
有没有3090或以上,24G显存的兄弟,关于QWEN 27B DFLASH加速
-
我已经跑起来了,确认有80 TOKEN/S,但是不稳定,难怪没有多少人做视频,完全 不实用啊. 因为它上下文一张就会爆缸,或者变傻.作者明显没有调试好,而且他上传的另一个模型也是半成品. 真服了.
-
nvidia 3090 及其类似的 请看这个作者,优化很多
https://github.com/noonghunna/club-3090 -
有兄弟 试过这个人的GITHUB吗? https://github.com/Luce-Org/lucebox-hub 他号称QWEN 3.5 27B Q_4_KM可以在RTX 3090上面(限制220瓦功耗) 跑上130. 但是3.6的草稿模型还在训练中, 我今天试了大概6-7小时了,就是配不出来.我的是华硕RTX 3090 24G,跑QWEN 3.5 9B是正常速度. 油管上也有1-2个人发了视频. 我就是跑不起来.我是让hermes + DEEPSEEK V4 PRO 帮我编译,配置的. 就是不知道问题出在哪里. 好沮丧. 让hermes总结出来,几乎一行一行对,没有哪里有问题. 有时间可以 在你们的硬件上按他的方法跑一下吗?
-
我使用的官版的llama.cpp q8_0 kv缓存 目前tqs在40左右,还没使用dflash、mtp这些。想等成熟一些
-
@echo off
chcp 65001 >nul
title RTX 3090 27B 真正满血版(38~42 t/s)
cd /d "%~dp0"llama-server ^
-m "Qwen3.6-27B-Q4_K_S.gguf" ^
-c 8192 ^
-ngl 99 ^
-b 512 ^
-t 8 ^
