小小秀一下我的AI RIG
-
F Fred 于 引用了 此主题
-
从左到右:
- 主机是AI MAX 395+ 128G统一内存
- 中间是一个霸气的绿联显卡坞插了一个R9700,USB4连接到主机
- 右边是一个4090 48G魔改涡轮卡,插在京东999显卡坞上,USB4连接到主机
可以干啥:
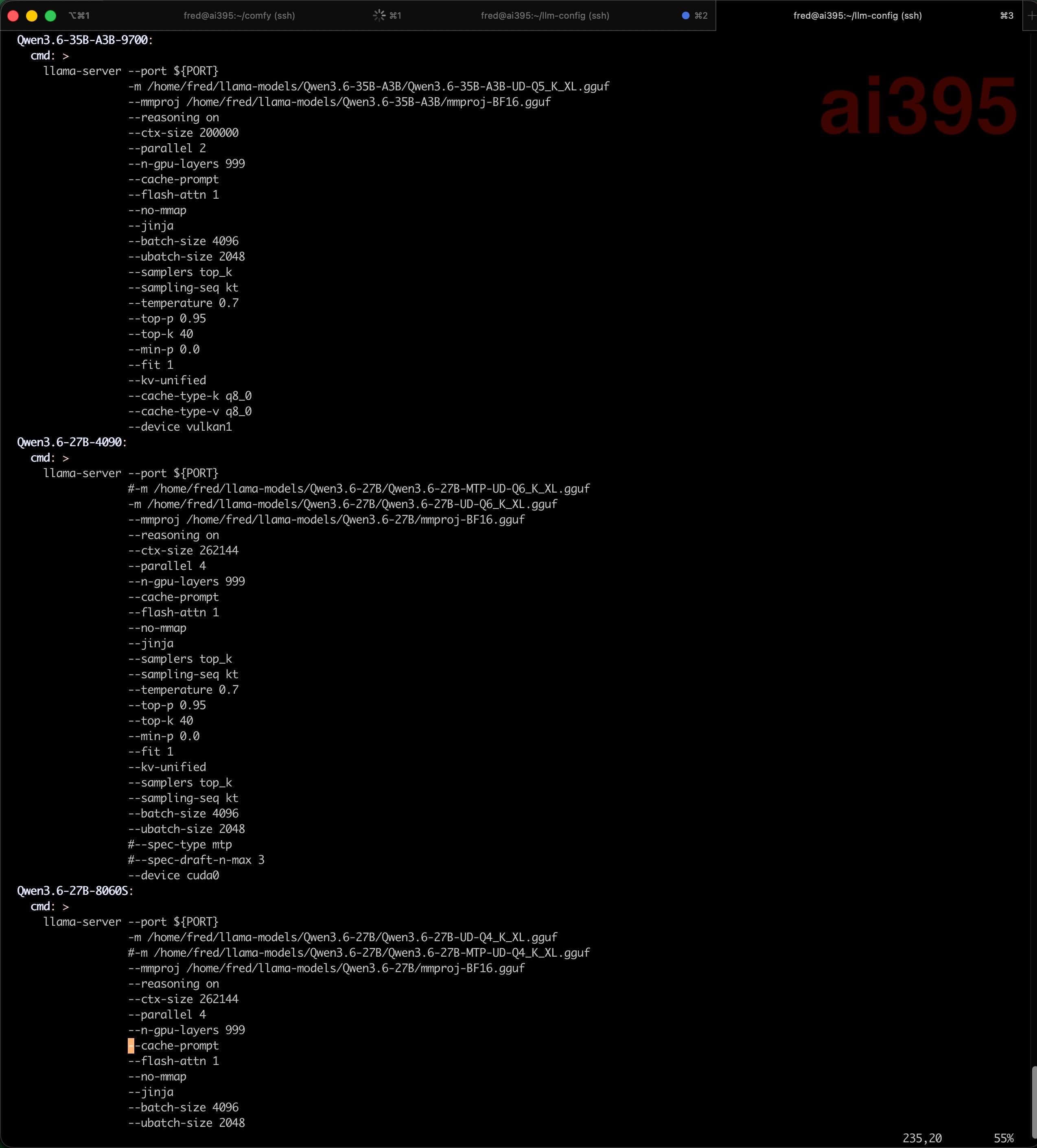
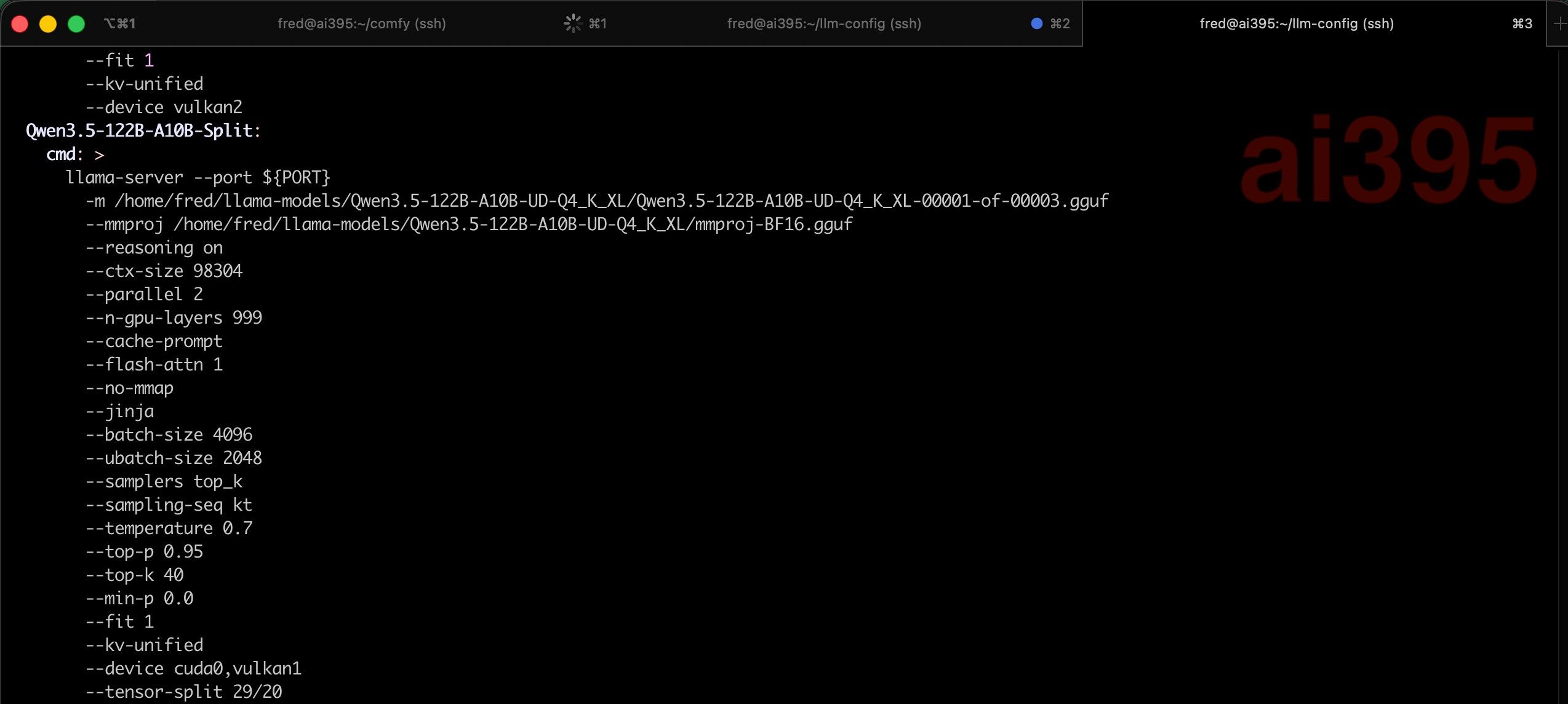
同时存在A卡、N卡、集成显卡(APU),一共有80G的VRAM,128G的UMA,可以跑这些组合:- llama.cpp 特殊编译选项(后面附),可以识别所有卡,可以跨卡用
-ts参数跑230B的量化大模型,速度还可以; - 可以在N卡上用vLLM跑Qwen3.6 27B Q6量化的模型,充分发挥vLLM的MTP功能,推理速度和Prefill速度都比llama.cpp更快;
- 可以在A卡、N卡上分别跑Comfy-UI;
- 主机AI MAX 395+的APU上因为内存大,可以跑一个Qwen3.5 122B的MoE模型,上下文短点的情况下速度也还可以。
- ……其他各种组合还可以发挥发挥
附llama.cpp编译参数
即让同一个llama.cpp即能识别A卡(ROCm设备),又能识别N卡(CUDA设备),还能用Vulkan通吃所有卡:cmake -S . -B build \ -DGGML_HIP=ON \ -DGGML_VULKAN=ON \ -DGGML_CUDA=ON \ -DCMAKE_CUDA_ARCHITECTURES=89 \ -DGGML_RPC=ON \ -DLLAMA_HIP_UMA=ON \ -DAMDGPU_TARGETS="gfx1030;gfx1031;gfx1151;gfx1201" \ -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc \ -DGGML_BACKEND_DL=ON \ -DGGML_NATIVE=OFF \ -DCMAKE_BUILD_TYPE=Release \ && cmake --build build -j$(nproc) \ && cmake --install build说明:关键点是查好自己显卡的代号,然后正确设置
