我觉得本地化部署就两个场景适合:
- 你有私密的数据。local agents场景,Openclaw或者Hermes真要能帮你干活,你得给他很多私密的数据,服务器的用户名密码,邮箱密码什么的。
- 你的需求没有现成的外部算力平台,比如老特的那种定制化的数字人生产流水线。
其他你要是写代码,爬资料之类的公共信息相关需求,直接买coding plan肯定更划算。
我觉得本地化部署就两个场景适合:
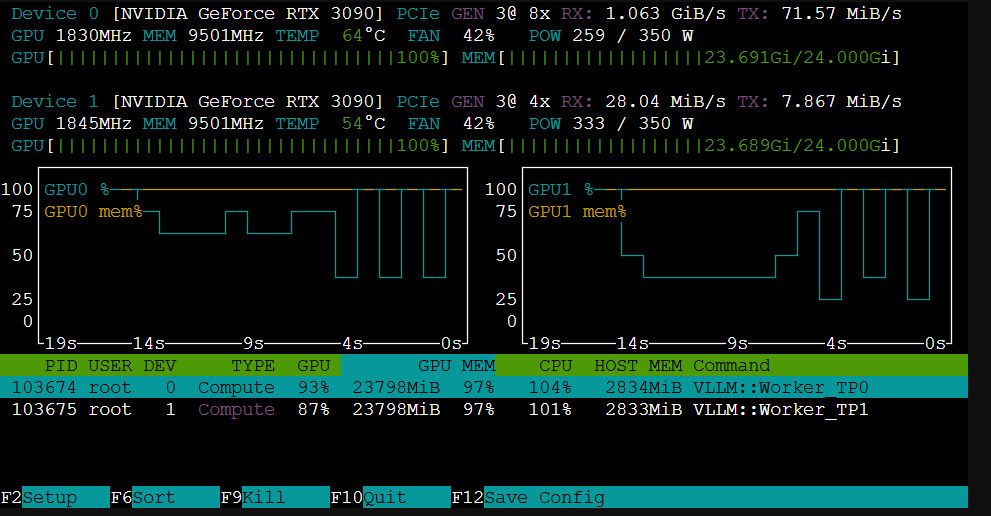
双卡3090 vLLM跑Qwen3.6-27B,强烈建议关注: https://github.com/noonghunna/club-3090 。
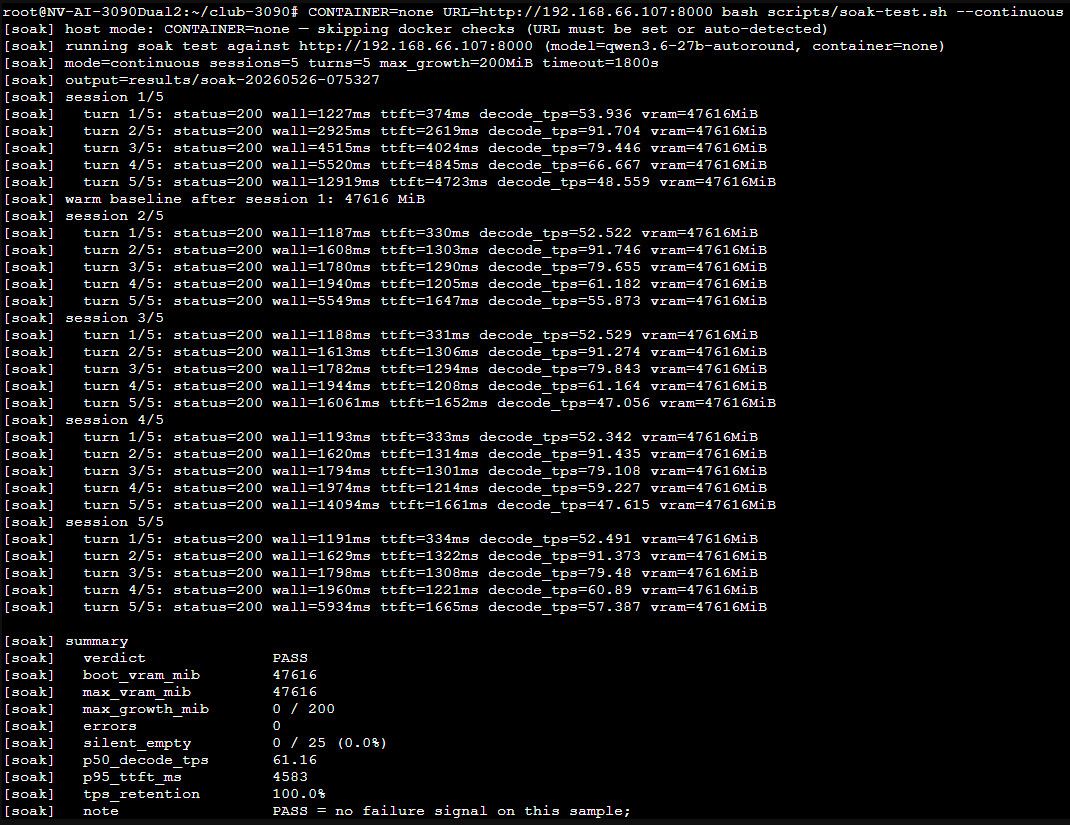
我自己的环境: 双卡3090 nvlink,模型Qwen3.6-27B-autoround-int4。 kv cache fp8_e5m2量化, 上下文长度 262144 。采用 dual-mtp 的vllm运行参数和测试脚本(soak-test.sh), p50_decode_tps:61.34;p95_ttft_ms:4864 。
官方给的测试,应该能到接近70tps,我的还有优化空间,但是能用了就没折腾,参考DUAL_CARD.md。
num_speculative_tokens我测了2,3,4,5。效果上3最好。
启动脚本:
root@NV-AI-3090Dual2:~# cat vllm.qwen3.6-27b.sh
#!/bin/bash
source /root/.bashrc
source /root/venv/bin/activate
# vLLM 启动脚本 — Qwen3.6-27B-AutoRound-INT4
# 用法: bash start-vllm-qwen3.6.sh [TP] [PP]
# TP: tensor-parallel size,默认 2
# PP: pipeline-parallel size,默认 1
set -e
# ========== 参数 ==========
TP="${1:-${TP:-2}}"
PP="${2:-${PP:-1}}"
MODEL_PATH="/root/models/qwen3.6-27b-autoround-int4"
PORT="${PORT:-8000}"
HOST="${HOST:-0.0.0.0}"
MAX_MODEL_LEN="${MAX_MODEL_LEN:-262144}"
GPU_MEM_UTIL="${GPU_MEMORY_UTILIZATION:-0.92}"
KV_CACHE_DTYPE="${KV_CACHE_DTYPE:-fp8_e5m2}"
TEMP="${TEMP:-${TEMPERATURE:-0.6}}"
TOP_P="${TOP_P:-0.95}"
TOP_K="${TOP_K:-20}"
MIN_P="${MIN_P:-0.0}"
