
分享自己的經驗 # 7900 XTX 本地 LLM 優化實測報告(Qwen3.6-27B)
-
感谢,抄了作业,重新编译一下从原来~30TPS 提升到~40TPS,后面对coding微调了一下基本上确定大概eGPU +7900xtx能编程能测试了,等装上x99-cd3会来更新一下
# 7900 XTX (TB3 eGPU) + Qwen3.6-27B llama.cpp MTP — Bench Summary Hardware: AMD 7900 XTX via Razer Core X Chroma (TB3) + Beelink SER7 Tool: llama-benchy (Sherlock Holmes prompts, pp=512 tg=128 depth=[0, 4096]) | # | Config | tg mean | tg peak | tg @ d4096 | pp512 | Accept | |---|-------------------------------------------------|--------:|--------:|-----------:|------:|-------:| | 1 | Baseline (mainline, no MTP, temp=0.2) | 30.26 | 31.5 | 29.79 | 459 | n/a | | 2 | + MTP enabled (old PR build 9117) | 35.54 | 41.0 | 29.45 | 310 | 97% | | 3 | + Rebuilt PR to latest (9173, GDN rollback fix) | 37.25 | 45.5 | 34.70 | 353 | 57% | | 4 | + GPU power_dpm forced to `high` | 45.00 | 54.8 | 37.94 | 351 | 57% | | 5 | + Qwen "precise coding" sampling (current) | 37.32 | 46.8 | 31.75 | 368 | 54% | Cumulative gain vs original baseline: **+23% TG mean, +49% TG peak** (Step 4 alone is +49% / +74%; step 5 trades 16% speed for output quality) ## Variant comparisons (PR 9173 + perf=high) | Variant | tg mean | tg peak | tg @ d4096 | Accept | Verdict | |--------------------------------------------|--------:|--------:|-----------:|-------:|------------------| | froggeric Q4_K_M MTP (default) | 45.00 | 54.8 | 37.94 | 67% | ✅ Best mean | | unsloth Q4_K_M MTP | 36.13 | 44.0 | 34.68 | 49% | ❌ -19% TG | | unsloth UD-Q4_K_XL MTP | 43.65 | 53.0 | 33.01 | 60% | ≈ Tied, worse @d | | Chain: `ngram-mod,draft-mtp` (unsloth tip) | — | — | — | — | 🔴 CRASH (SSM) | ## Sampling A/B (froggeric MTP, n=2, perf=high) | Preset | temp / top_p / top_k / pp | tg mean | Accept@0 | Note | |-------------------------|---------------------------|--------:|---------:|---------------| | Fast (temp=0.2) | 0.2 / — / 20 / — | 45.00 | 67% | Fastest, repetitive | | Precise coding (active) | 0.6 / 0.95 / 20 / 0.0 | 37.32 | 54% | ★ Current default | | Non-thinking general | 0.7 / 0.8 / 20 / 1.5 | 36.26 | 57% | Best @ long ctx | | Thinking general | 1.0 / 0.95 / 20 / 1.5 | 37.68 | 59% | Avoid (no MTP gain) | ## Other paths evaluated and rejected | Option | Result on 7900 XTX | |------------------------------|----------------------------------------| | vLLM (ROCm) | ❌ -10–20%, no Qwen3.6 MTP, 4–8h install | | TurboQuant (Vulkan port) | ❌ Broken — 10 t/s, GPU util <30% | | DFlash / Hipfire | ❌ Crashes >4k context, no MTP | | MLC-LLM (Vulkan) | ⚠️ ~10 t/s slower, no MTP | ## Hardware ceiling vs realistic upgrades | Setup | Expected tg mean | |--------------------------------------------------|-----------------:| | Current (TB3 eGPU, all sw optimizations) | 37–45 | | OCuLink mod to Core X Chroma (~$80, 3h) | 52–55 | | Move GPU to X99 desktop (PCIe 3.0 x16) | 58–62 | | Modern AM5 + PCIe 4.0 x16 (blog reference) | 67 | **Current `start_server start`:** llama.cpp PR 9173 + froggeric MTP Q4_K_M + `--spec-type draft-mtp --spec-draft-n-max 2` + KV q4_0 + FA on + Qwen precise coding sampling + GPU perf=high.
