
kimi k3 的左右互搏术 是值得称道的。它被评为最适合小白的模型是有道理的。
最被诟病的就是慢。真慢啊。非常慢。root下放开权重让 K3 随便折腾是最好的选择。
给它充值是主要原因就是。给他写好任务计划。你就放手让它慢慢,慢慢,慢慢跑就行了。基本能得到结果。
-
Kimi K3大获成功,团建都去三里屯工体,谢谢各位老爷充值. -
AI泡沫要来了吗?又是显卡锁仓,又是开放权重 AI所谓的开放 也不过是 让我们这些散户 入场而已。
开放的模型越多越好。显卡的需求量不就上来了。 -
从 41 到 56 tok/s:我修好了 DFlash 官方 benchmark 的 bug,顺手在 7900 XTX 上搭了全套联网大模型任何模型能工作才是最重要的。网络中的各种测试都是一个参考。只能作为你没安装前的考量参数。
输出速度再快。不能24小时无人值守运行程序也是一个展示型玩物。
这篇帖子的精华是给大家一个低门槛能链接互联网的 Qwen 27B。没有这个基础模块各种项目无法开展。
没上更复杂的链接方式是讲清楚让所有人都能安装太墨迹了。这套操作的适用行最强。安装最简单。 -
国内博主出海,要不要加入MCN机构?看了。速度可以。加载需要等待几秒。插件功能正常。
-
M1 Max MBP - Hermes干活小表情 太可爱了🤣@stxpnet 任务如下:从1开始数数到2亿
-
从 41 到 56 tok/s:我修好了 DFlash 官方 benchmark 的 bug,顺手在 7900 XTX 上搭了全套联网大模型我一直 用的 adspower.
补充下进展 联网+Qwen3.6-27B+cpu 纯编码 .sh .py .js 最终实现了视频工作流生产。
结论:在课件类视频中 实现指定逻辑是第一位的。 wan ltx 自身运行中的想象力不可控因素过多。不能实现无人程序化产出。 -
从 41 到 56 tok/s:我修好了 DFlash 官方 benchmark 的 bug,顺手在 7900 XTX 上搭了全套联网大模型联网+Qwen3.6-27B+ ltxv-13b-0.9.8-distilled-fp8(14.6G) 可以实现一个 自动产出的工作流了。
实测 老同学 2B的小模型和没有没什么区别。这个 2B是用来搞笑的生产力! -
从 41 到 56 tok/s:我修好了 DFlash 官方 benchmark 的 bug,顺手在 7900 XTX 上搭了全套联网大模型可以联网是开展工作流的基础。这样7900XTX就有了实战能力了。
-
从 41 到 56 tok/s:我修好了 DFlash 官方 benchmark 的 bug,顺手在 7900 XTX 上搭了全套联网大模型7900XTX 质量上下文 并能联网搜索 接入不了 Hermes。上下文长度不够。
-
从 41 到 56 tok/s:我修好了 DFlash 官方 benchmark 的 bug,顺手在 7900 XTX 上搭了全套联网大模型27B 不能联网 搜索的问题。很多人提问。提供一个解决方案吧。在不借用 hermes的情况下如何实现。安装后测试完全可用。建议 32G显存。24G可用但是不能太复杂。
全程使用 kimi k3 1M max 配置
实施时长:1小时。主要原因是网速。网速慢的时候得1.5小时Qwen3.6-27B 本地部署方案与测试报告
一、环境