CMAKE_CUDA_ARCHITECTURES,AMDGPU_TARGETS这几个宏。然后编译成功,用llama-cli --list-devices命令能看到自己的卡就说明成功了:fred@ai395:~$ llama-cli --list-devices ...... Available devices: CUDA0: NVIDIA GeForce RTX 4090 (48508 MiB, 558 MiB free) ROCm0: Radeon 8060S Graphics (126976 MiB, 99084 MiB free) ROCm1: AMD Radeon AI PRO R9700 (32624 MiB, 32556 MiB free) Vulkan0: NVIDIA GeForce RTX 4090 (49386 MiB, 782 MiB free) Vulkan1: AMD Radeon AI PRO R9700 (RADV GFX1201) (32624 MiB, 32566 MiB free) Vulkan2: Radeon 8060S Graphics (RADV GFX1151) (127488 MiB, 111400 MiB free)vLLM在N卡单跑Qwen3.6 27B Q6大模型的命令行:
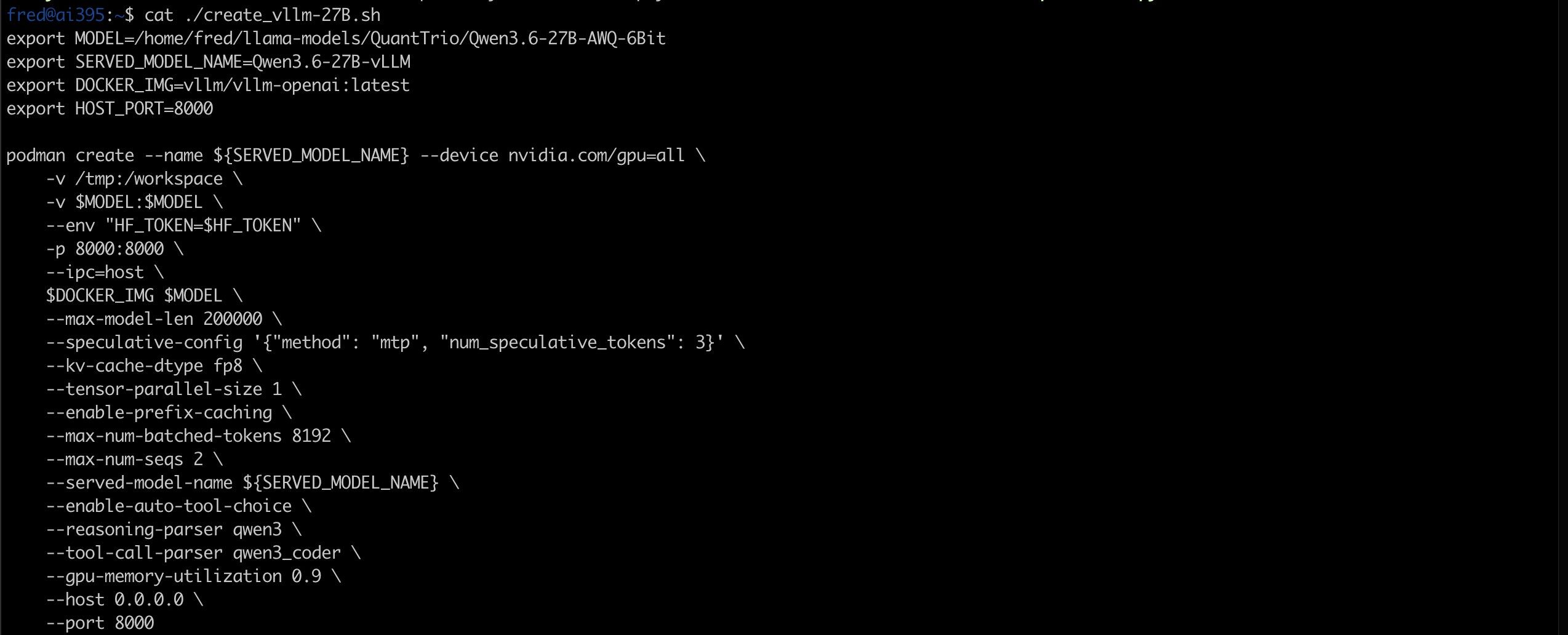
export MODEL=/home/fred/llama-models/QuantTrio/Qwen3.6-27B-AWQ-6Bit export SERVED_MODEL_NAME=Qwen3.6-27B-vLLM export DOCKER_IMG=vllm/vllm-openai:latest export HOST_PORT=8000 podman run --name ${SERVED_MODEL_NAME} --device nvidia.com/gpu=all \ -v /tmp:/workspace \ -v $MODEL:$MODEL \ --env "HF_TOKEN=$HF_TOKEN" \ -p 8000:8000 \ --ipc=host \ $DOCKER_IMG $MODEL \ --max-model-len 200000 \ --speculative-config '{"method": "mtp", "num_speculative_tokens": 3}' \ --kv-cache-dtype fp8 \ --tensor-parallel-size 1 \ --enable-prefix-caching \ --max-num-batched-tokens 8192 \ --max-num-seqs 2 \ --served-model-name ${SERVED_MODEL_NAME} \ --enable-auto-tool-choice \ --reasoning-parser qwen3 \ --tool-call-parser qwen3_coder \ --gpu-memory-utilization 0.9 \ --host 0.0.0.0 \ --port 8000其他说明