@ken-huang 讚讚讚 這張卡越來越超值 哈 請多多分享
-
@bin-flamebox 5500很便宜,Q8可以开128k,研究下Turboquant,看下LLM区的几个置顶帖子,弄好了可以开256k。
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
@CHIA-AN-YANG 128K上下文确实会让7900 XTX的LLM推理速度明显下降,这是正常的。有两个方向可以优化:
-
精简上下文长度:如果不是必须128K,可以试试在llama.cpp里用
--ctx-size 32768限制到32K。对于大部分Agent任务(Hermes、代码补全),32K完全够用,Prefill速度能快3-4倍。只有在处理超长文档或完整代码库时才需要128K。 -
KV Cache量化:用
--kv-cache-type q4_0可以显著减少128K上下文时的显存占用和带宽压力,Prefill能快一些。7900 XTX的显存带宽虽然高,但128K的KV Cache体积很大,量化后缓存更紧凑。 -
MTP(Multi-Token Prediction):如果还没开,试试llama.cpp的MTP模式(需要支持MTP的模型,Qwen 3.6 27B支持),Token生成速度能提升20-30%。
总结:日常用32K上下文 + Q4 KV Cache,需要处理长文档时再切换到128K。这样既保证了日常速度,又保留了大上下文能力。
-
-
感謝大大無私分享

-
张 张鑫磊 于 引用了 此主题
-
