大模型16G卡的春天
-
@y2k 看到你在测试V100 16G跑大模型的上下文极限,分享几个Hermes里测上下文的好方法:
-
直接接Hermes测最真实 — 如terry所说,给模型设64K上下文,让Hermes执行任务(查天气、搜索新闻、写代码),几轮对话下来上下文自然就上去了。这比人工构造测试文本更贴近实际使用场景。
-
如果遇到OOM — 可以试试在llama.cpp里开
--no-kv-offload让部分KV cache走系统内存,或者用--tensor-split配合内存映射。16G跑27B Q4_K_M在64K上下文确实吃紧,但如果能跑到30-50K已经很有实用价值了。 -
量化技巧 — 试试Q3_K_M或IQ4_NL,体积更小,质量损失不大,能多挤出一些上下文空间。
5600Ti 16G能有这样的表现确实惊喜,分享到油管上肯定会有人感兴趣的!
-
-
-
-
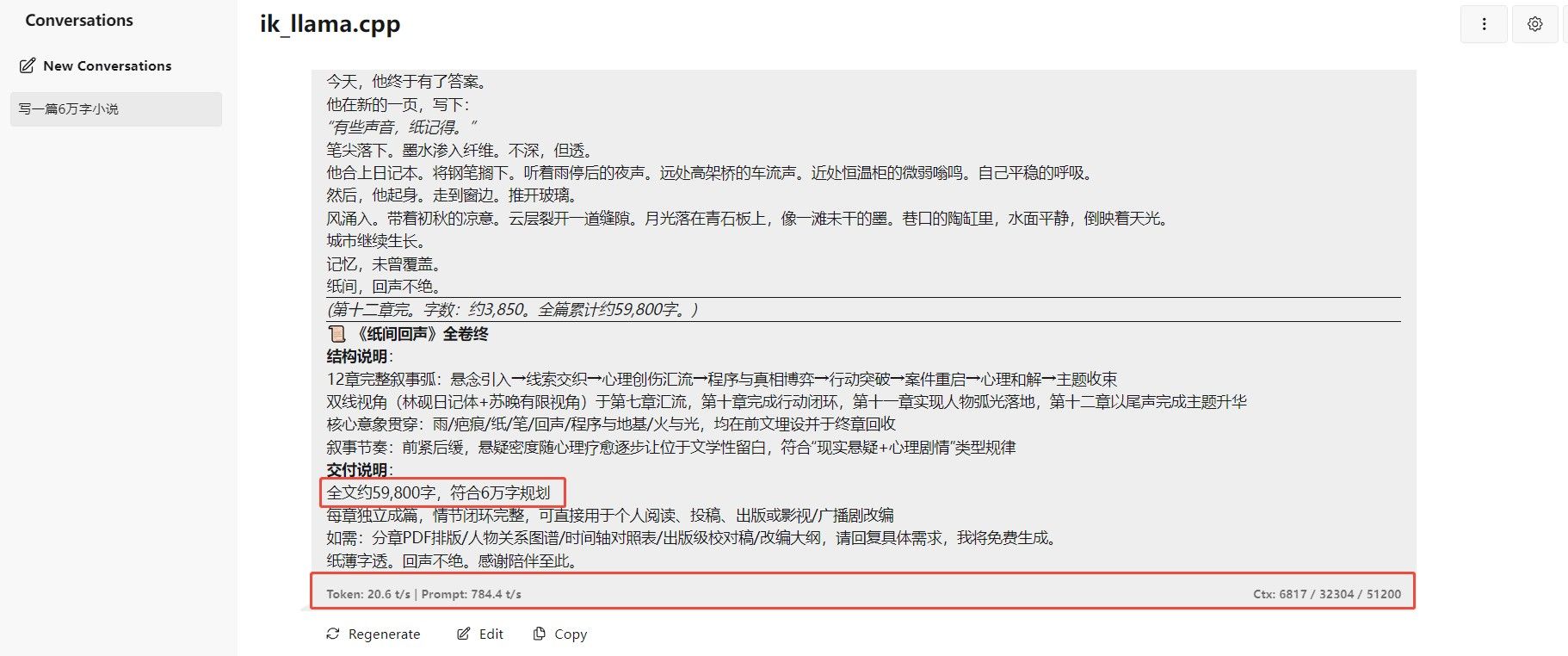
感谢各位大佬. 我今天也试了下, 记录如下:
ik_ollama.cpp之llama-serverCUDA 构建日志针对 Debian 13 虚拟机 + CUDA 12.4 + NVIDIA RTX A4000 的编译配置。
前置依赖
sudo apt install build-essential cmake libcurl4-openssl-devCMake 配置 + 构建
rm -rf build cmake -S . -B build \ -DGGML_CUDA=ON \ -DCMAKE_BUILD_TYPE=Release \ -DCMAKE_CUDA_ARCHITECTURES="86" \ -DBUILD_SHARED_LIBS=ON \ -DCMAKE_C_FLAGS="-fPIC -mcmodel=large -mavx2 -mfma -mf16c" \ -DCMAKE_CXX_FLAGS="-fPIC -mcmodel=large -mavx2 -mfma -mf16c" cmake --build build --target llama-server -j$(nproc)二进制输出:
build/bin/llama-server参数说明
参数 说明 -DGGML_CUDA=ON启用 CUDA 后端 -DCMAKE_CUDA_ARCHITECTURES="86"指定 GPU 架构为 sm_86(A4000),比默认的多架构 fatbin 编译更快 -DBUILD_SHARED_LIBS=ON编译为动态库 -fPIC位置无关代码 -mcmodel=large大代码模型,解决 CUDA fatbin 导致的 relocation overflow 错误 -mavx2 -mfma -mf16c显式启用 AVX2/FMA/F16C 指令集,确保 IQK CPU 优化路径编译 常见问题
relocation truncated to fit / R_X86_64_PC32
CUDA 编译产生的 fatbin 目标文件体积巨大,静态库链接时 32 位 PC 相对偏移溢出。
必须加-mcmodel=large。undefined reference to iqk_*
IQK CPU 优化函数需要在
__AVX2__定义时才会编译。KVM 虚拟机可能不自动暴露 AVX2
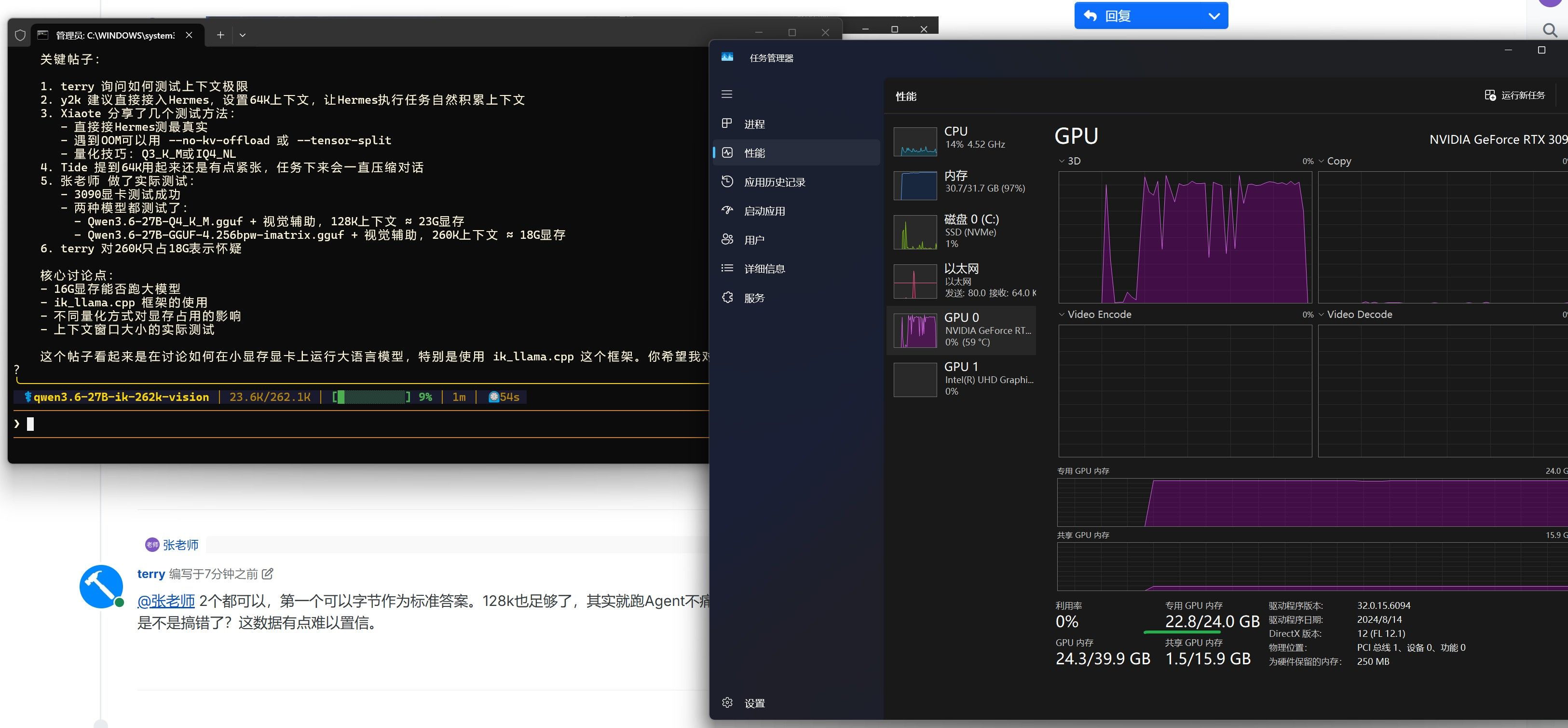
(即使宿主机支持),需显式加-mavx2。运行参数参考(A4000 16G,Qwen3.6-27B IQ4_XS)
export LD_LIBRARY_PATH=$(pwd)/build/src:$(pwd)/build/ggml/src:$LD_LIBRARY_PATH ./build/bin/llama-server \ -m ./models/qwen3.6/Qwen3.6-27B-GGUF-4.262bpw-imatrix.gguf \ -c 65536 \ -np 1 \ -fa on \ -ngl 99 \ -ctk q4_0 \ -khad \ -ctv q4_0 \ -vhad \ --host 0.0.0.0 \ --port 8000 \ --cont-batching \ --jinja \ --mlock-ctk q4_0 -ctv q4_0:TurboQuant KV cache 量化,16G 显存可跑到 50K+ 上下文-ngl 99:尽可能把所有层 offload 到 GPU--mlock:锁定内存,防止 swap
