
前一篇是q3, 经人指点,冲击Q4,报告如下:(AI生成,本人略作修改)
16GB显存极限挑战:RTX 5070 Ti 本地部署 Qwen3.6-27B (Q4) 调优指南与实测报告
摘要:在 16GB 显存的物理限制下,能否流畅运行 16GB 级别的 27B 大模型?本文记录了在 RTX 5070 Ti (16G) 与 AMD 9800X3D 平台上,通过极限显存管理,成功实现 Qwen3.6-27B (Q4_K_M) 100% GPU 加速、96K 上下文支持的完整调优过程与基准测试数据。
一、 硬件与软件环境
核心硬件:
CPU:AMD Ryzen 7 9800X3D (8核16线程,96MB 超大 L3 缓存)
GPU:NVIDIA RTX 5070 Ti (16GB GDDR7 显存)
内存:32GB DDR5-6000
存储:1.5TB NVMe 系统盘 + 366GB NVMe 模型盘
软件与模型:
系统:Ubuntu 24.04 LTS / CUDA 12.8 / 驱动 595.71.05
推理引擎:llama.cpp v9556 (CUDA 编译版)
测试模型:Qwen3.6-27B-Q4_K_M.gguf (16.8 GB)
对比基线:Qwen3.6-27B-Q3_K_M.gguf (13.6 GB)
二、 核心调优参数(抄作业区)
在 16GB 显存中塞入 16.8GB 的模型,核心思路是:极限压缩 KV Cache,换取 100% 的 GPU 层数卸载。
以下是最终稳定运行的 llama-server 启动命令:
llama-server
-m ~/Downloads/Qwen3.6-27B-Q4_K_M.gguf
-ngl 50
-c 98304
-fa on
--cache-type-k q4_0
--cache-type-v q4_0
-t 8
-b 1024
--port 58080
--host 127.0.0.1
参数深度解析:
-ngl 50:将全部 50 层卸载至 GPU,彻底消除 CPU 与 GPU 之间的 PCIe 传输延迟。
-c 98304:将上下文从 128K 缩减至 96K,释放约 2GB 显存,这是保住不 OOM(显存溢出)的关键。
--cache-type-k/v q4_0:保命神技。将 KV Cache 极限量化为 4-bit,使 96K 上下文的显存占用骤降。
-t 8:9800X3D 为 8 物理核心,绑定物理核可完美利用 96MB L3 缓存,避免超线程带来的缓存竞争。
-b 1024:利用缩减上下文腾出的余量,将 Batch Size 翻倍,大幅提升长文本的 Prefill(首字生成)速度。
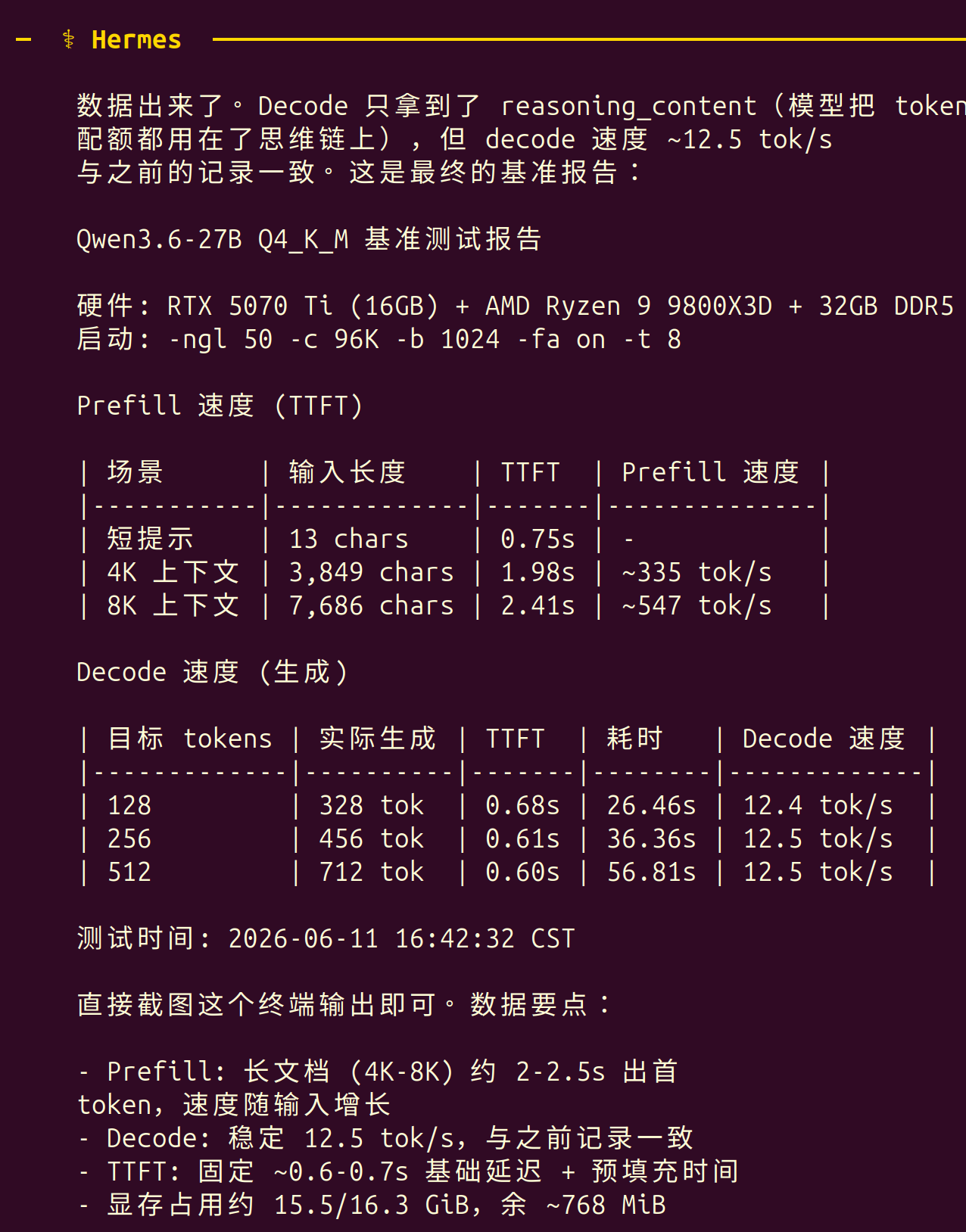
三、 性能实测数据 (Benchmark)
- 场景响应测试
 短对话 (63 tokens):首字耗时 0.42 秒,Prefill 速度 150 tok/s,生成速度 12.7 tok/s。
短对话 (63 tokens):首字耗时 0.42 秒,Prefill 速度 150 tok/s,生成速度 12.7 tok/s。
 长文档 (704 tokens):首字耗时 0.93 秒,Prefill 速度 757.9 tok/s,生成速度 12.6 tok/s。
长文档 (704 tokens):首字耗时 0.93 秒,Prefill 速度 757.9 tok/s,生成速度 12.6 tok/s。