謝謝樓主分享,我也成功在W7900上面跑Qwen3.6 27b Q4 MTP模型了,也掛了圖形識別模型成功。我用實際路徑的設定成功。輸出速度部分從原本的20t/s有增加到50t/s左右,從速度勉強可接受變成速度感覺順暢。更重要的是我也同時學會用llama.cpp在windows11架server了! 這軟體穩定度比lmstudio更好,模型載入速度超順暢。
@echo off
"D:\llama.cpp\build\bin\llama-server.exe" ^
-m "D:\llama.cpp\Qwen3.6-27B-MTP-Q4_K_M.gguf" ^
--mmproj "D:\llama.cpp\mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
--device Vulkan0 -ngl 999 -c 262144 ^
--temp 0.4 ^
--no-mmap ^
--api-key "*******" ^
-ctk q4_0 -ctv q4_0 -np 1 ^
--spec-type draft-mtp --spec-draft-n-max 3 ^
--reasoning off -fa 1 ^
--port 8081 --host 0.0.0.0
pause -
謝謝樓主分享,我也成功在W7900上面跑Qwen3.6 27b Q4 MTP模型了,也掛了圖形識別模型成功。我用實際路徑的設定成功。輸出速度部分從原本的20t/s有增加到50t/s左右,從速度勉強可接受變成速度感覺順暢。更重要的是我也同時學會用llama.cpp在windows11架server了! 這軟體穩定度比lmstudio更好,模型載入速度超順暢。
