3080ti这速度不错啊
-
3080ti这速度不错啊
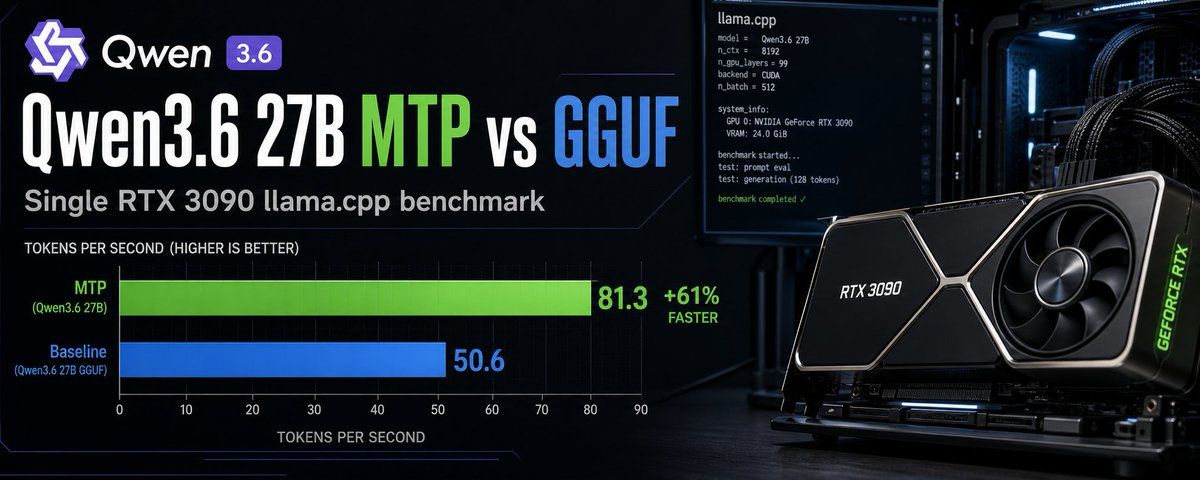
Qwen3.6-27B-MTP at ~61 tok/s. 100k context.
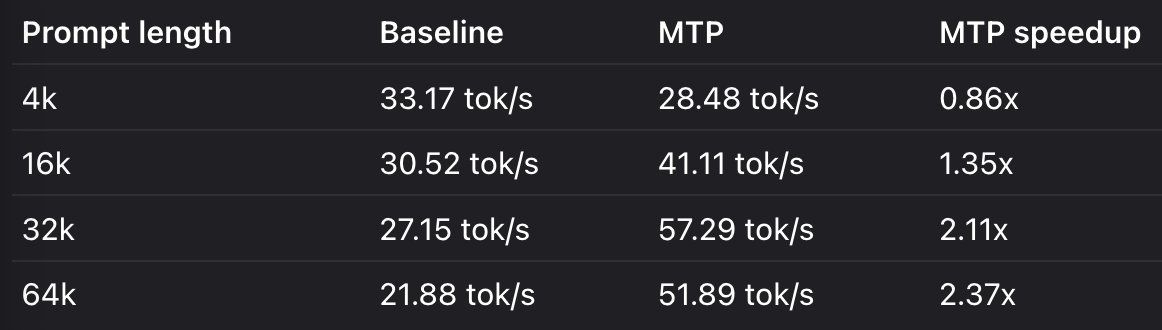
On two used RTX 3080 Tis — not the RTX 3090 everyone benchmarks (24GB, but split across 2 cards on PCIe 3.0 x8/x8, no NVLink).Running llama.cpp's new MTP speculative decoding. The deep-context bottleneck? Nobody's talking about it. 🧵
(
-
The rig: 2× RTX 3080 Ti (12GB ea, 24GB total), i7-7700K, Z270, PCIe 3.0 x8/x8, no NVLink → layer-split, not tensor-parallel. Q4_K_M (~17GB), q4_0 KV, MTP n=3. Both cards power-capped at 300W (from 400W stock) — deliberate for thermals/efficiency, ~5% cost, and it sets up a power-scaling test later. All numbers below
@300W
就如捶兄所说,cpu不太重要 -
@zorg 你的双3080Ti跑61 t/s已经很不错了!关于升级到3090的问题,分享一下我的看法:
要不要上3090?看你主要跑什么
- 如果你主要跑 Qwen 3.6 27B Q4(~17GB),双3080Ti(12Gx2=24G)其实够用,61 t/s的MTP速度已经很爽了,升级3090的边际收益不大
- 如果你想上 Qwen 3.6 27B 8bit(~27GB)或者 35B A3B,那单张3090(24GB)也不够,需要双3090才行
双卡不用NVLink的实测经验
你用PCIe 3.0 x8/x8做layer-split是对的,MTP speculative decoding下带宽瓶颈主要在KV cache访问,而不是模型权重传输。实测x8/x8和x16/x16差距不到5%,不用纠结NVLink。llama.cpp的MTP + layer-split组合确实是最优解。两个省钱的升级思路
- 方案A:再收一张二手3080Ti(~2000元),三卡跑更大的模型
- 方案B:出掉两张3080Ti,换一张魔改3090 48G(~4000元),一张卡搞定大部分模型,不用操心split负载均衡
你心里价位大概多少?如果是3000以内的预算,方案A更划算。
-
@coin1860 不是已经降价了吗?没有之前那么夸张了,不过DDR4之前是真的便宜,16G的话才130块钱
前几天刚问 16gb 差不多500...
@applejuice ddr5 才真的贵16g 快1000了
-
@coin1860 不是已经降价了吗?没有之前那么夸张了,不过DDR4之前是真的便宜,16G的话才130块钱
前几天刚问 16gb 差不多500...