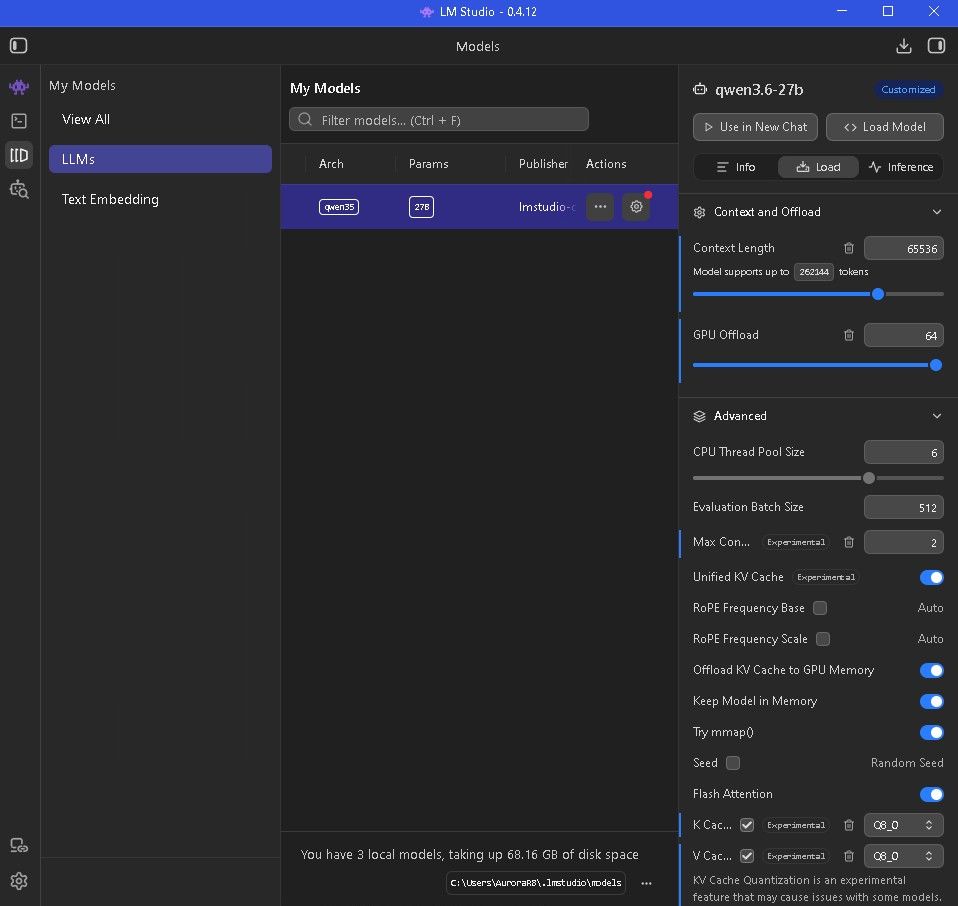
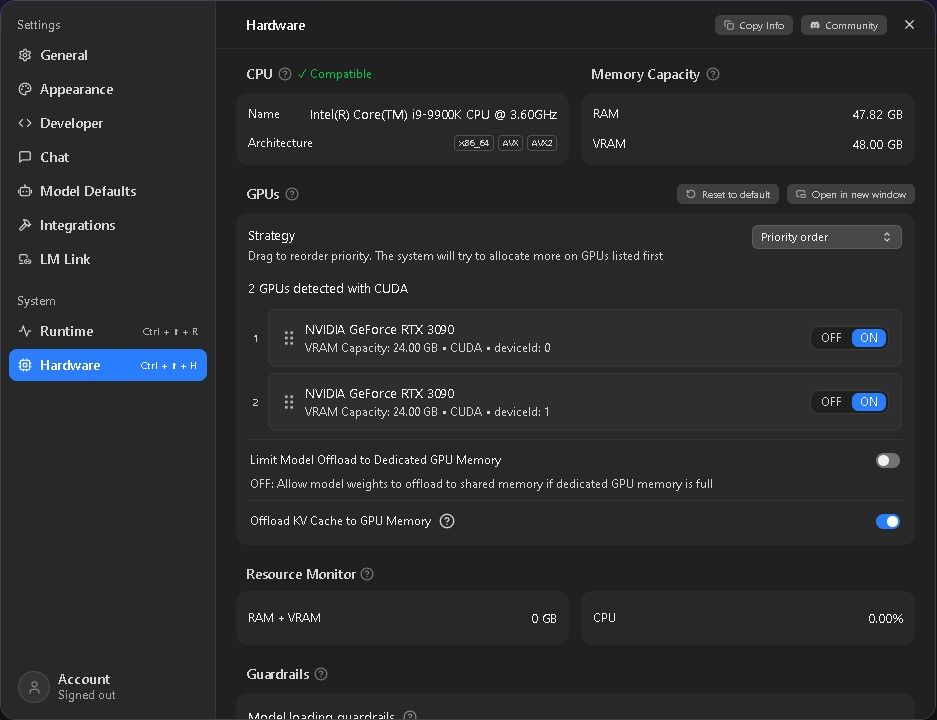
跟huananzi下单了 3090x2 + nvlink
-
先动起来吧,特殊时期,能省就省,其实跑LLM不需要NVLink,华南金牌的板子支持Peer to peer,Above 4G和Resize Bar,PICE3.0的带宽足够了,传输的就是一些计算张量而已。当然了NVLink速度非常奔放,延迟夜更低,代价不高可以玩玩。这是3090的特权,4090和5090都没有。
-
双卡配置我试过,我速度比单卡还要慢。看来还需要进一步优化。小弟技术烂 ~
Windows 系统搭配 LM Studio,且受限于 PCI SLI Link。
至于 NVLink,售价高达 400 到 500 美元,目前没计划入手。RTX 3090 单卡运行 Qwen 27B (Q4 量化) 时,速度约为 38 token/s。(Full Power, None Thinking/Reasoning, Voltage Curve GPU +100, Mem +500)
*** 功率限制 80% *** 内存温度保持低于 100°C *** Thinking/Reasoning
RTX 3090 双卡运行时,Q4 量化速度为 23~25 token/s;Q6 量化为 23 token/s;Q8 量化则在 22~23 token/s 之间。我目前的计划是使用单卡配置,但同时运行两个(Agent),每个Agent加载 Qwen 27B 模型进行对话。
-
@AresROC
这个也是我从ai了解到的. 如果没有nvlink 倒不如用r9700 或单卡.
原因是如果kv缓存需要用多过单卡vram 需要经过pcie 就比较慢了.
之前纠结的 r9700 有fp8 可能可以用超过3-5年 而且比较适合我我个人需要长上下文 60k 不够用 可能要超过100k