@echo off
"D:\llama.cpp\build\bin\llama-server.exe" ^
-m "D:\llama.cpp\Qwen3.6-27B-MTP-Q4_K_M.gguf" ^
--mmproj "D:\llama.cpp\mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
--device Vulkan0 -ngl 999 -c 262144 ^
--temp 0.4 ^
--no-mmap ^
--api-key "*******" ^
-ctk q4_0 -ctv q4_0 -np 1 ^
--spec-type draft-mtp --spec-draft-n-max 3 ^
--reasoning off -fa 1 ^
--port 8081 --host 0.0.0.0
pause -
@bin-flamebox 发测试结果来参考下。
@terry
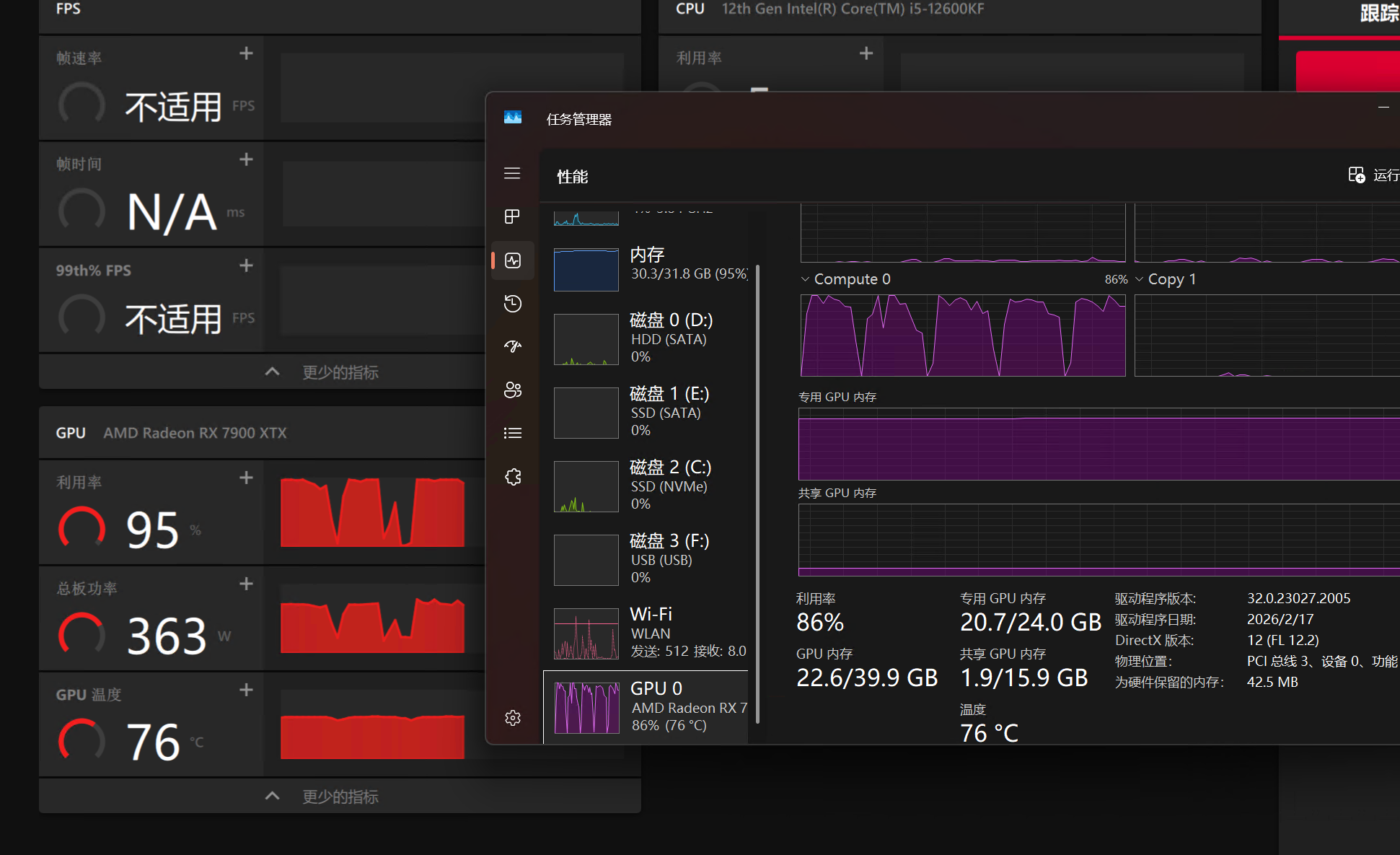
拿到手了。一开始用的是linux,一通环境全部装好了,什么rocm、vulkan乱七八糟的。本来挺顺的,但后来跑comfyui后却莫名卡死了,然后就不认驱动了 。怎么反复重装都没用,就算恢复到最开始的系统快照也是这样,莫名其妙!想一想,还是装回windows好了。。。
。怎么反复重装都没用,就算恢复到最开始的系统快照也是这样,莫名其妙!想一想,还是装回windows好了。。。