项 配置 CPU / 内存 i7-4790K(4C/8T)/ 32 GiB DDR3 GPU RX 7900 XTX 24 GiB(gfx1100),驱动 amdgpu 6.16.13,ROCm 7.2.0 系统 Ubuntu 24.04,kernel 6.14,磁盘余量 637G 网络 局域网固定 IP 192.168.8.247(路由器锁定)
二、总体架构
浏览器 → Open WebUI (:8080, venv) → dflash_server (:8000, C++/HIP) → 7900 XTX │ Q4_K_M 主模型 16G + Q8_0 DFlash 草稿 1.8G(DDTree 树验证)- 推理引擎:Lucebox DFlash(lucebox-hub 源码编译),块扩散草稿 + DDTree 树验证投机解码
- 隔离原则:venv 只隔离 Python 工具链(下载/前端);模型即 GGUF 文件,多模型切换零隔离成本;未用 Docker
- 启动命令:
dflash(模型 API)、dflash-ui(网页前端),GPU 高性能模式随服务启停自动切换(解决空载风扇噪音)
三、安装步骤(可复现)
# 1. 依赖 apt-get install -y git cmake build-essential hipblas-dev hipcub-dev \ rocblas-dev rocprim-dev rocwmma-dev python3-venv # 2. 源码 git clone --recurse-submodules https://github.com/Luce-Org/lucebox-hub cd lucebox-hub/server # 3. 编译(gfx1100,含 rocWMMA Phase2 prefill kernel) cmake -B build -S . -DCMAKE_BUILD_TYPE=Release -DDFLASH27B_GPU_BACKEND=hip \ -DDFLASH27B_HIP_ARCHITECTURES=gfx1100 -DDFLASH27B_HIP_SM80_EQUIV=ON cmake --build build --target test_dflash dflash_server test_flashprefill_kernels -j4 ./build/test_flashprefill_kernels # 数值验证 # 4. Python 工具(venv) python3 -m venv ~/venvs/dflash && ~/venvs/dflash/bin/pip install huggingface_hub transformers open-webui # 5. 模型 hf download unsloth/Qwen3.6-27B-GGUF Qwen3.6-27B-Q4_K_M.gguf --local-dir ~/models/ hf download Lucebox/Qwen3.6-27B-DFlash-GGUF dflash-draft-3.6-q8_0.gguf --local-dir ~/models/draft/
四、关键调优与踩坑记录