- 模型可以全速跑,但前提是全量的模型必须能fit进某一个卡的VRAM,这样USB4不会造成降速。
- 用llama.cpp的
-ts选项跨卡跑模型,可以充分利用各卡的显存,由于USB4的时延比PCIE高,所以性能稍有损失,但不大,因为跨卡数据交换量不大且交换并不频繁。 - vLLM不可跨A卡和N卡跑Tensor Parallel,只能跨多个A卡和多个N卡(因为底层的PyTorch只能支持一个版本)。
- 我在llama.cpp和vLLM前端顶了一个可以自动切换模型的代理工具
llama-swap,定义好之后用起来是很方便的。 - 操作系统是Fedora Linux 43,驱动跟着社区更新就行(时不时的
dnf update一下)。 - 要懂点Linux,不然不要这么玩,还是要懂些技术才能搞定的。
秀完了
这一套东西,加起来还是得5万左右。现在AI MAX 395又涨价了,可能现在得5万5左右了。目前还只是纯玩,平时实在没时间琢磨怎么用它赚钱。 -
从左到右:
- 主机是AI MAX 395+ 128G统一内存
- 中间是一个霸气的绿联显卡坞插了一个R9700,USB4连接到主机
- 右边是一个4090 48G魔改涡轮卡,插在京东999显卡坞上,USB4连接到主机
可以干啥:
同时存在A卡、N卡、集成显卡(APU),一共有80G的VRAM,128G的UMA,可以跑这些组合:- llama.cpp 特殊编译选项(后面附),可以识别所有卡,可以跨卡用
-ts参数跑230B的量化大模型,速度还可以; - 可以在N卡上用vLLM跑Qwen3.6 27B Q6量化的模型,充分发挥vLLM的MTP功能,推理速度和Prefill速度都比llama.cpp更快;
- 可以在A卡、N卡上分别跑Comfy-UI;
- 主机AI MAX 395+的APU上因为内存大,可以跑一个Qwen3.5 122B的MoE模型,上下文短点的情况下速度也还可以。
- ……其他各种组合还可以发挥发挥
附llama.cpp编译参数
即让同一个llama.cpp即能识别A卡(ROCm设备),又能识别N卡(CUDA设备),还能用Vulkan通吃所有卡:cmake -S . -B build \ -DGGML_HIP=ON \ -DGGML_VULKAN=ON \ -DGGML_CUDA=ON \ -DCMAKE_CUDA_ARCHITECTURES=89 \ -DGGML_RPC=ON \ -DLLAMA_HIP_UMA=ON \ -DAMDGPU_TARGETS="gfx1030;gfx1031;gfx1151;gfx1201" \ -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc \ -DGGML_BACKEND_DL=ON \ -DGGML_NATIVE=OFF \ -DCMAKE_BUILD_TYPE=Release \ && cmake --build build -j$(nproc) \ && cmake --install build说明:关键点是查好自己显卡的代号,然后正确设置
CMAKE_CUDA_ARCHITECTURES,AMDGPU_TARGETS这几个宏。然后编译成功,用llama-cli --list-devices命令能看到自己的卡就说明成功了:fred@ai395:~$ llama-cli --list-devices ...... Available devices: CUDA0: NVIDIA GeForce RTX 4090 (48508 MiB, 558 MiB free) ROCm0: Radeon 8060S Graphics (126976 MiB, 99084 MiB free) ROCm1: AMD Radeon AI PRO R9700 (32624 MiB, 32556 MiB free) Vulkan0: NVIDIA GeForce RTX 4090 (49386 MiB, 782 MiB free) Vulkan1: AMD Radeon AI PRO R9700 (RADV GFX1201) (32624 MiB, 32566 MiB free) Vulkan2: Radeon 8060S Graphics (RADV GFX1151) (127488 MiB, 111400 MiB free)vLLM在N卡单跑Qwen3.6 27B Q6大模型的命令行:
export MODEL=/home/fred/llama-models/QuantTrio/Qwen3.6-27B-AWQ-6Bit export SERVED_MODEL_NAME=Qwen3.6-27B-vLLM export DOCKER_IMG=vllm/vllm-openai:latest export HOST_PORT=8000 podman run --name ${SERVED_MODEL_NAME} --device nvidia.com/gpu=all \ -v /tmp:/workspace \ -v $MODEL:$MODEL \ --env "HF_TOKEN=$HF_TOKEN" \ -p 8000:8000 \ --ipc=host \ $DOCKER_IMG $MODEL \ --max-model-len 200000 \ --speculative-config '{"method": "mtp", "num_speculative_tokens": 3}' \ --kv-cache-dtype fp8 \ --tensor-parallel-size 1 \ --enable-prefix-caching \ --max-num-batched-tokens 8192 \ --max-num-seqs 2 \ --served-model-name ${SERVED_MODEL_NAME} \ --enable-auto-tool-choice \ --reasoning-parser qwen3 \ --tool-call-parser qwen3_coder \ --gpu-memory-utilization 0.9 \ --host 0.0.0.0 \ --port 8000其他说明
- 模型可以全速跑,但前提是全量的模型必须能fit进某一个卡的VRAM,这样USB4不会造成降速。
- 用llama.cpp的
-ts选项跨卡跑模型,可以充分利用各卡的显存,由于USB4的时延比PCIE高,所以性能稍有损失,但不大,因为跨卡数据交换量不大且交换并不频繁。 - vLLM不可跨A卡和N卡跑Tensor Parallel,只能跨多个A卡和多个N卡(因为底层的PyTorch只能支持一个版本)。
- 我在llama.cpp和vLLM前端顶了一个可以自动切换模型的代理工具
llama-swap,定义好之后用起来是很方便的。 - 操作系统是Fedora Linux 43,驱动跟着社区更新就行(时不时的
dnf update一下)。 - 要懂点Linux,不然不要这么玩,还是要懂些技术才能搞定的。
秀完了
这一套东西,加起来还是得5万左右。现在AI MAX 395又涨价了,可能现在得5万5左右了。目前还只是纯玩,平时实在没时间琢磨怎么用它赚钱。 -
@Fred 这一套跟 6000 pro 96g 比起来如何呢?
@Fred 这一套跟 6000 pro 96g 比起来如何呢?
这两者相比属于是用法拉利对比大众高尔夫GTI了。PRO 6000单卡大显存,N卡最新架构,算力比5090略强,从生态,到实际的性能,都比这3货加起来还强不少。但我没法给你准确的数字,只知道肯定是PRO 6000强。
考虑价格,我这套就算5万5吧,PRO 6000单卡7万,加配个主机,稍微配寒碜一点的主机估计总共8万5拿下吧。我觉得3万差价基本上就是两者性能上的差距。
但是需要知道一点,我这个大众高尔夫GTI也不是一无是处,PRO 6000单卡跑230B大模型估计够呛,如果还想所有层都在显存里,更是不足够的。但我这个3个GPU加起来就可以跑出来不错的感受。 -
@Fred 这一套跟 6000 pro 96g 比起来如何呢?
