
分享自己的經驗 # 7900 XTX 本地 LLM 優化實測報告(Qwen3.6-27B)
-
7900 XTX 本地 LLM 優化實測報告(Qwen3.6-27B)
硬體: AMD RX 7900 XTX 24GB / AMD Ryzen 9 7950X / Windows 11 原生
用途: Hermes Agent、加密貨幣分析、查資料、opencode/pi.dev 本地 API
推論框架: llama.cpp Vulkan(Windows Native)
優化前 vs 優化後
指標 優化前 優化後 提升 Prefill(長 context 14k token) ~273 t/s ~530 t/s +94% TG 生成速度(Hermes) ~37 t/s 62–80 t/s +68~116% TG 生成速度(一般對話) ~37 t/s ~42 t/s +14% Qwen3 thinking 卡死問題 偶發(8000+ token 無限生成) 已解決 
VRAM 佔用 ~18.7 GB ~18.7 GB 不變
優化一:KV Cache q8_0 → q4_0
改動:
run.bat和start-all.bat的-ctk q8_0 -ctv q8_0改成-ctk q4_0 -ctv q4_0效果:
- Prefill:273 t/s → 730 t/s(+167%)
- TG:37 t/s → 42 t/s(+14%)
- 品質:差異可忽略(q4_0 vs q8_0 KV cache 品質損失極小)
原因: Vulkan 後端的 q8_0 KV cache 有嚴重 Prefill 瓶頸,q4_0 就沒有這個問題。
這是最簡單、最有效的改動,不需要換模型或換 binary。
優化二:關閉 Qwen3 Thinking(--reasoning off)
改動:
run.bat加上--reasoning off效果: 解決 Qwen3.6 偶發性卡死問題。
原因: Hermes Gateway 送的請求會觸發 Qwen3 的 thinking mode,budget 預設為 INT_MAX(無限),
導致 server 有時生成 8000+ 個 thinking token 停不下來,後續所有請求全部卡在 queue 裡。
優化三:MTP(Multi-Token Prediction)升級
升級內容
- Binary: 從 PR #22673 源碼編譯(llama.cpp MTP 分支,尚未合入主線)
- 模型: 換成帶 MTP 層的
Qwen3.6-27B-Q4_K_M-mtp.gguf(15.8 GB,froggeric/Qwen3.6-27B-MTP-GGUF) - 新增參數:
--spec-type draft-mtp --spec-draft-n-max 3 -fa 1 - 注意: 參數名稱是
draft-mtp,不是mtp(新版 PR 已改名)
實測速度(Hermes 結構化輸出)
請求 Prefill TG MTP 接受率 系統提示暖機(14k tokens) 531 t/s 62.8 t/s 95.6% 第 1 次 Telegram 指令 398 t/s 60.0 t/s 72.7% 第 2 次 Telegram 指令 453 t/s 73.6 t/s 98.5% 第 3 次 Telegram 指令 469 t/s 59.5 t/s 72.6% 直接 API 測試(短句) — 79.9 t/s — 重要:MTP 加速效果依任務而定
場景 接受率 TG 速度 說明 Hermes 結構化輸出(工具呼叫、JSON) 72–100% 60–80 t/s 最佳 加密貨幣分析、查資料(固定格式) 預估 70%+ 60–75 t/s 很好 Web UI 自由對話 30–45% 35–49 t/s 效果有限 結論: MTP 對結構化輸出效果顯著(+68~116%),自由對話效果有限甚至可能略慢。
最終啟動設定
run-mtp.bat(只跑 llama-server,測試用)
@echo off C:\llama-cpp-mtp\build\bin\Release\llama-server.exe ^ -m C:\llama-cpp\Qwen3.6-27B-Q4_K_M-mtp.gguf ^ --device Vulkan0 -ngl 999 -c 65536 ^ -ctk q4_0 -ctv q4_0 -np 1 ^ --spec-type draft-mtp --spec-draft-n-max 3 ^ --reasoning off -fa 1 ^ --port 8080 --host 0.0.0.0 pausestart-all-mtp.bat(完整啟動:llama-server + Hermes + 暖機)
@echo off set "H_EXE=C:\Users\jaran\AppData\Local\hermes\hermes-agent\venv\Scripts\hermes.exe" set "L_EXE=C:\llama-cpp-mtp\build\bin\Release\llama-server.exe" set "M_PATH=C:\llama-cpp\Qwen3.6-27B-Q4_K_M-mtp.gguf" set "H_HOME=C:\Users\jaran\AppData\Local\hermes" set PATH=C:\llama-cpp-mtp\build\bin\Release;%PATH% echo [STEP 1] Launching llama-server (MTP)... start "llama-server-mtp" cmd /k "%L_EXE% -m %M_PATH% --device Vulkan0 -ngl 999 -c 64000 -ctk q4_0 -ctv q4_0 -np 1 --spec-type draft-mtp --spec-draft-n-max 3 -fa 1 --reasoning off --port 8080 --host 127.0.0.1" timeout /t 8 echo [STEP 2] Launching Hermes Gateway... start "hermes-gateway" cmd /k "set HERMES_HOME=%H_HOME%&& set HERMES_GIT_BASH_PATH=C:\Program Files\Git\bin\bash.exe&& %H_EXE% gateway run --replace" timeout /t 5 echo [STEP 3] Running Warmup Script... powershell -ExecutionPolicy Bypass -File "%H_HOME%\scripts\warmup.ps1" echo. echo ======================================================= echo SYSTEM READY [MTP Mode: draft-mtp, n-max 3] echo ======================================================= pause
踩坑紀錄
- BITS Transfer 不支援 HuggingFace redirect → 改用
curl.exe -L -C -(支援斷點續傳) - Vulkan SDK 裝好但 cmake 找不到 → 需手動
set VULKAN_SDK=C:\VulkanSDK\1.4.350.0 - VS Build Tools 需手動勾選「使用 C++ 的桌面開發」 → winget 不帶 --override 只裝框架
- WebUI 編譯需 npm build → node/npm 裝好後先 build WebUI 再編 server
- MTP 參數名稱是
draft-mtp,不是mtp→ PR 更新後改名,文章版本較舊 - llama-common.dll 被 server 鎖住無法重編 → 先關 server 再 build
- Qwen3.6 是 hybrid SSM 架構 → KV cache 無法跨對話複用,每次都重跑全部 prompt(正常現象)
等待中的升級
- PR #22673 合併進主線後:不用自行編譯,直接下載官方 release binary 即可
- MTP Prefill 降速 bug 修復後:Prefill 速度可望進一步提升(目前 Prefill 略慢於非 MTP)
- Vulkan + TurboQuant 整合穩定後:Prefill 和 TG 都有進一步提升空間
測試日期:2026/05/14–15
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
感謝大神~我最開始也是聽你的建議從老特說一直跟到現在,台灣觀眾,買了7900XTX越玩越有心得,真的CP值很高,差點就買了3090坑..沒保又貴
-
昨天淘宝天猫入了全新的蓝宝白金版xtx,5500还能开专票,价格应该算不错了。赶紧来学习。
@chia-an-yang 请教lz现在用q4_0实用的上下文可以开到128k吗 -
@bin-flamebox 关于XTX + Qwen3.6-27B Q4_0跑128k上下文的问题,我帮你算一下:
VRAM需求估算:
- 模型权重:27B params × 0.5 bytes (Q4_0) ≈ 13.5GB
- KV Cache(128k上下文):27B × 128k × 2 bytes × 40层 × 0.5(GQA比例)≈ 约6-8GB
- 其他开销(buffer, overhead):约1-2GB
- 总计:约21-24GB
7900 XTX有24GB,所以Q4_0 + 128k上下文理论上是能塞下的,但非常极限。实际跑起来如果显存不够,llama.cpp会自动做部分offload到系统内存,速度会下降但不会崩。
建议:
- 如果一定要128k,试试Q4_K_M(比Q4_0略大但质量更好),或者降到Q3_K_L
- 64k上下文就轻松很多了,大概只需要16-18GB VRAM
- 另外注意:llama.cpp的MTP(Multi-Token Prediction)在XTX上开的话能提升tokens/s,但会额外吃点显存
用
llama-cli --no-display-prompt -m model.gguf -n 1 -c 131072可以先测试一下能不能正常加载,不崩就说明能跑。 -
昨天淘宝天猫入了全新的蓝宝白金版xtx,5500还能开专票,价格应该算不错了。赶紧来学习。
@chia-an-yang 请教lz现在用q4_0实用的上下文可以开到128k吗@bin-flamebox 5500很便宜,Q8可以开128k,研究下Turboquant,看下LLM区的几个置顶帖子,弄好了可以开256k。
-
@bin-flamebox 5500很便宜,Q8可以开128k,研究下Turboquant,看下LLM区的几个置顶帖子,弄好了可以开256k。
-
@terry 之前用n卡就是一直开Turboquant的,但现在看到各种说这卡开Turboquant prefill会严重慢,所以比较关心kv 开到Q4_0到底能稳定开到几k上下文。这两天显卡到了我也实测下
-
感谢,抄了作业,重新编译一下从原来~30TPS 提升到~40TPS,后面对coding微调了一下基本上确定大概eGPU +7900xtx能编程能测试了,等装上x99-cd3会来更新一下
