大概出片时长是多少?我LTX2.3四秒480X320用了~520秒 系统32GB RAM, 加大了SWAP FILE还有加了一堆参数才不OOM
--disable-smart-memory --disable-async-offload
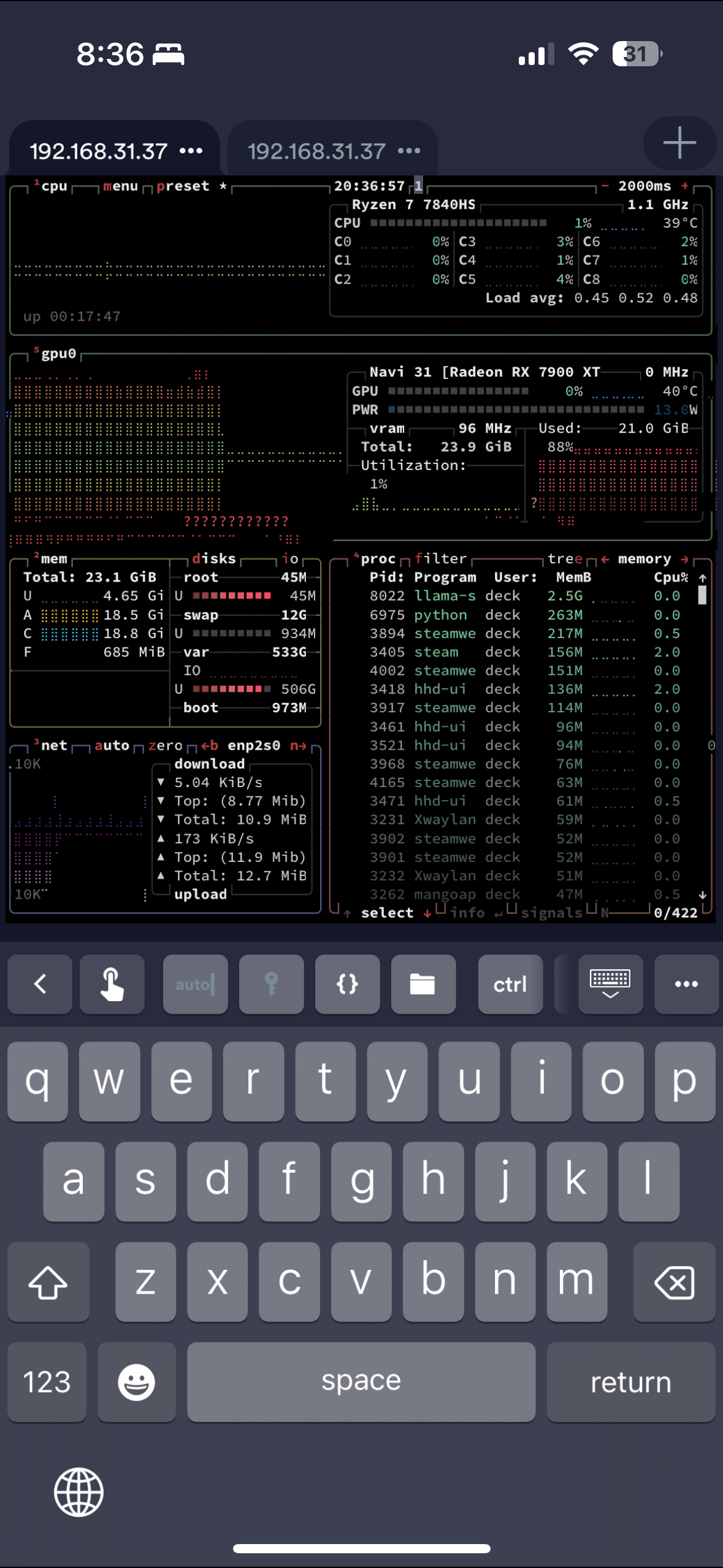
可能是eGPU + bazzite(Linux bazzite 6.17.7-ba29.fc43.x86_64) + distrobox ubuntu关系? 其他硬件软件都差不多了
大概出片时长是多少?我LTX2.3四秒480X320用了~520秒 系统32GB RAM, 加大了SWAP FILE还有加了一堆参数才不OOM
--disable-smart-memory --disable-async-offload
可能是eGPU + bazzite(Linux bazzite 6.17.7-ba29.fc43.x86_64) + distrobox ubuntu关系? 其他硬件软件都差不多了
感谢,抄了作业,重新编译一下从原来~30TPS 提升到~40TPS,后面对coding微调了一下基本上确定大概eGPU +7900xtx能编程能测试了,等装上x99-cd3会来更新一下
# 7900 XTX (TB3 eGPU) + Qwen3.6-27B llama.cpp MTP — Bench Summary
Hardware: AMD 7900 XTX via Razer Core X Chroma (TB3) + Beelink SER7
Tool: llama-benchy (Sherlock Holmes prompts, pp=512 tg=128 depth=[0, 4096])
| # | Config | tg mean | tg peak | tg @ d4096 | pp512 | Accept |
|---|-------------------------------------------------|--------:|--------:|-----------:|------:|-------:|
| 1 | Baseline (mainline, no MTP, temp=0.2) | 30.26 | 31.5 | 29.79 | 459 | n/a |
| 2 | + MTP enabled (old PR build 9117) | 35.54 | 41.0 | 29.45 | 310 | 97% |
| 3 | + Rebuilt PR to latest (9173, GDN rollback fix) | 37.25 | 45.5 | 34.70 | 353 | 57% |
| 4 | + GPU power_dpm forced to `high` | 45.00 | 54.8 | 37.94 | 351 | 57% |
| 5 | + Qwen "precise coding" sampling (current) | 37.32 | 46.8 | 31.75 | 368 | 54% |
Cumulative gain vs original baseline: **+23% TG mean, +49% TG peak**
(Step 4 alone is +49% / +74%; step 5 trades 16% speed for output quality)
## Variant comparisons (PR 9173 + perf=high)
| Variant | tg mean | tg peak | tg @ d4096 | Accept | Verdict |
|--------------------------------------------|--------:|--------:|-----------:|-------:|------------------|
