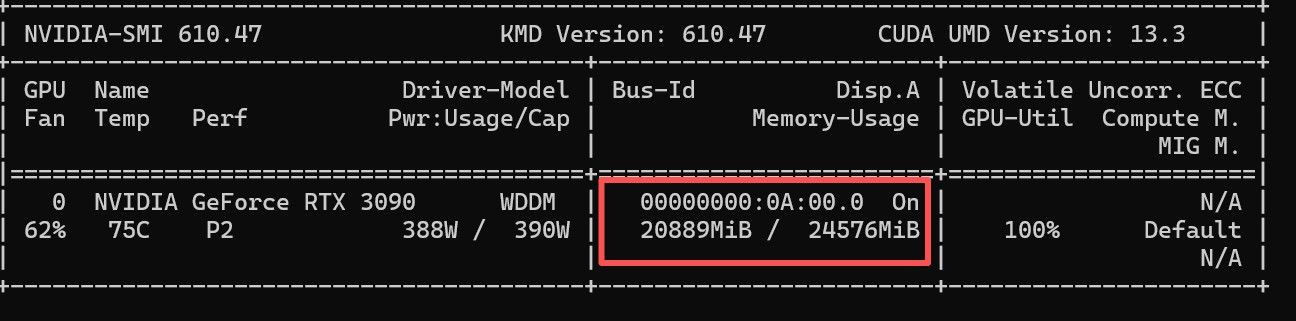
--reasoning off
请教下,启动参数中--reasoning off 配置为off后,后续的 --chat-template-kwargs '{"preserve_thinking":true}'
--reasoning-format deepseek --reasoning-budget 300 \ 参数还会生效吗?
毅袁
@毅袁
-
2026-07 小测一个适合24g单卡跑Hermes 的模型 Qwen3.6-35B-A3B-UD-IQ4_NL_XL (140t/s 170K上下文 tooleval 96分) -
3090单卡跑的3090 club项目,hermes很慢,可能是啥原因呢? -
别再推荐免费编程工具Trae了,应该马上收费了,我每天用到被限制了. -
3090 24G 跑QWOPUS 3.6 27B mtp 131K上下文 KV(Q8_0) 55TOK/S 智能开关思考- 最终配置,再也不折腾了(6月14日更新)@c0aster https://github.com/ikawrakow/ik_llama.cpp 从这个项目自己编译的ik_llama,启动参数如下:
start "ik_llama - heretic-v2 27B" "%EXE%" ^
-m "J:\llama-b9370-bin-win-cuda-12.4-x64\models\1\Qwen3.6-27B-uncensored-heretic-v2-Native-MTP-Preserved-Q4_K_M.gguf" ^
--mmproj "J:\llama-b9370-bin-win-cuda-12.4-x64\models\1\Qwen3.6-27B-mmproj-BF16.gguf" ^
-ngl 99 -c 131072 --threads 12 --no-mmap ^
--flash-attn on ^
--cache-type-k q4_0 --cache-type-v q4_0 ^
--batch-size 512 --ubatch-size 256 ^
--merge-qkv --merge-up-gate-experts ^
--cache-ram 32768 ^
--spec-type mtp:n_max=4,p_min=0.0 ^
--jinja --chat-template-file "%TEMPLATE%" ^
--timeout 3600 --host 0.0.0.0 --port 8080 -