坑 根因 解法 官方 bench 速度虚低(41 t/s) bench_he.py只传--ddtree-budget不传--ddtree,源码里预算不启用树模式直接驱动 test_dflash补--ddtreebudget≥16 速度腰斩 verify token 数 >16 触发 TILE kernel(gfx1100 上的慢/不稳路径) 实测甜点 budget=12(VEC 路径内 AL 平台期上限)Q8_0 草稿必需环境变量 滑窗正确性 DFLASH27B_DRAFT_SWA=2048运行中 OOM 崩溃 64K 上下文 KV 全量预分配 + 前缀缓存 32 槽不限量 MAX_CTX=32768+--prefix-cache-slots 8前端报超上下文 Open WebUI 发 max_tokens=32768服务端 --default-max-tokens 8192(§4.4 钳制,日志已验证)风扇空载狂转 DPM 常驻 high 启动脚本内 high,退出 trap 回 auto
五、测试报告
测试项 结果 rocWMMA kernel 数值验证 全部 PASS(S=8192:18.3 ms/iter) AR 基线( test_generate)25.87 tok/s 投机链模式(缺 --ddtree)41.4 tok/s DDTree budget=12(10-prompt 均值) 44.46 tok/s,AL 4.65,接受率 29.5%,1.72× AR API 实测:英文代码 53.9 tok/s(接受率 34%) API 实测:中文对话 19.8 tok/s(草稿为代码优化,中文收益低,属预期) 显存占用(稳定运行) 19.6 / 24 GiB,余量 4+ GiB 注:参考文章的 81 tok/s 未复现,原因有二——其使用 6 月旧版引擎(现行版在 gfx1100 有性能回退),且其 CPU 为双路 E5;本文数据为本机多次实测均值。
六、Web 支持(Open WebUI)
pip install open-webui装入同一 venv;启动脚本dflash-ui注入:OPENAI_API_BASE_URL(S)=http://127.0.0.1:8000/v1ENABLE_OLLAMA_API=false
- 访问
http://192.168.8.247:8080,首个注册账号自动成为管理员(数据全在本机)
七、网页搜索实现
原理:模型本身不联网。Open WebUI 中间件在调用模型前先用 DuckDuckGo(
ddgs,免 API key,本机直连已验证)检索,把结果注入提示词,模型基于注入内容作答并附引用。配置落地(两个教训)
- 该版本配置键为
ENABLE_WEB_SEARCH/WEB_SEARCH_ENGINE(而非旧版ENABLE_RAG_WEB_SEARCH); - 首次启动会把默认值持久化进 SQLite(
…/site-packages/open_webui/data/webui.db),之后 env 改不动——最终直接改库:web.search.enable=trueweb.search.engine="duckduckgo"result_count=3
使用方式
全局开关只是放行;每个对话需在输入框点 地球图标(代码依据
middleware.py:2456,仅当features.web_search=true才执行搜索)。闲聊勿开,免得拖慢首 token。
八、运维速查
dflash # 启模型 API(:8000) Ctrl+C 停 dflash-ui # 启网页前端(:8080) Ctrl+C 停 MAX_CTX=65536 PC_SLOTS=2 MAX_TOKENS=16384 dflash # 长文本临时配置 MODEL=/root/models/xxx.gguf dflash # 换模型 # 日志:/root/dflash-server.log /root/webui.log全部组件已在运行状态,重启机器后按顺序执行