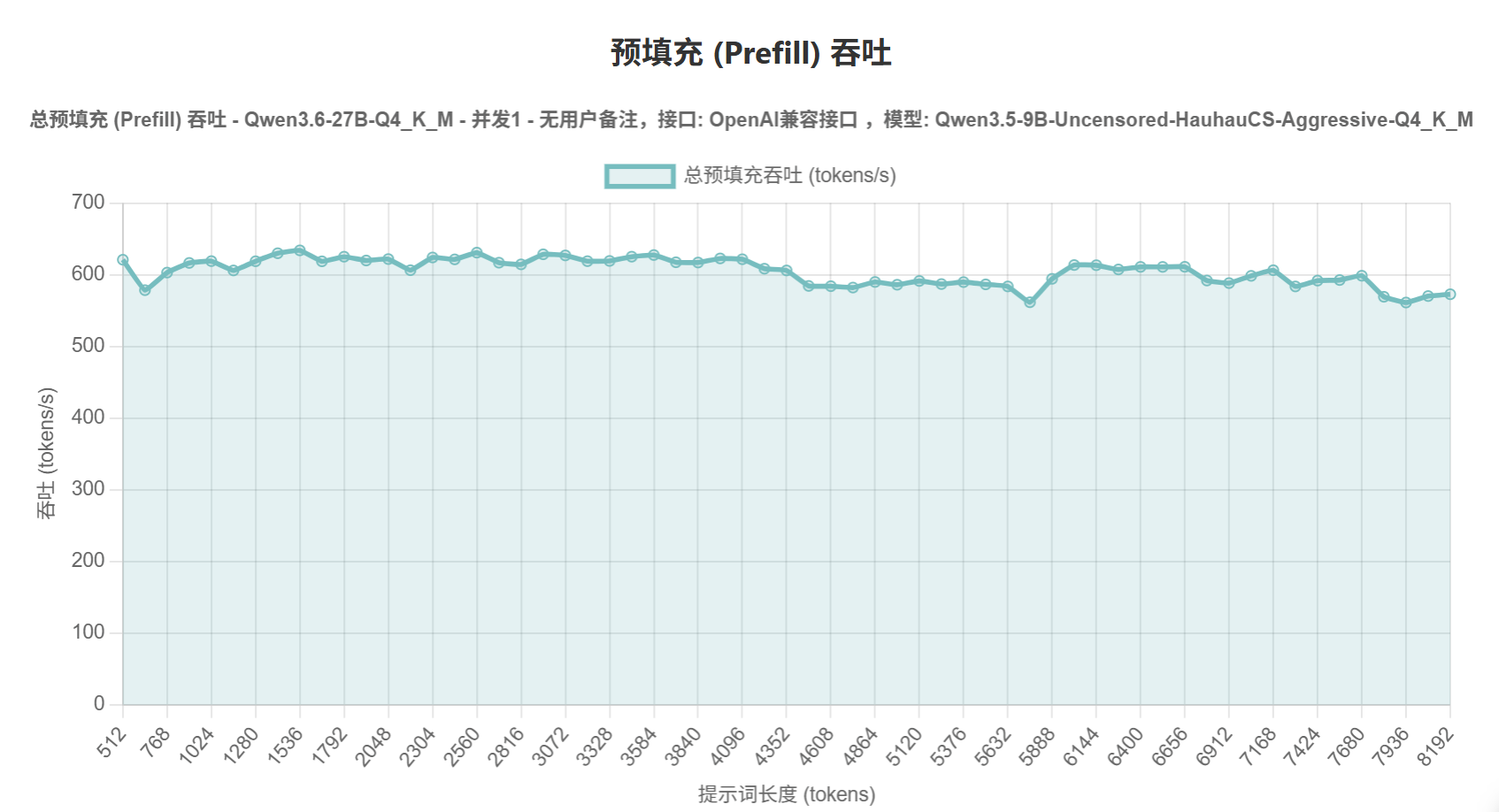
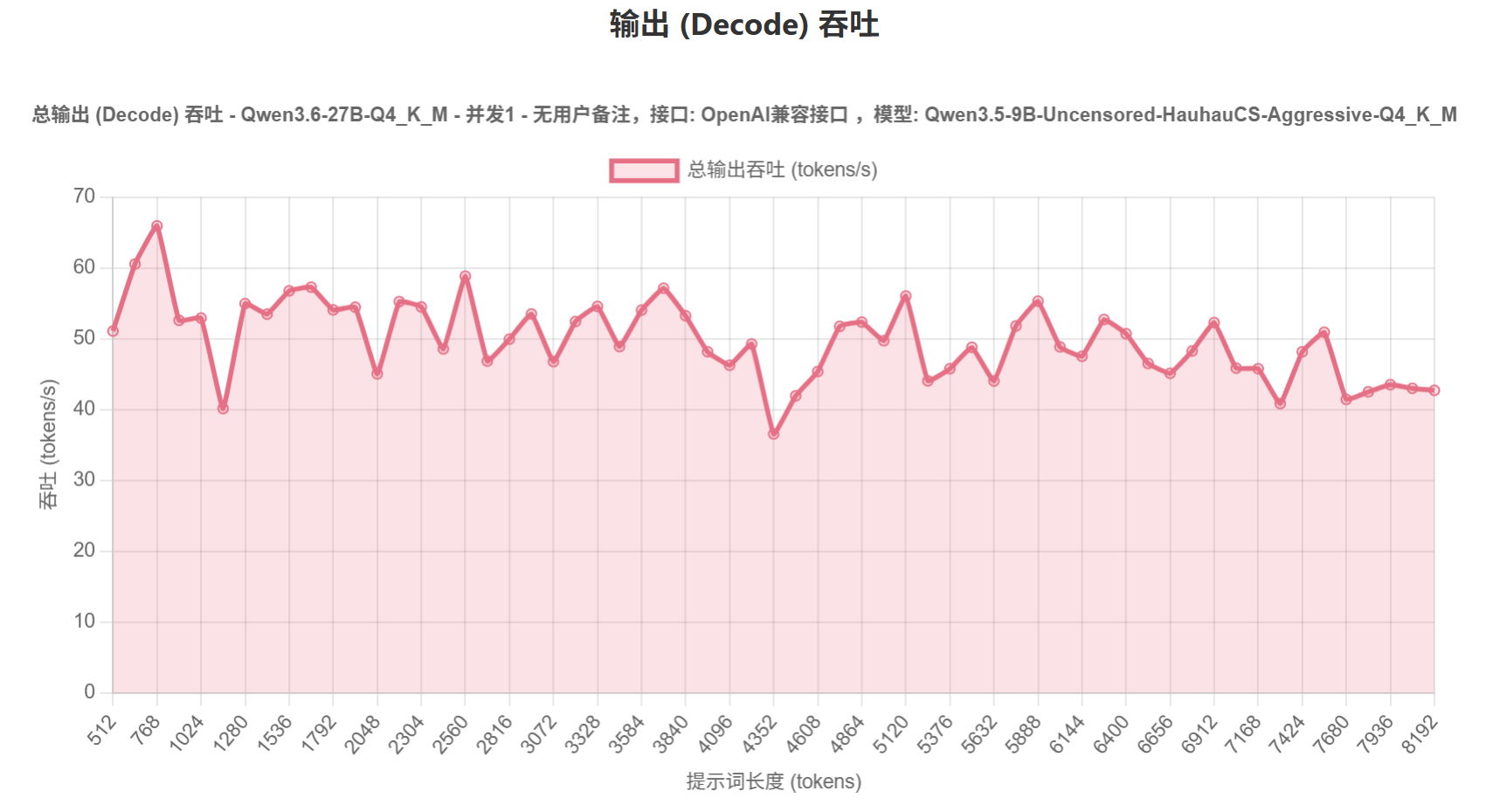
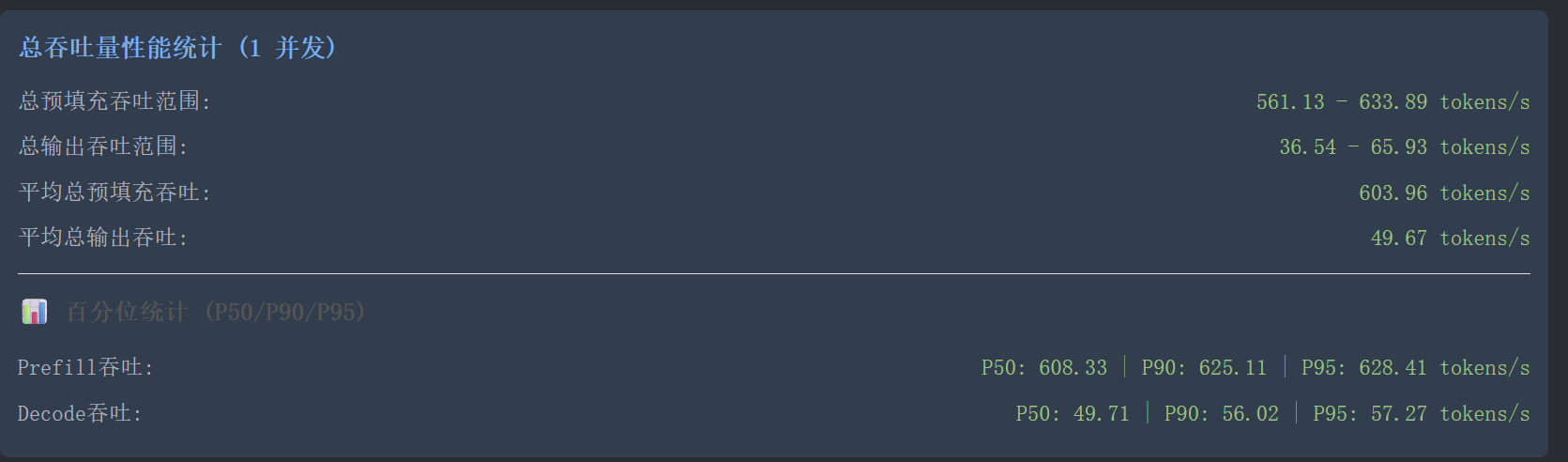
使用llama.cpp的vulkan后端,配合最新整合mtp的主线编译+mtp专用的量化模型。跑出的成绩还行吧。预填充500-600tk/s,输出有36-65tk/s。上下文我只拉到128k,显存占用不到21个G。
接入到claud code后,实际用起来比预期还好一点。果然预填充速度才是最重要的,如果当初买r9700,可能要差一截 -
@terry
拿到手了。一开始用的是linux,一通环境全部装好了,什么rocm、vulkan乱七八糟的。本来挺顺的,但后来跑comfyui后却莫名卡死了,然后就不认驱动了 。怎么反复重装都没用,就算恢复到最开始的系统快照也是这样,莫名其妙!想一想,还是装回windows好了。。。
使用llama.cpp的vulkan后端,配合最新整合mtp的主线编译+mtp专用的量化模型。跑出的成绩还行吧。预填充500-600tk/s,输出有36-65tk/s。上下文我只拉到128k,显存占用不到21个G。
接入到claud code后,实际用起来比预期还好一点。果然预填充速度才是最重要的,如果当初买r9700,可能要差一截@bin-flamebox 你Linux有什么问题?脚本去下载AMD官方的一键安装脚本,问Gemini,和它说清楚,肯定没问题的。