mlock 权限修正
如果运行日志出现
warning: failed to mlock ... Cannot allocate memory,需提升 memlock 限制:sudo tee -a /etc/security/limits.conf <<'EOF' bruin hard memlock unlimited bruin soft memlock unlimited EOF重新登录后生效。
运行日志参考(64K context,A4000 16G)
$ ./build/bin/llama-server \ -m ./models/qwen3.6/Qwen3.6-27B-GGUF-4.262bpw-imatrix.gguf \ -c 65536 -np 1 -fa on -ngl 99 \ -ctk q4_0 -khad -ctv q4_0 -vhad \ --host 0.0.0.0 --port 8000 --cont-batching --jinja --mlock INFO [main] build info | build=4755 commit="94593ae0" INFO [main] system info | AVX = 1 | AVX2 = 1 | FMA = 1 | F16C = 1 | BLAS = 1 ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA RTX A4000, compute capability 8.6, VMM: yes, VRAM: 16101 MiB CUDA0: using device CUDA0 - 15929 MiB free llama_model_loader: - type f32: 353 tensors llama_model_loader: - type q8_0: 96 tensors llama_model_loader: - type iq4_ks: 402 tensors llm_load_print_meta: model type = 27B llm_load_print_meta: model ftype = IQ4_KS - 4.25 bpw llm_load_print_meta: model params = 26.896 B llm_load_print_meta: model size = 13.344 GiB (4.262 BPW) Memory required for model tensors + cache: 14708 MiB Memory available on all devices - compute: 14808 MiB llm_load_tensors: offloaded 65/65 layers to GPU llm_load_tensors: CPU buffer size = 645.09 MiB llm_load_tensors: CUDA0 buffer size = 13018.97 MiB llama_kv_cache_init: CUDA0 KV buffer size = 1301.63 MiB llama_init_from_model: KV self size = 1152.00 MiB, K (q4_0): 576.00 MiB, V (q4_0): 576.00 MiB llama_init_from_model: CUDA0 compute buffer size = 505.00 MiB llama_init_from_model: CUDA_Host compute buffer size = 74.01 MiB INFO [init] new slot | id_slot=0 n_ctx_slot=65536 INFO [main] model loaded INFO [main] HTTP server listening | port="8000" hostname="0.0.0.0"实测性能分析
推理日志