dflash、dflash-ui即可恢复。总结:在保证速度的情况下。让模型能够执行网络搜集工作。这个信息时代里,这个功能更加重要。
希望此文能帮助到大家。 -
震惊!萌新从0开始酣战4天,被Hermes和豆包连续坑害6小时原因竟是……我不建议使用你推荐的这个方案。
2080ti 没魔改 11G 也大概率是矿卡。而且这个型号太老了。只能说哥们你运气不错。
作为一搏一搏就摩托变单车的选手。
建议选择前先买一手刮刮乐。看看风向。
欧皇可以上。 -
想问 这个配置是买N卡好还是AMD卡? 显卡买7900XTX还是3080矿卡20G ?预算有限7900 XTX 吧。3080 矿 翻车概率 太高了
-
kimi K3不要用来编程了,卡的不动了,又用回kimi k2.7 code了最近腰脱严重了。。。。。。。。。。
-
kimi K3不要用来编程了,卡的不动了,又用回kimi k2.7 code了不要暴露自己的实力。五分钟
-
Linux Mint 22.3 安装教程在有集成显卡的情况下。安装 Linux mint 22.3是非常好的选择。可以实现很多实用的功能。
-
一文看懂:编程技术哪家强,如何选工具和模型赞同。想用便宜 token 还做好程序的就得像我这种半人工模式才行。
-
我的搜索自己说了算Linux 下安装 adspower 。
Hermes下。把你的API和KEY 给Hermes 就搞定了。
无桌面的模式 应该也不复杂。就用个搜索会更简单。免费的窗口就够用。让AI不要用完就关闭是重点。免费的每天有打开次数的限制。
现在有永久窗口提供购买。属于活动。不是长期有的。上一次活动我没参加。这期开了一堆。
论坛里有个想实现常驻浏览器搜索的。在论坛刚开不久。用adspower 就搞定了。很简单。属于小白工具。
它相当于一个免费的 MCP server。没开源而已。
MCP
通过AdsPower LocalAPI MCP Server,您可以直接在支持 MCP 的 AI 工具(如Claude、Cursor等)中,用对话的方式来操作 AdsPower,例如启动浏览器、创建浏览器、更新浏览器指纹配置等操作。 了解更多配置类型
通用配置
平台配置
Claude Code
Codex
Cursor
OpenCode -
Linux Mint 22.3 安装教程摘抄我自己的文章。
折腾了下 windows 11 下 comfly ui。恶补下视频生成技术。直接讲重点。对于系统桌面的需求。单机不能看结果很难受。因为是非工作内容。这台7900XTX 并没接入我的工作网络。状态单身。
Linux下的设置:
首先是 Linux mint 22.3 下测试 集显负责桌面显示,视频播放等工作。独立显卡负责算力输出。非常容易。没什么可以讲的。直接让在线AI 全程就可以搞定。
(今天补充下吧:最好赋予免授权权限。
1.详细了解当前电脑配置。等待AI完成后进行下一步对话
2.安装集成显卡负责桌面显示,独立显卡负责算力供应配置。等待AI完成后进行下一步对话
3.检查安装是否成功。显示当前显卡驱动版本。)
之后 切换到 windows 11 场景。十分折腾 和我好久没用过也是直接原因。说结果吧。
