我发的:slot launch_slot_: id 1 | task -1 | sampler chain: logits -> ?penalties -> ?dry -> ?top-n-sigma -> top-k -> ?typical -> top-p -> min-p -> ?xtc -> ?temp-ext -> dist
slot launch_slot_: id 1 | task 6822 | processing task, is_child = 0
slot update_slots: id 1 | task 6822 | new prompt, n_ctx_slot = 95232, n_keep = 0, task.n_tokens = 30511
slot update_slots: id 1 | task 6822 | n_past = 30273, slot.prompt.tokens.size() = 30505, seq_id = 1, pos_min = 30504, n_swa = 0
slot update_slots: id 1 | task 6822 | Checking checkpoint with [30270, 30270] against 30273...
slot update_slots: id 1 | task 6822 | restored context checkpoint (pos_min = 30270, pos_max = 30270, n_tokens = 30271, n_past = 30271, size = 149.626 MiB)
slot update_slots: id 1 | task 6822 | n_tokens = 30271, memory_seq_rm [30271, end)
slot update_slots: id 1 | task 6822 | prompt processing progress, n_tokens = 30507, batch.n_tokens = 236, progress = 0.999869
slot update_slots: id 1 | task 6822 | n_tokens = 30507, memory_seq_rm [30507, end)
slot init_sampler: id 1 | task 6822 | init sampler, took 2.71 ms, tokens: text = 30511, total = 30511
slot update_slots: id 1 | task 6822 | prompt processing done, n_tokens = 30511, batch.n_tokens = 4
slot create_check: id 1 | task 6822 | created context checkpoint 11 of 32 (pos_min = 30506, pos_max = 30506, n_tokens = 30507, size = 149.626 MiB)
srv log_server_r: done request: POST /v1/chat/completions 127.0.0.1 200
reasoning-budget: deactivated (natural end)
slot print_timing: id 1 | task 6822 |
prompt eval time = 421.28 ms / 240 tokens ( 1.76 ms per token, 569.69 tokens per second)
eval time = 1775.41 ms / 66 tokens ( 26.90 ms per token, 37.17 tokens per second)
total time = 2196.70 ms / 306 tokens
slot release: id 1 | task 6822 | stop processing: n_tokens = 30576, truncated = 0
srv update_slots: all slots are idle
srv params_from_: Chat format: peg-native
slot get_availabl: id 1 | task -1 | selected slot by LCP similarity, sim_best = 0.677 (> 0.100 thold), f_keep = 1.000
reasoning-budget: activated, budget=2147483647 tokens
slot launch_slot_: id 1 | task -1 | sampler chain: logits -> ?penalties -> ?dry -> ?top-n-sigma -> top-k -> ?typical -> top-p -> min-p -> ?xtc -> ?temp-ext -> dist
slot launch_slot_: id 1 | task 6890 | processing task, is_child = 0
slot update_slots: id 1 | task 6890 | new prompt, n_ctx_slot = 95232, n_keep = 0, task.n_tokens = 45168
slot update_slots: id 1 | task 6890 | n_tokens = 30576, memory_seq_rm [30576, end)
slot update_slots: id 1 | task 6890 | prompt processing progress, n_tokens = 32624, batch.n_tokens = 2048, progress = 0.722281
slot update_slots: id 1 | task 6890 | n_tokens = 32624, memory_seq_rm [32624, end)
slot update_slots: id 1 | task 6890 | prompt processing progress, n_tokens = 34672, batch.n_tokens = 2048, progress = 0.767623
slot update_slots: id 1 | task 6890 | n_tokens = 34672, memory_seq_rm [34672, end)
slot update_slots: id 1 | task 6890 | prompt processing progress, n_tokens = 36720, batch.n_tokens = 2048, progress = 0.812965
slot update_slots: id 1 | task 6890 | n_tokens = 36720, memory_seq_rm [36720, end)
slot update_slots: id 1 | task 6890 | prompt processing progress, n_tokens = 38768, batch.n_tokens = 2048, progress = 0.858307
slot update_slots: id 1 | task 6890 | n_tokens = 38768, memory_seq_rm [38768, end)
