
硬件配置
- 处理:Ryzen Threadripper 3970X
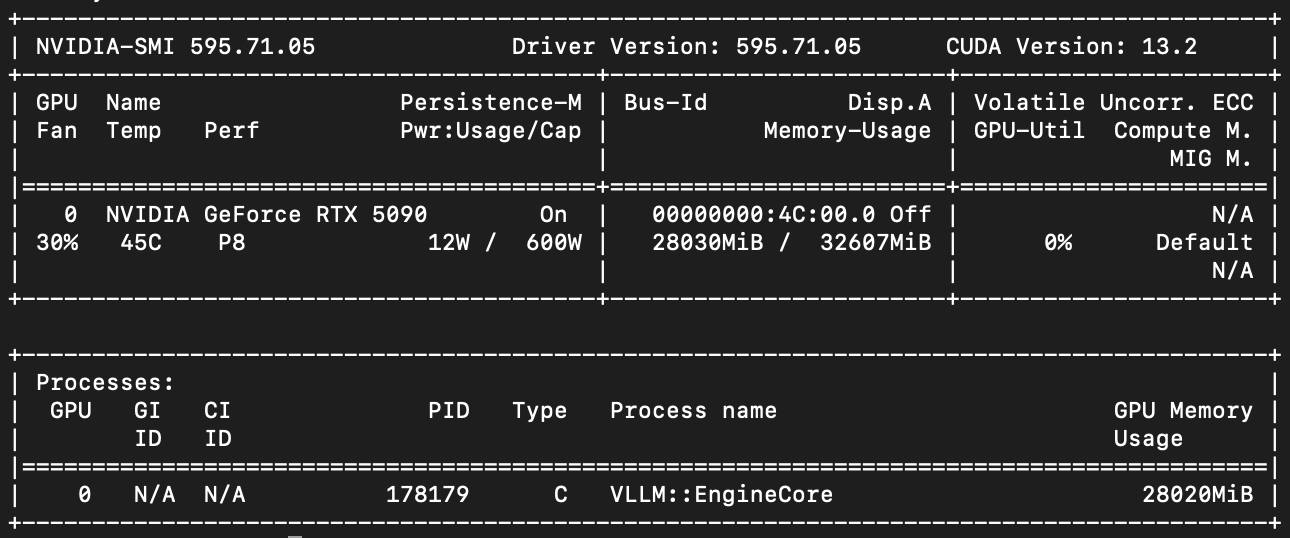
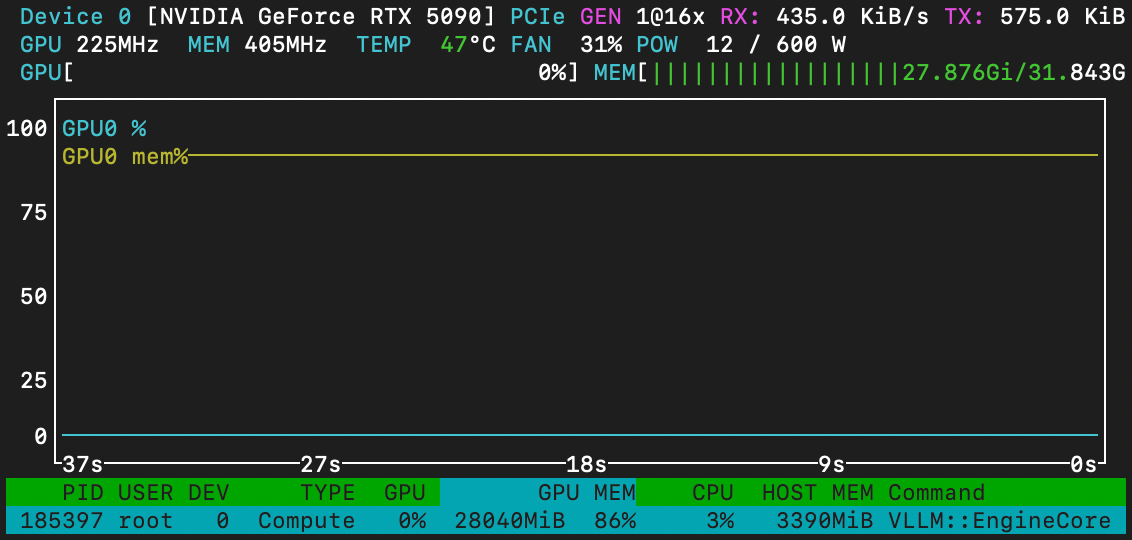
- 显卡:RTX5090 32GB
- 内存:DDR4-3200 32GB x 8
软件配置
- 系统:Ubuntu 24.04 LTS
- 推理:vLLM v0.21.0(Docker)
- 驱动:v595.71.05|CUDA v13.2
- 模型一:自制/Qwen3.6-27B-Heretic-W4G128(Refusal:6/100)
- 模型二:Lorbus/Qwen3.6-27B-int4-AutoRound
启动指令及参数
docker run --gpus all \
--ipc=host \
-v /fast_pool/models:/models \
-p 8000:8000 \
-e PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True,max_split_size_mb:512 \
vllm/vllm-openai:latest \
--model /models/Qwen3.6-27B-Heretic-w4g128 \
--quantization auto_round \
--dtype bfloat16 \
--max-model-len 196608 \
--kv-cache-dtype fp8 \
--gpu-memory-utilization 0.9 \
--max-num-seqs 1 \
--enable-prefix-caching \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser qwen3 \
--default-chat-template-kwargs '{"enable_thinking": false}' \
--safetensors-load-strategy prefetch \
--trust-remote-code \
--host 0.0.0.0 \
--port 8000
Benchmark测试
============================================================
Qwen3.6-27B Heretic W4G128 — Benchmark
3 run × 1024 output tokens
============================================================
Run 1/3... ✓ TTFT=281ms TPS=43.5 (522 token)
Run 2/3... ✓ TTFT=69ms TPS=43.4 (522 token)
Run 3/3... ✓ TTFT=69ms TPS=43.4 (522 token)
Run TTFT (ms) TPOT (ms) TPS Token Total (s)
──── ────────── ────────── ──────── ─────── ──────────
1 280.78 23.00 43.47 522 12.29
2 68.85 23.02 43.45 522 12.08
3 68.82 23.02 43.43 522 12.09
AVG 139.48 23.01 43.45 ─ ─
平均43.5t/s,比之前我在log看到的86t/s低很多。原因可能是benchmark.py只生成了522token,没到1023,而且这是纯文字短回答,prefix cache没热身。注意TTFT第一次281ms,第二次69ms,prefix cache命中后快了4倍~TPOT 23.01ms,每个token约23ms。
WARNING 05-24 08:23:58 [argparse_utils.py:257] With `vllm serve`, you should provide the model as a positional argument or in a config file instead of via the `--model` option. The `--model` option will be removed in a future version.