3090 24G 跑QWOPUS 3.6 27B mtp 131K上下文 KV(Q8_0) 55TOK/S 智能开关思考- 最终配置,再也不折腾了(6月14日更新)@c0aster 感谢分享,已经按照ik-llama实施,实测Qwen3.6-27B-uncensored-heretic-v2-Native-MTP-Preserved-Q4_K_M.gguf达到69t/s,已经能够满足生产力需求了
-
求教,为什么我的3090跑Qwen3.6 27B,没有丝滑感,搭配codex编程只有不到30tokey/s -
求教,为什么我的3090跑Qwen3.6 27B,没有丝滑感,搭配codex编程只有不到30tokey/s -
求教,为什么我的3090跑Qwen3.6 27B,没有丝滑感,搭配codex编程只有不到30tokey/s -
求教,为什么我的3090跑Qwen3.6 27B,没有丝滑感,搭配codex编程只有不到30tokey/s -
Claude Code编程最好用旗舰在线API,千万不要图便宜。 -
求教,为什么我的3090跑Qwen3.6 27B,没有丝滑感,搭配codex编程只有不到30tokey/s不好意思,一着急,启动参数贴错了
@echo off
chcp 65001 >nul
title Qwen3.6-27B-UD RTX3090 Optimized Launcher:: ================= 配置区 =================
:: 请将下方路径修改为你电脑上实际的模型文件路径
set MODEL_PATH=J:\llama-b9370-bin-win-cuda-12.4-x64\models\2\Qwen3.6-27B-NEO-CODE-HERE-2T-OT-Q4_K_M.gguf:: 如果你有对应的多模态视觉文件(mmproj),可以在下方取消注释并填写路径;没有则保持注释
set MMPROJ_PATH=J:\llama-b9370-bin-win-cuda-12.4-x64\models\2\mmproj-F16.gguf
:: ==========================================echo ========================================
echo Qwen3.6-27B-UD RTX 3090 启动中...
echo ==========================================:: 启动 llama.cpp (假设 llama-server.exe 或 main.exe 在当前目录下,如果不在请写绝对路径)
.\llama-server.exe ^