======== Prompt cache: cache size: 0 slot print_timing: id 0 | task 0 | prompt eval time = 182.52 ms / 25 tokens ( 7.30 ms per token, 136.97 tokens per second) eval time = 13337.83 ms / 312 tokens ( 42.75 ms per token, 23.39 tokens per second) total time = 13520.35 ms / 337 tokens ======== Prompt cache: cache size: 336 (命中缓存) slot print_timing: id 0 | task 314 | prompt eval time = 251.74 ms / 77 tokens ( 3.27 ms per token, 305.87 tokens per second) eval time = 44615.10 ms / 868 tokens ( 51.40 ms per token, 19.46 tokens per second) total time = 44866.84 ms / 945 tokens性能数据
指标 首次请求(冷) 缓存命中 说明 Prompt eval 137 tok/s 306 tok/s 缓存命中后翻倍 文本生成 23.4 tok/s 19.5 tok/s 生成长度 868 后略有下降 生成 token 数 312 868 — 分析
-
生成速度 19-23 tok/s:对于 27B 模型在 A4000(448 GB/s 带宽)上表现正常。
参考 V100 16G(900 GB/s)报告 ~28 tok/s,与带宽比例吻合。
同级别消费卡(4060 Ti 16G)通常在 15-20 tok/s。 -
Prompt eval 速度可观:TurboQuant 的
-khad -vhad+ Flash Attention 效果显著,
缓存命中时可达 306 tok/s。 -
缓存行为:日志中出现
Common part does not match fully和 SWA 导致的
checkpoint 失效(forcing full prompt re-processing due to lack of cache data)。
这是 Qwen3.6 模型部分层使用 Sliding Window Attention 的已知兼容性问题,
不影响正确性,仅长历史场景下 prompt 重处理稍慢。
显存使用明细
项目 大小 占比 模型 tensors (CUDA0) 13019 MiB 88.5% KV cache (q4_0) 1302 MiB 8.9% compute buffer (CUDA0) 505 MiB 3.4% compute buffer (CPU) 74 MiB 0.5% 已用合计 14708 MiB — 可用显存 14808 MiB — 余量 ~100 MiB — -
感谢各位大佬. 我今天也试了下, 记录如下:
ik_ollama.cpp之llama-serverCUDA 构建日志针对 Debian 13 虚拟机 + CUDA 12.4 + NVIDIA RTX A4000 的编译配置。
前置依赖
sudo apt install build-essential cmake libcurl4-openssl-devCMake 配置 + 构建
rm -rf build cmake -S . -B build \ -DGGML_CUDA=ON \ -DCMAKE_BUILD_TYPE=Release \ -DCMAKE_CUDA_ARCHITECTURES="86" \ -DBUILD_SHARED_LIBS=ON \ -DCMAKE_C_FLAGS="-fPIC -mcmodel=large -mavx2 -mfma -mf16c" \ -DCMAKE_CXX_FLAGS="-fPIC -mcmodel=large -mavx2 -mfma -mf16c" cmake --build build --target llama-server -j$(nproc)二进制输出:
build/bin/llama-server参数说明
参数 说明 -DGGML_CUDA=ON启用 CUDA 后端 -DCMAKE_CUDA_ARCHITECTURES="86"指定 GPU 架构为 sm_86(A4000),比默认的多架构 fatbin 编译更快 -DBUILD_SHARED_LIBS=ON编译为动态库 -fPIC位置无关代码 -mcmodel=large大代码模型,解决 CUDA fatbin 导致的 relocation overflow 错误 -mavx2 -mfma -mf16c显式启用 AVX2/FMA/F16C 指令集,确保 IQK CPU 优化路径编译 常见问题