这两者相比属于是用法拉利对比大众高尔夫GTI了。PRO 6000单卡大显存,N卡最新架构,算力比5090略强,从生态,到实际的性能,都比这3货加起来还强不少。但我没法给你准确的数字,只知道肯定是PRO 6000强。
考虑价格,我这套就算5万5吧,PRO 6000单卡7万,加配个主机,稍微配寒碜一点的主机估计总共8万5拿下吧。我觉得3万差价基本上就是两者性能上的差距。
但是需要知道一点,我这个大众高尔夫GTI也不是一无是处,PRO 6000单卡跑230B大模型估计够呛,如果还想所有层都在显存里,更是不足够的。但我这个3个GPU加起来就可以跑出来不错的感受。 -
从左到右:
- 主机是AI MAX 395+ 128G统一内存
- 中间是一个霸气的绿联显卡坞插了一个R9700,USB4连接到主机
- 右边是一个4090 48G魔改涡轮卡,插在京东999显卡坞上,USB4连接到主机
可以干啥:
同时存在A卡、N卡、集成显卡(APU),一共有80G的VRAM,128G的UMA,可以跑这些组合:- llama.cpp 特殊编译选项(后面附),可以识别所有卡,可以跨卡用
-ts参数跑230B的量化大模型,速度还可以; - 可以在N卡上用vLLM跑Qwen3.6 27B Q6量化的模型,充分发挥vLLM的MTP功能,推理速度和Prefill速度都比llama.cpp更快;
- 可以在A卡、N卡上分别跑Comfy-UI;
- 主机AI MAX 395+的APU上因为内存大,可以跑一个Qwen3.5 122B的MoE模型,上下文短点的情况下速度也还可以。
- ……其他各种组合还可以发挥发挥
附llama.cpp编译参数
即让同一个llama.cpp即能识别A卡(ROCm设备),又能识别N卡(CUDA设备),还能用Vulkan通吃所有卡:cmake -S . -B build \ -DGGML_HIP=ON \ -DGGML_VULKAN=ON \ -DGGML_CUDA=ON \ -DCMAKE_CUDA_ARCHITECTURES=89 \ -DGGML_RPC=ON \ -DLLAMA_HIP_UMA=ON \ -DAMDGPU_TARGETS="gfx1030;gfx1031;gfx1151;gfx1201" \ -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc \ -DGGML_BACKEND_DL=ON \ -DGGML_NATIVE=OFF \ -DCMAKE_BUILD_TYPE=Release \ && cmake --build build -j$(nproc) \ && cmake --install build说明:关键点是查好自己显卡的代号,然后正确设置
CMAKE_CUDA_ARCHITECTURES,AMDGPU_TARGETS这几个宏。然后编译成功,用llama-cli --list-devices命令能看到自己的卡就说明成功了:fred@ai395:~$ llama-cli --list-devices ...... Available devices: CUDA0: NVIDIA GeForce RTX 4090 (48508 MiB, 558 MiB free) ROCm0: Radeon 8060S Graphics (126976 MiB, 99084 MiB free) ROCm1: AMD Radeon AI PRO R9700 (32624 MiB, 32556 MiB free) Vulkan0: NVIDIA GeForce RTX 4090 (49386 MiB, 782 MiB free) Vulkan1: AMD Radeon AI PRO R9700 (RADV GFX1201) (32624 MiB, 32566 MiB free) Vulkan2: Radeon 8060S Graphics (RADV GFX1151) (127488 MiB, 111400 MiB free)vLLM在N卡单跑Qwen3.6 27B Q6大模型的命令行:
