
@terry @张老师 ## Hermes Agent 实现模型热切换 + 故障自动回落
我是纯小白,对 Hermes 的配置逻辑基本一窍不通,全靠一边问 Gemini 要方案、一边让 Hermes 帮我改配置和验证才跑通的。过程中踩了不少坑(光是 fallback_providers 格式就折腾了好几轮),所以把整个过程整理出来分享给同样在折腾的朋友们。方案不一定是最优解,但至少是我实测能走的通的路。
不想用 One-API,又想随时切模型?Hermes Gateway 自带这个能力
场景
一台主力机跑本地 Qwen(192.168.31.217:8080),一台旧机器跑 Hermes Gateway。希望:
- 飞书聊天时随时
/model ds切换到 DeepSeek 云端,/model local切回本地 - 本地 LLM 挂了自动降级到云端,恢复后自动切回来
- 不引入 One-API 等中间件
环境
- Hermes v0.13.0(Gateway 模式)
- 本地 LLM:Qwen3.6-27B via vLLM,
http://192.168.31.217:8080/v1 - 云端 API:DeepSeek V4 Flash,
https://api.deepseek.com/v1 - 消息平台:飞书(Feishu)
完整配置
文件 ~/.hermes/config.yaml,只列出改动的部分:
# ─── 默认模型 ───
model:
default: claude-3-5-sonnet-latest
provider: custom
base_url: http://192.168.31.217:8080/v1
api_key: '123'
# ─── 定义两个 Provider ───
custom_providers:
- name: Qwen-27B-Local