REPEAT_PENALTY="${REPEAT_PENALTY:-1.0}"
# speculative decoding
SPECULATIVE_CONFIG='{"method":"mtp","num_speculative_tokens":3}'
# 推理模板参数(关闭 thinking)
CHAT_TEMPLATE_KWARGS='{"enable_thinking": false}'
# ========== 环境变量 ==========
export NVIDIA_VISIBLE_DEVICES="${NVIDIA_VISIBLE_DEVICES:-all}"
export HUGGING_FACE_HUB_TOKEN="${HF_TOKEN:-}"
export VLLM_WORKER_MULTIPROC_METHOD=spawn
export NCCL_CUMEM_ENABLE=0
export NCCL_P2P_DISABLE=0
export VLLM_NO_USAGE_STATS=1
export VLLM_USE_FLASHINFER_SAMPLER=1
export OMP_NUM_THREADS=1
export PYTORCH_CUDA_ALLOC_CONF="expandable_segments:True,max_split_size_mb:512"
# NVLink 检测(自行补充 detect_nvlink.sh 逻辑,或删掉这两行)
# source /etc/club3090/detect_nvlink.sh
# _NVLINK_ENABLED=0 # 手动设置:0=无NVLink, 1=NvLink开启
# ========== 构建命令 ==========
ARGS=(
--model "$MODEL_PATH"
--served-model-name qwen3.6-27b-autoround
--quantization auto_round
--dtype float16
--tensor-parallel-size "$TP"
--pipeline-parallel-size "$PP"
--max-model-len "$MAX_MODEL_LEN"
--gpu-memory-utilization "$GPU_MEM_UTIL"
--max-num-seqs 2
--max-num-batched-tokens 8192
--kv-cache-dtype "$KV_CACHE_DTYPE"
--trust-remote-code
# --chat-template "${CHAT_TEMPLATE}" # 没有自定义模板文件则删除此行
--reasoning-parser qwen3
--default-chat-template-kwargs "$CHAT_TEMPLATE_KWARGS"
--enable-auto-tool-choice
--tool-call-parser qwen3_coder
