请教大家M5 Max 128G MacBook Pro上的oMLX如何优化
-
大家好,我从今年元旦开始关注open claw的介绍和使用心得,碰巧过年时M5 max的MBP发布,就24期分期购入了128G的版本。本着先跑通再优化的思路先尝试了ollama,跑Qwen3.5 70B,学习openclaw。后来听大佬的话换到Qwen3.6 27B 8bit mlx。
之后夜以继日的沉浸在学习的快感里,可能是看多了本地ai内容的视频,被算法推了抡锤者大佬的视频,受益匪浅,很认同楼主的世界观,AI本质还是我们的工具,了解他,学习他,思考并找到他能给我们赋能的功能,相比原来chatgpt和gemini的纯文字交流来说,体会到了哥伦布的爽感。
目前我手里的硬件:AMDPC主机+32G内存+3090显卡,之前有过学习stable diffusion的经验,过年期间开始琢磨ltx2.3的其他玩家的玩法,只是偶尔生成参数控制不好内存溢出崩溃,敢在显卡涨价前在国外下单5090 32G,等下次回国带回来学习,希望如楼主所说能够更轻松的做一些音视频尝试。
M5 max上运行openclaw一段时间发现这家伙确实阿尔兹海默现象逐渐出现,现在更多的是使用Hermes,不同的架构还是缓解很多。现状搭配是M5 Max专职运行oMLX,提供api给家里每个人的openclaw或者hermes使用,这两个月在公司运营,法务梳理,业务拓展上榜了我很多。业务生成音视频我也是告诉Hermes,让他去调用PC的comfy ui api完成,真是挺好玩的。
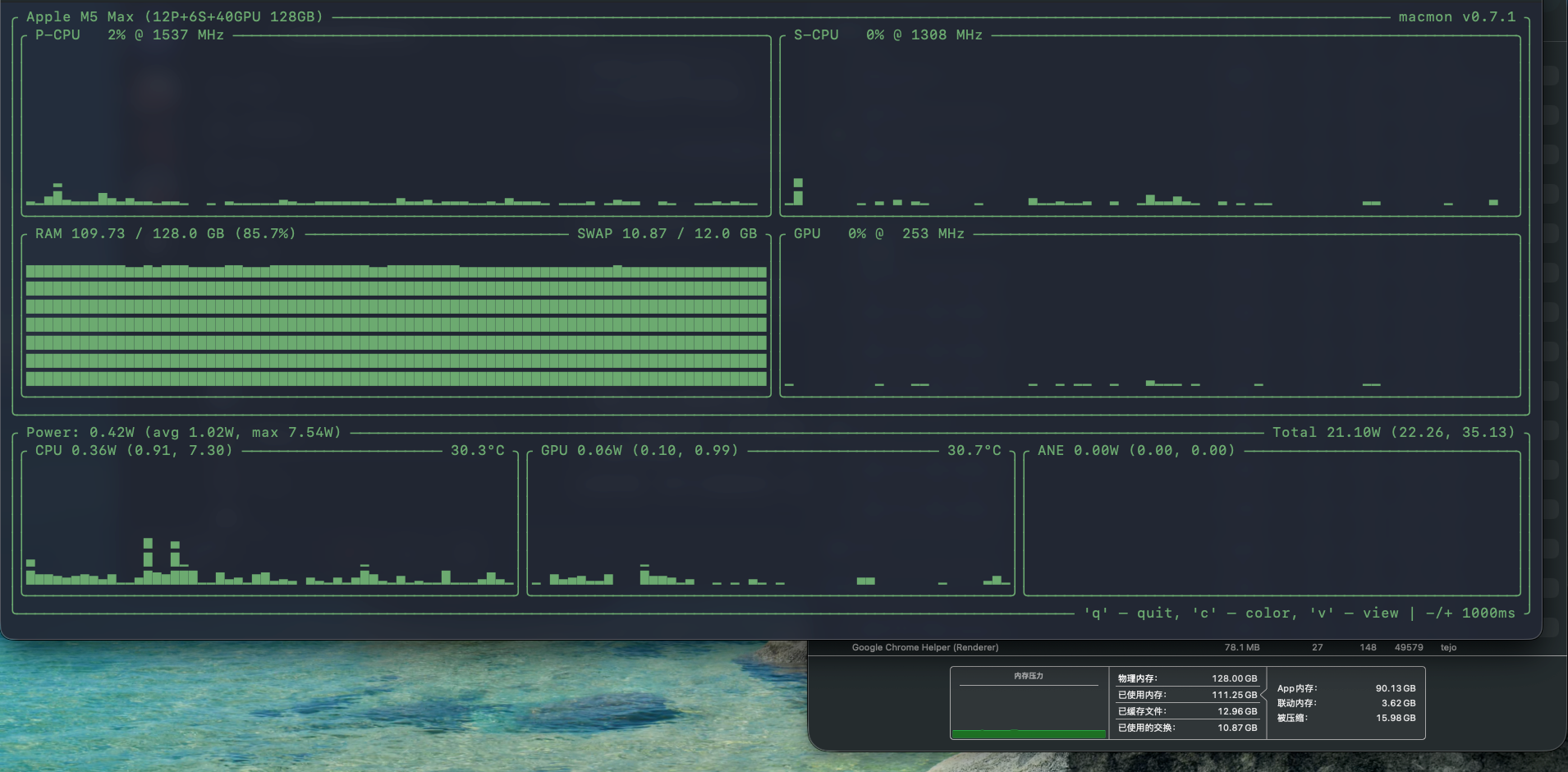