(APIServer pid=1) INFO 05-24 08:23:58 [utils.py:306]
(APIServer pid=1) INFO 05-24 08:23:58 [utils.py:306] █ █ █▄ ▄█
(APIServer pid=1) INFO 05-24 08:23:58 [utils.py:306] ▄▄ ▄█ █ █ █ ▀▄▀ █ version 0.21.0
(APIServer pid=1) INFO 05-24 08:23:58 [utils.py:306] █▄█▀ █ █ █ █ model /models/Qwen3.6-27B-Heretic-w4g128
(APIServer pid=1) INFO 05-24 08:23:58 [utils.py:306] ▀▀ ▀▀▀▀▀ ▀▀▀▀▀ ▀ ▀
(APIServer pid=1) INFO 05-24 08:23:58 [utils.py:306]
(APIServer pid=1) INFO 05-24 08:23:58 [utils.py:240] non-default args: {'model_tag': '/models/Qwen3.6-27B-Heretic-w4g128', 'default_chat_template_kwargs': {'enable_thinking': False}, 'enable_auto_tool_choice': True, 'tool_call_parser': 'qwen3_coder', 'host': '0.0.0.0', 'model': '/models/Qwen3.6-27B-Heretic-w4g128', 'trust_remote_code': True, 'dtype': 'bfloat16', 'max_model_len': 196608, 'quantization': 'auto_round', 'safetensors_load_strategy': 'prefetch', 'reasoning_parser': 'qwen3', 'gpu_memory_utilization': 0.9, 'kv_cache_dtype': 'fp8', 'enable_prefix_caching': True, 'max_num_seqs': 1}
(APIServer pid=1) WARNING 05-24 08:23:58 [envs.py:1866] Unknown vLLM environment variable detected: VLLM_BUILD_COMMIT
(APIServer pid=1) WARNING 05-24 08:23:58 [envs.py:1866] Unknown vLLM environment variable detected: VLLM_BUILD_PIPELINE
(APIServer pid=1) WARNING 05-24 08:23:58 [envs.py:1866] Unknown vLLM environment variable detected: VLLM_BUILD_URL
(APIServer pid=1) WARNING 05-24 08:23:58 [envs.py:1866] Unknown vLLM environment variable detected: VLLM_IMAGE_TAG
(APIServer pid=1) INFO 05-24 08:24:09 [model.py:568] Resolved architecture: Qwen3_5ForConditionalGeneration
(APIServer pid=1) INFO 05-24 08:24:09 [model.py:1697] Using max model len 196608
(APIServer pid=1) INFO 05-24 08:24:10 [cache.py:261] Using fp8 data type to store kv cache. It reduces the GPU memory footprint and boosts the performance. Meanwhile, it may cause accuracy drop without a proper scaling factor
(APIServer pid=1) WARNING 05-24 08:24:10 [config.py:367] Mamba cache mode is set to 'align' for Qwen3_5ForConditionalGeneration by default when prefix caching is enabled
(APIServer pid=1) INFO 05-24 08:24:10 [config.py:387] Warning: Prefix caching in Mamba cache 'align' mode is currently enabled. Its support for Mamba layers is experimental. Please report any issues you may observe.
(APIServer pid=1) INFO 05-24 08:24:10 [vllm.py:886] Asynchronous scheduling is enabled.
(APIServer pid=1) INFO 05-24 08:24:10 [kernel.py:212] Final IR op priority after setting platform defaults: IrOpPriorityConfig(rms_norm=['native'], fused_add_rms_norm=['native'])
(APIServer pid=1) [transformers] `Qwen2VLImageProcessorFast` is deprecated. The `Fast` suffix for image processors has been removed; use `Qwen2VLImageProcessor` instead.
(APIServer pid=1) [transformers] The `use_fast` parameter is deprecated and will be removed in a future version. Use `backend="torchvision"` instead of `use_fast=True`, or `backend="pil"` instead of `use_fast=False`.
(EngineCore pid=392) INFO 05-24 08:24:26 [core.py:109] Initializing a V1 LLM engine (v0.21.0) with config: model='/models/Qwen3.6-27B-Heretic-w4g128', speculative_config=None, tokenizer='/models/Qwen3.6-27B-Heretic-w4g128', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=True, dtype=torch.bfloat16, max_seq_len=196608, download_dir=None, load_format=auto, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, decode_context_parallel_size=1, dcp_comm_backend=ag_rs, disable_custom_all_reduce=False, quantization=inc, quantization_config=None, enforce_eager=False, enable_return_routed_experts=False, kv_cache_dtype=fp8, device_config=cuda, structured_outputs_config