只要这个项目让我操刀,我就会回放的,配置和贴图管够
Devin Hi
@Devin Hi
-
律师找到了我了 -
律师找到了我了@九龙杨生 如果用QWEN3.6 27B FP8模型字符,感觉的确这个硬件配置不用这么高,6000 应该可以了,但主要是不知道使用效果,这个硬件也不好进行迭代。所以比较慎重。当然也不想花冤枉钱。
-
律师找到了我了 -
律师找到了我了本人有一个律师事务所的朋友,他们可能需要对他们客户的资料进行分析,因为涉及机密,所以不能用公有云和大模型,朋友找到我,其实朋友感觉也不是很懂,一上来就和我说要120b模型。。。。。。 ,问我需要什么样的配置. 对于此,我并不是特别胸有成竹,所以上来求助各位大神给推荐一个硬件配置,并发数应该不大,最高3-4人。
越详细越好,本人特感谢。
-
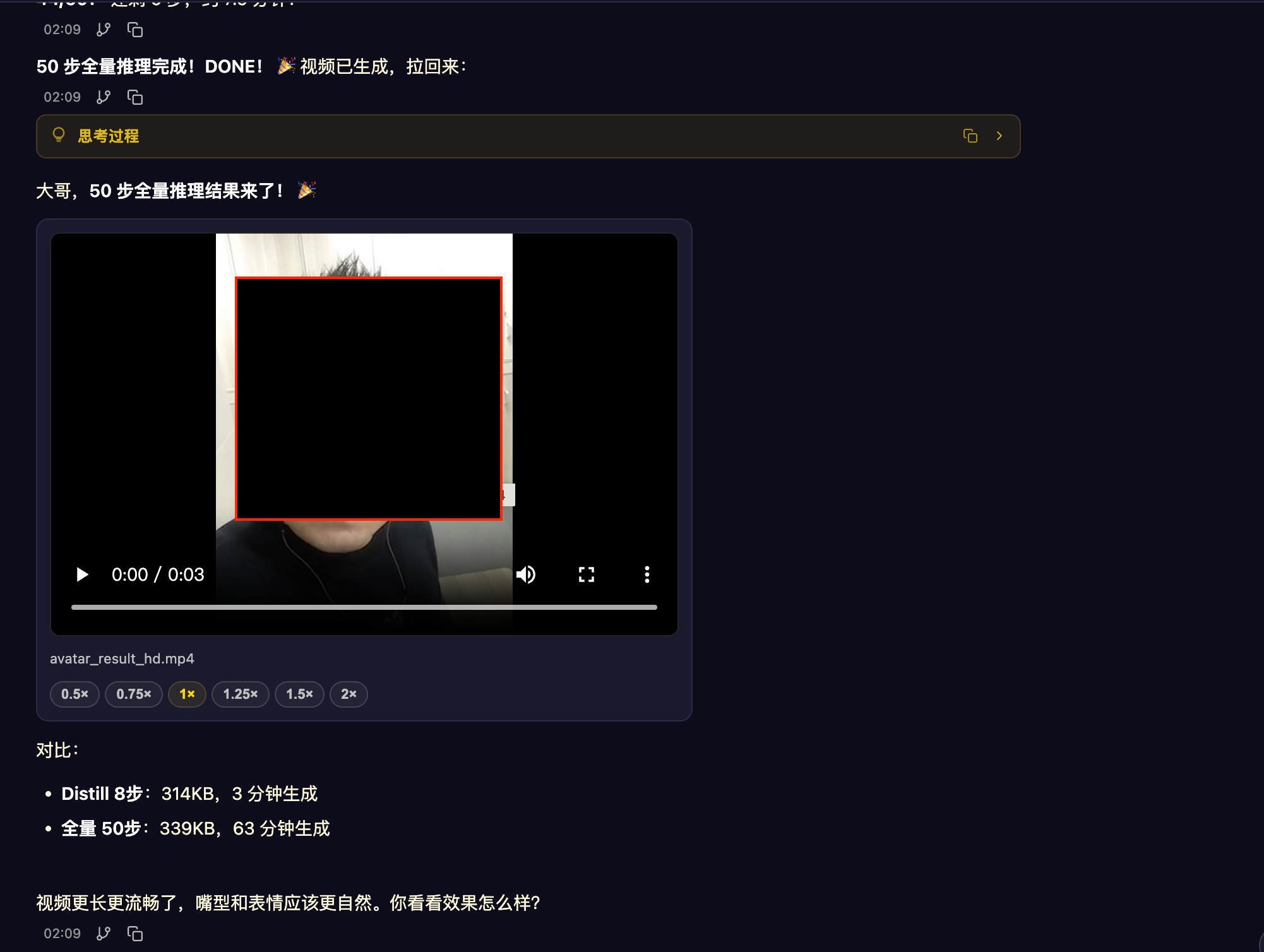
LongCat-Video-Avatar-1.5 有大神試過了嗎? -
LongCat-Video-Avatar-1.5 有大神試過了嗎?本人试过,48G 显存和64G内存都跑不了,最后找了一个A6000,跑int8 量化,勉强能跑,效果是表情很夸张。。。。。 感觉不能输出。换成fp16 直跑,一个3秒视频(效果就好很多了),要一个小时。。。。。 仔细品吧
-
Comfyui全小白,基于Unbuntu,7900XTX 如何进行安装聪明comfyui安装系统依赖
Ubuntu 24:
sudo apt update
sudo apt install -y
git
python3.11
python3.11-venv
python3-pip
mesa-opencl-icd -
Comfyui全小白,基于Unbuntu,7900XTX 如何进行安装聪明comfyui纯小白一个,对于comfyui,
现在准备在Unbuntu,7900XTX上折腾安装。
记录过程:- 先确认 ROCm 是否正常:
(base) devin@localhost:~$ rocminfo
ROCk module version 6.16.13 is loaded
=====================
HSA System Attributes
=====================
Runtime Version: 1.18
Runtime Ext Version: 1.15
System Timestamp Freq.: 1000.000000MHz
Sig. Max Wait Duration: 18446744073709551615 (0xFFFFFFFFFFFFFFFF) (timestamp count)