个人用习惯claude
而且现在的agent开局就20-30k context单卡3090 不考虑 turboquant, f16 kv 可能就只能支持50k
这个情况应该考虑r9700但是价钱很两张3090+nvlink 整机价钱都只是多过r9700一丢丢
考虑到2张r9700 没用 因为pcie3 比较慢(pcie5 整体硬件又贵不少)
2张3090+nvlink 长上下文 prefill 比较快 又便宜 所以选了3090只希望可以用上3年 如果可以去到4-5年就赚了
ai 也给了一个不知对错的解答:r9700 也不一定能撑4-5年 如果概率来说2-3年一张3090坏的成本 还低过3年后 r9700 坏的成本,可能ai 没考虑到3090 是矿卡...以上都是ai 问来的 希望大神纠错
-
双卡配置我试过,我速度比单卡还要慢。看来还需要进一步优化。小弟技术烂 ~
Windows 系统搭配 LM Studio,且受限于 PCI SLI Link。
至于 NVLink,售价高达 400 到 500 美元,目前没计划入手。RTX 3090 单卡运行 Qwen 27B (Q4 量化) 时,速度约为 38 token/s。(Full Power, None Thinking/Reasoning, Voltage Curve GPU +100, Mem +500)
*** 功率限制 80% *** 内存温度保持低于 100°C *** Thinking/Reasoning
RTX 3090 双卡运行时,Q4 量化速度为 23~25 token/s;Q6 量化为 23 token/s;Q8 量化则在 22~23 token/s 之间。我目前的计划是使用单卡配置,但同时运行两个(Agent),每个Agent加载 Qwen 27B 模型进行对话。
-
@AresROC
这个也是我从ai了解到的. 如果没有nvlink 倒不如用r9700 或单卡.
