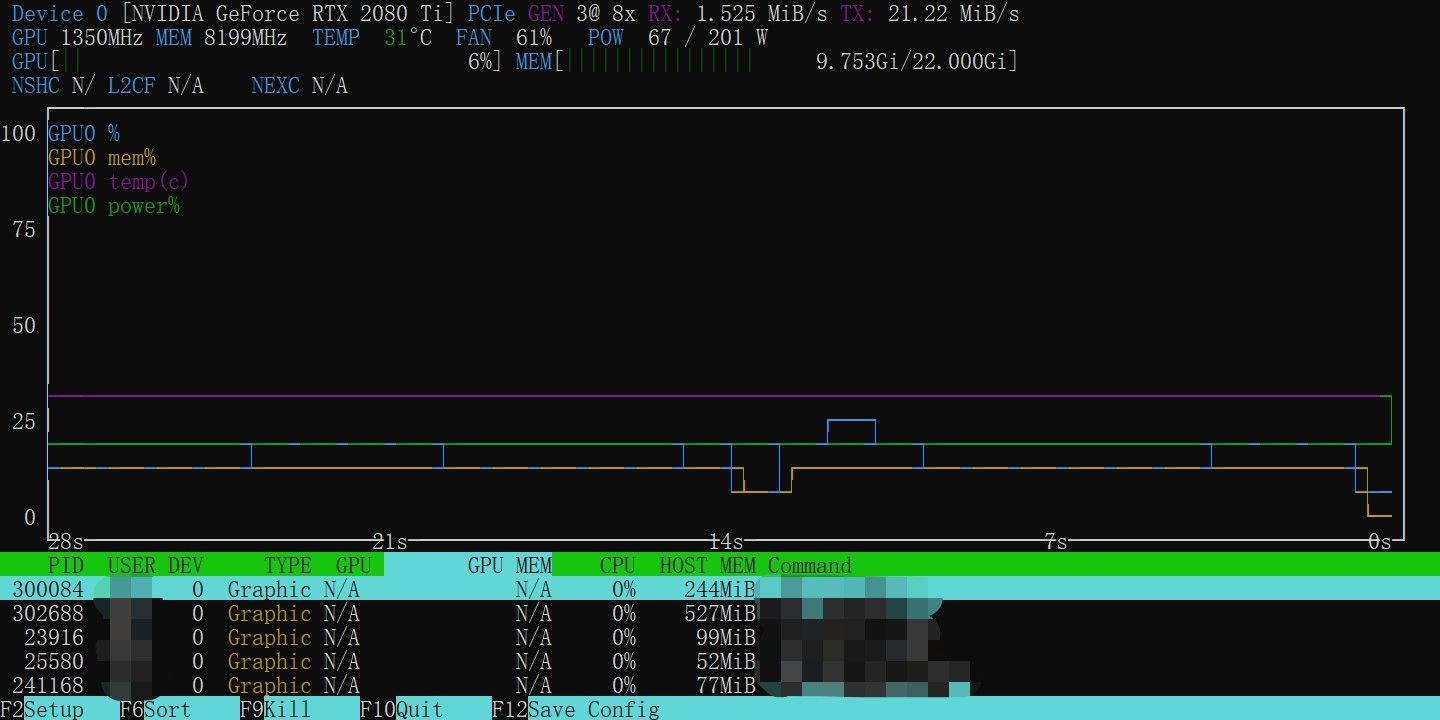
买了2张5060Ti,谁能跑最便宜的Qwen 27B?