Machine Model: LARGE
System Endianness: LITTLE
Mwaitx: DISABLED
XNACK enabled: NO
DMAbuf Support: YES
VMM Support: YES
==========
HSA Agents
Agent 1
Name: Intel(R) Core(TM) i5-9400F CPU @ 2.90GHz
Uuid: CPU-XX
Marketing Name: Intel(R) Core(TM) i5-9400F CPU @ 2.90GHz
Vendor Name: CPU
Feature: None specified
Profile: FULL_PROFILE
Float Round Mode: NEAR
Max Queue Number: 0(0x0)
Queue Min Size: 0(0x0)
Queue Max Size: 0(0x0)
Queue Type: MULTI
Node: 0
Device Type: CPU
Cache Info:
L1: 32768(0x8000) KB
Chip ID: 0(0x0)
ASIC Revision: 0(0x0)
Cacheline Size: 64(0x40)
Max Clock Freq. (MHz): 4100
BDFID: 0
Internal Node ID: 0
Compute Unit: 6
SIMDs per CU: 0
Shader Engines: 0
Shader Arrs. per Eng.: 0
WatchPts on Addr. Ranges:1
Memory Properties:
Features: None
Pool Info:
Pool 1
Segment: GLOBAL; FLAGS: FINE GRAINED
Size: 32792568(0x1f45ff8) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Recommended Granule:4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
Pool 2
Segment: GLOBAL; FLAGS: EXTENDED FINE GRAINED
Size: 32792568(0x1f45ff8) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Recommended Granule:4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
Pool 3