export MODEL=/home/fred/llama-models/QuantTrio/Qwen3.6-27B-AWQ-6Bit export SERVED_MODEL_NAME=Qwen3.6-27B-vLLM export DOCKER_IMG=vllm/vllm-openai:latest export HOST_PORT=8000 podman run --name ${SERVED_MODEL_NAME} --device nvidia.com/gpu=all \ -v /tmp:/workspace \ -v $MODEL:$MODEL \ --env "HF_TOKEN=$HF_TOKEN" \ -p 8000:8000 \ --ipc=host \ $DOCKER_IMG $MODEL \ --max-model-len 200000 \ --speculative-config '{"method": "mtp", "num_speculative_tokens": 3}' \ --kv-cache-dtype fp8 \ --tensor-parallel-size 1 \ --enable-prefix-caching \ --max-num-batched-tokens 8192 \ --max-num-seqs 2 \ --served-model-name ${SERVED_MODEL_NAME} \ --enable-auto-tool-choice \ --reasoning-parser qwen3 \ --tool-call-parser qwen3_coder \ --gpu-memory-utilization 0.9 \ --host 0.0.0.0 \ --port 8000其他说明
- 模型可以全速跑,但前提是全量的模型必须能fit进某一个卡的VRAM,这样USB4不会造成降速。
- 用llama.cpp的
-ts选项跨卡跑模型,可以充分利用各卡的显存,由于USB4的时延比PCIE高,所以性能稍有损失,但不大,因为跨卡数据交换量不大且交换并不频繁。 - vLLM不可跨A卡和N卡跑Tensor Parallel,只能跨多个A卡和多个N卡(因为底层的PyTorch只能支持一个版本)。
- 我在llama.cpp和vLLM前端顶了一个可以自动切换模型的代理工具
llama-swap,定义好之后用起来是很方便的。 - 操作系统是Fedora Linux 43,驱动跟着社区更新就行(时不时的
dnf update一下)。 - 要懂点Linux,不然不要这么玩,还是要懂些技术才能搞定的。
秀完了
这一套东西,加起来还是得5万左右。现在AI MAX 395又涨价了,可能现在得5万5左右了。目前还只是纯玩,平时实在没时间琢磨怎么用它赚钱。来补些图:
图1:注意看,在下面一层有一个关键设备:大疆POWER 1000。当成一个UPS来用,都花了这么多小钱钱,买了卡买了机器,不要吝啬把电源配得保险一些,别因为电源闪断,或者电压不稳或者突然断电,烧了卡之后还要找修显卡的张哥,就麻烦大了。
图2:4090显卡,以及狗东999的显卡坞,USB4和Ocuulink双接口,自带800w电源,很不错。但两个特别提醒:
- 不要买2个这种同样显卡坞插到同一台主机。因为它有个白痴低级失误:它的雷电UUID好像是固定的,没法改,每个显卡坞都是一样的UUID。因此在Linux下,只能识别一个这种显卡坞。当时我本来是买了2个这个显卡坞,但第二个始终不识别,这个问题当时折腾我好久。最后买了退,退了换,最后换了品牌,有了不同的TB UUID才搞定。着着实实享受了一把狗东的售后服务。
- 4090和R9700,都是12PIN+4PIN的PCI-E电源线,这个显卡坞不带这种线,只带3个8PIN线,需要自己买转接,或者显卡如果带也行。
图3:霸气的绿联显卡坞,自带850W金牌电源,自带12PIN+4PIN,自带8PIN,通吃一切显卡。缺点是不便宜啊,显卡坞2000+的就不算便宜了:
图4:颜值在线的R9700,这卡是真好看。但它在显卡坞上有个毛病要注意:如果主机不开机,它的风扇会狂转。
图5图6:主机AI MAX 395,零刻的128G版本,刚去查了一下狗东,狗日的涨价到21000了!我当时买的时候14000。后面带2个10G网口,2个USB4 type-c,前置带指纹解锁(Windows才能用)。我插了2个显卡坞,都是type-c,后面看着也不拥挤,还好。我这个机器是Linux无头服务器,也不用它打游戏啥的,因此随意插了一个hdmi的线到显示器。干干净净的,不挤。
总结一下几个坑:
- 不要买2个同样型号的狗东999显卡坞
- R9700外置,如果主机不开,风扇会狂转,此时只能自己去关显卡坞的电源
- 尽量上个UPS,对你的几万块的资产稍微好点
-
来补些图:
图1:注意看,在下面一层有一个关键设备:大疆POWER 1000。当成一个UPS来用,都花了这么多小钱钱,买了卡买了机器,不要吝啬把电源配得保险一些,别因为电源闪断,或者电压不稳或者突然断电,烧了卡之后还要找修显卡的张哥,就麻烦大了。
图2:4090显卡,以及狗东999的显卡坞,USB4和Ocuulink双接口,自带800w电源,很不错。但两个特别提醒:
- 不要买2个这种同样显卡坞插到同一台主机。因为它有个白痴低级失误:它的雷电UUID好像是固定的,没法改,每个显卡坞都是一样的UUID。因此在Linux下,只能识别一个这种显卡坞。当时我本来是买了2个这个显卡坞,但第二个始终不识别,这个问题当时折腾我好久。最后买了退,退了换,最后换了品牌,有了不同的TB UUID才搞定。着着实实享受了一把狗东的售后服务。