| froggeric Q4_K_M MTP (default) | 45.00 | 54.8 | 37.94 | 67% | ✅ Best mean |
| unsloth Q4_K_M MTP | 36.13 | 44.0 | 34.68 | 49% | ❌ -19% TG |
| unsloth UD-Q4_K_XL MTP | 43.65 | 53.0 | 33.01 | 60% | ≈ Tied, worse @d |
| Chain: `ngram-mod,draft-mtp` (unsloth tip) | — | — | — | — | 🔴 CRASH (SSM) |
## Sampling A/B (froggeric MTP, n=2, perf=high)
| Preset | temp / top_p / top_k / pp | tg mean | Accept@0 | Note |
|-------------------------|---------------------------|--------:|---------:|---------------|
| Fast (temp=0.2) | 0.2 / — / 20 / — | 45.00 | 67% | Fastest, repetitive |
| Precise coding (active) | 0.6 / 0.95 / 20 / 0.0 | 37.32 | 54% | ★ Current default |
| Non-thinking general | 0.7 / 0.8 / 20 / 1.5 | 36.26 | 57% | Best @ long ctx |
| Thinking general | 1.0 / 0.95 / 20 / 1.5 | 37.68 | 59% | Avoid (no MTP gain) |
## Other paths evaluated and rejected
| Option | Result on 7900 XTX |
|------------------------------|----------------------------------------|
| vLLM (ROCm) | ❌ -10–20%, no Qwen3.6 MTP, 4–8h install |
| TurboQuant (Vulkan port) | ❌ Broken — 10 t/s, GPU util <30% |
| DFlash / Hipfire | ❌ Crashes >4k context, no MTP |
| MLC-LLM (Vulkan) | ⚠️ ~10 t/s slower, no MTP |
## Hardware ceiling vs realistic upgrades
| Setup | Expected tg mean |
|--------------------------------------------------|-----------------:|
| Current (TB3 eGPU, all sw optimizations) | 37–45 |
| OCuLink mod to Core X Chroma (~$80, 3h) | 52–55 |
| Move GPU to X99 desktop (PCIe 3.0 x16) | 58–62 |
| Modern AM5 + PCIe 4.0 x16 (blog reference) | 67 |
**Current `start_server start`:** llama.cpp PR 9173 + froggeric MTP Q4_K_M + `--spec-type draft-mtp --spec-draft-n-max 2` + KV q4_0 + FA on + Qwen precise coding sampling + GPU perf=high.