--model "%MODEL_PATH%" ^
--ctx-size 131072 ^
--gpu-layers 99 ^
--parallel 1 ^
--temp 0.8 ^
--top-p 0.95 ^
--top-k 20 ^
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--flash-attn on ^
--timeout 3600 ^
--repeat-penalty 1.2 ^
--jinja --chat-template-file chat_template.jinja ^
--port 8080 ^
--host 0.0.0.0pause
-
求教,为什么我的3090跑Qwen3.6 27B,没有丝滑感,搭配codex编程只有不到30tokey/s -
求教,为什么我的3090跑Qwen3.6 27B,没有丝滑感,搭配codex编程只有不到30tokey/s看着兄弟的3090 生产力 丝滑起飞,我的在地上爬,心中满是羡慕,求大佬指点!
先介绍环境:
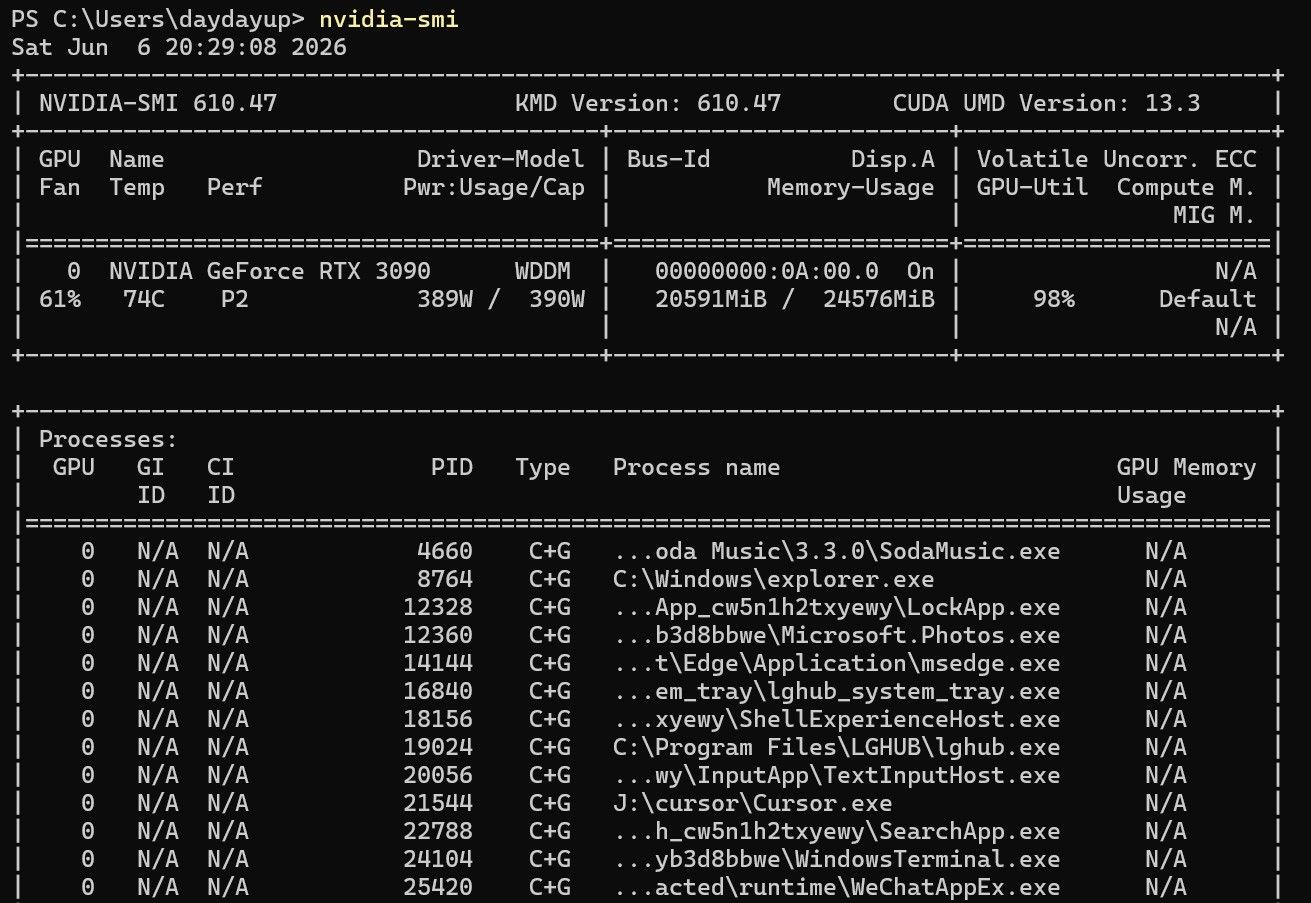
CPU 5700X
GPU 3090 24G
内存64G
win10系统
本地模型相关
model:Qwen3.6-27B-NEO-CODE-HERE-2T-OT-Q4_K_M.gguf
@echo off
chcp 65001 >nul
title Qwen3.6-27B-UD RTX3090 Optimized Launcher:: ================= 配置区 =================
:: 请将下方路径修改为你电脑上实际的模型文件路径
set MODEL_PATH=J:\llama-b9370-bin-win-cuda-12.4-x64\models\1\Qwen3.6-27B-uncensored-heretic-v2-Native-MTP-Preserved-Q4_K_M.gguf:: 如果你有对应的多模态视觉文件(mmproj),可以在下方取消注释并填写路径;没有则保持注释
set MMPROJ_PATH=J:\llama-b9370-bin-win-cuda-12.4-x64\models\1\Qwen3.6-27B-mmproj-BF16.gguf
:: ==========================================echo ========================================
echo Qwen3.6-27B-UD RTX 3090 启动中...