-
@bin-flamebox 你Linux有什么问题?脚本去下载AMD官方的一键安装脚本,问Gemini,和它说清楚,肯定没问题的。
@terry 一开始没有问题,啥都装好了,跑llm一切正常。就是跑了个comfyui后不认驱动了。。。
之前测试过,如果跑llm的话,现在vulkan比rocm好太多了。
现在还是觉得装回windows方便不少,性能基本差不了多少,关键我不是24小时开机使用,偶尔直接玩玩游戏,win更合适
现在comfyui有windows桌面版一键直装了,直接内置装好rocm需要的python虚拟环境,比自己github clone方便很多了 -
系统 于 取消固定此主题
-
謝謝樓主分享,我也成功在W7900上面跑Qwen3.6 27b Q4 MTP模型了,也掛了圖形識別模型成功。我用實際路徑的設定成功。輸出速度部分從原本的20t/s有增加到50t/s左右,從速度勉強可接受變成速度感覺順暢。更重要的是我也同時學會用llama.cpp在windows11架server了! 這軟體穩定度比lmstudio更好,模型載入速度超順暢。
@echo off
"D:\llama.cpp\build\bin\llama-server.exe" ^
-m "D:\llama.cpp\Qwen3.6-27B-MTP-Q4_K_M.gguf" ^
--mmproj "D:\llama.cpp\mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
--device Vulkan0 -ngl 999 -c 262144 ^
