
618 买的 7900xtx + 1200w金牌电源套装,6300左右。
有个闲置的老服务器,E52670 v2(原本是V1,听说没有pcie atomics,花了70块钱买了两块V2换上)64G ddr3,华硕Z9PA-D8主板,去年送人都没人要,今年拿来跑hermes了。
到货之后,就换上电源,插上显卡,开机。
配置如下:
Hardware: ASUS Z9PA-D8 + 2x E5-2670 V2 + 64GB DDR3 ECC + RX 7900 XTX 24GB
OS: Ubuntu 24.04 Server
Driver: Mesa 26.1.2 (RADV NAVI31)
Backend: Vulkan
llama.cpp: b9664 + 最新版自编译
两个模型:
Qwen3.6-27B-uncensored-heretic-v2-Native-MTP-Preserved-Q4_K_M.gguf
Qwen3.6-35B-A3B-uncensored-heretic-Native-MTP-Preserved-APEX-I-Compact.gguf
配对应的mmproj 。
启动脚本:
27B:
#!/bin/bash
# 1. 注入 AMD Vulkan 专属性能优化变量
export GGML_VK_ALLOW_GRAPHICS_QUEUE=1
export GGML_VK_VISIBLE_DEVICES=0
# 2. 启动服务
exec /data/llamacpp/llama-server-active \
-m /data/models/Qwen3.6-27B-uncensored-heretic-v2-Native-MTP-Preserved-Q4_K_M.gguf \
--mmproj /data/models/mmproj-27B-F16.gguf \
-ngl 999 \