=StructuredOutputsConfig(backend='auto', disable_any_whitespace=False, disable_additional_properties=False, reasoning_parser='qwen3', reasoning_parser_plugin='', enable_in_reasoning=False), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None, kv_cache_metrics=False, kv_cache_metrics_sample=0.01, cudagraph_metrics=False, enable_layerwise_nvtx_tracing=False, enable_mfu_metrics=False, enable_mm_processor_stats=False, enable_logging_iteration_details=False), seed=0, served_model_name=/models/Qwen3.6-27B-Heretic-w4g128, enable_prefix_caching=True, enable_chunked_prefill=True, pooler_config=None, compilation_config={'mode': <CompilationMode.VLLM_COMPILE: 3>, 'debug_dump_path': None, 'cache_dir': '', 'compile_cache_save_format': 'binary', 'backend': 'inductor', 'custom_ops': ['none'], 'ir_enable_torch_wrap': True, 'splitting_ops': ['vllm::unified_attention_with_output', 'vllm::unified_mla_attention_with_output', 'vllm::mamba_mixer2', 'vllm::mamba_mixer', 'vllm::short_conv', 'vllm::linear_attention', 'vllm::plamo2_mamba_mixer', 'vllm::gdn_attention_core', 'vllm::gdn_attention_core_xpu', 'vllm::olmo_hybrid_gdn_full_forward', 'vllm::kda_attention', 'vllm::sparse_attn_indexer', 'vllm::rocm_aiter_sparse_attn_indexer', 'vllm::deepseek_v4_attention', 'vllm::unified_kv_cache_update', 'vllm::unified_mla_kv_cache_update'], 'compile_mm_encoder': False, 'cudagraph_mm_encoder': False, 'encoder_cudagraph_token_budgets': [], 'encoder_cudagraph_max_vision_items_per_batch': 0, 'encoder_cudagraph_max_frames_per_batch': None, 'compile_sizes': [], 'compile_ranges_endpoints': [2048], 'inductor_compile_config': {'enable_auto_functionalized_v2': False, 'size_asserts': False, 'alignment_asserts': False, 'scalar_asserts': False, 'combo_kernels': True, 'benchmark_combo_kernel': True}, 'inductor_passes': {}, 'cudagraph_mode': <CUDAGraphMode.FULL_AND_PIECEWISE: (2, 1)>, 'cudagraph_num_of_warmups': 1, 'cudagraph_capture_sizes': [1, 2], 'cudagraph_copy_inputs': False, 'cudagraph_specialize_lora': True, 'use_inductor_graph_partition': False, 'pass_config': {'fuse_norm_quant': False, 'fuse_act_quant': False, 'fuse_attn_quant': False, 'enable_sp': False, 'fuse_gemm_comms': False, 'fuse_allreduce_rms': False, 'fuse_act_padding': False}, 'max_cudagraph_capture_size': 2, 'dynamic_shapes_config': {'type': <DynamicShapesType.BACKED: 'backed'>, 'evaluate_guards': False, 'assume_32_bit_indexing': False}, 'local_cache_dir': None, 'fast_moe_cold_start': False, 'static_all_moe_layers': []}, kernel_config=KernelConfig(ir_op_priority=IrOpPriorityConfig(rms_norm=['native'], fused_add_rms_norm=['native']), enable_flashinfer_autotune=False, moe_backend='auto')
(EngineCore pid=392) [transformers] `Qwen2VLImageProcessorFast` is deprecated. The `Fast` suffix for image processors has been removed; use `Qwen2VLImageProcessor` instead.
(EngineCore pid=392) INFO 05-24 08:24:29 [parallel_state.py:1410] world_size=1 rank=0 local_rank=0 distributed_init_method=tcp://172.17.0.3:51473 backend=nccl
(EngineCore pid=392) INFO 05-24 08:24:29 [parallel_state.py:1723] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, PCP rank 0, TP rank 0, EP rank N/A, EPLB rank N/A
(EngineCore pid=392) INFO 05-24 08:24:29 [topk_topp_sampler.py:45] Using FlashInfer for top-p & top-k sampling.
(EngineCore pid=392) [transformers] The `use_fast` parameter is deprecated and will be removed in a future version. Use `backend="torchvision"` instead of `use_fast=True`, or `backend="pil"` instead of `use_fast=False`.
(EngineCore pid=392) INFO 05-24 08:24:36 [gpu_model_runner.py:4857] Starting to load model /models/Qwen3.6-27B-Heretic-w4g128...