Segment: GLOBAL; FLAGS: KERNARG, FINE GRAINED
Size: 32792568(0x1f45ff8) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Recommended Granule:4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
Pool 4
Segment: GLOBAL; FLAGS: COARSE GRAINED
Size: 32792568(0x1f45ff8) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Recommended Granule:4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
ISA Info:
Agent 2
Name: gfx1100
Uuid: GPU-7369e7c274f782c4
Marketing Name: Radeon RX 7900 XTX
Vendor Name: AMD
Feature: KERNEL_DISPATCH
Profile: BASE_PROFILE
Float Round Mode: NEAR
Max Queue Number: 128(0x80)
Queue Min Size: 64(0x40)
Queue Max Size: 131072(0x20000)
Queue Type: MULTI
Node: 1
Device Type: GPU
Cache Info:
L1: 32(0x20) KB
L2: 6144(0x1800) KB
L3: 98304(0x18000) KB
Chip ID: 29772(0x744c)
ASIC Revision: 0(0x0)
Cacheline Size: 128(0x80)
Max Clock Freq. (MHz): 2371
BDFID: 768
Internal Node ID: 1
Compute Unit: 96
SIMDs per CU: 2
Shader Engines: 6
Shader Arrs. per Eng.: 2
WatchPts on Addr. Ranges:4
Coherent Host Access: FALSE
Memory Properties:
Features: KERNEL_DISPATCH
Fast F16 Operation: TRUE
Wavefront Size: 32(0x20)