-c 131072\
-np 1 \
-ctk q8_0 -ctv q8_0 \
-fa on \
--image-min-tokens 1024 \
--jinja \
--chat-template-file /data/models/fix-chat_template.jinja \
--spec-type draft-mtp --spec-draft-n-max 2 \
--host 0.0.0.0 \
--port 7890 \
--api-key xxxxxxx \
--alias qwen-36-27B\
--metrics
35B:
#!/bin/bash
# 1. 注入 AMD Vulkan 专属性能优化变量
export GGML_VK_ALLOW_GRAPHICS_QUEUE=1
export GGML_VK_VISIBLE_DEVICES=0
# 2. 启动服务
exec /data/llamacpp/llama-server-active \
-m /data/models/Qwen3.6-35B-A3B-uncensored-heretic-Native-MTP-Preserved-APEX-I-Compact.gguf \
--mmproj /data/models/mmproj-35B-A3B-F16.gguf \
-ngl 999 \
-c 262144 \
-np 1 \
-b 2048 -ub 2048 \
-ctk q4_0 -ctv q4_0 \
-fa on \
--cache-reuse 4096 \
--image-min-tokens 1024 \
--jinja \
--chat-template-file /data/models/fix-chat_template.jinja \
--host 0.0.0.0 \
--port 7890 \
