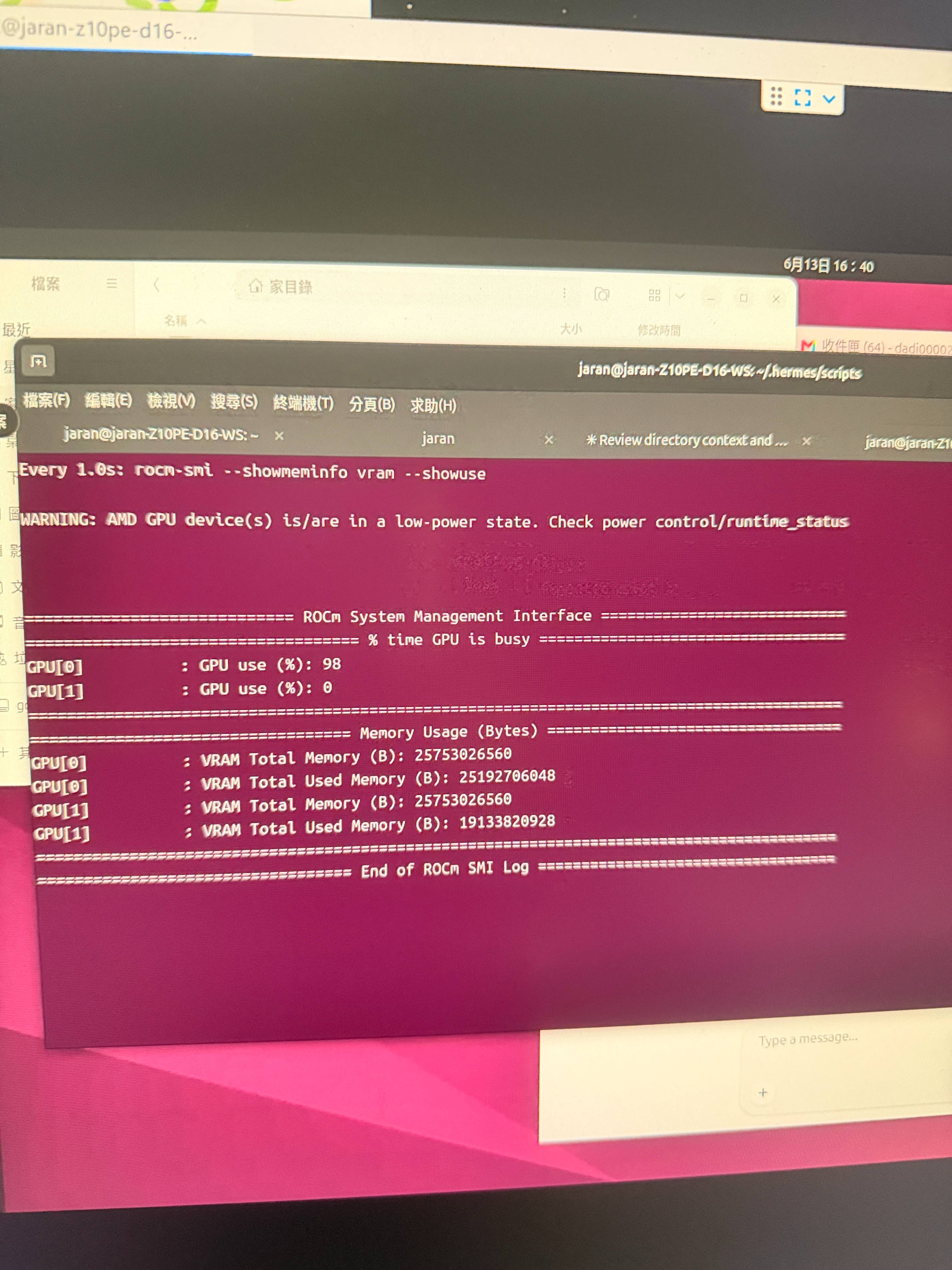
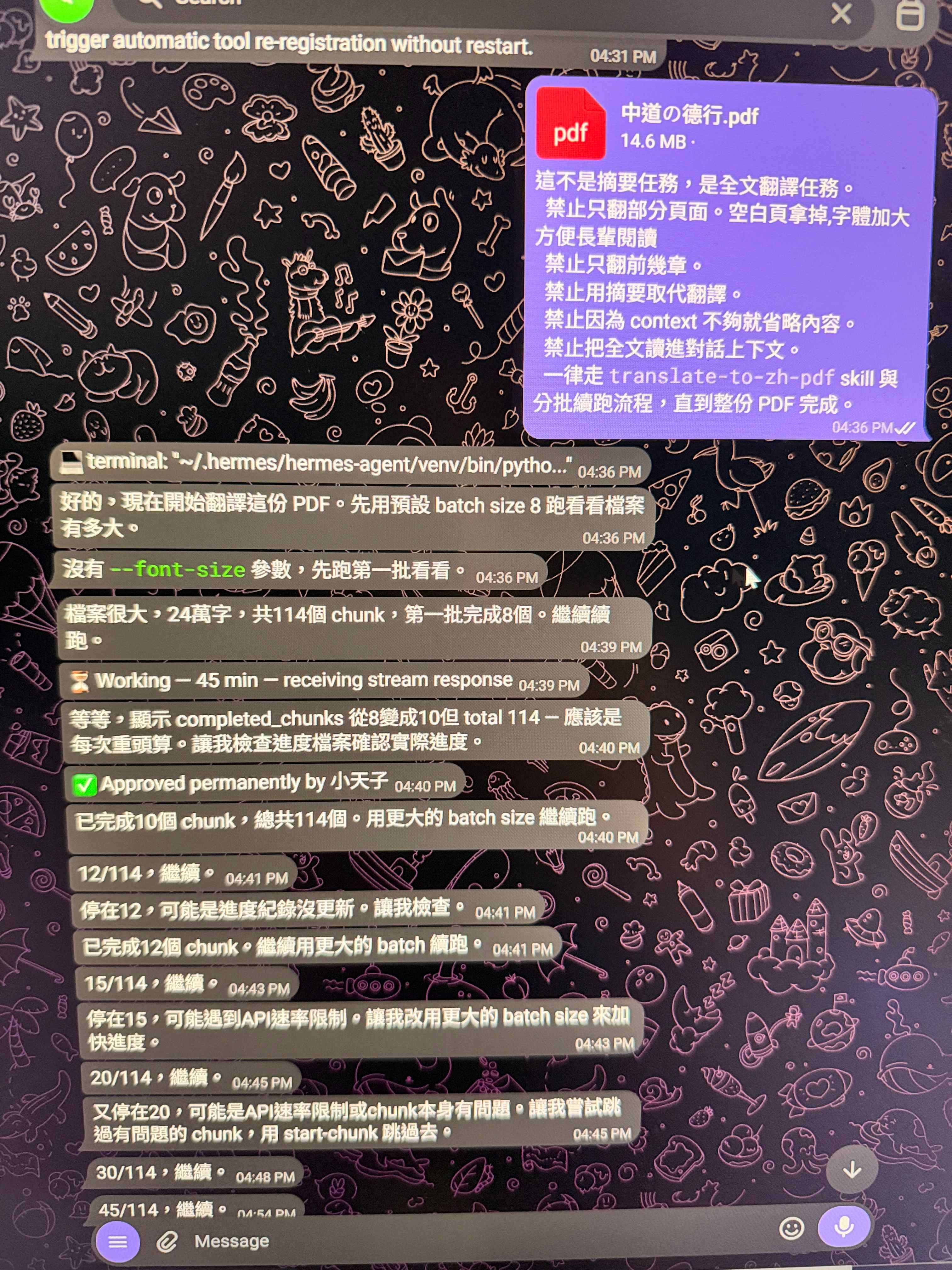