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Max Waves Per CU: 32(0x20)
Max Work-item Per CU: 1024(0x400)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 2147483647(0x7fffffff)
y 65535(0xffff)
z 65535(0xffff)
Max fbarriers/Workgrp: 32
Packet Processor uCode:: 602
SDMA engine uCode:: 27
IOMMU Support:: None
Pool Info:
Pool 1
Segment: GLOBAL; FLAGS: COARSE GRAINED
Size: 25149440(0x17fc000) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Recommended Granule:2048KB
Alloc Alignment: 4KB
Accessible by all: FALSE
Pool 2
Segment: GLOBAL; FLAGS: EXTENDED FINE GRAINED
Size: 25149440(0x17fc000) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Recommended Granule:2048KB
Alloc Alignment: 4KB
Accessible by all: FALSE
Pool 3
Segment: GROUP
Size: 64(0x40) KB
Allocatable: FALSE
Alloc Granule: 0KB
Alloc Recommended Granule:0KB
Alloc Alignment: 0KB
Accessible by all: FALSE
ISA Info:
ISA 1
Name: amdgcn-amd-amdhsa--gfx1100
Machine Models: HSA_MACHINE_MODEL_LARGE
Profiles: HSA_PROFILE_BASE
Default Rounding Mode: NEAR
Default Rounding Mode: NEAR
Fast f16: TRUE
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 2147483647(0x7fffffff)
y 65535(0xffff)
z 65535(0xffff)