(EngineCore pid=392) INFO 05-24 08:24:36 [cuda.py:427] Using backend AttentionBackendEnum.FLASH_ATTN for vit attention
(EngineCore pid=392) INFO 05-24 08:24:36 [mm_encoder_attention.py:372] Using AttentionBackendEnum.FLASH_ATTN for MMEncoderAttention.
(EngineCore pid=392) INFO 05-24 08:24:36 [gptq_marlin.py:387] Using MarlinLinearKernel for GPTQMarlinLinearMethod
(EngineCore pid=392) INFO 05-24 08:24:36 [gdn_linear_attn.py:169] Using Triton/FLA GDN prefill kernel
(EngineCore pid=392) INFO 05-24 08:24:36 [cuda.py:372] Using FLASHINFER attention backend out of potential backends: ['FLASHINFER', 'TRITON_ATTN'].
(EngineCore pid=392) INFO 05-24 08:24:37 [weight_utils.py:938] Filesystem type for checkpoints: ZFS. Checkpoint size: 17.41 GiB. Available RAM: 192.24 GiB.
(EngineCore pid=392) INFO 05-24 08:24:37 [weight_utils.py:900] Prefetching checkpoint files into page cache started (in background, num_threads=8, block_size=16777216 bytes)
Loading safetensors checkpoint shards: 0% Completed | 0/10 [00:00<?, ?it/s]
(EngineCore pid=392) INFO 05-24 08:24:37 [weight_utils.py:872] Prefetching checkpoint files: 10% (1/10)
(EngineCore pid=392) INFO 05-24 08:24:37 [weight_utils.py:872] Prefetching checkpoint files: 20% (2/10)
Loading safetensors checkpoint shards: 10% Completed | 1/10 [00:00<00:05, 1.74it/s]
(EngineCore pid=392) INFO 05-24 08:24:37 [weight_utils.py:872] Prefetching checkpoint files: 30% (3/10)
(EngineCore pid=392) INFO 05-24 08:24:37 [weight_utils.py:872] Prefetching checkpoint files: 40% (4/10)
(EngineCore pid=392) INFO 05-24 08:24:37 [weight_utils.py:872] Prefetching checkpoint files: 50% (5/10)
(EngineCore pid=392) INFO 05-24 08:24:37 [weight_utils.py:872] Prefetching checkpoint files: 60% (6/10)
(EngineCore pid=392) INFO 05-24 08:24:37 [weight_utils.py:872] Prefetching checkpoint files: 70% (7/10)
(EngineCore pid=392) INFO 05-24 08:24:37 [weight_utils.py:872] Prefetching checkpoint files: 80% (8/10)
(EngineCore pid=392) INFO 05-24 08:24:37 [weight_utils.py:872] Prefetching checkpoint files: 90% (9/10)
(EngineCore pid=392) INFO 05-24 08:24:38 [weight_utils.py:872] Prefetching checkpoint files: 100% (10/10)
(EngineCore pid=392) INFO 05-24 08:24:38 [weight_utils.py:895] Prefetching checkpoint files into page cache finished in 0.97s
Loading safetensors checkpoint shards: 20% Completed | 2/10 [00:01<00:04, 1.99it/s]
Loading safetensors checkpoint shards: 30% Completed | 3/10 [00:01<00:03, 2.24it/s]
Loading safetensors checkpoint shards: 40% Completed | 4/10 [00:01<00:02, 2.39it/s]
Loading safetensors checkpoint shards: 50% Completed | 5/10 [00:02<00:02, 2.49it/s]
Loading safetensors checkpoint shards: 60% Completed | 6/10 [00:02<00:01, 2.55it/s]
Loading safetensors checkpoint shards: 70% Completed | 7/10 [00:02<00:00, 3.04it/s]
Loading safetensors checkpoint shards: 80% Completed | 8/10 [00:03<00:00, 3.09it/s]
Loading safetensors checkpoint shards: 100% Completed | 10/10 [00:03<00:00, 3.88it/s]
Loading safetensors checkpoint shards: 100% Completed | 10/10 [00:03<00:00, 2.93it/s]
(EngineCore pid=392)
(EngineCore pid=392) INFO 05-24 08:24:40 [default_loader.py:397] Loading weights took 3.50 seconds
(EngineCore pid=392) INFO 05-24 08:24:41 [gpu_model_runner.py:4959] Model loading took 17.45 GiB memory and 4.497936 seconds
(EngineCore pid=392) INFO 05-24 08:24:41 [interface.py:645] Setting attention block size to 1568 tokens to ensure that attention page size is >= mamba page size.