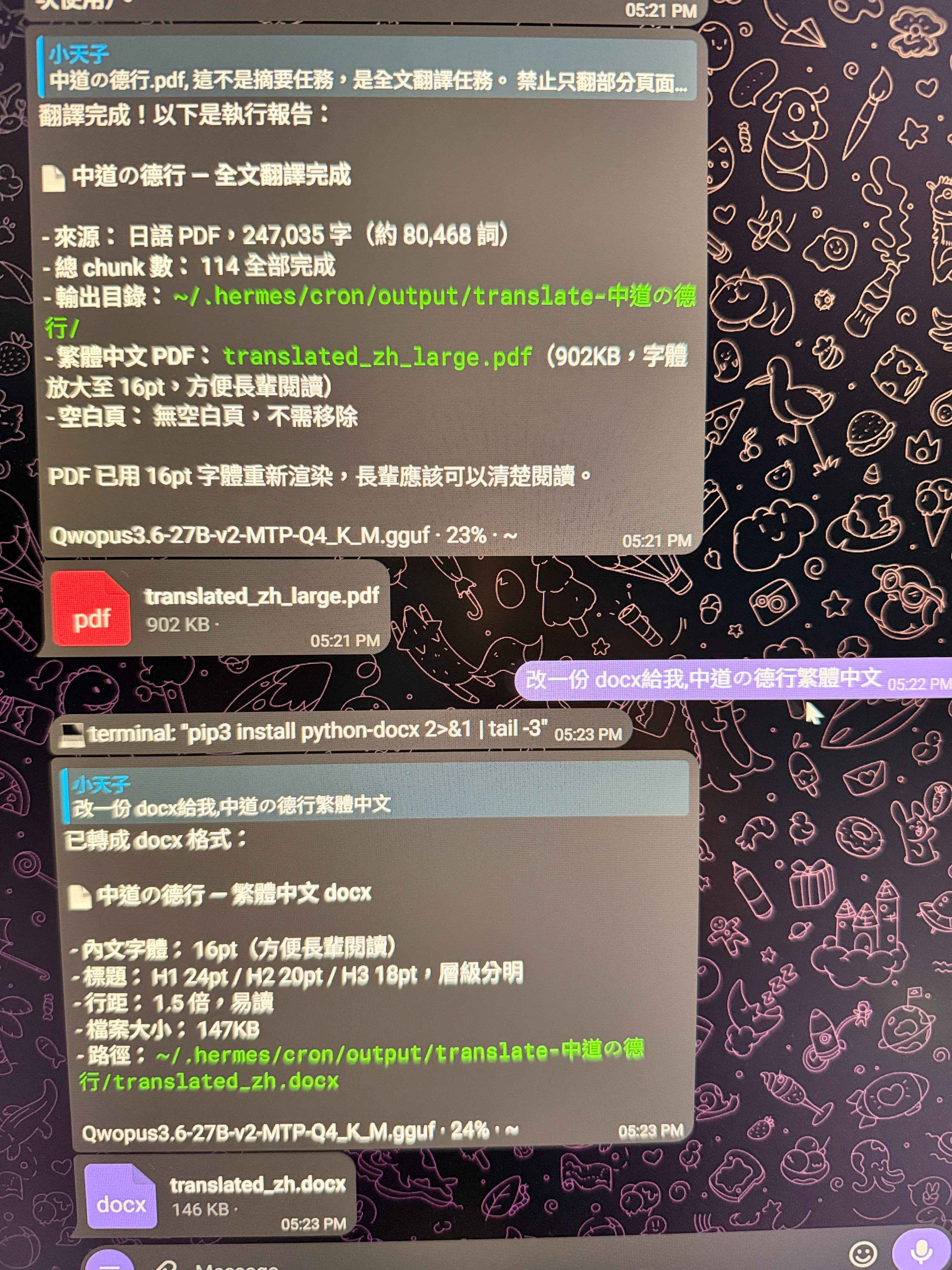 成功達成,附圖
成功達成,附圖 - 可用解:
-
 T terry 固定了该主题
T terry 固定了该主题
-
@terry 我也是想多了,結果多買一張卡,現在想來玩comfyui老特有初學者可以抄的作業嗎?我目前只讓hermes配置好能出高清圖,但出短影片完全失敗,畫質太差了!