--temp 0.4 ^
--no-mmap ^
--api-key "*******" ^
-ctk q4_0 -ctv q4_0 -np 1 ^
--spec-type draft-mtp --spec-draft-n-max 3 ^
--reasoning off -fa 1 ^
--port 8081 --host 0.0.0.0
pause勉強可接受變成速度感覺順暢。更重要的是我也同時學會用llama.cpp在windows11架server了! 這軟體穩定度比lmstudio更好,模型載入速度超順暢。
@echo off
"D:\llama.cpp\build\bin\llama-server.exe" ^
-m "D:\llama.cpp\Qwen3.6-27B-MTP-Q4_K_M.gguf" ^
--mmproj "D:\llama.cpp\mmproj-Qwen3.6-27B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
--device Vulkan0 -ngl 999 -c 262144 ^
--temp 0.4 ^
--no-mmap ^
--api-key "*******" ^
-ctk q4_0 -ctv q4_0 -np 1 ^恭喜啦!~這張卡很划算的
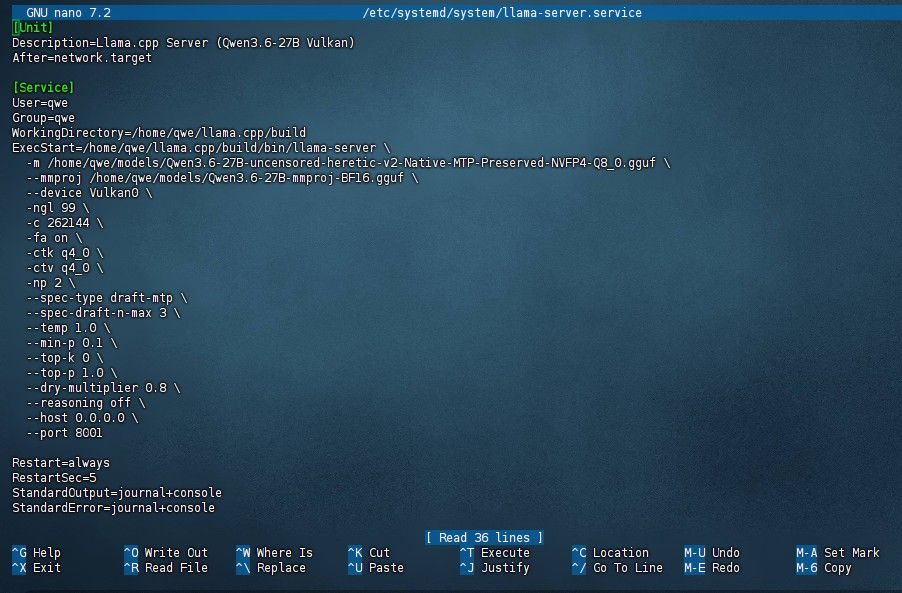 7900xtx 32G X99 大概40-50t/s
7900xtx 32G X99 大概40-50t/s