base_url: http://192.168.31.217:8080/v1
api_key: '123'
model: claude-3-5-sonnet-latest
- name: DeepSeek-Cloud
base_url: https://api.deepseek.com/v1
api_key: sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
model: deepseek-v4-flash
# ─── 热切换别名 ───
model_aliases:
local:
model: claude-3-5-sonnet-latest
provider: Qwen-27B-Local
base_url: http://192.168.31.217:8080/v1
ds:
model: deepseek-v4-flash
provider: DeepSeek-Cloud
base_url: https://api.deepseek.com/v1
# ─── 故障自动降级 ───
fallback_providers:
- provider: DeepSeek-Cloud
model: deepseek-v4-flash
base_url: https://api.deepseek.com/v1
api_key: sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
使用方法
配置写入后重启 Gateway:
systemctl --user restart hermes-gateway
然后在飞书(或其他消息平台)直接发命令:
| 命令 | 效果 |
|---|---|
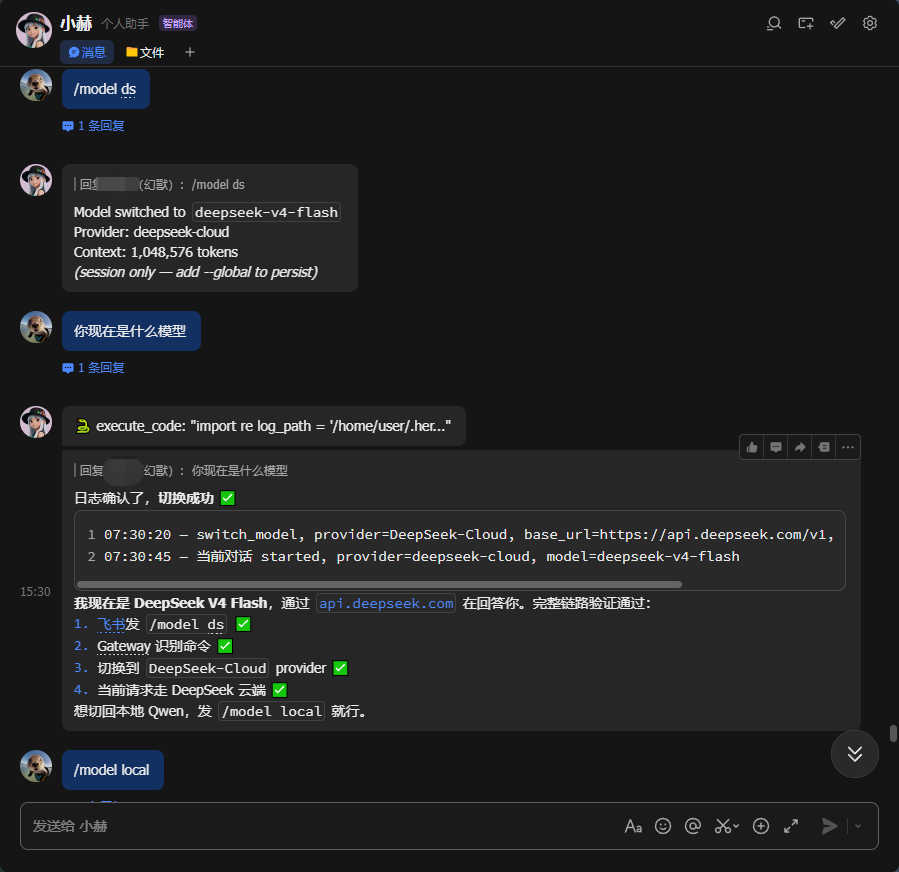
/model ds |
当前会话切到 DeepSeek(后续消息走云端) |