-
显存不够用,也不支持NVLink扩展
-
我的3080跑3.6-27B-Q4KM 上下文65536刚刚够用,每秒差不多32token。对我来说也满足了,毕竟3080玩本地部署才刚刚够入门。刚加载的时候占用18181M显存,随着对话没啥变化。我一般开着watch -n 2 nvidia-smi实时监控显卡,我现在就怕它高温。显存温度最高来到92度,让我揪心。
-
@Tide 限制显卡功率,同时给显存超频,测试一下稳定性。
我用着2080Ti 22GB改水冷的,用Nvidia Inspector工具,把功率限制在200W~230W,核心超频+40Mhz(也可以不超核心),显存超频+1200Mhz,跑下来温度最高只有不到50°C,热点不超过65°C,室温27°C左右。
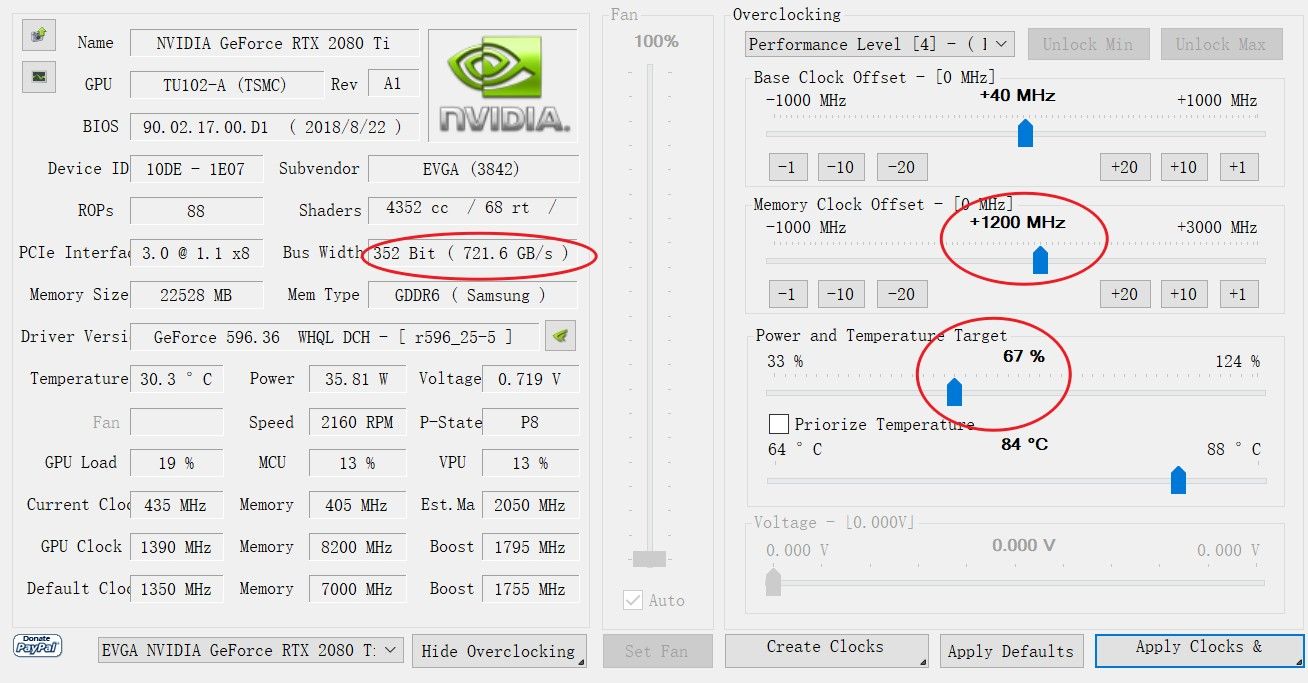
显存超频后带宽721.6GB/s,相比默认的616GB/s,提升超过17%,完美抵消限制功率导致的核心频率下降带来的性能损失,直接节约100W,33%的功率Qwen 27B Q4_K_M,上下文开32K跑下来,decode 25 tok/s
用Llama.cpp benchmark跑分如图:
全默认,显卡功率300W:

核心超频+40Mhz,显存超频+1200Mhz:

核心超频+40Mhz,显存超频+1200Mhz,显卡功率锁67%限制在200W:

大语言模型主的矩阵运算要跑在GPU的Tensor Cores上,对GPU其他部分如大量的SM单元里的CUDA核心占用不高,GPU此时对功率的实际消耗并不需要太高。
并且大语言模型prefill阶段对核心频率有一定依赖,但降频对prefill性能影响不太大。
decode吐字阶段,对显存带宽的依赖程度大于核心算力,经常是显存带宽不足,喂不饱核心,核心有很多时间都在空转等数据。综上,你的3080可以尝试限制功率,并小超显存,给显卡背板加装散热铝片+风扇。
然后实测看看数据。 -
@Tide 限制显卡功率,同时给显存超频,测试一下稳定性。
我用着2080Ti 22GB改水冷的,用Nvidia Inspector工具,把功率限制在200W~230W,核心超频+40Mhz(也可以不超核心),显存超频+1200Mhz,跑下来温度最高只有不到50°C,热点不超过65°C,室温27°C左右。
显存超频后带宽721.6GB/s,相比默认的616GB/s,提升超过17%,完美抵消限制功率导致的核心频率下降带来的性能损失,直接节约100W,33%的功率Qwen 27B Q4_K_M,上下文开32K跑下来,decode 25 tok/s
用Llama.cpp benchmark跑分如图:
全默认,显卡功率300W:
核心超频+40Mhz,显存超频+1200Mhz:
核心超频+40Mhz,显存超频+1200Mhz,显卡功率锁67%限制在200W:
大语言模型主的矩阵运算要跑在GPU的Tensor Cores上,对GPU其他部分如大量的SM单元里的CUDA核心占用不高,GPU此时对功率的实际消耗并不需要太高。
并且大语言模型prefill阶段对核心频率有一定依赖,但降频对prefill性能影响不太大。
decode吐字阶段,对显存带宽的依赖程度大于核心算力,经常是显存带宽不足,喂不饱核心,核心有很多时间都在空转等数据。综上,你的3080可以尝试限制功率,并小超显存,给显卡背板加装散热铝片+风扇。
然后实测看看数据。 -
@Vivid-Vector 3090ti有参数么?
