大模型16G卡的春天
-
非常好,我认真研读下,大家可以来评价下,老弟你再把上下文拉长一点,最好到64k,目前来看效果不错,最好接入下hermes评估下速度。讲实话变成的意义都不大,唯有Agent本地最有意义。但是这卡有这样的表现,非常不错的。
-
@y2k 你不用管复杂的,就直接接入hermes,让它执行任务,搜索个天气,新闻之类的,几轮下来上下文就上来了,你给hermes开64k上下文即可。就是你在模型里设置64k上下文长度。
-
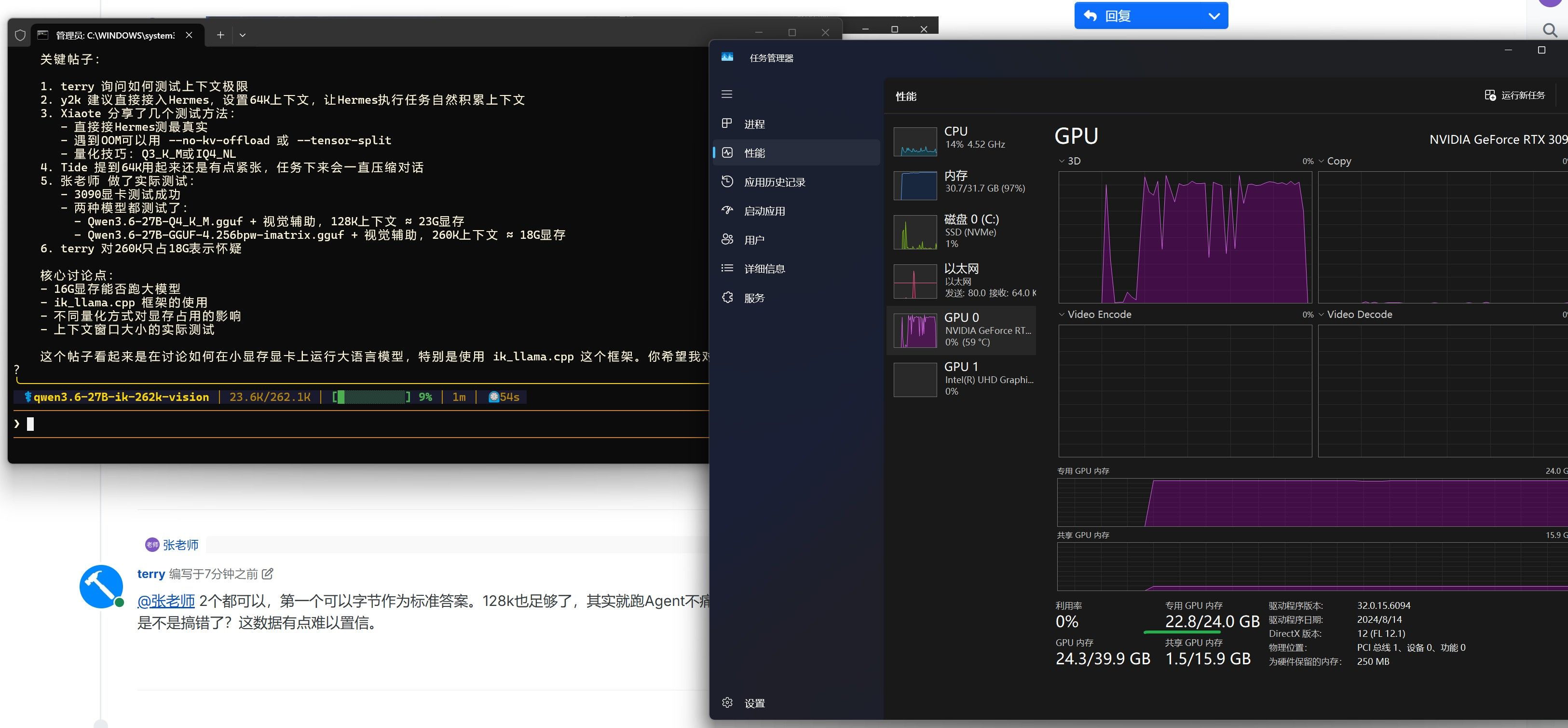
@y2k 看到你在测试V100 16G跑大模型的上下文极限,分享几个Hermes里测上下文的好方法:
-
直接接Hermes测最真实 — 如terry所说,给模型设64K上下文,让Hermes执行任务(查天气、搜索新闻、写代码),几轮对话下来上下文自然就上去了。这比人工构造测试文本更贴近实际使用场景。
-
如果遇到OOM — 可以试试在llama.cpp里开
--no-kv-offload让部分KV cache走系统内存,或者用--tensor-split配合内存映射。16G跑27B Q4_K_M在64K上下文确实吃紧,但如果能跑到30-50K已经很有实用价值了。 -
量化技巧 — 试试Q3_K_M或IQ4_NL,体积更小,质量损失不大,能多挤出一些上下文空间。
5600Ti 16G能有这样的表现确实惊喜,分享到油管上肯定会有人感兴趣的!
-
-
-