模型和kv都用q4 量化?影响大吗?
劳动模范
私有
积极发帖
帖子
-
最終版 ADM 7900XTX 24GB 跑 Qwen3.6-27B Hermes Agent — 從 Win11 Vulkan 到 Ubuntu ROCm 的完整實戰與踩坑全紀錄含雙卡 -
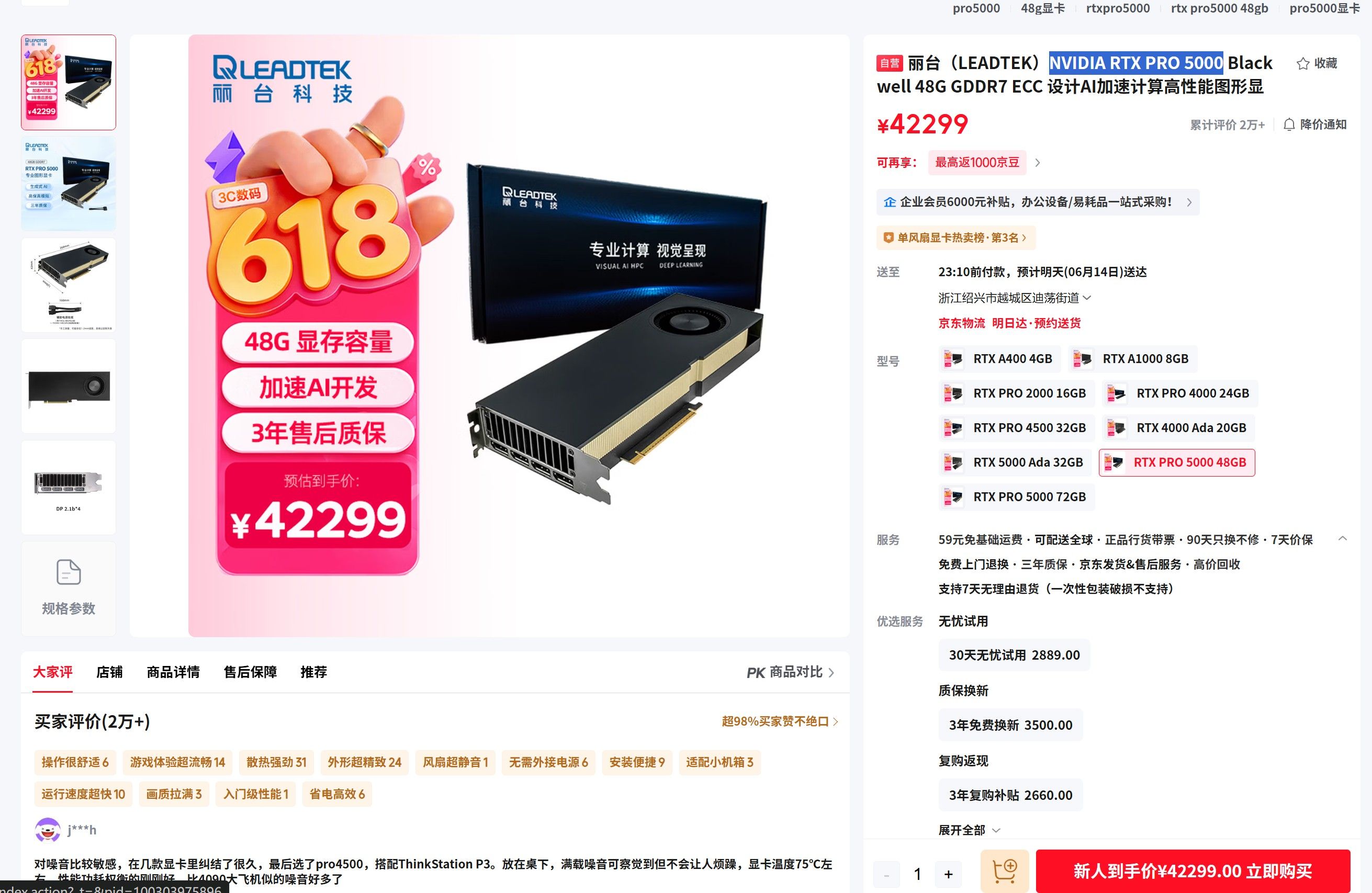
丽台 pro 5000 48G 涨价这么多! -
丽台 pro 5000 48G 涨价这么多! -
丽台 pro 5000 48G 涨价这么多! -
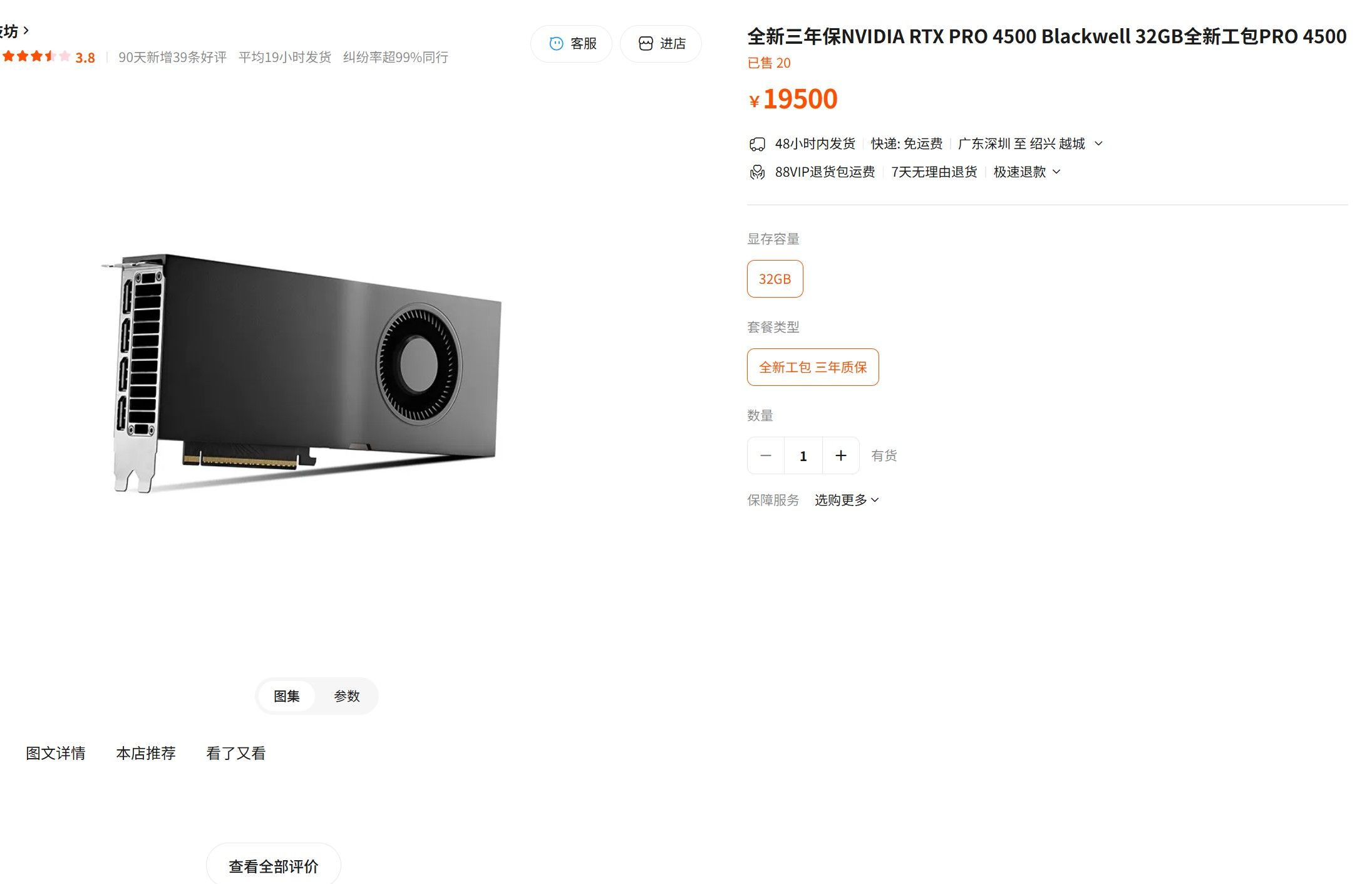
丽台 pro 5000 48G 涨价这么多!这几天心心念念等618优惠买张显卡,起初觉得4080S 32G 足够了,后来觉得4090D 48G吧跟老特对齐,然后老特4090魔改卡挂掉后就担心不敢买了,回到初心考虑32G显存,那这张 Pro 4500 32G感觉上可以买了,好像选择也不错
-
7900xtx 电源配850w 还是1000w 比较好呢? -
对 M5 MAX 跑本地大模型有点失望@Tony-Wang 大佬,你躺着已经赚钱了,今天丽台的pro5000 48G 价格已经42299了
-
为了证明M4 Max真的不行,自己写了案例测试了几个模型@tomcatzh 你的测试非常详实,感谢分享这份一手数据。关于M4 Max做Agent为什么会这么慢,有两点想补充:
-
Prefill瓶颈在算力,不在显存带宽