- 4090和R9700,都是12PIN+4PIN的PCI-E电源线,这个显卡坞不带这种线,只带3个8PIN线,需要自己买转接,或者显卡如果带也行。
图3:霸气的绿联显卡坞,自带850W金牌电源,自带12PIN+4PIN,自带8PIN,通吃一切显卡。缺点是不便宜啊,显卡坞2000+的就不算便宜了:
图4:颜值在线的R9700,这卡是真好看。但它在显卡坞上有个毛病要注意:如果主机不开机,它的风扇会狂转。
图5图6:主机AI MAX 395,零刻的128G版本,刚去查了一下狗东,狗日的涨价到21000了!我当时买的时候14000。后面带2个10G网口,2个USB4 type-c,前置带指纹解锁(Windows才能用)。我插了2个显卡坞,都是type-c,后面看着也不拥挤,还好。我这个机器是Linux无头服务器,也不用它打游戏啥的,因此随意插了一个hdmi的线到显示器。干干净净的,不挤。
总结一下几个坑:
- 不要买2个同样型号的狗东999显卡坞
- R9700外置,如果主机不开,风扇会狂转,此时只能自己去关显卡坞的电源
- 尽量上个UPS,对你的几万块的资产稍微好点
-
来补些图:
图1:注意看,在下面一层有一个关键设备:大疆POWER 1000。当成一个UPS来用,都花了这么多小钱钱,买了卡买了机器,不要吝啬把电源配得保险一些,别因为电源闪断,或者电压不稳或者突然断电,烧了卡之后还要找修显卡的张哥,就麻烦大了。
图2:4090显卡,以及狗东999的显卡坞,USB4和Ocuulink双接口,自带800w电源,很不错。但两个特别提醒:
- 不要买2个这种同样显卡坞插到同一台主机。因为它有个白痴低级失误:它的雷电UUID好像是固定的,没法改,每个显卡坞都是一样的UUID。因此在Linux下,只能识别一个这种显卡坞。当时我本来是买了2个这个显卡坞,但第二个始终不识别,这个问题当时折腾我好久。最后买了退,退了换,最后换了品牌,有了不同的TB UUID才搞定。着着实实享受了一把狗东的售后服务。
- 4090和R9700,都是12PIN+4PIN的PCI-E电源线,这个显卡坞不带这种线,只带3个8PIN线,需要自己买转接,或者显卡如果带也行。
图3:霸气的绿联显卡坞,自带850W金牌电源,自带12PIN+4PIN,自带8PIN,通吃一切显卡。缺点是不便宜啊,显卡坞2000+的就不算便宜了:
图4:颜值在线的R9700,这卡是真好看。但它在显卡坞上有个毛病要注意:如果主机不开机,它的风扇会狂转。
图5图6:主机AI MAX 395,零刻的128G版本,刚去查了一下狗东,狗日的涨价到21000了!我当时买的时候14000。后面带2个10G网口,2个USB4 type-c,前置带指纹解锁(Windows才能用)。我插了2个显卡坞,都是type-c,后面看着也不拥挤,还好。我这个机器是Linux无头服务器,也不用它打游戏啥的,因此随意插了一个hdmi的线到显示器。干干净净的,不挤。
总结一下几个坑:
- 不要买2个同样型号的狗东999显卡坞
- R9700外置,如果主机不开,风扇会狂转,此时只能自己去关显卡坞的电源
- 尽量上个UPS,对你的几万块的资产稍微好点
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
-
@fred 我零刻gti15用的零刻600w显卡坞,就2个8pin,请教个接7900xtx这3个8pin的方案,豆包和卖家说价买个1分2的线插第二个8pin口,不要求性能发挥满,只要不烧卡就行,感谢!

-
@fred 我零刻gti15用的零刻600w显卡坞,就2个8pin,请教个接7900xtx这3个8pin的方案,豆包和卖家说价买个1分2的线插第二个8pin口,不要求性能发挥满,只要不烧卡就行,感谢!
@fred 我零刻gti15用的零刻600w显卡坞,就2个8pin,请教个接7900xtx这3个8pin的方案,豆包和卖家说价买个1分2的线插第二个8pin口,不要求性能发挥满,只要不烧卡就行,感谢!
还是稳妥起见,显卡坞有3个8P才保险。你看这些个帖子吧,很多人反对这样做:https://forums.tomshardware.com/threads/can-i-use-a-3-x-8-pin-7900-xtx-with-only-2-x-8-pins-connected-to-it.3809019/
https://linustechtips.com/topic/1475161-is-rx-7900-xtx-able-to-work-from-2-pcie-cables-instead-of-3/