# 7900 XTX (TB3 eGPU) + Qwen3.6-27B llama.cpp MTP — Bench Summary Hardware: AMD 7900 XTX via Razer Core X Chroma (TB3) + Beelink SER7 Tool: llama-benchy (Sherlock Holmes prompts, pp=512 tg=128 depth=[0, 4096]) | # | Config | tg mean | tg peak | tg @ d4096 | pp512 | Accept | |---|-------------------------------------------------|--------:|--------:|-----------:|------:|-------:| | 1 | Baseline (mainline, no MTP, temp=0.2) | 30.26 | 31.5 | 29.79 | 459 | n/a | | 2 | + MTP enabled (old PR build 9117) | 35.54 | 41.0 | 29.45 | 310 | 97% | | 3 | + Rebuilt PR to latest (9173, GDN rollback fix) | 37.25 | 45.5 | 34.70 | 353 | 57% | | 4 | + GPU power_dpm forced to `high` | 45.00 | 54.8 | 37.94 | 351 | 57% | | 5 | + Qwen "precise coding" sampling (current) | 37.32 | 46.8 | 31.75 | 368 | 54% | Cumulative gain vs original baseline: **+23% TG mean, +49% TG peak** (Step 4 alone is +49% / +74%; step 5 trades 16% speed for output quality) ## Variant comparisons (PR 9173 + perf=high) | Variant | tg mean | tg peak | tg @ d4096 | Accept | Verdict | |--------------------------------------------|--------:|--------:|-----------:|-------:|------------------| | froggeric Q4_K_M MTP (default) | 45.00 | 54.8 | 37.94 | 67% | ✅ Best mean | | unsloth Q4_K_M MTP | 36.13 | 44.0 | 34.68 | 49% | ❌ -19% TG | | unsloth UD-Q4_K_XL MTP | 43.65 | 53.0 | 33.01 | 60% | ≈ Tied, worse @d | | Chain: `ngram-mod,draft-mtp` (unsloth tip) | — | — | — | — | 🔴 CRASH (SSM) | ## Sampling A/B (froggeric MTP, n=2, perf=high) | Preset | temp / top_p / top_k / pp | tg mean | Accept@0 | Note | |-------------------------|---------------------------|--------:|---------:|---------------| | Fast (temp=0.2) | 0.2 / — / 20 / — | 45.00 | 67% | Fastest, repetitive | | Precise coding (active) | 0.6 / 0.95 / 20 / 0.0 | 37.32 | 54% | ★ Current default | | Non-thinking general | 0.7 / 0.8 / 20 / 1.5 | 36.26 | 57% | Best @ long ctx | | Thinking general | 1.0 / 0.95 / 20 / 1.5 | 37.68 | 59% | Avoid (no MTP gain) | ## Other paths evaluated and rejected | Option | Result on 7900 XTX | |------------------------------|----------------------------------------| | vLLM (ROCm) | ❌ -10–20%, no Qwen3.6 MTP, 4–8h install | | TurboQuant (Vulkan port) | ❌ Broken — 10 t/s, GPU util <30% | | DFlash / Hipfire | ❌ Crashes >4k context, no MTP | | MLC-LLM (Vulkan) | ⚠️ ~10 t/s slower, no MTP | ## Hardware ceiling vs realistic upgrades | Setup | Expected tg mean | |--------------------------------------------------|-----------------:| | Current (TB3 eGPU, all sw optimizations) | 37–45 | | OCuLink mod to Core X Chroma (~$80, 3h) | 52–55 | | Move GPU to X99 desktop (PCIe 3.0 x16) | 58–62 | | Modern AM5 + PCIe 4.0 x16 (blog reference) | 67 | **Current `start_server start`:** llama.cpp PR 9173 + froggeric MTP Q4_K_M + `--spec-type draft-mtp --spec-draft-n-max 2` + KV q4_0 + FA on + Qwen precise coding sampling + GPU perf=high.