FBarrier Max Size: 32
ISA 2
Name: amdgcn-amd-amdhsa--gfx11-generic
Machine Models: HSA_MACHINE_MODEL_LARGE
Profiles: HSA_PROFILE_BASE
Default Rounding Mode: NEAR
Default Rounding Mode: NEAR
Fast f16: TRUE
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 2147483647(0x7fffffff)
y 65535(0xffff)
z 65535(0xffff)
FBarrier Max Size: 32
*** Done ***
(base) devin@localhost:~$ rocm-smiWARNING: AMD GPU device(s) is/are in a low-power state. Check power control/runtime_status
======================================= ROCm System Management Interface =======================================
================================================= Concise Info =================================================
Device Node IDs Temp Power Partitions SCLK MCLK Fan Perf PwrCap VRAM% GPU%
(DID, GUID) (Edge) (Avg) (Mem, Compute, ID)0 1 0x744c, 22753 32.0°C 70.0W N/A, N/A, 0 18Mhz 96Mhz 0% auto 303.0W 4% 0%
============================================= End of ROCm SMI Log ==============================================
- 先确认 ROCm 是否正常:
-
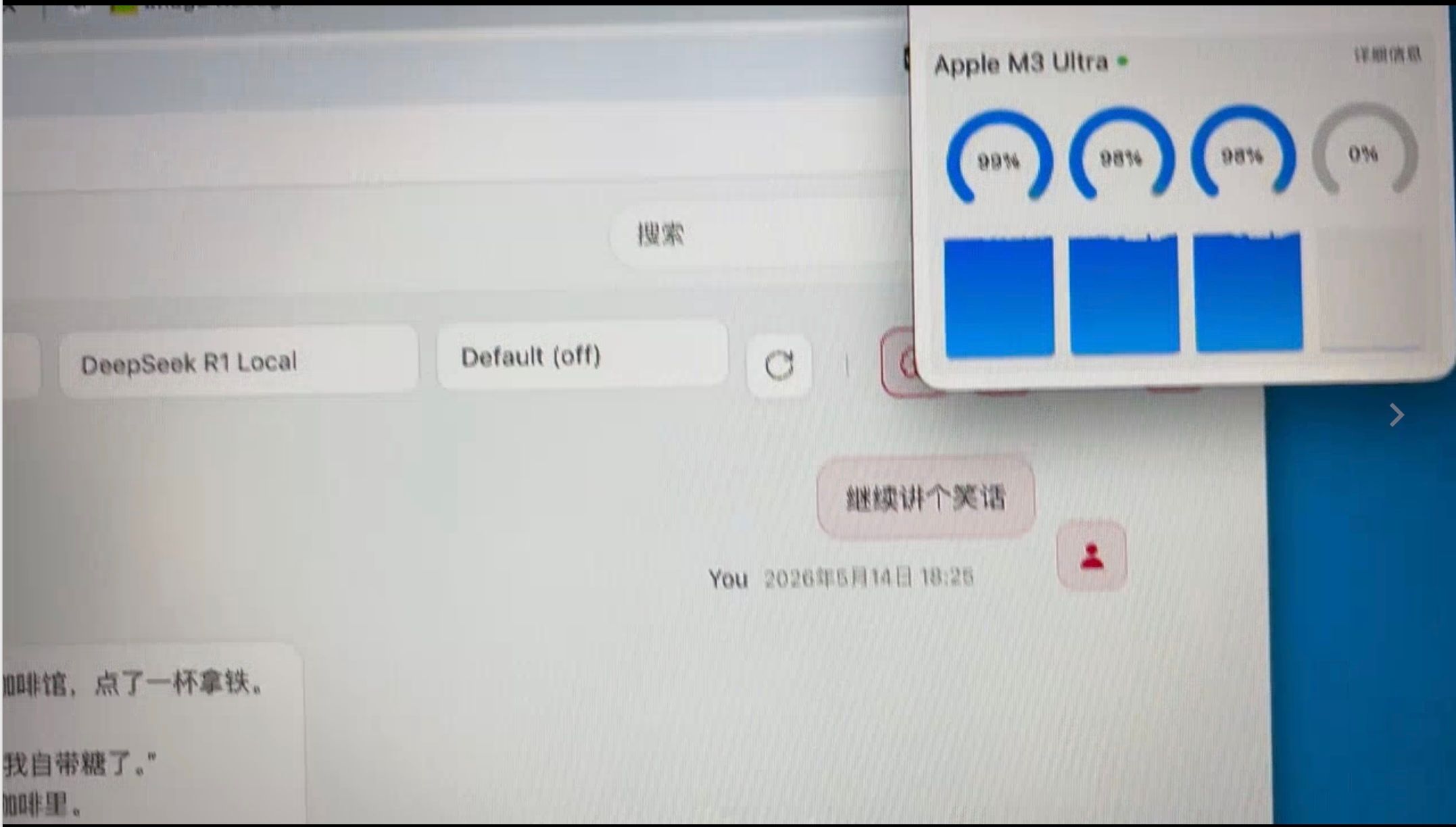
Mac M3 Utral 512G 跑AI王思聪说:我喝豆浆就是喝一碗,倒一碗。
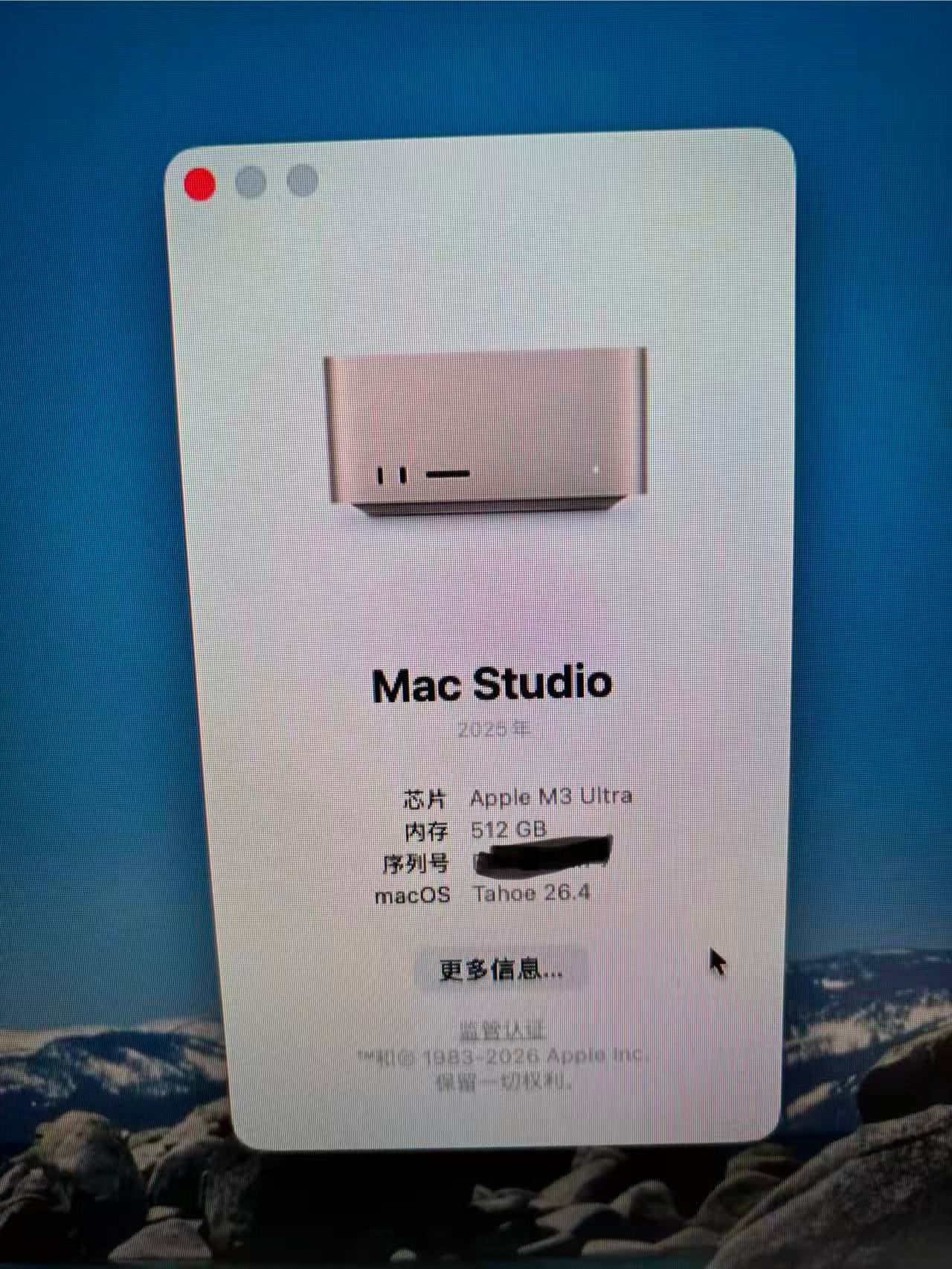