echo ========================================:: 启动 llama.cpp (假设 llama-server.exe 或 main.exe 在当前目录下,如果不在请写绝对路径)
.\llama-server.exe ^
--model "%MODEL_PATH%" ^
-ngl 99 ^
-c 131072 ^
-n 8192 ^
-fa on^
--port 8080 ^
--host 0.0.0.0 ^
--image-min-tokens 1024 ^
--batch-size 512 ^
--ubatch-size 256 ^
--spec-type draft-mtp ^
--spec-draft-n-max 2
--cache-type-k q4_0 ^
--cache-type-v q4_0 ^
--jinja --chat-template-file chat_template.jinja ^
--timeout 3600 ^
--jinja ^
--temp 0.6 ^
--top-p 0.95 ^
--top-k 20 ^
--min-p 0.05 ^
--repeat-penalty 1.05
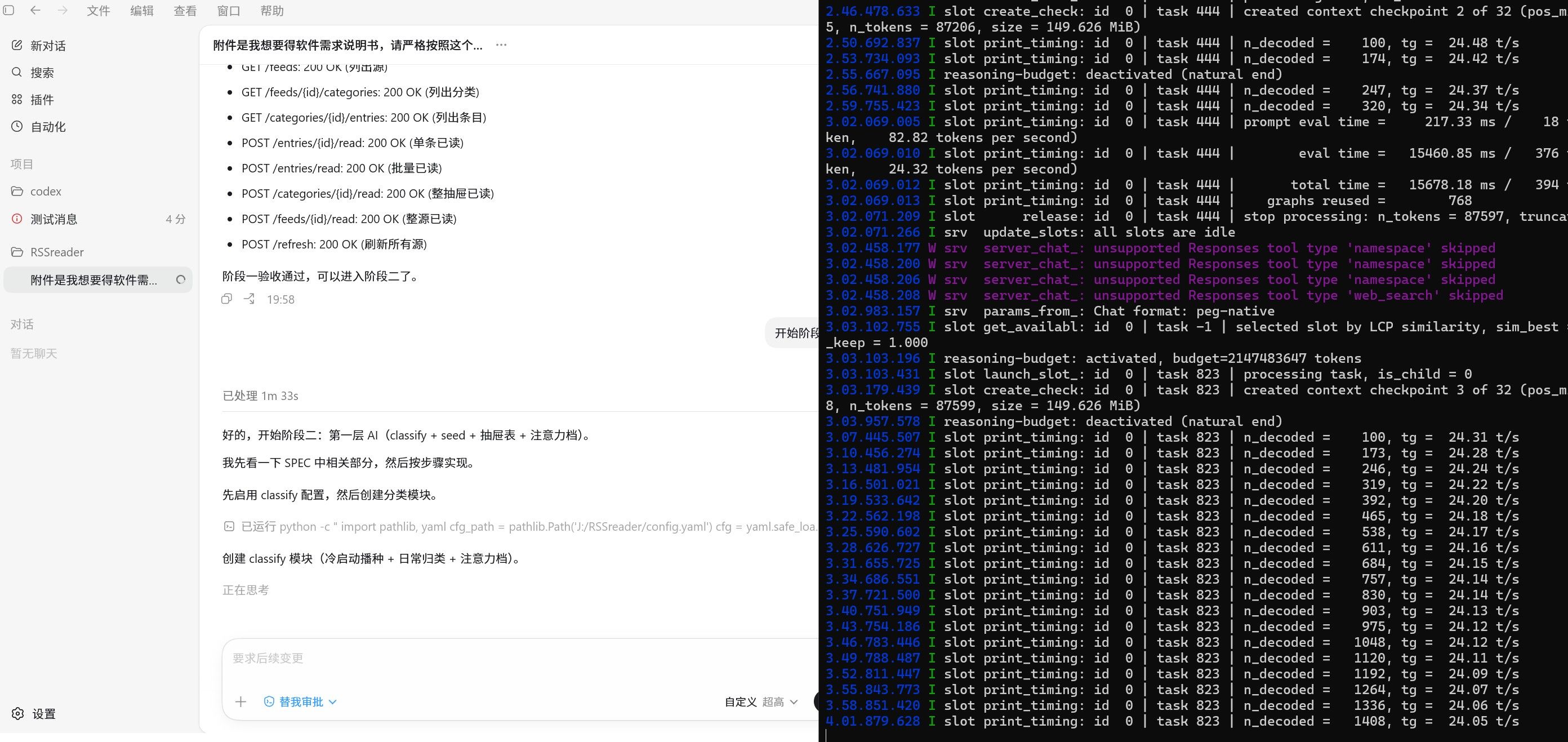
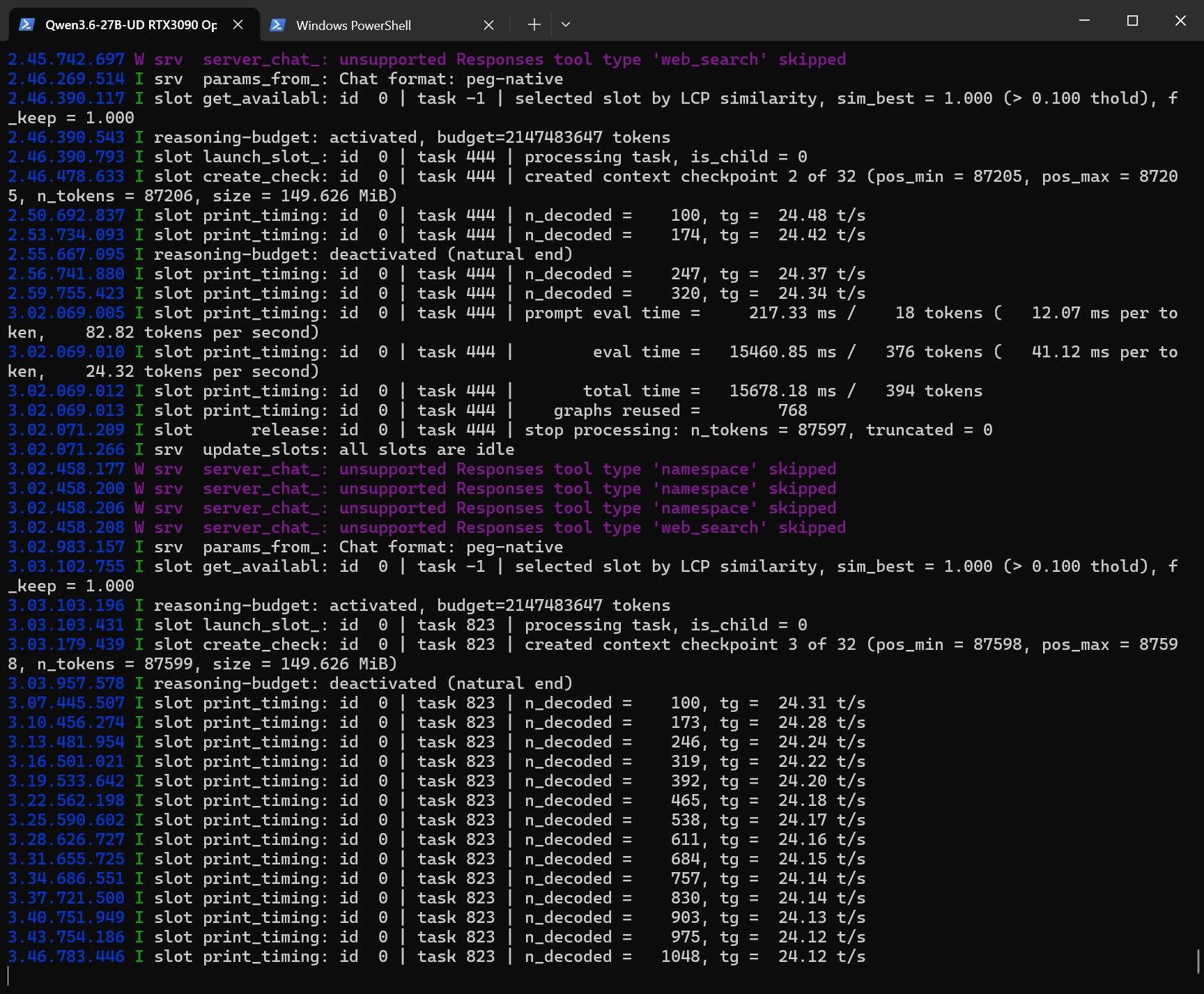
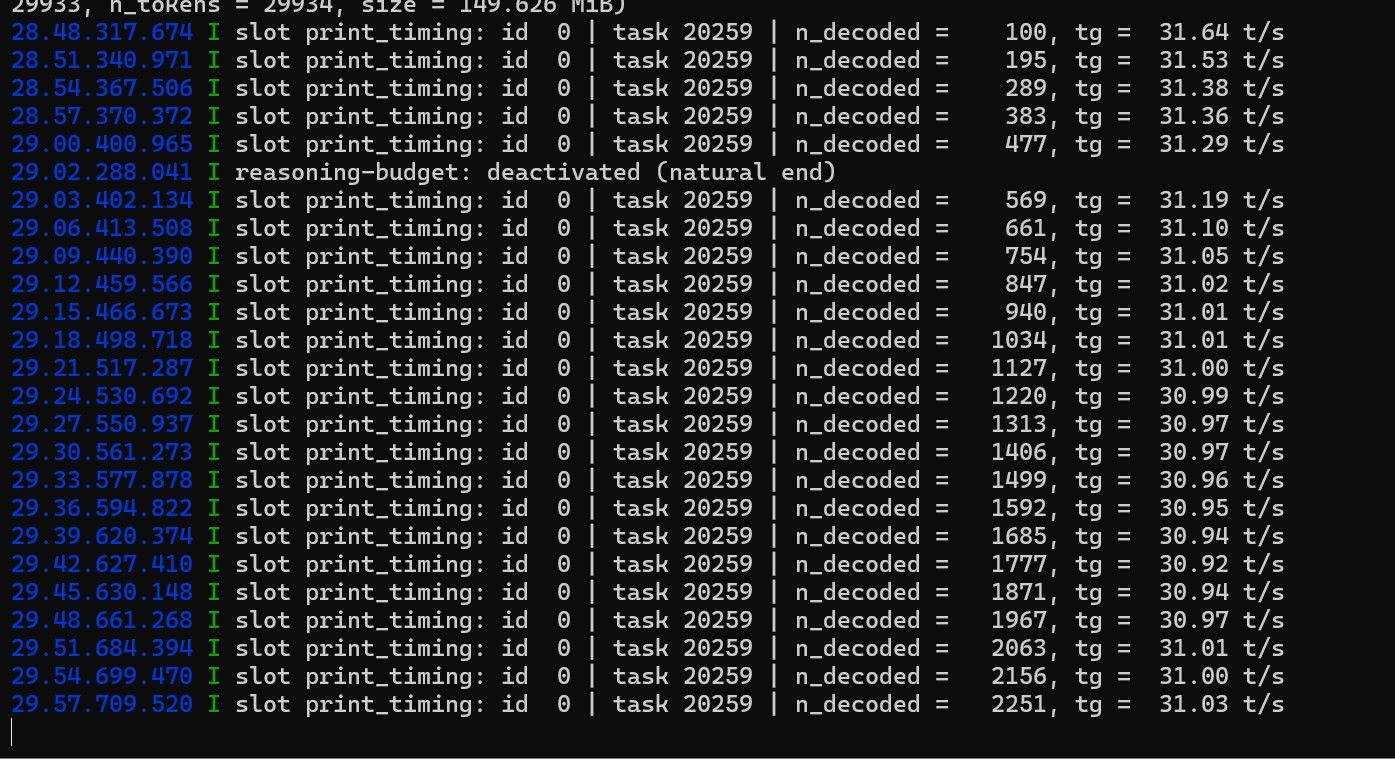
终端测是codex桌面版
使用codex编制一个小程序,实际速率如截图