(EngineCore pid=392) INFO 05-24 08:24:41 [interface.py:669] Padding mamba page size by 0.13% to ensure that mamba page size and attention page size are exactly equal.
(EngineCore pid=392) INFO 05-24 08:24:41 [gpu_model_runner.py:5920] Encoder cache will be initialized with a budget of 16384 tokens, and profiled with 1 image items of the maximum feature size.
(EngineCore pid=392) INFO 05-24 08:25:04 [backends.py:1089] Using cache directory: /root/.cache/vllm/torch_compile_cache/537a496283/rank_0_0/backbone for vLLM's torch.compile
(EngineCore pid=392) INFO 05-24 08:25:04 [backends.py:1148] Dynamo bytecode transform time: 11.73 s
(EngineCore pid=392) INFO 05-24 08:25:07 [backends.py:378] Cache the graph of compile range (1, 2048) for later use
(EngineCore pid=392) INFO 05-24 08:25:34 [backends.py:393] Compiling a graph for compile range (1, 2048) takes 28.64 s
(EngineCore pid=392) INFO 05-24 08:25:41 [decorators.py:708] saved AOT compiled function to /root/.cache/vllm/torch_compile_cache/torch_aot_compile/39e231811ba95356ca3efb314dd32a14ee616beee18711c360c6ceba7a22119d/rank_0_0/model
(EngineCore pid=392) INFO 05-24 08:25:41 [monitor.py:53] torch.compile took 48.44 s in total
(EngineCore pid=392) INFO 05-24 08:26:58 [monitor.py:81] Initial profiling/warmup run took 76.56 s
(EngineCore pid=392) INFO 05-24 08:26:58 [gpu_model_runner.py:6063] Profiling CUDA graph memory: PIECEWISE=2 (largest=2), FULL=1 (largest=1)
(EngineCore pid=392) INFO 05-24 08:27:01 [gpu_model_runner.py:6142] Estimated CUDA graph memory: 0.40 GiB total
(EngineCore pid=392) INFO 05-24 08:27:01 [gpu_worker.py:462] Available KV cache memory: 8.27 GiB
(EngineCore pid=392) INFO 05-24 08:27:01 [gpu_worker.py:477] CUDA graph memory profiling is enabled (default since v0.21.0). The current --gpu-memory-utilization=0.9000 is equivalent to --gpu-memory-utilization=0.8872 without CUDA graph memory profiling. To maintain the same effective KV cache size as before, increase --gpu-memory-utilization to 0.9128. To disable, set VLLM_MEMORY_PROFILER_ESTIMATE_CUDAGRAPHS=0.
(EngineCore pid=392) INFO 05-24 08:27:01 [kv_cache_utils.py:1710] GPU KV cache size: 256,186 tokens
(EngineCore pid=392) INFO 05-24 08:27:01 [kv_cache_utils.py:1711] Maximum concurrency for 196,608 tokens per request: 1.30x
(EngineCore pid=392) INFO 05-24 08:27:01 [kernel_warmup.py:44] Skipping FlashInfer autotune because it is disabled.
Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 100%|██████████| 2/2 [00:00<00:00, 20.00it/s]
Capturing CUDA graphs (decode, FULL): 100%|██████████| 1/1 [00:00<00:00, 5.15it/s]
(EngineCore pid=392) INFO 05-24 08:27:02 [gpu_model_runner.py:6243] Graph capturing finished in 1 secs, took 0.43 GiB
(EngineCore pid=392) INFO 05-24 08:27:02 [gpu_worker.py:621] CUDA graph pool memory: 0.43 GiB (actual), 0.4 GiB (estimated), difference: 0.03 GiB (7.2%).