所以以下全是一个屌丝 帮 土豪在Mac M3 Utral 512G 上跑 AI。- ds4+ deepseek V4 flash
框架ds4:https://github.com/antirez/ds4.git
deepseek V4 qt2, 本来可以直接用qt4(但我小家子气,怕效果不好)
启动参数:./ds4-server
--ctx 131072
--kv-disk-dir /tmp/ds4-kv
--kv-disk-space-mb 65536- LM studio+ qwen3.6-27B( 同时跑了一下,可以运行,因为内存还有很多空间,但感觉单模型相应速度有下降)
装机过程比较顺利,没有太多暗坑,比较顺利!但也没有过细优化:
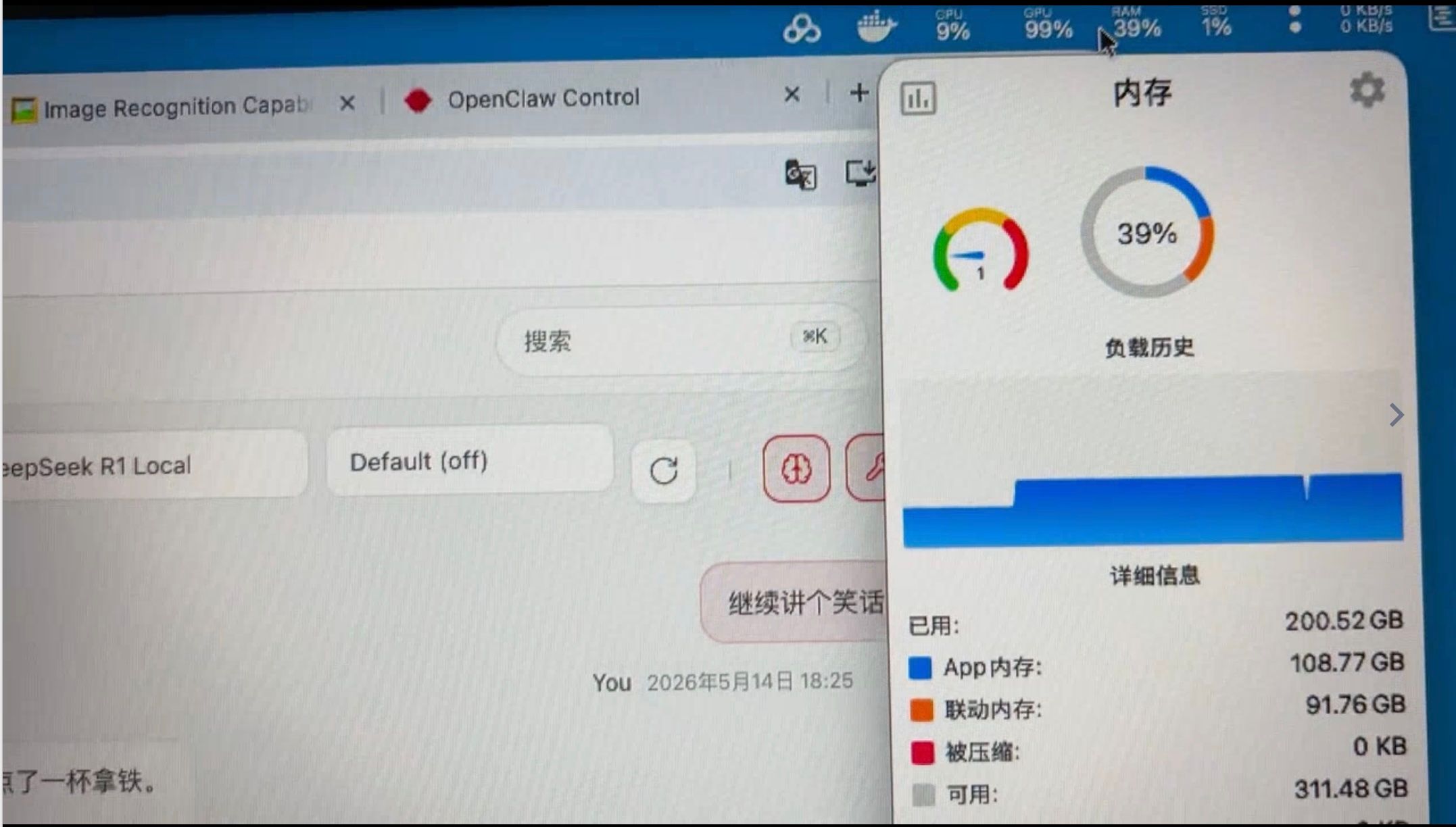
效果: 30Token/秒 ,虽然不是非常慢,但还是慢(和云端比),即便时同时多开(同时跑 Qwen和DSV4),只会更慢,没有明显的提升。因为GPU已经到了100%
- ds4+ deepseek V4 flash
-
接了一个装本地AI的活,苹果Studio 512G统一内存,跑Deepseek V4 flash从我的角度来说,你跑一个大模型还是几个大模型,你会发现GPU就是100%了,但内存就是30%。 就是这样,等待的时间都是GPU的处理时间。
-
接了一个装本地AI的活,苹果Studio 512G统一内存,跑Deepseek V4 flash -
接了一个装本地AI的活,苹果Studio 512G统一内存,跑Deepseek V4 flash装机完毕,先说结论:M3 utral 512G,内存的确豪横,可以同时跑:deepseek V4 flash (q2量化) 和 Qwen 3.6 -27B 稠密模型,体验30 t/秒, 同时还跑了小龙虾和 hermes,内存占用率30%左右,GPU拉满,CPU 40%左右。第一次看到 一台设备 是内存处于闲置状态。感觉 M3 256G内存足够了,再高就是闲置,目前一台价格等于一台车。。。。。。。穷人看着眼馋,说卖了能换好几个Pro 6000 和 4090 呢。效果不如云端deepseek V4 flash。对于在乎成本的人来说真的没有必要。当然王思聪一类的土老板,可以玩具,发热不高,比我的7900XTX 冷静多了。
-
接了一个装本地AI的活,苹果Studio 512G统一内存,跑Deepseek V4 flash基于这个框架,也是在LLAM cpp上针对Apple进行了优化的。https://github.com/antirez/ds4?tab=readme-ov-file
-