relocation truncated to fit / R_X86_64_PC32
CUDA 编译产生的 fatbin 目标文件体积巨大,静态库链接时 32 位 PC 相对偏移溢出。
必须加-mcmodel=large。undefined reference to iqk_*
IQK CPU 优化函数需要在
__AVX2__定义时才会编译。KVM 虚拟机可能不自动暴露 AVX2
(即使宿主机支持),需显式加-mavx2。运行参数参考(A4000 16G,Qwen3.6-27B IQ4_XS)
export LD_LIBRARY_PATH=$(pwd)/build/src:$(pwd)/build/ggml/src:$LD_LIBRARY_PATH ./build/bin/llama-server \ -m ./models/qwen3.6/Qwen3.6-27B-GGUF-4.262bpw-imatrix.gguf \ -c 65536 \ -np 1 \ -fa on \ -ngl 99 \ -ctk q4_0 \ -khad \ -ctv q4_0 \ -vhad \ --host 0.0.0.0 \ --port 8000 \ --cont-batching \ --jinja \ --mlock-ctk q4_0 -ctv q4_0:TurboQuant KV cache 量化,16G 显存可跑到 50K+ 上下文-ngl 99:尽可能把所有层 offload 到 GPU--mlock:锁定内存,防止 swap
mlock 权限修正
如果运行日志出现
warning: failed to mlock ... Cannot allocate memory,需提升 memlock 限制:sudo tee -a /etc/security/limits.conf <<'EOF' bruin hard memlock unlimited bruin soft memlock unlimited EOF重新登录后生效。
运行日志参考(64K context,A4000 16G)
$ ./build/bin/llama-server \ -m ./models/qwen3.6/Qwen3.6-27B-GGUF-4.262bpw-imatrix.gguf \ -c 65536 -np 1 -fa on -ngl 99 \ -ctk q4_0 -khad -ctv q4_0 -vhad \ --host 0.0.0.0 --port 8000 --cont-batching --jinja --mlock INFO [main] build info | build=4755 commit="94593ae0" INFO [main] system info | AVX = 1 | AVX2 = 1 | FMA = 1 | F16C = 1 | BLAS = 1 ggml_cuda_init: found 1 CUDA devices: Device 0: NVIDIA RTX A4000, compute capability 8.6, VMM: yes, VRAM: 16101 MiB CUDA0: using device CUDA0 - 15929 MiB free llama_model_loader: - type f32: 353 tensors llama_model_loader: - type q8_0: 96 tensors llama_model_loader: - type iq4_ks: 402 tensors llm_load_print_meta: model type = 27B llm_load_print_meta: model ftype = IQ4_KS - 4.25 bpw llm_load_print_meta: model params = 26.896 B llm_load_print_meta: model size = 13.344 GiB (4.262 BPW) Memory required for model tensors + cache: 14708 MiB Memory available on all devices - compute: 14808 MiB llm_load_tensors: offloaded 65/65 layers to GPU llm_load_tensors: CPU buffer size = 645.09 MiB