-
系统 于 取消固定此主题
-
感谢,抄了作业,重新编译一下从原来~30TPS 提升到~40TPS,后面对coding微调了一下基本上确定大概eGPU +7900xtx能编程能测试了,等装上x99-cd3会来更新一下
# 7900 XTX (TB3 eGPU) + Qwen3.6-27B llama.cpp MTP — Bench Summary Hardware: AMD 7900 XTX via Razer Core X Chroma (TB3) + Beelink SER7 Tool: llama-benchy (Sherlock Holmes prompts, pp=512 tg=128 depth=[0, 4096]) | # | Config | tg mean | tg peak | tg @ d4096 | pp512 | Accept | |---|-------------------------------------------------|--------:|--------:|-----------:|------:|-------:| | 1 | Baseline (mainline, no MTP, temp=0.2) | 30.26 | 31.5 | 29.79 | 459 | n/a | | 2 | + MTP enabled (old PR build 9117) | 35.54 | 41.0 | 29.45 | 310 | 97% | | 3 | + Rebuilt PR to latest (9173, GDN rollback fix) | 37.25 | 45.5 | 34.70 | 353 | 57% | | 4 | + GPU power_dpm forced to `high` | 45.00 | 54.8 | 37.94 | 351 | 57% | | 5 | + Qwen "precise coding" sampling (current) | 37.32 | 46.8 | 31.75 | 368 | 54% | Cumulative gain vs original baseline: **+23% TG mean, +49% TG peak** (Step 4 alone is +49% / +74%; step 5 trades 16% speed for output quality) ## Variant comparisons (PR 9173 + perf=high) | Variant | tg mean | tg peak | tg @ d4096 | Accept | Verdict | |--------------------------------------------|--------:|--------:|-----------:|-------:|------------------| | froggeric Q4_K_M MTP (default) | 45.00 | 54.8 | 37.94 | 67% | ✅ Best mean | | unsloth Q4_K_M MTP | 36.13 | 44.0 | 34.68 | 49% | ❌ -19% TG | | unsloth UD-Q4_K_XL MTP | 43.65 | 53.0 | 33.01 | 60% | ≈ Tied, worse @d | | Chain: `ngram-mod,draft-mtp` (unsloth tip) | — | — | — | — | 🔴 CRASH (SSM) | ## Sampling A/B (froggeric MTP, n=2, perf=high) | Preset | temp / top_p / top_k / pp | tg mean | Accept@0 | Note | |-------------------------|---------------------------|--------:|---------:|---------------| | Fast (temp=0.2) | 0.2 / — / 20 / — | 45.00 | 67% | Fastest, repetitive | | Precise coding (active) | 0.6 / 0.95 / 20 / 0.0 | 37.32 | 54% | ★ Current default | | Non-thinking general | 0.7 / 0.8 / 20 / 1.5 | 36.26 | 57% | Best @ long ctx | | Thinking general | 1.0 / 0.95 / 20 / 1.5 | 37.68 | 59% | Avoid (no MTP gain) | ## Other paths evaluated and rejected | Option | Result on 7900 XTX | |------------------------------|----------------------------------------| | vLLM (ROCm) | ❌ -10–20%, no Qwen3.6 MTP, 4–8h install | | TurboQuant (Vulkan port) | ❌ Broken — 10 t/s, GPU util <30% | | DFlash / Hipfire | ❌ Crashes >4k context, no MTP | | MLC-LLM (Vulkan) | ⚠️ ~10 t/s slower, no MTP | ## Hardware ceiling vs realistic upgrades | Setup | Expected tg mean | |--------------------------------------------------|-----------------:| | Current (TB3 eGPU, all sw optimizations) | 37–45 | | OCuLink mod to Core X Chroma (~$80, 3h) | 52–55 | | Move GPU to X99 desktop (PCIe 3.0 x16) | 58–62 | | Modern AM5 + PCIe 4.0 x16 (blog reference) | 67 | **Current `start_server start`:** llama.cpp PR 9173 + froggeric MTP Q4_K_M + `--spec-type draft-mtp --spec-draft-n-max 2` + KV q4_0 + FA on + Qwen precise coding sampling + GPU perf=high.@ken-huang 讚讚讚 這張卡越來越超值 哈 請多多分享
-
@bin-flamebox 5500很便宜,Q8可以开128k,研究下Turboquant,看下LLM区的几个置顶帖子,弄好了可以开256k。
-
T terry 于 将此主题固定
-
@CHIA-AN-YANG 128K上下文确实会让7900 XTX的LLM推理速度明显下降,这是正常的。有两个方向可以优化:
-
精简上下文长度:如果不是必须128K,可以试试在llama.cpp里用
--ctx-size 32768限制到32K。对于大部分Agent任务(Hermes、代码补全),32K完全够用,Prefill速度能快3-4倍。只有在处理超长文档或完整代码库时才需要128K。 -
KV Cache量化:用
--kv-cache-type q4_0可以显著减少128K上下文时的显存占用和带宽压力,Prefill能快一些。7900 XTX的显存带宽虽然高,但128K的KV Cache体积很大,量化后缓存更紧凑。 -
MTP(Multi-Token Prediction):如果还没开,试试llama.cpp的MTP模式(需要支持MTP的模型,Qwen 3.6 27B支持),Token生成速度能提升20-30%。
总结:日常用32K上下文 + Q4 KV Cache,需要处理长文档时再切换到128K。这样既保证了日常速度,又保留了大上下文能力。
-
-
感謝大大無私分享

-
张 张鑫磊 于 引用了 此主题
-
謝謝樓主分享,我也成功在W7900上面跑Qwen3.6 27b Q4 MTP模型了,也掛了圖形識別模型成功。我用實際路徑的設定成功。輸出速度部分從原本的20t/s有增加到50t/s左右,從速度勉強可接受變成速度感覺順暢。更重要的是我也同時學會用llama.cpp在windows11架server了! 這軟體穩定度比lmstudio更好,模型載入速度超順暢。
@echo off
"D:\llama.cpp\build\bin\llama-server.exe" ^
-m "D:\llama.cpp\Qwen3.6-27B-MTP-Q4_K_M.gguf" ^
--mmproj "D:\llama.cpp\mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
--device Vulkan0 -ngl 999 -c 262144 ^
--temp 0.4 ^
--no-mmap ^
--api-key "*******" ^
-ctk q4_0 -ctv q4_0 -np 1 ^
--spec-type draft-mtp --spec-draft-n-max 3 ^
--reasoning off -fa 1 ^
--port 8081 --host 0.0.0.0
pause
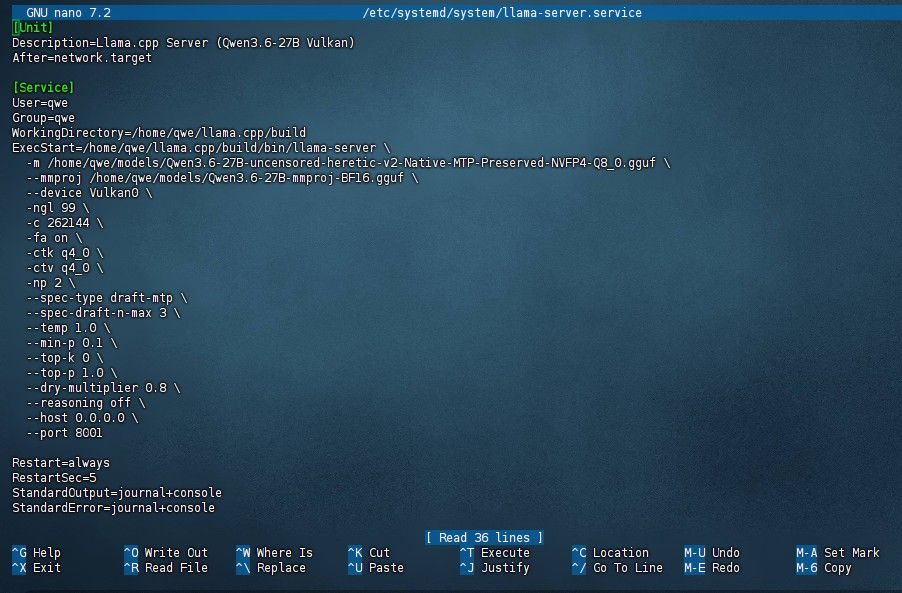 7900xtx 32G X99 大概40-50t/s
7900xtx 32G X99 大概40-50t/s