由于家里所有成员开始更多的使用Hermes,现在M5 max也经常排着7/8个对话运行,响应速度开始在高峰时有感知的减慢,所以想跪求其他前辈的oMLX调优心法,让他能更流畅的运行,随附我现在的模型设置,先谢过各位,好人一生平安。
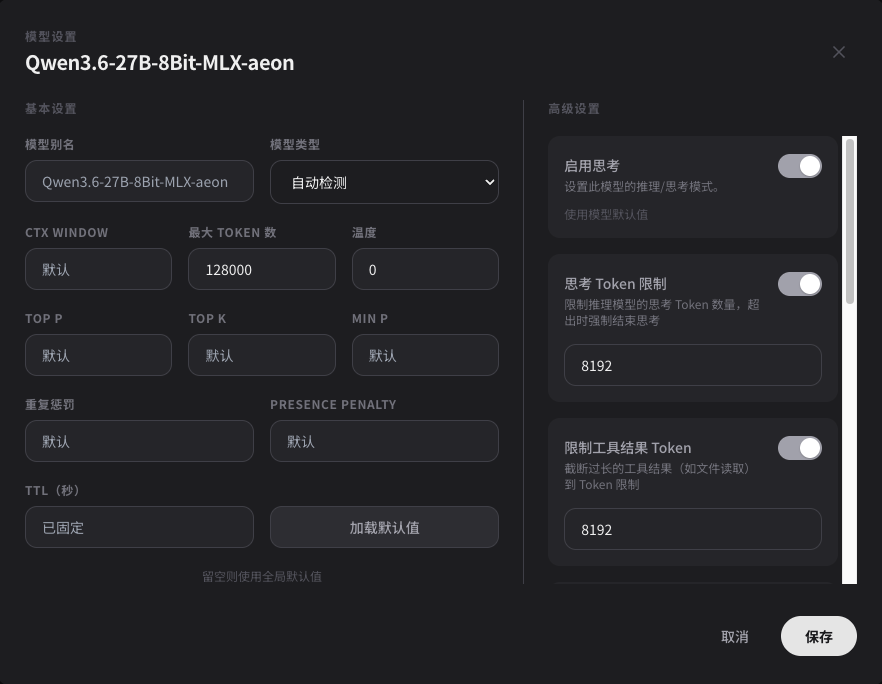
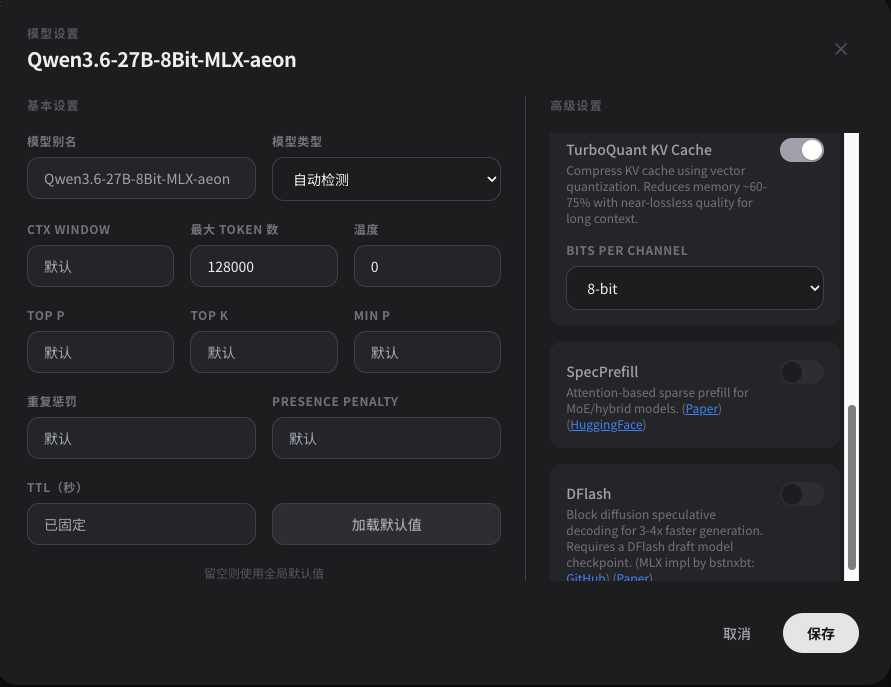
-
为什么你的正文是这样的…… 看起来好累
我之前用过一段时间vMLX,一开始体验很好,后来碰到恶性bug,在git上提了issue,作者也回复我了,迭代了新版本,但是还是没解决…… 我是在venv里装的,但是vMLX还是会去读一些系统python环境,导致冲突,就放弃mac生态了…… -
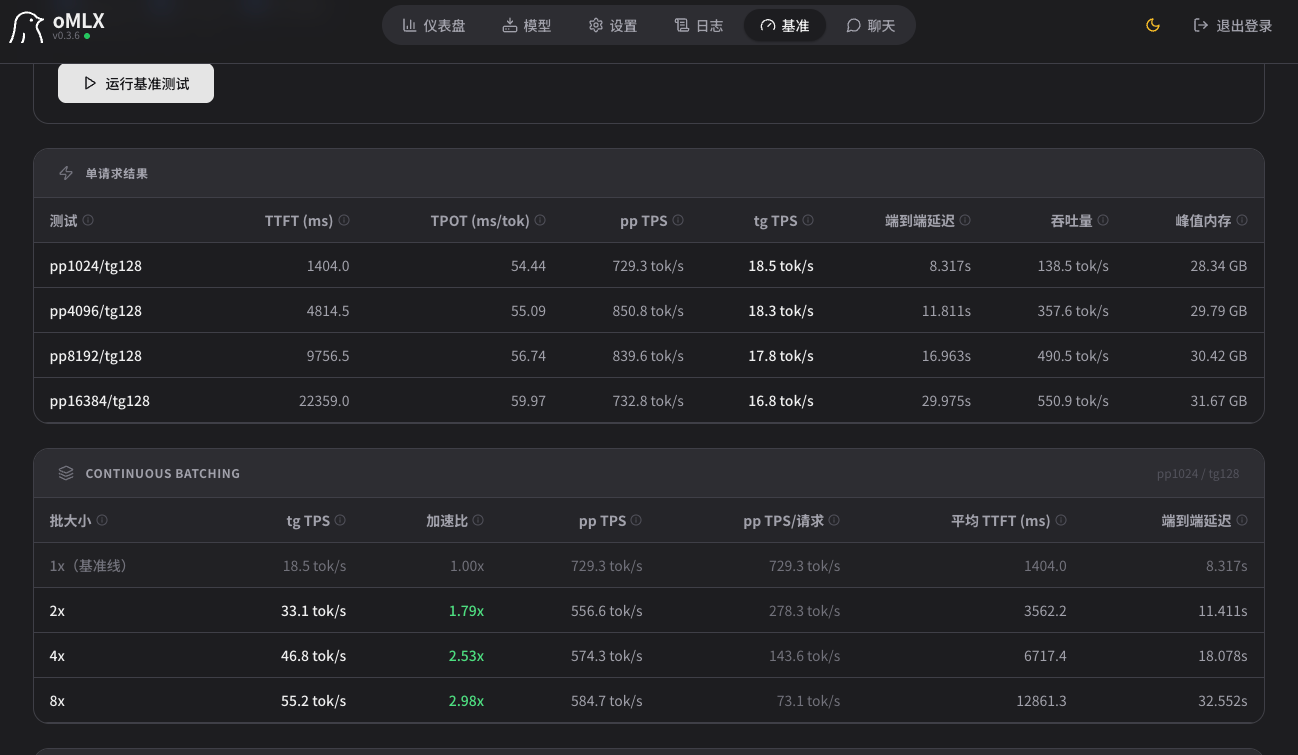