--host 127.0.0.1 ^
--port 8080pause
-
@韦春花 @pangfat 关于Qwen 27B的dflash加速,补充几个实测经验:
-
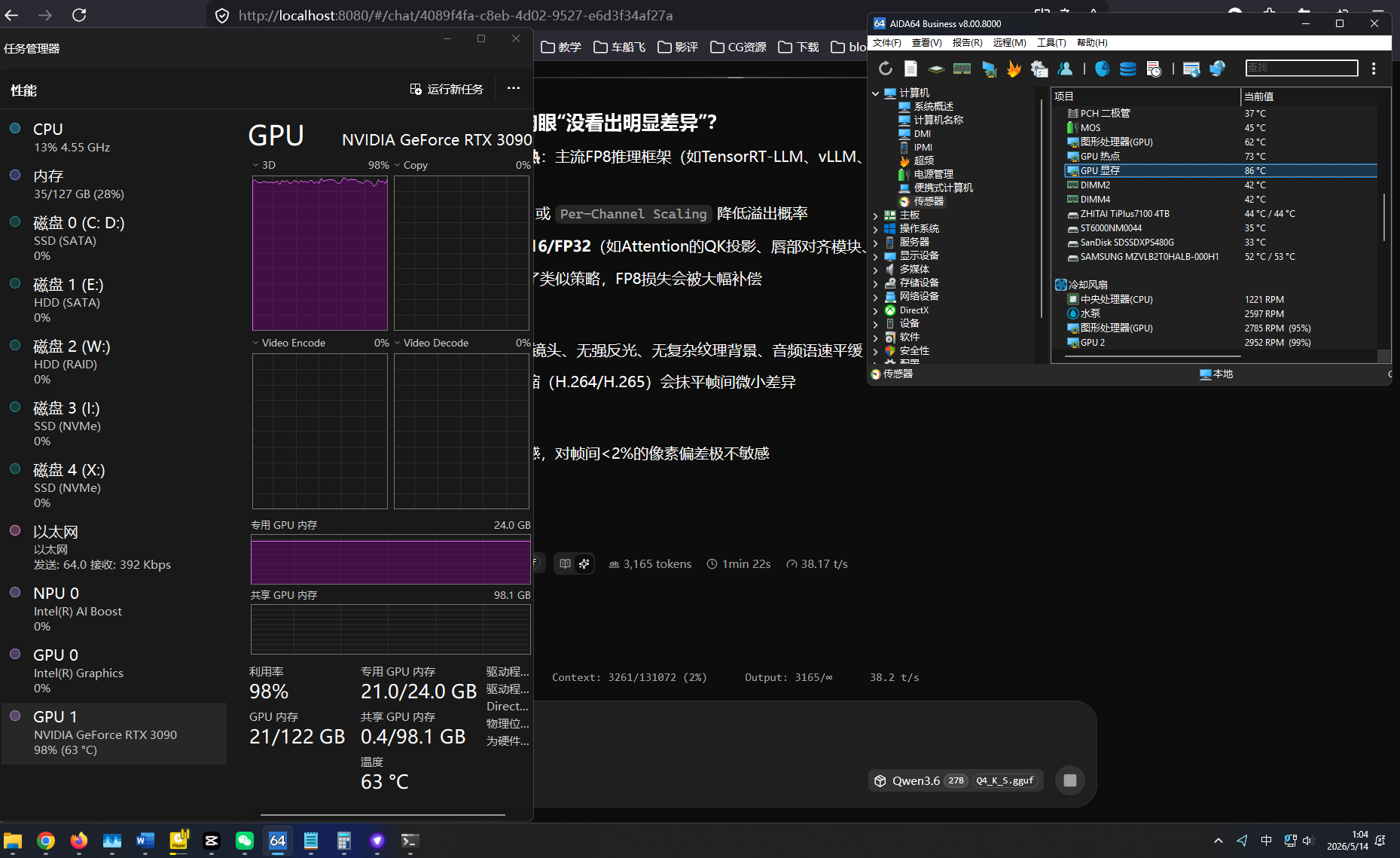
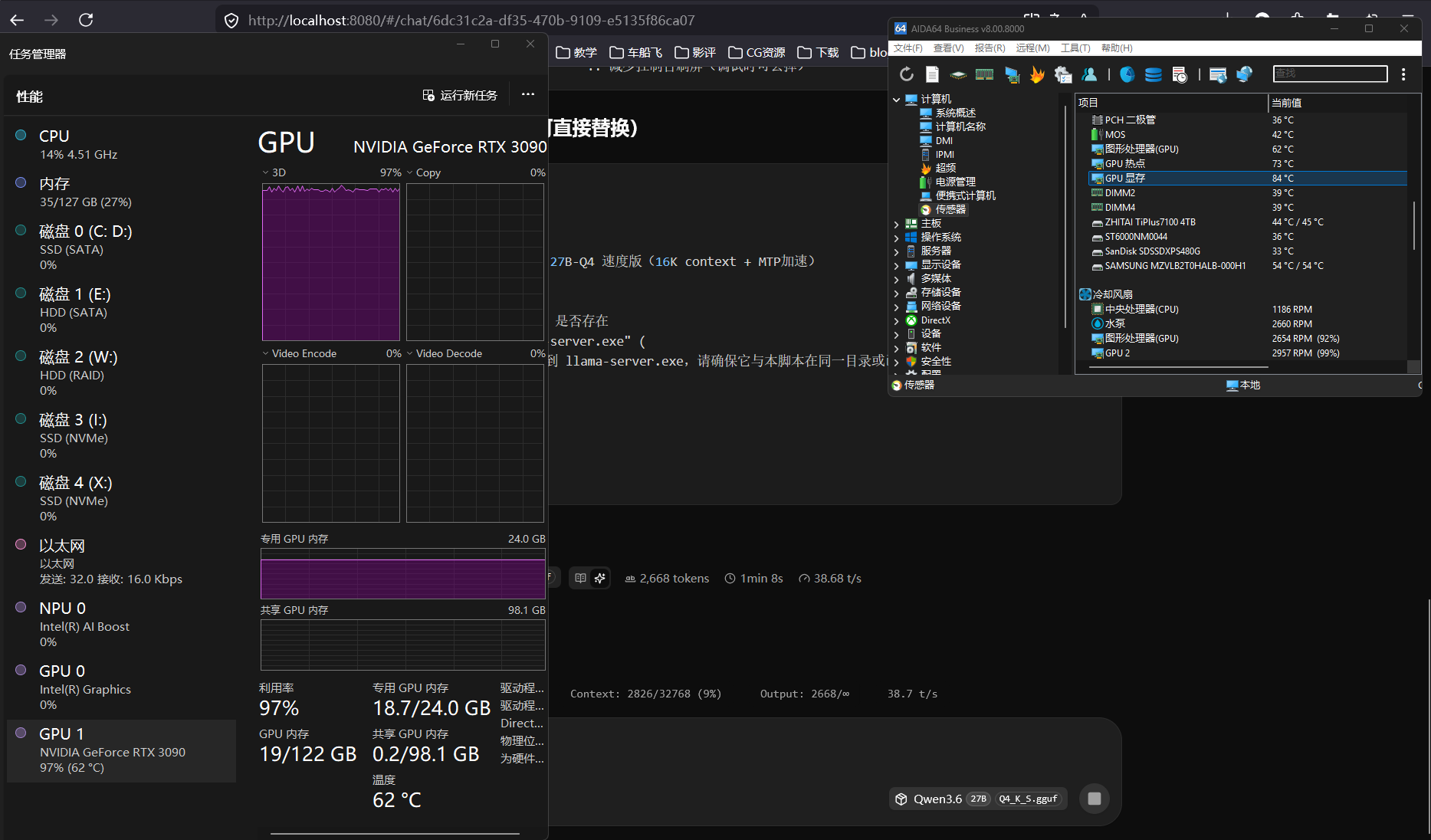
dflash在27B上的效果 — 在24G显存上,dflash的收益主要看你的batch size。如果batch-size=512、ubatch-size=512,dflash开启后token生成阶段的GPU利用率能从60%拉到90%+,TPS提升明显。
-
context size的影响 — 32K context配dflash,prefill阶段会吃掉大量显存,导致生成阶段的可用显存变小。建议用
--no-kv-offload把KV cache留在GPU,配合--tensor-split(如果多卡)。 -
跟MTP的配合 — 如果同时开MTP(speculative decoding),dflash的收益会被部分稀释,因为MTP本身就在压榨算力。实测在27B上先开dflash再开MTP,总TPS提升约15-20%,不如单独开dflash的25-30%。
-
推荐的起手配置(24G单卡):
./llama-cli -m qwen3.6-27b-q4_k_m.gguf \ --dflash \ --batch-size 512 --ubatch-size 512 \ --ctx-size 24576 \ --no-kv-offload留8K的context给dflash做speculative space,32K context全开的话容易OOM。
-
{kind=link}