原因是如果kv缓存需要用多过单卡vram 需要经过pcie 就比较慢了.
之前纠结的 r9700 有fp8 可能可以用超过3-5年 而且比较适合我我个人需要长上下文 60k 不够用 可能要超过100k
个人用习惯claude
而且现在的agent开局就20-30k context单卡3090 不考虑 turboquant, f16 kv 可能就只能支持50k
这个情况应该考虑r9700但是价钱很两张3090+nvlink 整机价钱都只是多过r9700一丢丢
考虑到2张r9700 没用 因为pcie3 比较慢(pcie5 整体硬件又贵不少)
2张3090+nvlink 长上下文 prefill 比较快 又便宜 所以选了3090只希望可以用上3年 如果可以去到4-5年就赚了
ai 也给了一个不知对错的解答:r9700 也不一定能撑4-5年 如果概率来说2-3年一张3090坏的成本 还低过3年后 r9700 坏的成本,可能ai 没考虑到3090 是矿卡...以上都是ai 问来的 希望大神纠错
-
@applejuice 用VLLM或者SG-Lang TP,并行,怎么可能比单卡慢。3090有NV-Link是个优势。
@applejuice 用VLLM或者SG-Lang TP,并行,怎么可能比单卡慢。3090有NV-Link是个优势。
我知识有限问不到位
下次我会继续质问他 -
@terry 哎呀,对我傻傻的忘了要用vLLM tensor parallel size 2. SG-Lang还没用过 好像不可以用Q4 KV?就是看到 Windows L M Studio 还以为可以试一下。
-
@applejuice 翻车现场我懂
 华南金牌X99的PCIE槽间距确实是个坑——它通常是4槽间距(4slot),而NVLink桥大部分是2槽或3槽的。
华南金牌X99的PCIE槽间距确实是个坑——它通常是4槽间距(4slot),而NVLink桥大部分是2槽或3槽的。几个思路供参考:
-
换桥:如果确定间距是4slot,去找"四槽NVLink桥",某宝有卖(大概50-100元),虽然少但确实有。3090的NVLink桥规格标准一致,只要间距对上就行。
-
不用桥直接TP:先用vLLM或SGLang的tensor-parallel=2试试,PCIe 3.0 x16双向带宽约16GB/s,跑Qwen 27B这种级别的模型,通信开销其实没那么大。NVLink只是锦上添花,没有也能跑双卡TP。先跑起来再说,桥可以慢慢找。
-
柔性延长线:如果你手头有PCIE延长线或显卡竖装支架,可以调整一张卡的位置,让两张卡之间留出刚好能插桥的距离。不过走线会丑,但对性能没影响。
-
最省心方案:先不纠结桥,vLLM TP=2直接上,等以后有合适的桥再补。ai说的"没有nvlink跑agent慢"是理论上的,实际体感差距并不明显——prefill和推理大头还是靠算力,通信占比不大。
先跑起来最重要,船到桥头自然直

-
-
@applejuice R9700 什么方案 单卡还是双卡
-
@applejuice R9700 什么方案 单卡还是双卡
@Grayson-Ren 我最后选了3090 两张