1.显示器 直连 独立显卡 安装Windows 11
2.安装完成进入Windows 下 驱动你的集成显卡。(不放心,或技术一般建议重启一下看看设备管理器。集成驱动是否正常。)
3.关机进入bios 将集成显卡设置为主显卡。显示器接到主板的集成显卡接口,从集成显卡进入系统。
3步这是我测试后的方案。错误过程直接省略吧。
这个布局对 comfly ui 有非常显著的提升。在你需要桌面的情况下。 -
Linux Mint 22.3 安装教程步骤:
一 访问 https://linuxmint.com/download.php
二
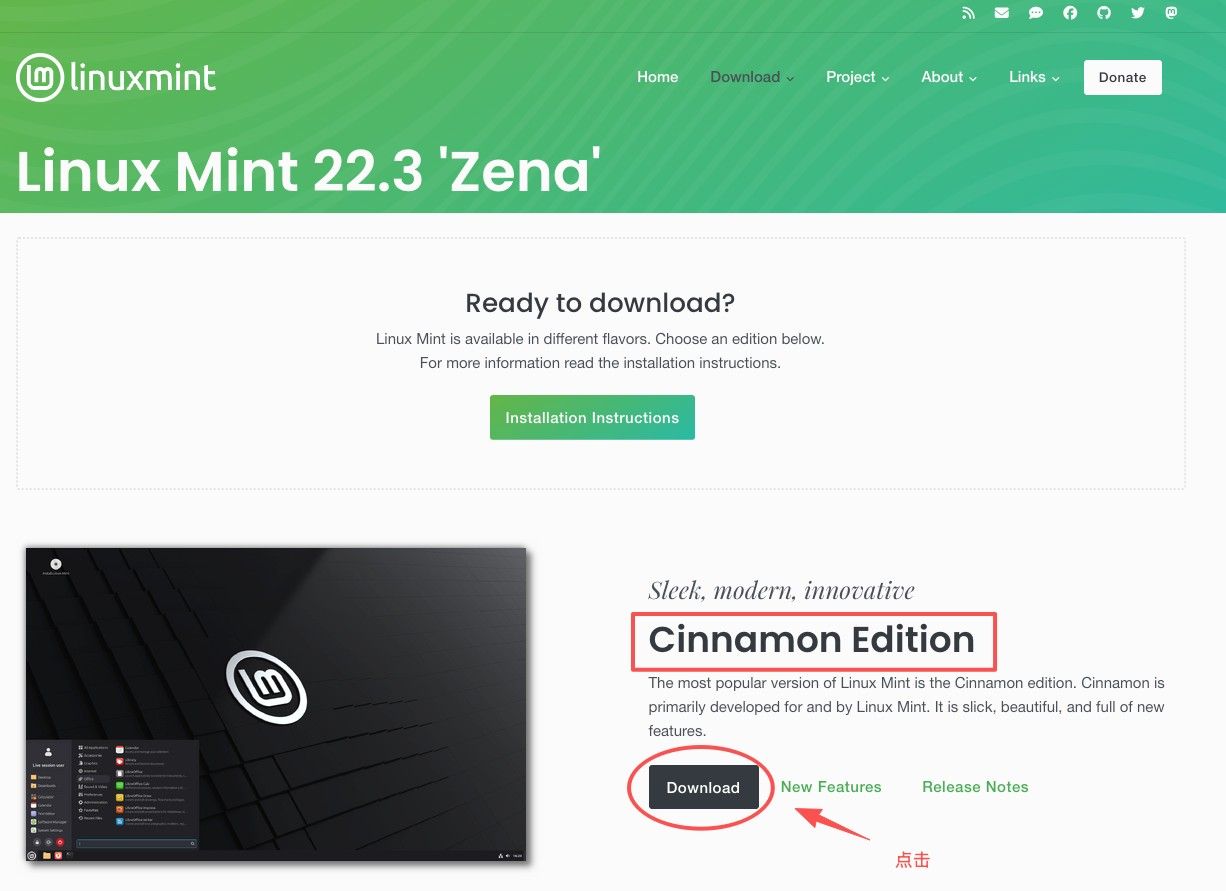
三 往下拉 找到你的国家。任意服务器都可以。速度不行就换一个。
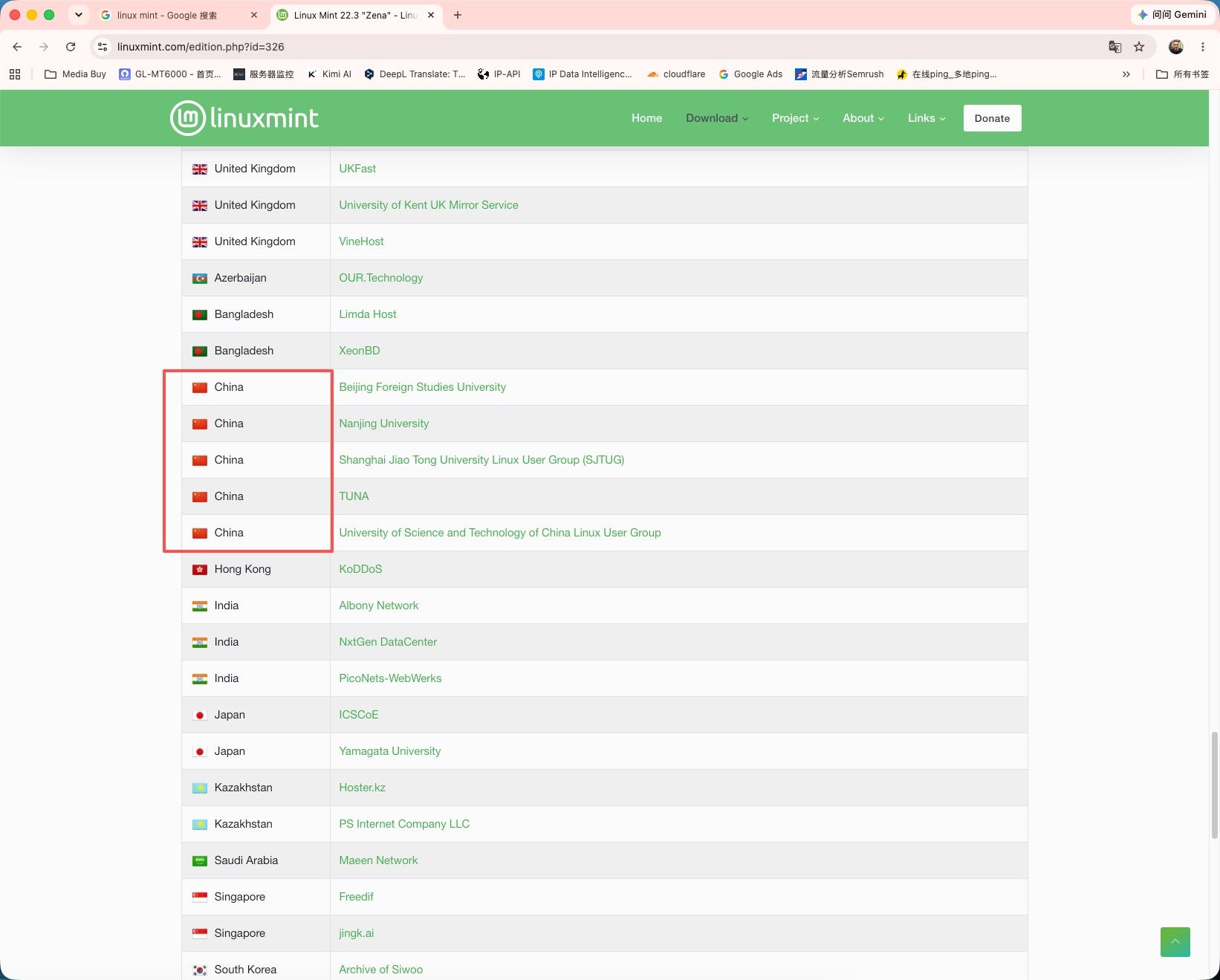
四 Linux Mint 22.3 制作启动U盘教程
使用 Rufus
下载 Rufus:
官网:https://rufus.ie/zh/
下载 rufus-4.x.exe(便携版,无需安装)
制作步骤:
插入U盘,打开 Rufus
设备:选择你的U盘(注意别选错!)
引导类型选择:点击「选择」按钮,找到你下载的 Linux Mint ISO 文件
分区类型:
如果你的电脑是 较新的 UEFI 启动(2015年后):选 GPT,目标系统类型选 UEFI (非 CSM)
如果你的电脑是 较老的 Legacy BIOS:选 MBR,目标系统类型选 BIOS 或 UEFI
不确定的话,选 GPT + UEFI 即可,兼容性最好
文件系统:保持默认 FAT32
卷标:可以自定义,如 LINUXMINT22
点击 「开始」
弹出提示时,选择 「以 ISO 镜像模式写入(推荐)」
等待进度条完成,显示 「准备就绪」 即可拔出U盘Mac 系统制作教程
下载:
官网:https://www.balena.io/etcher/
下载 .dmg 文件安装
制作步骤:
插入U盘
打开 balenaEtcher
点击 「Flash from file」 → 选择 ISO 文件
点击 「Select target」 → 选择U盘
点击 「Flash!」
输入 Mac 管理员密码授权
等待完成即可四 开始安装
主板BIOS设置(重点)
① 关闭 Secure Boot(安全启动)
② 设置启动模式(UEFI vs Legacy)
③ 调整启动顺序 将 USB 设备 或 UEFI: USB 移到第一位
④ 关闭 Fast Boot(快速启动)
⑤ SATA 模式设置(重要!)BIOS → 系统 → SATA配置 → SATA模式选择 → AHCI
⑥ 其他建议设置设置项 推荐值 说明 VT-x / AMD-V Enabled 虚拟化支持,建议开启 IOMMU Enabled AMD平台建议开启 Above 4G Decoding Enabled 大显存显卡(如你的7900XTX)建议开启 Re-Size BAR Enabled 提升显卡性能 插上U盘 启动 开始安装
等待进入图形化安装界面
左上角有个图标 双击开始安装
不要安装多媒体 不要联网
磁盘步骤建议全新格式化安装
好了。完成后记得最后一步。选择关机。不要选择重启。在启动前一定要拔掉U盘。
收工。 -
求助帖,文字(文案、剧本)转音频,声音 AI 化太明显!对于 死磕 windows ,我只好不说什么了。你的逻辑思路一直是BUG状态。只能你自己修复。