--enable-prefix-caching
--enable-chunked-prefill
--disable-custom-all-reduce
--speculative-config "$SPECULATIVE_CONFIG"
--override-generation-config "{\"temperature\":${TEMP},\"top_p\":${TOP_P},\"top_k\":${TOP_K},\"min_p\":${MIN_P},\"repetition_penalty\":${REPEAT_PENALTY}}"
--host "$HOST"
--port "$PORT"
)
echo "=========================================="
echo "启动 vLLM | TP=$TP PP=$PP | $MODEL_PATH"
echo "=========================================="
echo "命令: vllm serve ${ARGS[*]}"
echo ""
exec vllm serve "${ARGS[@]}"
deactivate
我第一台自己的PC也是手搓的,2000年 毒龙750+256M内存,20G硬盘。用了5年,最后加到512M内存做archlinux的NAS. 跑了电驴、samba、nfs什么的。记得当时硬盘都是并口,动静老大了,而且还特别烫手。
Rustdesk我一直在用效果不错。建议自架服务,不要用官方服务,安全第一。
内网穿透,方案很多了,我现在是手机ipv6的wireguard穿回来;如果你传大文件,建议用vmess这种伪装的协议,我架了一个vmess的ws,放在ipv6的网站下,作为传大文件和wg的备用。wg是基于udp的,用的多了容易被运营商卡速度,vmess+ws基于tcp没有这个问题。
如果不愿意用ipv6或者嫌不方便,可以考虑nat打洞,具体youtube上各大博主都有介绍,嫌麻烦就cloudflare,不怕麻烦就弄个小水管的vps做信息中转。我实测nat打洞还是挺方便的,各种网络环境都能回来。 cloudflare反代方案好在不用改端口,但是速度不太行,小流量延时不敏感的可以考虑。
今天看到一篇微信公众号文章: https://mp.weixin.qq.com/s/KQo-UBEOvtRMW5dK1bz6PQ
按照文章内容搭建了测试环境:
git clone https://github.com/ggml-org/llama.cpp llama.cpp-mtp
cd llama.cpp-mtp
git fetch origin pull/22673/head:pr-22673
git checkout pr-22673
mkdir build && cd build
cmake .. \
-DCMAKE_BUILD_TYPE=Release \
-DGGML_CUDA=ON \
-DLLAMA_CURL=ON \