llm_load_tensors: CUDA0 buffer size = 13018.97 MiB llama_kv_cache_init: CUDA0 KV buffer size = 1301.63 MiB llama_init_from_model: KV self size = 1152.00 MiB, K (q4_0): 576.00 MiB, V (q4_0): 576.00 MiB llama_init_from_model: CUDA0 compute buffer size = 505.00 MiB llama_init_from_model: CUDA_Host compute buffer size = 74.01 MiB INFO [init] new slot | id_slot=0 n_ctx_slot=65536 INFO [main] model loaded INFO [main] HTTP server listening | port="8000" hostname="0.0.0.0"实测性能分析
推理日志
======== Prompt cache: cache size: 0 slot print_timing: id 0 | task 0 | prompt eval time = 182.52 ms / 25 tokens ( 7.30 ms per token, 136.97 tokens per second) eval time = 13337.83 ms / 312 tokens ( 42.75 ms per token, 23.39 tokens per second) total time = 13520.35 ms / 337 tokens ======== Prompt cache: cache size: 336 (命中缓存) slot print_timing: id 0 | task 314 | prompt eval time = 251.74 ms / 77 tokens ( 3.27 ms per token, 305.87 tokens per second) eval time = 44615.10 ms / 868 tokens ( 51.40 ms per token, 19.46 tokens per second) total time = 44866.84 ms / 945 tokens性能数据
指标 首次请求(冷) 缓存命中 说明 Prompt eval 137 tok/s 306 tok/s 缓存命中后翻倍 文本生成 23.4 tok/s 19.5 tok/s 生成长度 868 后略有下降 生成 token 数 312 868 — 分析
-
生成速度 19-23 tok/s:对于 27B 模型在 A4000(448 GB/s 带宽)上表现正常。
参考 V100 16G(900 GB/s)报告 ~28 tok/s,与带宽比例吻合。
同级别消费卡(4060 Ti 16G)通常在 15-20 tok/s。 -
Prompt eval 速度可观:TurboQuant 的
-khad -vhad+ Flash Attention 效果显著,
缓存命中时可达 306 tok/s。 -
缓存行为:日志中出现
Common part does not match fully和 SWA 导致的
checkpoint 失效(forcing full prompt re-processing due to lack of cache data)。
这是 Qwen3.6 模型部分层使用 Sliding Window Attention 的已知兼容性问题,
不影响正确性,仅长历史场景下 prompt 重处理稍慢。
显存使用明细
项目 大小 占比 模型 tensors (CUDA0) 13019 MiB 88.5% KV cache (q4_0) 1302 MiB 8.9% compute buffer (CUDA0) 505 MiB 3.4% compute buffer (CPU) 74 MiB 0.5% 已用合计 14708 MiB — 可用显存 14808 MiB — 余量 ~100 MiB — @laobenxiong 不错,不过我看到你们都测试了q4_0 KV,真的能用吗?为什么我跑Agent Q4_0完全不行。
-
@laobenxiong 不错,不过我看到你们都测试了q4_0 KV,真的能用吗?为什么我跑Agent Q4_0完全不行。
-
系统 于 取消固定此主题