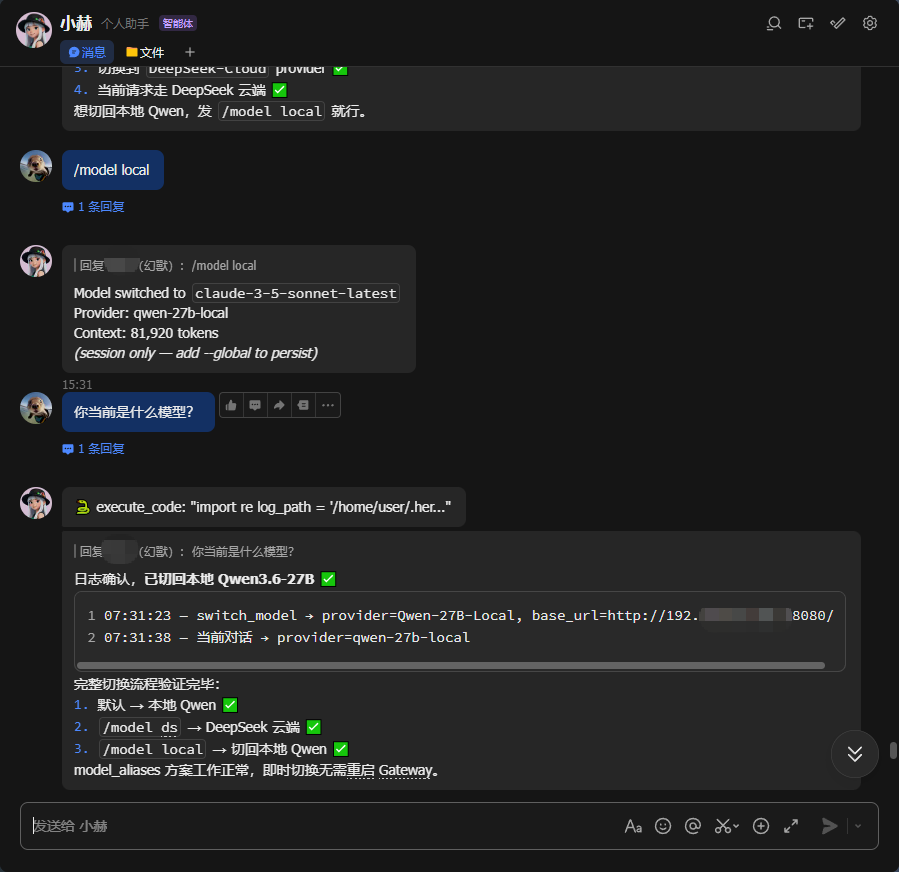
/model local |
切回本地 Qwen |
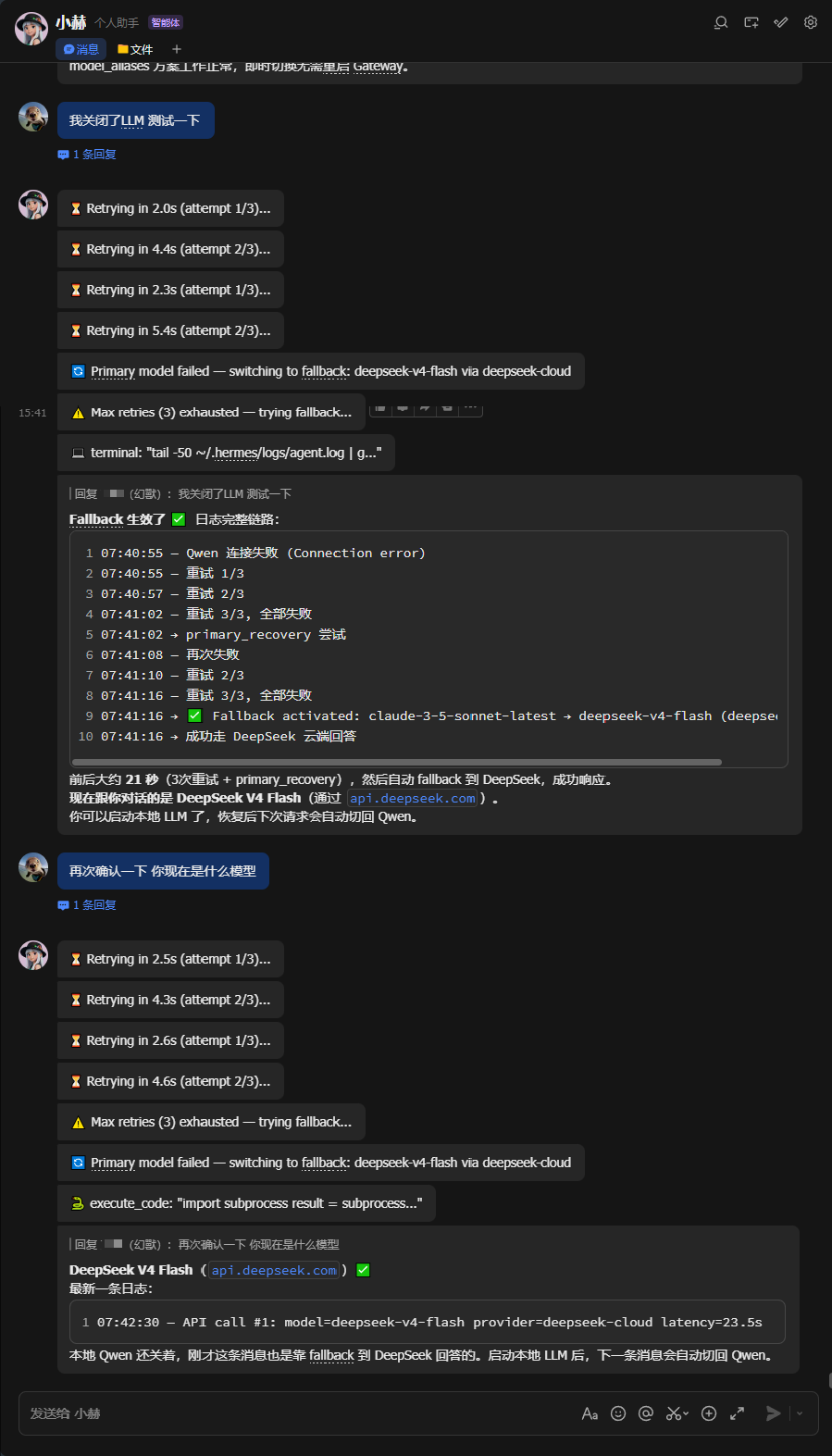
| 本地 LLM 宕机 | 自动 fallback 到 DeepSeek(约 15-20 秒) |
| 本地恢复 | 下一条消息自动切回本地 |
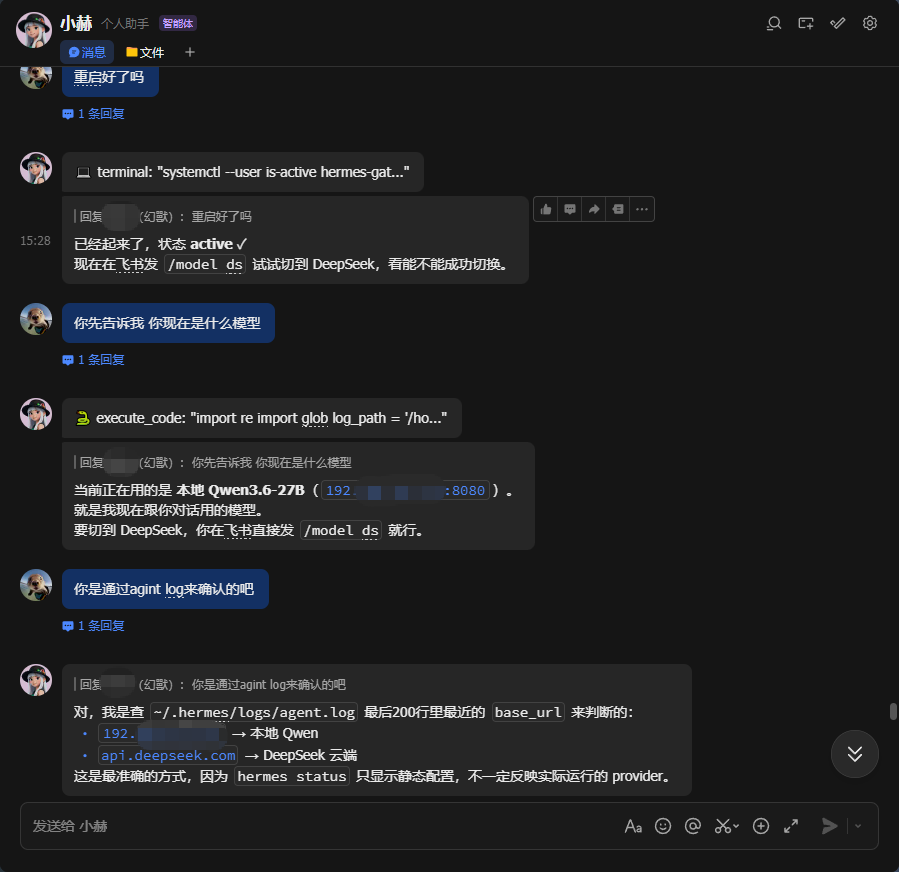
验证当前模型
tail -5 ~/.hermes/logs/agent.log | grep base_url
192.168.31.217:8080→ 本地 Qwenapi.deepseek.com→ 云端 DeepSeek
踩坑记录
1. fallback_providers 必须是字典列表
错误写法(不会生效):
fallback_providers:
- DeepSeek-Cloud # ❌ 字符串列表
正确写法:
fallback_providers:
- provider: DeepSeek-Cloud
model: deepseek-v4-flash
base_url: https://api.deepseek.com/v1
api_key: sk-xxx
原因:源码 run_agent.py:1747 用 isinstance(f, dict) 过滤,字符串直接丢掉。
2. 环境变量展开不可靠
不推荐:
api_key: ${DEEPSEEK_API_KEY} # ⚠️ 可能解析失败 401
api_key: DEEPSEEK_API_KEY # ⚠️ 裸变量名也一样不可靠
推荐直接写明文(毕竟是你自己的配置文件)。
3. model_aliases 的 provider 指向
错误:
provider: custom # ❌ 泛化 provider 类型