-DGGML_NATIVE=ON \
-DGGML_CUDA_GRAPHS=ON \
-DGGML_CUDA_F16=ON \
-DGGML_CUDA_FA_ALL_QUANTS=ON \
-DCMAKE_CUDA_ARCHITECTURES=75 # 按需调整,89=Ada/4090,86=Ampere/3090
cmake --build . --config Release \
--target llama-server llama-bench --parallel
下载了unsloth的开启MTP模型: https://huggingface.co/unsloth/Qwen3.6-27B-MTP-GGUF/resolve/main/Qwen3.6-27B-Q4_K_M.gguf -O ~/models/Qwen3.6-27B-MTP-Q4_K_M.gguf
不加载vision的情况下, 启动:
~/llama.cpp-mtp/build/bin/llama-server -m ~/models/Qwen3.6-27B-MTP-Q4_K_M.gguf \
--ctx-size 131072 \
--n-gpu-layers 999 \
-fa on \
--port 8000 \
--host 0.0.0.0 \
--cache-type-k q4_0 \
--cache-type-v q4_0 \
--no-mmap \
--no-warmup \
--reasoning off \
--jinja \
--parallel 1 \
--spec-type mtp \
--spec-draft-n-max 2 \
--chat-template-kwargs "{\"enable_thinking\": false, \"preserve_thinking\": false}"
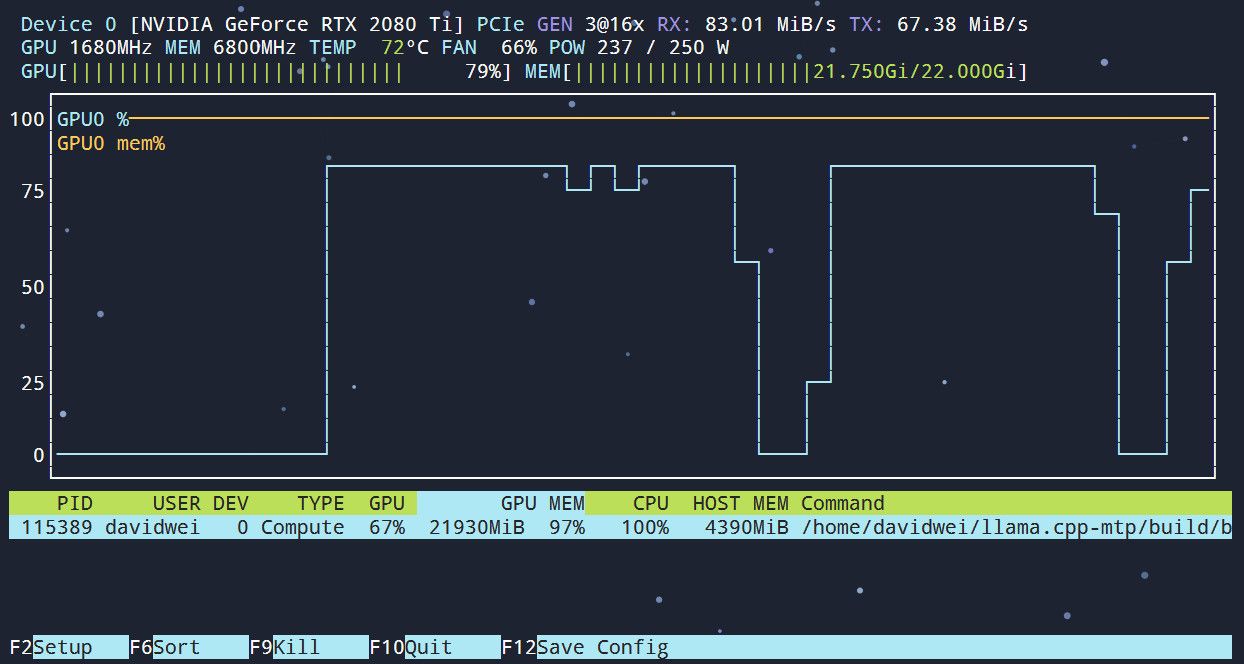
128k上下文,显存占用20.5G,简单用cherrybox提了几个问题,prompt大概2k上下。 TPS从之前的27提升到了33左右。整体感觉快了20%。 coding场景没有测试,理论上应该提升更多。
另外,对于--spec-draft-n-max 的值,测了1,2,3。发现2时收益最大,能跑到33~34; 1和3都在30上下。 总体都比裸跑有提升。
最后挂上了vision,发了一张1M左右的图片测试了一下,TPS在28左右,显存占用21.75G。 我准备测几天,看看会不会OOM。
另外还有一个发现,开了MTP以后,显卡的utility下来了。之前基本上都在95%以上,功率一直顶着上限250W。开了MTP,tps上升的同时,utility基本上都在80%左右,功率也基本上不会满载了。估计是降低了开销,输出也降低,但是被MTP补偿了。
总体来讲,2080Ti这个卡应该没什么压榨空间了,跑Hermes太慢,适合跑好skill,布置好cron让他后台自己干活,不适合前台交互。