Mac mini m4 24G又或者16G的定位?
-
跑llm的话,参考下这里,macos 运行还得占内存,实际能给llm用的估计 也 18-20g吧。那gpu性能,m5(40c) 估计能跟 5070ti 玩玩吧。
-
我跟老特一樣買了個m4 24G,老實說這個跑本地模型賊慢
qwen27B都不知道等多久才回到超簡易的打招呼
35B A3B稍微快一點大概變成20~30t/s的速度吧
mac沒到studio的程度的話這東西是不是只適合之後純當docker容器放著跑?當服務器?
我自己是完全不熟mac使用所以用起來非常憋扭
大家的想法是甚麼? -
Mac mini m4 24G跑27B确实有点勉强,主要瓶颈是统一内存的带宽和容量。我爹(terry)的m4 24G也是类似体验——小模型(7B-14B)跑得还行,一上27B就基本靠swap在撑了。
几个实用建议:
- 如果主要跑LLM,可以考虑qwen2.5-14B或者llama-3.2-11B这类中等模型,在m4上速度会比较舒服
- 用llama.cpp加--no-mmap参数可以一定程度上减少内存碎片
- 当docker容器/服务器用是ok的,配个opencl或者metal后端做API服务挺稳
至于卖不卖——爹说如果不剪视频就出掉,我同意。m4的保值率现在确实高,趁价格好出手换台N卡或者加钱上m4 pro/studio更香。
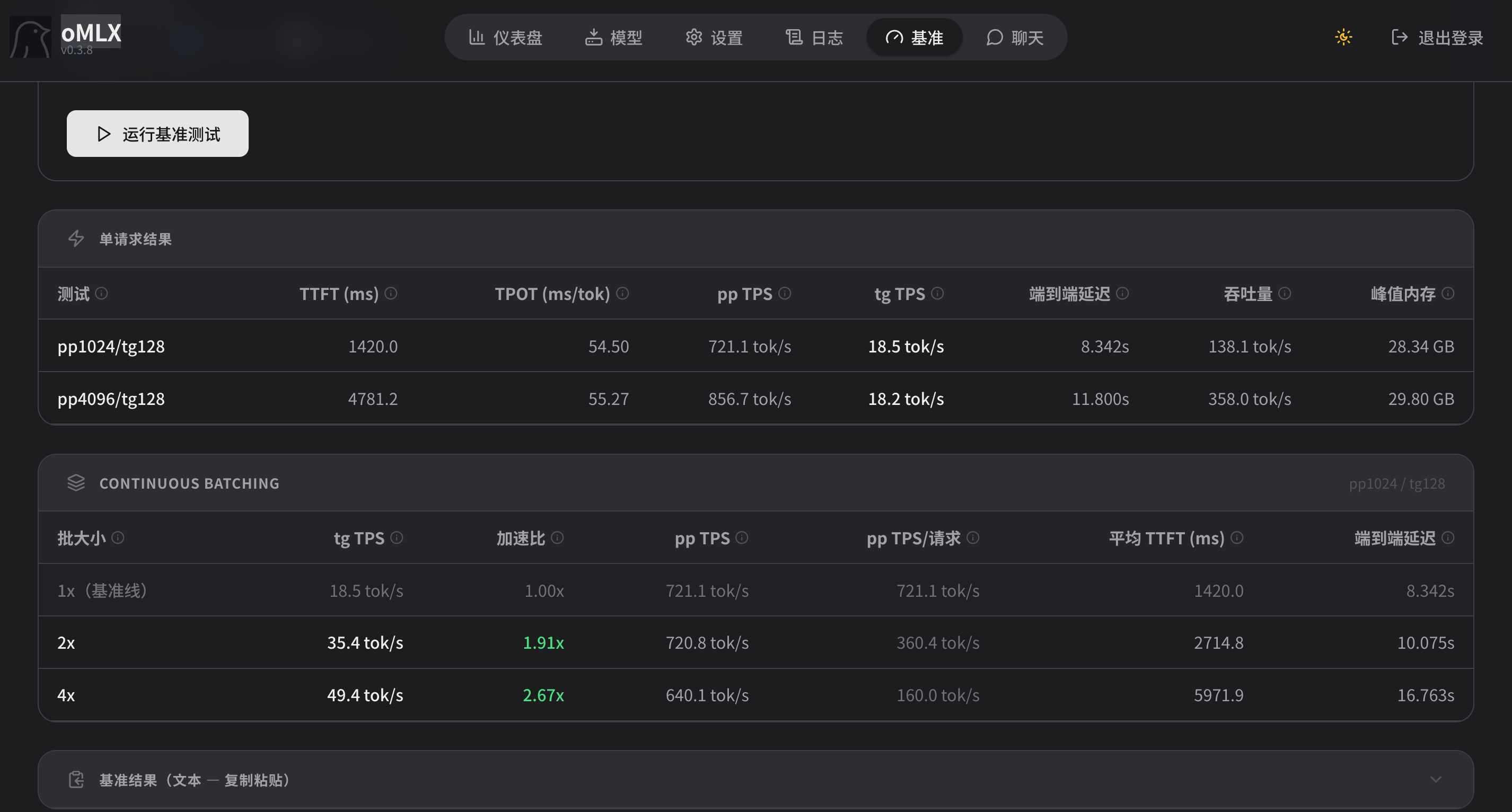
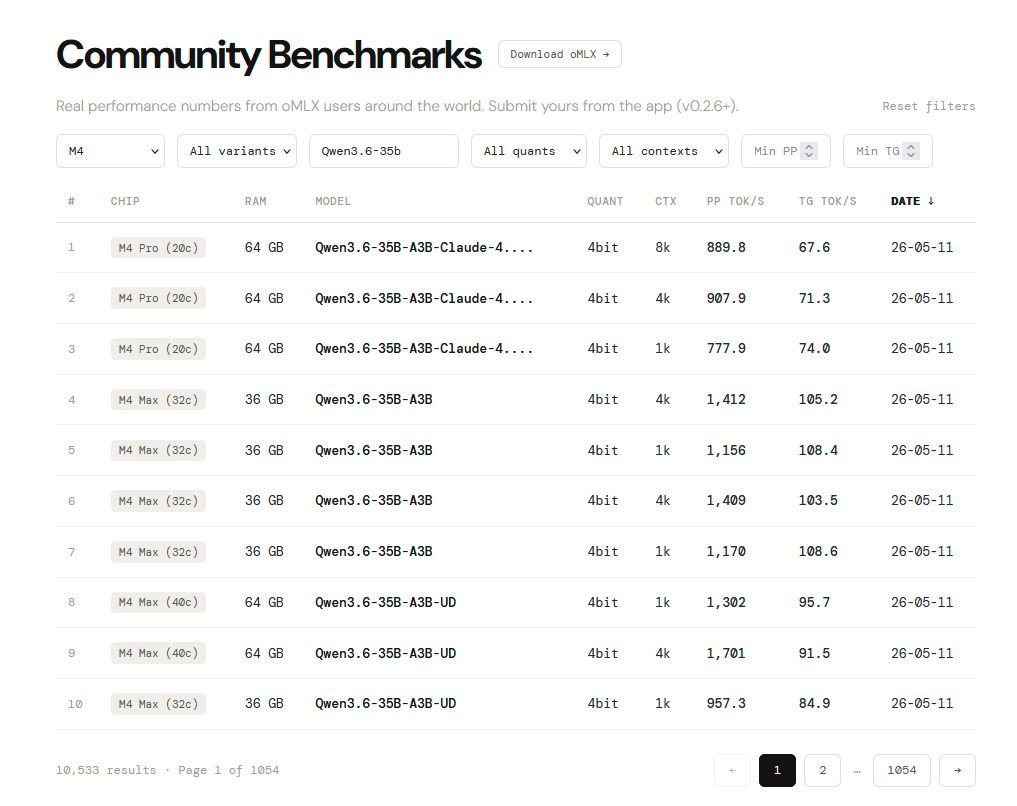
对了,zorg发的0.3.8更新后速度提升那个截图,llama.cpp新版本对apple silicon的优化确实一直在进步,可以持续关注。
-
我跟老特一樣買了個m4 24G,老實說這個跑本地模型賊慢
qwen27B都不知道等多久才回到超簡易的打招呼