--api-key xxxxxxx \
--alias qwen-36-35BA3B \
--metrics
速度情况:
Qwen3.6 35BA3B:开启后约剩余4G显存
简单测试了一个58000 token 大文本(约10万汉字)prefill 大概2000,decode 大概116-117。
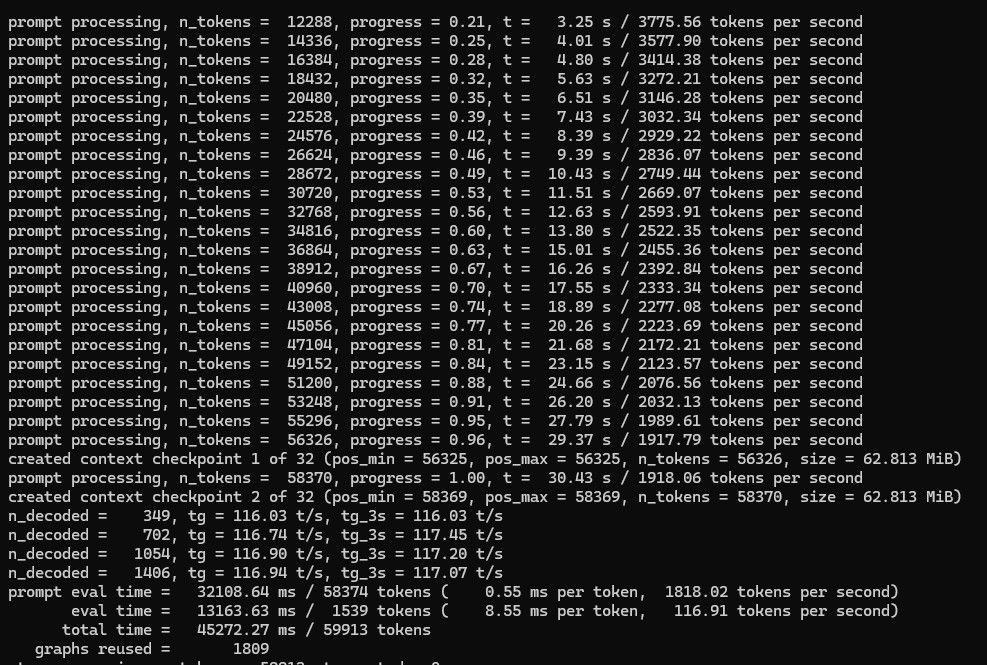
简单测试问答与千字左右文本生成:decode速度大概 130+
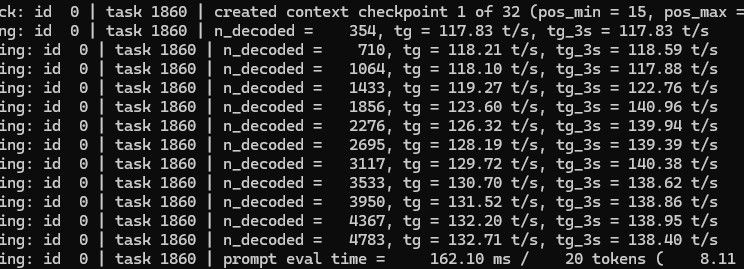
图片分析速度跟大文本差不多,不浪费资源了。
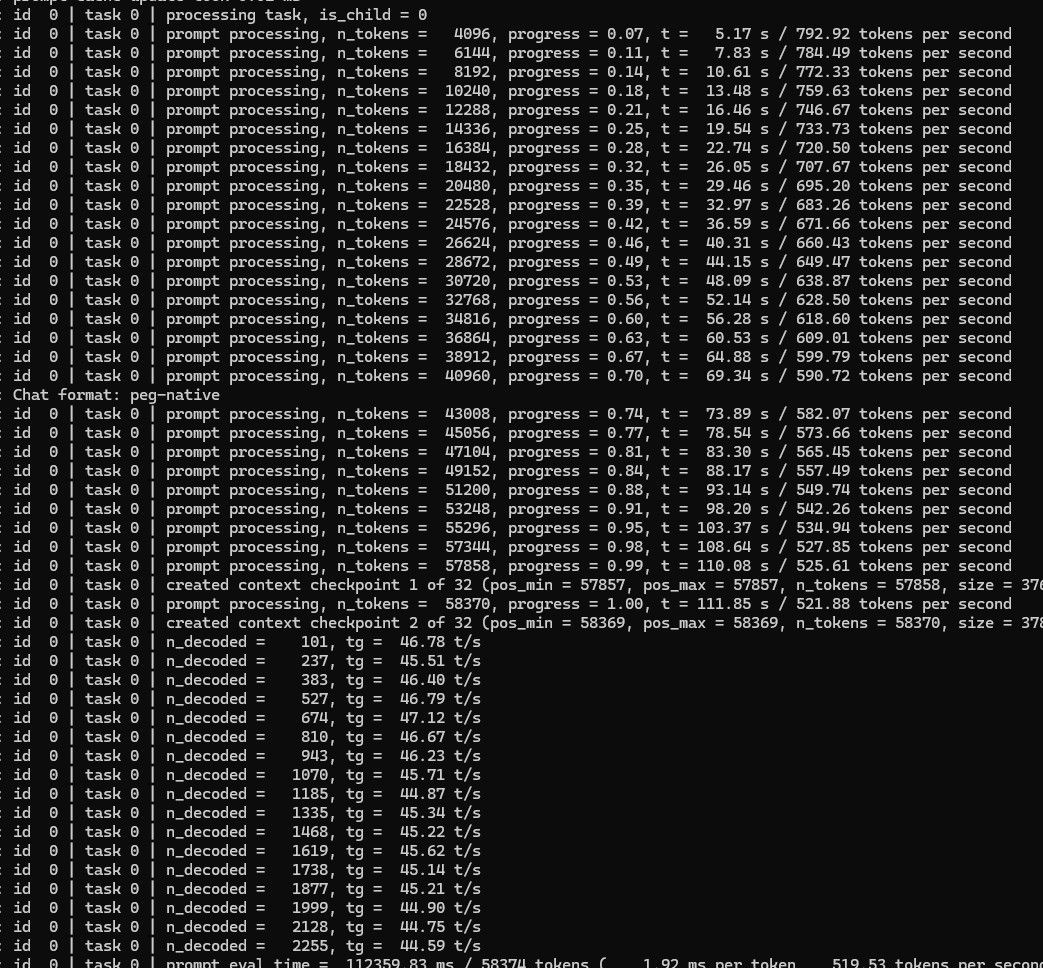
Qwen3.6 27B,开启后约剩余1G显存
58000token 大文本:prefill 平均600,decode 大概45。
简单问答千字左右文本生成:decode 大概 70+
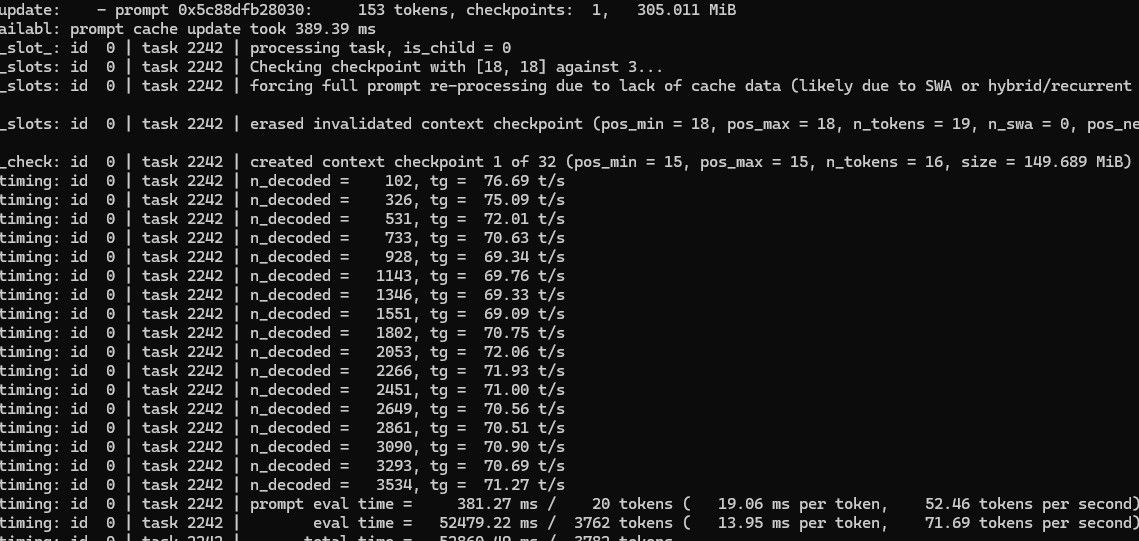
之前是用5090D32G vllm Qwen3.6-27B nvfp4量化。速度大概prefill 7000+ decode 200+。7900xtx 跑 35BA3B效果勉强能接近。目前就以35BA3B为主要模型在运行。
用途:
1 hermes 底座模型,配合修改过的jinja模板,实测没有出现bug,日常工作效果凑合。我不用hermes 开发,纯维护一些自动化脚本,rag库,搜索引擎服务之类的。
2 RSS重度使用者,vibe了一个自用的RSS阅读器,BYOK,无限token没心理负担,用llm实现快速新闻归类,新闻摘要,注意力等级标签等等。适合不喜欢推荐算法,希望保持大量阅读的用户:https://github.com/bemoons/KickRSS
3 沉浸式翻译,ocr,各种小ai应用等等。