slot update_slots: id 1 | task 6890 | 8192 tokens since last checkpoint at 30507, creating new checkpoint during processing at position 40816
slot update_slots: id 1 | task 6890 | prompt processing progress, n_tokens = 40816, batch.n_tokens = 2048, progress = 0.903649
slot create_check: id 1 | task 6890 | created context checkpoint 12 of 32 (pos_min = 38767, pos_max = 38767, n_tokens = 38768, size = 149.626 MiB)
slot update_slots: id 1 | task 6890 | n_tokens = 40816, memory_seq_rm [40816, end)
slot update_slots: id 1 | task 6890 | prompt processing progress, n_tokens = 42864, batch.n_tokens = 2048, progress = 0.948990
slot update_slots: id 1 | task 6890 | n_tokens = 42864, memory_seq_rm [42864, end)
slot update_slots: id 1 | task 6890 | prompt processing progress, n_tokens = 44652, batch.n_tokens = 1788, progress = 0.988576
slot update_slots: id 1 | task 6890 | n_tokens = 44652, memory_seq_rm [44652, end)
slot update_slots: id 1 | task 6890 | prompt processing progress, n_tokens = 45164, batch.n_tokens = 512, progress = 0.999911
slot create_check: id 1 | task 6890 | created context checkpoint 13 of 32 (pos_min = 44651, pos_max = 44651, n_tokens = 44652, size = 149.626 MiB)
slot update_slots: id 1 | task 6890 | n_tokens = 45164, memory_seq_rm [45164, end)
slot init_sampler: id 1 | task 6890 | init sampler, took 4.16 ms, tokens: text = 45168, total = 45168
slot update_slots: id 1 | task 6890 | prompt processing done, n_tokens = 45168, batch.n_tokens = 4
slot create_check: id 1 | task 6890 | created context checkpoint 14 of 32 (pos_min = 45163, pos_max = 45163, n_tokens = 45164, size = 149.626 MiB)
srv log_server_r: done request: POST /v1/chat/completions 127.0.0.1 200
reasoning-budget: deactivated (natural end)
slot print_timing: id 1 | task 6890 |
prompt eval time = 16677.88 ms / 14592 tokens ( 1.14 ms per token, 874.93 tokens per second)
eval time = 2132.32 ms / 79 tokens ( 26.99 ms per token, 37.05 tokens per second)
total time = 18810.20 ms / 14671 tokens
slot release: id 1 | task 6890 | stop processing: n_tokens = 45246, truncated = 0
srv update_slots: all slots are idle
这是本次用到35%左右上下文时的日志, 后面是本次的启动参数,我主要拉长了一些上下文 # 杀死旧进程,等待3秒确保释放资源
killall llama3-server 2>/dev/null; sleep 3
进入目录,启动优化后的服务(Hermes专属45分钟缓存保留,全局自动回收)
cd ~ && LLAMA_SET_ROWS=0 ./llama3-server
-m /data/models/Qwen3.6-27B-Omnimerge-v4-IQ4_NLmanni.gguf
--mmproj /data/models/mmproj-Qwen_Qwen3.6-27B-f16.gguf
--host 0.0.0.0 --port 12026 --fit on
--ctx-size 105000 -n -1 \
批处理拉满,3090算力最大化
--batch-size 8192 --ubatch-size 4096 \
KV缓存最低量化,稳跑65000ctx
--cache-type-k q2_K --cache-type-v q2_K --cache-reuse 65000 \
CPU满线程,速度核心
--parallel 1 --threads 10 --threads-batch 10 \
生成质量优化(不影响速度)
--temp 0.85 --top_p 0.9 --top_k 24 --repeat_penalty 1.04 \
服务/监控/模板
--metrics --jinja --seed 42 --cont-batching \
思考模式保留
--reasoning-budget 768 --reasoning on --reasoning-format deepseek \
===================== 核心优化:Hermes专属45分钟缓存保留 =====================
--max-slots 8
--slot-reclaim-timeout 2700 \
-ngl 99 -fa on
--memory-usage high
--max-batch-size 8192
--low-vram off
--no-penalty-off
--prompt-cache-full
--no-check-tensors
--log_file /tmp/fastllm-llm.log
--metrics on 目前 的情况 我在nvtop里面看 GPU线和MEM线在运行的时候完美重合,满载时,最高 温度我看似乎是47度,这个温度我挺满意 的,不过如果还能降低一些就好了。,算是吃到了 算力+显存的甜点配置,但是日志里面看速度掉落到了38TOKENS/S 这种情况下,我应该如何优化及调整参数,以获得最大的上下文 + 均衡配置呢?