(EngineCore pid=392) INFO 05-24 08:27:02 [jit_monitor.py:54] Kernel JIT monitor activated — Triton JIT compilations during inference will be logged as warnings.
(EngineCore pid=392) INFO 05-24 08:27:02 [core.py:299] init engine (profile, create kv cache, warmup model) took 141.51 s (compilation: 48.44 s)
(EngineCore pid=392) INFO 05-24 08:27:03 [vllm.py:886] Asynchronous scheduling is enabled.
(EngineCore pid=392) INFO 05-24 08:27:03 [kernel.py:212] Final IR op priority after setting platform defaults: IrOpPriorityConfig(rms_norm=['native'], fused_add_rms_norm=['native'])
(APIServer pid=1) INFO 05-24 08:27:03 [api_server.py:613] Supported tasks: ['generate']
(APIServer pid=1) INFO 05-24 08:27:03 [parser_manager.py:202] "auto" tool choice has been enabled.
(APIServer pid=1) WARNING 05-24 08:27:03 [model.py:1454] Default vLLM sampling parameters have been overridden by the model's `generation_config.json`: `{'temperature': 1.0, 'top_k': 20, 'top_p': 0.95}`. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
(APIServer pid=1) INFO 05-24 08:27:04 [hf.py:483] Detected the chat template content format to be 'string'. You can set `--chat-template-content-format` to override this.
(APIServer pid=1) INFO 05-24 08:27:19 [base.py:224] Multi-modal warmup completed in 14.396s
(APIServer pid=1) INFO 05-24 08:27:19 [base.py:224] Readonly multi-modal warmup completed in 0.556s
(APIServer pid=1) INFO 05-24 08:27:19 [api_server.py:617] Starting vLLM server on http://0.0.0.0:8000
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:37] Available routes are:
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /openapi.json, Methods: HEAD, GET
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /docs, Methods: HEAD, GET
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /docs/oauth2-redirect, Methods: HEAD, GET
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /redoc, Methods: HEAD, GET
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /tokenize, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /detokenize, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /load, Methods: GET
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /version, Methods: GET
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /health, Methods: GET
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /metrics, Methods: GET
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /v1/models, Methods: GET
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /ping, Methods: GET
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /ping, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /invocations, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /v1/chat/completions, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /v1/chat/completions/batch, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /v1/responses, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /v1/responses/{response_id}, Methods: GET
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /v1/responses/{response_id}/cancel, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /v1/completions, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /v1/messages, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /v1/messages/count_tokens, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /inference/v1/generate, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /scale_elastic_ep, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /is_scaling_elastic_ep, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /generative_scoring, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /v1/chat/completions/render, Methods: POST
(APIServer pid=1) INFO 05-24 08:27:19 [launcher.py:46] Route: /v1/completions/render, Methods: POST
(APIServer pid=1) INFO: Started server process [1]
(APIServer pid=1) INFO: Waiting for application startup.
(APIServer pid=1) INFO: Application startup complete.
(EngineCore pid=392) WARNING 05-24 08:29:10 [jit_monitor.py:103] Triton kernel JIT compilation during inference: _zero_kv_blocks_kernel. This causes a latency spike; consider extending warmup to cover this shape/config.
(EngineCore pid=392) WARNING 05-24 08:29:10 [jit_monitor.py:103] Triton kernel JIT compilation during inference: _compute_slot_mapping_kernel. This causes a latency spike; consider extending warmup to cover this shape/config.
(EngineCore pid=392) WARNING 05-24 08:29:11 [jit_monitor.py:103] Triton kernel JIT compilation during inference: _causal_conv1d_fwd_kernel. This causes a latency spike; consider extending warmup to cover this shape/config.
(EngineCore pid=392) WARNING 05-24 08:29:11 [jit_monitor.py:103] Triton kernel JIT compilation during inference: _fused_post_conv_kernel. This causes a latency spike; consider extending warmup to cover this shape/config.