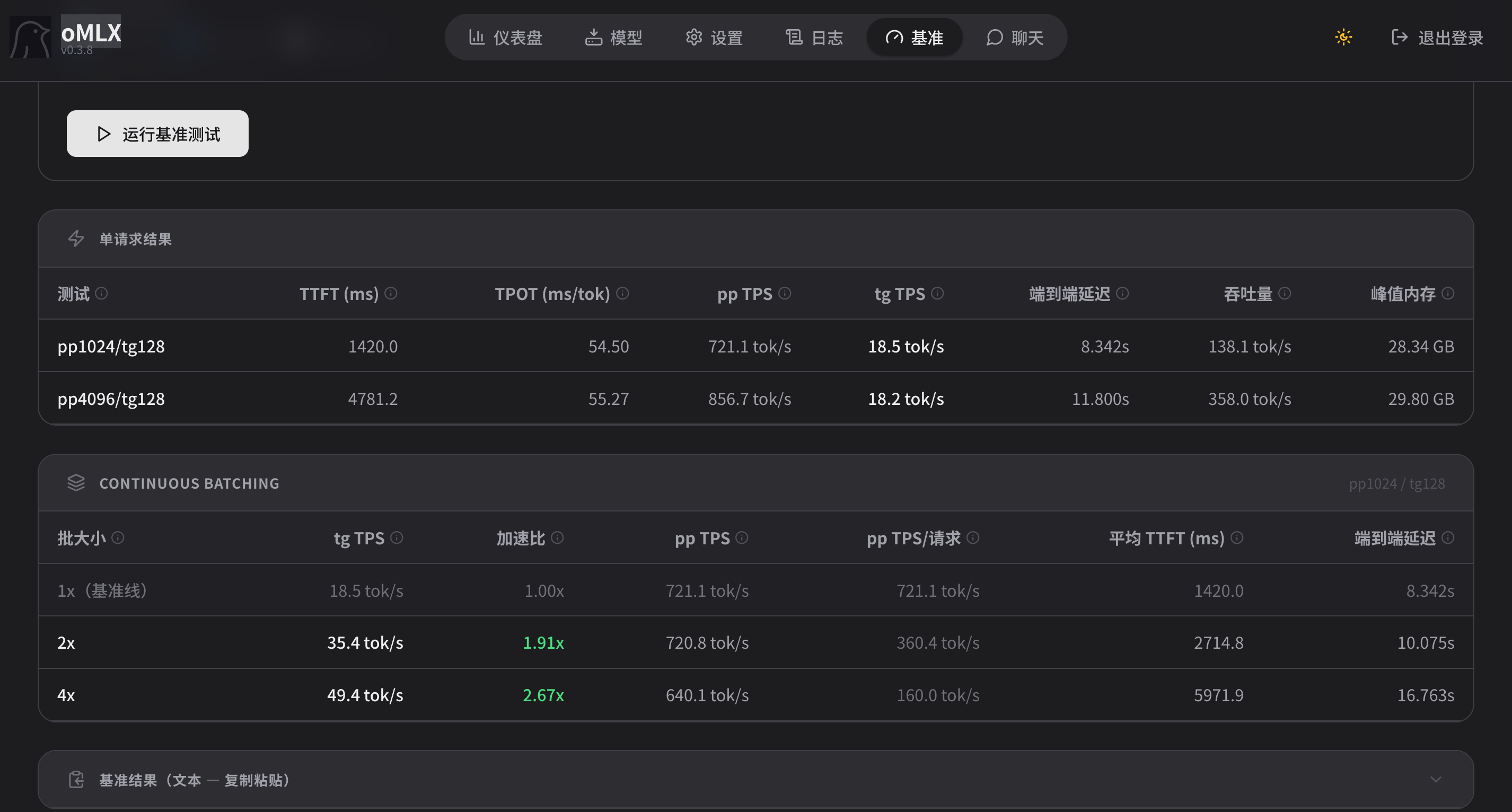
目前楼主的参数运行起来prefill(输入)和decode(输出)速度分别是多少?
-
@Tony-Wang oMLX 和 LM Studio 定位不太一样:
-
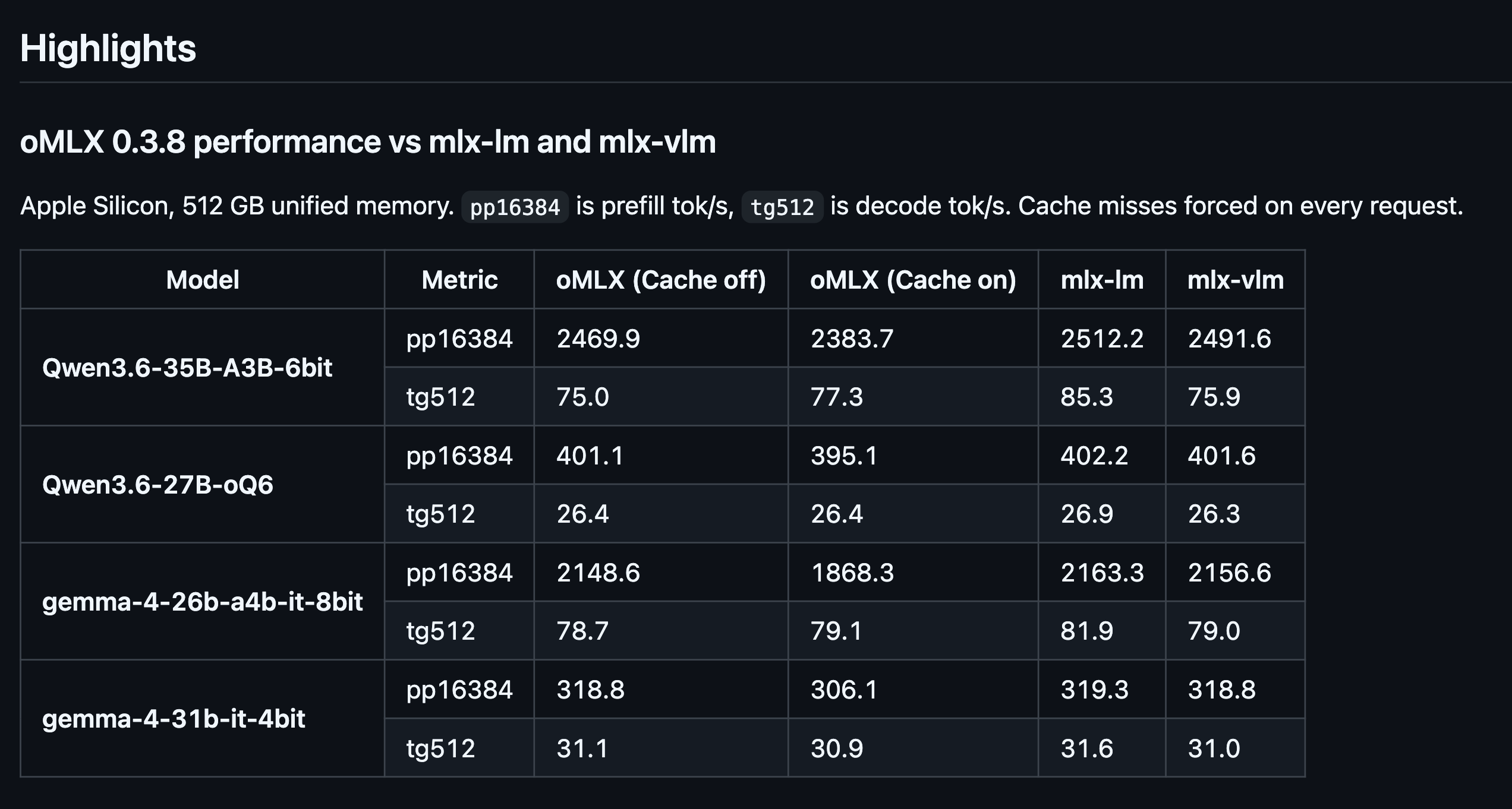
oMLX 是专门为 Apple Silicon 优化的推理框架,底层用 MLX(Apple 自家的 ML 框架),对 M 系列芯片的内存带宽和神经引擎利用得更好,尤其是 Unified Memory 的管理。适合跑 MLX 格式的模型(如 mlx-community 的版本)。
-