 稳如泰山
稳如泰山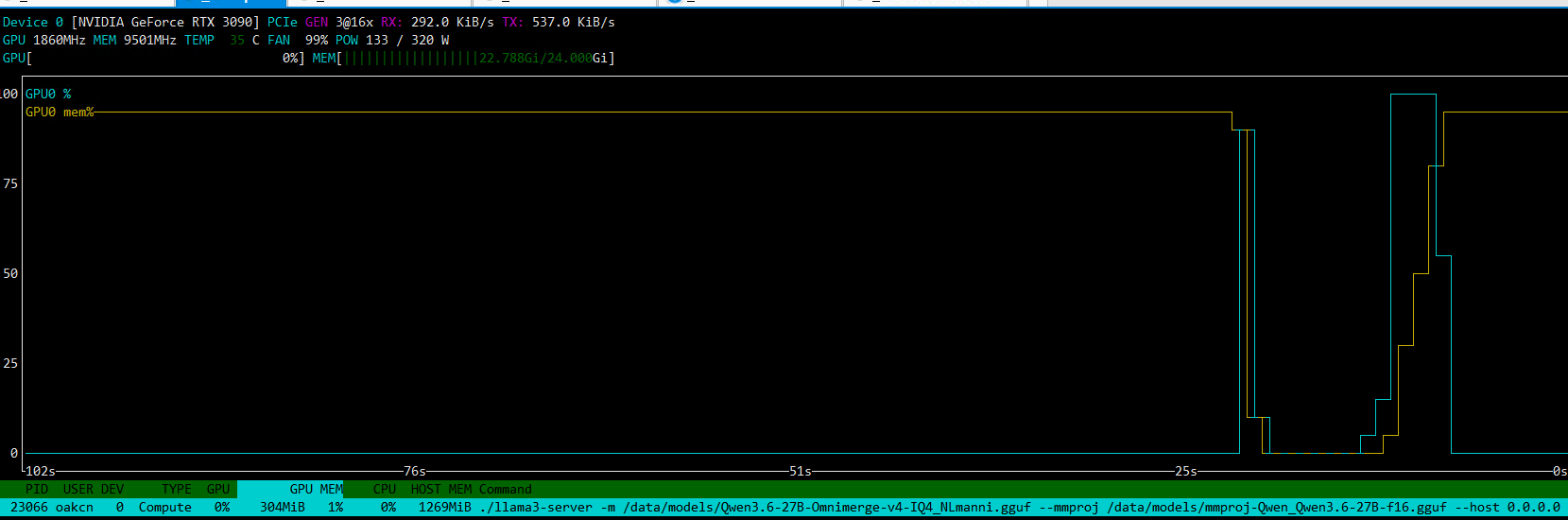
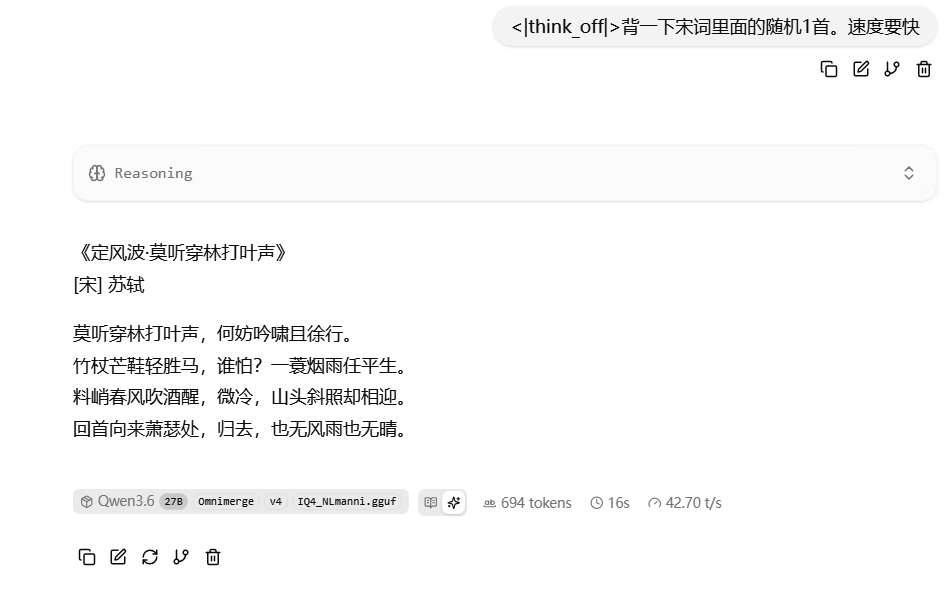