(APIServer pid=1) INFO 05-24 08:41:30 [loggers.py:271] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 4.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 83.8%, MM cache hit rate: 50.0%
(APIServer pid=1) INFO 05-24 08:41:40 [loggers.py:271] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 83.8%, MM cache hit rate: 50.0%
(APIServer pid=1) INFO: 172.17.0.1:45968 - "POST /v1/chat/completions HTTP/1.1" 200 OK
(APIServer pid=1) INFO 05-24 08:42:00 [loggers.py:271] Engine 000: Avg prompt throughput: 3.5 tokens/s, Avg generation throughput: 56.7 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 2.3%, Prefix cache hit rate: 83.8%, MM cache hit rate: 50.0%
(APIServer pid=1) INFO: 172.17.0.1:58652 - "POST /v1/chat/completions HTTP/1.1" 200 OK
(APIServer pid=1) INFO 05-24 08:42:10 [loggers.py:271] Engine 000: Avg prompt throughput: 3.5 tokens/s, Avg generation throughput: 86.3 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 2.3%, Prefix cache hit rate: 83.8%, MM cache hit rate: 50.0%
(APIServer pid=1) INFO: 172.17.0.1:42426 - "POST /v1/chat/completions HTTP/1.1" 200 OK
(APIServer pid=1) INFO 05-24 08:42:20 [loggers.py:271] Engine 000: Avg prompt throughput: 3.5 tokens/s, Avg generation throughput: 86.3 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 2.3%, Prefix cache hit rate: 83.8%, MM cache hit rate: 50.0%
(APIServer pid=1) INFO 05-24 08:42:30 [loggers.py:271] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 83.9 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 83.8%, MM cache hit rate: 50.0%
(APIServer pid=1) INFO 05-24 08:42:40 [loggers.py:271] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 83.8%, MM cache hit rate: 50.0%
(APIServer pid=1) INFO: 172.17.0.1:35304 - "POST /v1/chat/completions HTTP/1.1" 200 OK
(APIServer pid=1) INFO 05-24 08:44:10 [loggers.py:271] Engine 000: Avg prompt throughput: 3.5 tokens/s, Avg generation throughput: 67.2 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 2.3%, Prefix cache hit rate: 83.8%, MM cache hit rate: 50.0%
(APIServer pid=1) INFO: 172.17.0.1:57372 - "POST /v1/chat/completions HTTP/1.1" 200 OK
(APIServer pid=1) INFO 05-24 08:44:20 [loggers.py:271] Engine 000: Avg prompt throughput: 3.5 tokens/s, Avg generation throughput: 86.3 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 2.3%, Prefix cache hit rate: 83.8%, MM cache hit rate: 50.0%
(APIServer pid=1) INFO: 172.17.0.1:37742 - "POST /v1/chat/completions HTTP/1.1" 200 OK
(APIServer pid=1) INFO 05-24 08:44:30 [loggers.py:271] Engine 000: Avg prompt throughput: 3.5 tokens/s, Avg generation throughput: 86.3 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 2.3%, Prefix cache hit rate: 83.8%, MM cache hit rate: 50.0%
(APIServer pid=1) INFO 05-24 08:44:40 [loggers.py:271] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 73.4 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 83.8%, MM cache hit rate: 50.0%
(APIServer pid=1) INFO 05-24 08:44:50 [loggers.py:271] Engine 000: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Waiting: 0 reqs, GPU KV cache usage: 0.0%, Prefix cache hit rate: 83.8%, MM cache hit rate: 50.0%
不知道KV还能不能再往上冲,毕竟是多模态,不审查内容跟不审查图片识别都已经测试没问题了~请大神帮忙看看KV跟TPS还有什么可以调整的空间~感谢感谢~第一个帖子搞得不好还请多包涵~
对了,模型二我就没有贴了,因为效能不如我自制的模型,我是看了几个老外的帖子说很厉害85-110TPS,结果试了之后才34,我这个也有上到85的时候,平均比Lorbus多~但我又看到另外一个说用NVFP4+MTP也很厉害,可能晚上我也来折腾一下,试试自制NVFP4 + MTP跑一下~以上汇报~