@暧昧光影
手上暂时没有3090Ti。
不过按我的经验,温度能控制得住的情况下,锁功率,小超核心,大超显存,对于跑LLM来说都适用。
B站有人实测PRO 6000 Max-Q 版,功率只有300W,相比满血600W的工作站版只损失10%的性能,而且他还没给显存超频。我看到的PRO 6000,跑LLM经常都是吃不满功耗,TDP 600W的工作站版,只吃到450W左右的样子。
跑满600W功耗的情况,通常是GPU SM里的CUDA核心满载,Tensor Cores也接近满载,同时显存空间和带宽也占用很高的情况才会出现。
LLM的矩阵运算主要靠Tensor Cores执行,且吃满显存空间和带宽,但SM CUDA核心通常空载。 -
我的3080跑3.6-27B-Q4KM 上下文65536刚刚够用,每秒差不多32token。对我来说也满足了,毕竟3080玩本地部署才刚刚够入门。刚加载的时候占用18181M显存,随着对话没啥变化。我一般开着watch -n 2 nvidia-smi实时监控显卡,我现在就怕它高温。显存温度最高来到92度,让我揪心。
-
@Eric-HO
是用 https://github.com/TheTom/llama-cpp-turboquant 嗎
能跑多少 t/s
能給我llama.cpp的參數嗎 我想參考你覺得我現在只有一張3070ti 8g 如果再加一張3060 12g能順跑3.6-27B-Q4KM嗎
我現在用
cpu 5900x
ram 64g
gpu 3070ti 8g-ngl 9 -c 87475 -np 1
-t 12 -b 1024
-ctk turbo4 -ctv turbo4-fa on
--jinja--cache-reuse 1024
--slot-save-path cache--spec-type ngram-mod
--spec-ngram-size-n 6 `
--draft-min 16 --draft-max 96qwen3.6-27b-q4_k_m.gguf 2.84 t/s 左右
Qwen3.6-35B-A3B-IQ4_XS.gguf 35 t/s 左右 -
@Tide 限制显卡功率,同时给显存超频,测试一下稳定性。
我用着2080Ti 22GB改水冷的,用Nvidia Inspector工具,把功率限制在200W~230W,核心超频+40Mhz(也可以不超核心),显存超频+1200Mhz,跑下来温度最高只有不到50°C,热点不超过65°C,室温27°C左右。
显存超频后带宽721.6GB/s,相比默认的616GB/s,提升超过17%,完美抵消限制功率导致的核心频率下降带来的性能损失,直接节约100W,33%的功率Qwen 27B Q4_K_M,上下文开32K跑下来,decode 25 tok/s
用Llama.cpp benchmark跑分如图:
全默认,显卡功率300W:
核心超频+40Mhz,显存超频+1200Mhz:
核心超频+40Mhz,显存超频+1200Mhz,显卡功率锁67%限制在200W:
大语言模型主的矩阵运算要跑在GPU的Tensor Cores上,对GPU其他部分如大量的SM单元里的CUDA核心占用不高,GPU此时对功率的实际消耗并不需要太高。
并且大语言模型prefill阶段对核心频率有一定依赖,但降频对prefill性能影响不太大。
decode吐字阶段,对显存带宽的依赖程度大于核心算力,经常是显存带宽不足,喂不饱核心,核心有很多时间都在空转等数据。综上,你的3080可以尝试限制功率,并小超显存,给显卡背板加装散热铝片+风扇。
然后实测看看数据。 -
@Eric-HO
是用 https://github.com/TheTom/llama-cpp-turboquant 嗎
能跑多少 t/s
能給我llama.cpp的參數嗎 我想參考你覺得我現在只有一張3070ti 8g 如果再加一張3060 12g能順跑3.6-27B-Q4KM嗎
我現在用
cpu 5900x
ram 64g
gpu 3070ti 8g-ngl 9 -c 87475 -np 1
-t 12 -b 1024
-ctk turbo4 -ctv turbo4-fa on
--jinja--cache-reuse 1024
--slot-save-path cache--spec-type ngram-mod
--spec-ngram-size-n 6 `
--draft-min 16 --draft-max 96qwen3.6-27b-q4_k_m.gguf 2.84 t/s 左右
Qwen3.6-35B-A3B-IQ4_XS.gguf 35 t/s 左右 -
@Eric-HO 这是通过NV link显存合并的吗?
-