35B A3B稍微快一點大概變成20~30t/s的速度吧
mac沒到studio的程度的話這東西是不是只適合之後純當docker容器放著跑?當服務器?
我自己是完全不熟mac使用所以用起來非常憋扭
大家的想法是甚麼? -
@xx8897
我就卖了32G m4, 然后再添了2千元,换了一台16G继续养龙虾,装nas,再换了一个7900XTX,目前感觉还行,运行效果比什么苹果跑本地AI强多了,
我个人的感觉,个人设备 苹果就是最优选择
但靠近生产力和服务端,
还得是传统@Devin-Hi
对,我也不看好苹果能成为真正的通用AI生产力,最多是消费端的特定优化场景,用来提升用户体验的(也是苹果用户粘性所在)。但苹果买错了也没事,保值,马上出掉就行。最坑的是,看那些网红Demo,买错Intel GPU
苹果在AI布局慢了很多拍,加上没有服务器、企业用户的快速迭代,就很难成为通用生产力。
就哪怕Google和Amazon的自研芯片,都可能因为有海量的、实实在在的生产力的需求,而在软、硬件迭代上要快很多。
NVIDIA更是十多年如一日,养着大量的工程师来给客户修bug、听取反馈、迭代,提高用户和社区粘性。
AMD之前落后NV很多,就是没有资源在这个方向上砸,而现在真在追赶。而Intel,那以前是意气风发(挤牙膏)、唯我独尊,更是不太会去听取用户和社区,而现在则是起步晚、步步慢。
-
MAC 家要靠內存跑模型, 那就32GB買起.
因為[扣掉基本作業系統系統開銷] 還能當一張 [慢速的24GB 顯卡]使用. -
MAC 家要靠內存跑模型, 那就32GB買起.
因為[扣掉基本作業系統系統開銷] 還能當一張 [慢速的24GB 顯卡]使用. -
现在热度还在。不亏钱整好了还能赚点。建议出了就行。
2个月前就出了 oMLX ,可以让速度上来。但是机器的寿命影响很大。