LM Studio 更像是一个全功能 GUI 管理平台,底层可以用 llama.cpp、MLX、甚至 OpenAI API 兼容模式。它的优势是开箱即用、界面友好、支持各种格式的 GGUF 模型,但针对 M 系列的底层优化不如 oMLX 深入。
-
vMLX 确实有过稳定性问题,我见过不少反馈说有环境冲突。oMLX 迭代快,最近的版本改善了很多。
-
实际建议:如果你主要是用 Mac 跑推理且不介意命令行,oMLX 值得一试,尤其是 Unified Memory 模式下可以跑超过显存大小的模型。如果图省心、经常换不同模型玩,LM Studio 更方便。两个可以同时装不冲突。
-
-
模式不一样。钱花了就会有结果的。这个配置可以。苹果为维持销量也会通过各种方式不让你放弃这个配置。放心这个配置没问题。
-
看来mac优势在于多线程?双线程加速比1.91,几乎不掉速度。
但是单线程18.5t/s,还是太慢了点
-
关掉会降智. 我用刑侦十题的变体(防止它被训练过), 测试27b, thinking模式下, 完美解答, 但是时间巨长. no think 模式下翻车. 其余35a3, 26a4, 还用了 ud, 开了thinking也都全部翻车.
-
oMLX 用了后会让你跑起来。主要问题是温度激升。(物理解决。空调开着)对固态硬盘的寿命影响非常大。大约新机使用后。寿命会缩减到2-3年。最大可能2年就报废。1T的原装盘1400元左右。其实算算也不算什么。奔跑吧。少年
-
oMLX 用了后会让你跑起来。主要问题是温度激升。(物理解决。空调开着)对固态硬盘的寿命影响非常大。大约新机使用后。寿命会缩减到2-3年。最大可能2年就报废。1T的原装盘1400元左右。其实算算也不算什么。奔跑吧。少年