llama-benchy result:
cd /var/home/deck/tmp/llama-benchy
uv run llama-benchy \
--base-url http://127.0.0.1:8081/v1 \
--model froggeric/Qwen3.6-27B-MTP-GGUF \
--served-model-name Qwen3.6-27B-Q4_K_M-mtp.gguf \
--tokenizer Qwen/Qwen3.6-27B \
--pp 2048 --tg 32 \
--depth 0 8192 32768 \
--runs 1 --no-cache --latency-mode generation --skip-coherence \
--save-result results/qwen36-27b-mtp-8081-sample-20260513.json --format json
Results:
| context depth | pp t/s | tg t/s | peak tg t/s | TTFR | est PPT |
|---|---:|---:|---:|---:|---:|
| 0 | 457.92 | 29.75 | 30.0 | 4693 ms | 4477 ms |
| 8192 | 432.96 | 28.24 | 29.0 | 23870 ms | 23654 ms |
| 32768 | 329.57 | 25.24 | 27.0 | 105856 ms | 105640 ms |
.venv/bin/llama-benchy \
--base-url http://127.0.0.1:8081/v1 \
--model Qwen/Qwen3.6-27B \
--served-model-name Qwen_Qwen3.6-27B-Q4_K_M.gguf \
--tokenizer Qwen/Qwen3.6-27B \
--pp 2048 \
--tg 32 \
--depth 0 8192 32768 \
--runs 1 \
--latency-mode generation \
--save-result results/qwen36-27b-original-8081-20260513T235739Z.json \
--format json
Results:
| depth | pp t/s | tg t/s | TTFR ms |
|---|---:|---:|---:|
| 0 | 685.49 | 30.63 | 3190.39 |
| 8192 | 640.61 | 30.00 | 16184.55 |
| 32768 | 486.52 | 28.16 | 71766.55 |
llama.cpp server config:
#MODEL="/run/media/deck/ExternalSSD/.llama.cpp/models/froggeric_Qwen3.6-27B-MTP-GGUF/Qwen3.6-27B-Q4_K_M-mtp.gguf"
MODEL="/var/run/media/deck/ExternalSSD/.llama.cpp/models/Qwen_Qwen3.6-27B-GGUF/Qwen_Qwen3.6-27B-Q4_K_M.gguf"
# cd "/var/home/deck/tmp/llama-pr-22673-mtp-clean/build-vulkan-pr22673/bin"
cd "/var/home/deck/code/llama.cpp/build-vulkan/bin"
export VK_LOADER_LAYERS_DISABLE=VK_LAYER_LS_frame_generation
exec ./llama-server \
-m "$MODEL" \
-ngl 99 \
-dev Vulkan0 \
-fa on \
-c 200000 \
-ctk q4_0 \
-ctv q4_0 \
-ub 256 \
--temp 0.2 \
--top-k 20 \
--parallel 1 \
-rea off \
--reasoning-budget 0 \
--host "$HOST" \
--port "$PORT"
# MTP flags:
# --spec-type mtp
# --spec-draft-n-max 2
昨天测了一天感觉MTP打开没有变化(~30tok/s),用了几轮就会爆VRAM, 希望指正哪里出问题了。
我是用beelink ser7 + eGPU 7900xtx + bazzite + hermes agent + discrod
现在基本可以游戏/LLM随时切换, eGPU坑还是很多, 在等x99主板到装机
eGPU坑:
用all-ways-egpu可以点亮显卡+游戏
Kfd/ROCm没发使用,试了setup时不去设置iGPU kfd就能用了,但是bazzite不能进game mode了,还在找最后解决方案
Update:
confirm disable iGPU from bios, I can use ROCm and Bazzite able to boot into game mode