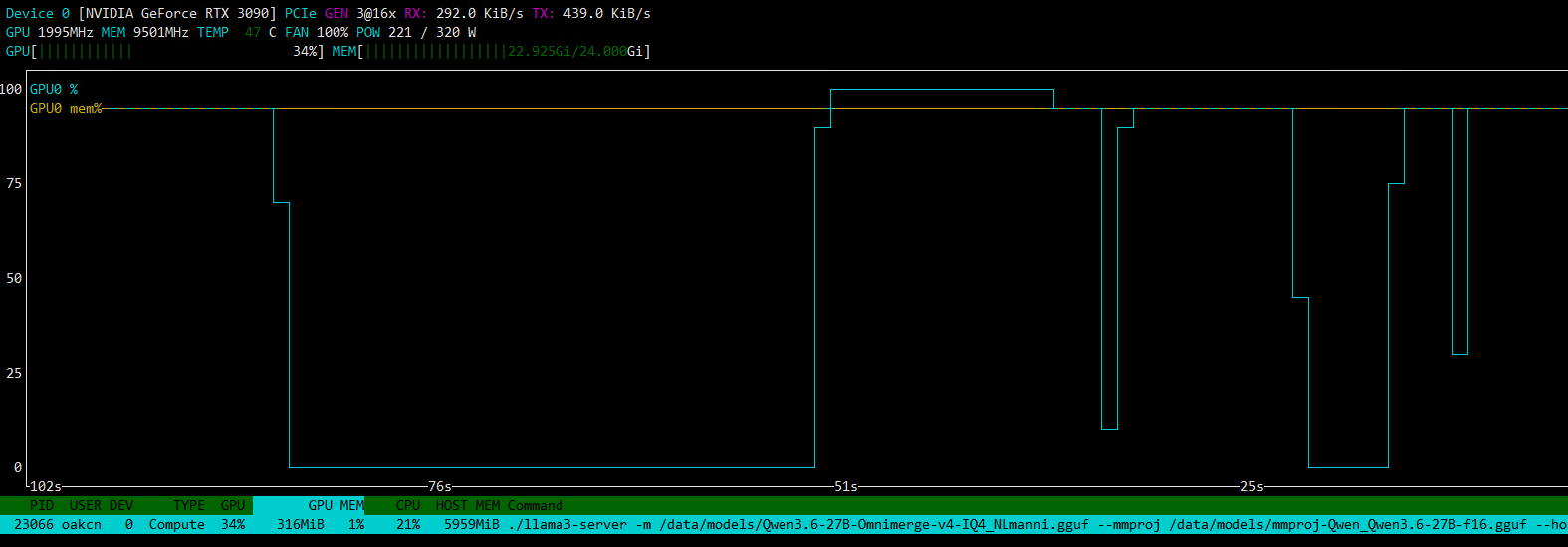
 目前看来,速度是稳的, 这里介绍一下,我用模型是
目前看来,速度是稳的, 这里介绍一下,我用模型是