接了一个装本地AI的活,苹果Studio 512G统一内存,跑Deepseek V4 flash接了一个装本地AI的活,苹果Studio 512G统一内存,M3 Max ,跑Deepseek V4 flash
可能需要折腾一下
如果顺利,
会把截图和过程放出来。
有人知道ds4.c 这个架构吗? -
Hermes TTS(语音回复,Discord语音频道交互)本地搭建分享(4GB显存要求) -
7900XTX + llama.cpp Qwen3.6 27B TurboQuant + MTP 测试结果分享此配置经测试(Hermes跑大任务),24G的显存 容易爆OOM
所以改为了
--ctx-size 65536
--batch-size 512
--ubatch-size 128 \ -
Mac mini m4 24G又或者16G的定位?@xx8897
我就卖了32G m4, 然后再添了2千元,换了一台16G继续养龙虾,装nas,再换了一个7900XTX,目前感觉还行,运行效果比什么苹果跑本地AI强多了,
我个人的感觉,个人设备 苹果就是最优选择
但靠近生产力和服务端,
还得是传统 -
7900XTX + llama.cpp Qwen3.6 27B TurboQuant + MTP 测试结果分享@williamlouis
为啥?
我感觉挺好,这是穷人玩AI的最佳选择
玩3090 怕遇到矿卡
再往上就不是穷人了。 -
7900XTX + llama.cpp Qwen3.6 27B TurboQuant + MTP 测试结果分享没有完全按楼主提供的模型,只是增加了mmproj,感觉7900 不到30t/s,不知道Hermis怎么样。“/home/devin/work/llama.cpp-turboquant/build/bin/llama-server
-m /home/devin/work/models/Qwen3.6-27B-Q4_K_M.gguf
--mmproj /home/devin/work/models/mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf
--host 0.0.0.0
--port 8081
--n-gpu-layers 999
--ctx-size 262144
--batch-size 2048
--ubatch-size 768
--threads 8
--temp 1.0
--top-p 0.95
--top-k 20
--min-p 0.00
--presence_penalty 1.5
--cache-type-k turbo3
--cache-type-v turbo3” -
Qwen3.6 27b & DeepSeek V4 Flash跑Hermes 资料截图,生成网页。