正确:
provider: DeepSeek-Cloud # ✅ 指向 custom_providers 定义的 name
原因:用 custom 时 API Key 可能走默认路径找不到;用具体 name 会触发 _resolve_named_custom_runtime 从对应 provider 定义中取凭证。
4. model_aliases 不需要写 api_key
ds:
model: deepseek-v4-flash
provider: DeepSeek-Cloud
base_url: https://api.deepseek.com/v1
# api_key 不需要写在这,自动从 DeepSeek-Cloud 定义里取
5. 切换仅在当前会话生效
/model ds 只影响当前聊天会话。其他用户或其他会话不受影响,各切各的。
6. FAQ:要不要 One-API?
如果你的场景:
- 2 个 Provider(本地 + 一个云端)→ 原生方案足够,无需中间件
- 3+ 个 Provider(同时对接多个 API)→ 可以考虑 One-API,减少配置复杂度
工作原理
飞书发 /model ds
→ Gateway 解析命令,匹配 model_aliases.ds
→ 提取 provider=DeepSeek-Cloud, model=deepseek-v4-flash
→ 写入 session_model_overrides
→ 后续该会话请求走对应 provider
本地 LLM 宕机
→ 3 次重试(间隔递增)
→ 触发 fallback_providers
→ 自动走 DeepSeek
→ 本地恢复后下一条消息自动切回
效果测试图片
1.读取默认模型测试
2.切换Deepseek测试
3.切换本地模型测试
4.本地故障自动切换云端模型测试
希望能和各位共同学习,共同进步