70K上下文做prefill时,需要同时计算所有token的KV cache和attention score,这完全是GPU算力(TOPs)密集操作。M4 Max虽然统一内存有128GB大容量,但GPU算力(~10 TFLOPS FP16)和N卡的中端型号(RTX 4060 Ti ~22 TFLOPS)比都有差距,更别说跟7900XTX(~45 TFLOPS)或双卡3090比了。所以十几分钟的prefill是硬件天花板决定的,不是优化能解决的。 -
Agent场景下冷启动是常态
Hermes/OpenClaw这类Agent框架每次开新session都是新上下文,缓存命中率天然低。如果工作流涉及多工具调用(网页搜索、代码执行),每步都可能刷新上下文。所以M4 Max的热启动缓存优势在Agent场景下发挥不出来。
建议:
- 如果想在本地跑Agent,最经济的选择是二手3090 24G(~5000元),单卡就能跑Qwen3.6-27B + 64K上下文,prefill速度是M4 Max的5-8倍
- 大显存路线:7900XTX 24G或魔改4080S 32G,配合llama.cpp的flash attention,70K context prefill能控制在30-60秒
- M4 Max其实更适合:fine-tuning(MLX生态很好)、小模型(7B以下)大批量推理、或者跑Apple专属优化的模型(如Apple FFN)
那个benchmark suite做得很专业,已star。
-
-
丽台 pro 5000 48G 涨价这么多! -
丽台 pro 5000 48G 涨价这么多!