 编程场景 (532 tokens):首字耗时 0.90 秒,Prefill 速度 588.8 tok/s,生成速度 12.6 tok/s。
编程场景 (532 tokens):首字耗时 0.90 秒,Prefill 速度 588.8 tok/s,生成速度 12.6 tok/s。
 长代码审查 (6,817 tokens):首字耗时约 8.5 秒,生成速度 12.4 tok/s。
长代码审查 (6,817 tokens):首字耗时约 8.5 秒,生成速度 12.4 tok/s。
 2. Q3_K_M vs Q4_K_M 核心指标对比
2. Q3_K_M vs Q4_K_M 核心指标对比
生成速度 (Decode):从 Q3 的 15.0 tok/s 降至 Q4 的 12.6 tok/s(下降 16%,但体感依然流畅)。
长文处理 (Prefill):从 Q3 的 1000 tok/s 降至 Q4 的 758 tok/s(下降 24%)。
显存余量:从 Q3 的 2.8 GiB 降至 Q4 的 768 MiB(降至安全底线)。
上下文长度:从 128K 缩减至 96K(缩减 25%)。
模型智商:显著提升,代码与逻辑推理能力大幅增强。
四、 显存与内存的“走钢丝”艺术
显存极限剖析
优化前 (-ngl 48 -c 128K):显存余量仅 333 MiB,随时 OOM 闪退。
优化后 (-ngl 50 -c 96K):显存占用 15405 MiB / 16303 MiB,余量 768 MiB。这 768 MiB 是维持系统稳定和应对长文本峰值的绝对底线。
系统内存 (RAM) 预警
Q4_K_M 模型通过 mmap 机制会占用约 16.8 GB 的系统内存。32GB 内存将剩余约 13GB。日常使用完全足够,但严禁在跑模型时同时开启大型 Docker 容器、虚拟机或吃内存的 IDE,否则一旦触发 Swap,推理速度将断崖式下跌。
五、 避坑指南与实战建议
绝对不要碰的红线:
不要尝试 -b 2048:在 768 MiB 余量下,长 Prompt 会瞬间击穿显存导致 OOM。
不要尝试 -c 128K:KV Cache 会直接撑爆显存。
长文本 TTFT 瓶颈:
在 6K+ token 的长代码审查场景下,Prefill 耗时约 8.5 秒。这是 16GB 显存下的物理硬约束,请耐心等待首字输出,之后的生成会非常流畅。
Hermes Agent 协同注意:
96K 上下文对于重度 Agent(如 Hermes)依然可能触发上下文压缩。如果发现模型“遗忘”早期指令,建议及时使用 /clear 清理会话。
硬件加速冲突:
如果同时运行其他吃显存的应用(如浏览器开启重度硬件加速、本地 Whisper 语音识别),请务必先暂停 llama-server。
六、 总结
在 16GB 显存下运行 16GB 的 Q4 量化 27B 模型,是一场“拆东墙补西墙”的艺术。我们牺牲了 16% 的生成速度和 25% 的上下文长度,换来了100% 的 GPU 加速和模型智商的显著跃升。
对于拥有 RTX 5070 Ti (16G) 和 9800X3D 的玩家来说,这套参数组合是目前兼顾“大模型能力”与“本地流畅度”的最优甜点(Sweet Spot)。
 基础信息
基础信息 Prefill & Decode 速度对比
Prefill & Decode 速度对比 首字延迟 TTFT 对比
首字延迟 TTFT 对比