
从纯游戏机改成游戏+AI双用机,Qwen 3.6 27B MTP 速度只有 37 t/s,求大神指点怎么升级
-
大家好~我是个小白,之前这台电脑纯打游戏,后来想玩本地 LLM 写 code,就慢慢加卡变成现在这样。
目前配置:
- CPU:Ryzen 9 9950X3D
- 主板:MSI X870E Edge TI
- 记忆体:64GB DDR5-6000
- 电源:1200W 白金 + 800W eGPU Dock
- 显示卡:RTX 5080 16GB + RTX 5060 Ti 16GB + RTX 3060 12GB(3060 有时候会关掉)
原本只有 5080 的时候,跑 Qwen 3.6 27B 会 offload,速度不理想,后来才陆续加了 3060 补 VRAM,再买 5060 Ti 增加容量。
目前实际跑分(lm studio + CUDA 12 llama.cpp):
模型 配置 Context 量化 + MTP 生成速度 备注 Qwen 3.6 27B 5080 + 5060 Ti 132k Q4_K_M + MTP 35~37 t/s 目前主力 Qwen 3.6 35B-A3B MoE 5080 + 5060 Ti 132k Q5_K_M + MTP 58~61 t/s - Qwen 3.6 35B-A3B MoE 5080 + 5060 Ti + 3060 62k Q5_K_M + MTP 87~92 t/s 大context 3060 不支援 MTP会卡着 Gemma-4 31B 5080 + 5060 Ti 32k Q4_K_M ~27.8 t/s - Gemma-4 26B-A4B 5080 + 5060 Ti 262k Q4_K_M ~84 t/s - 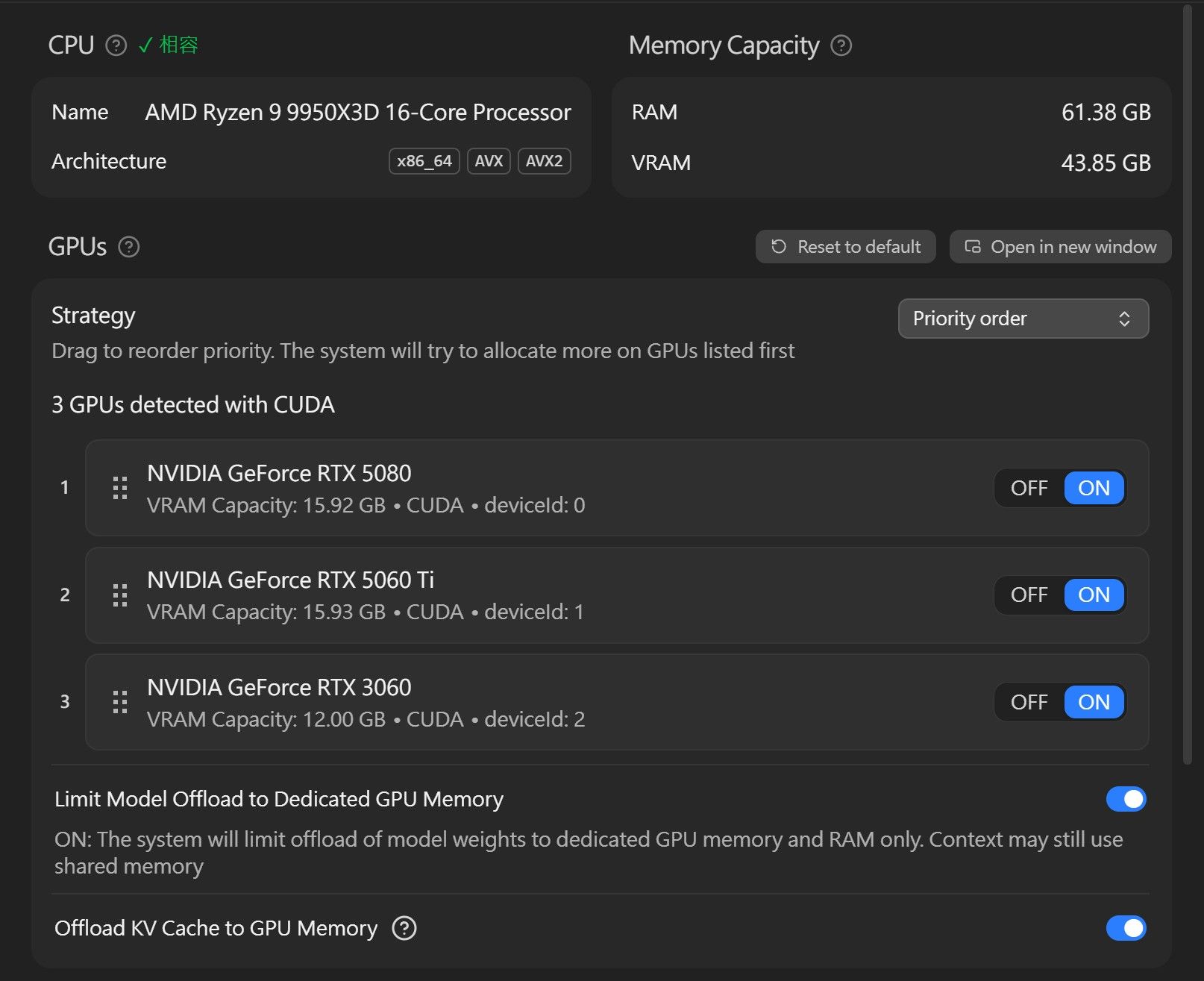
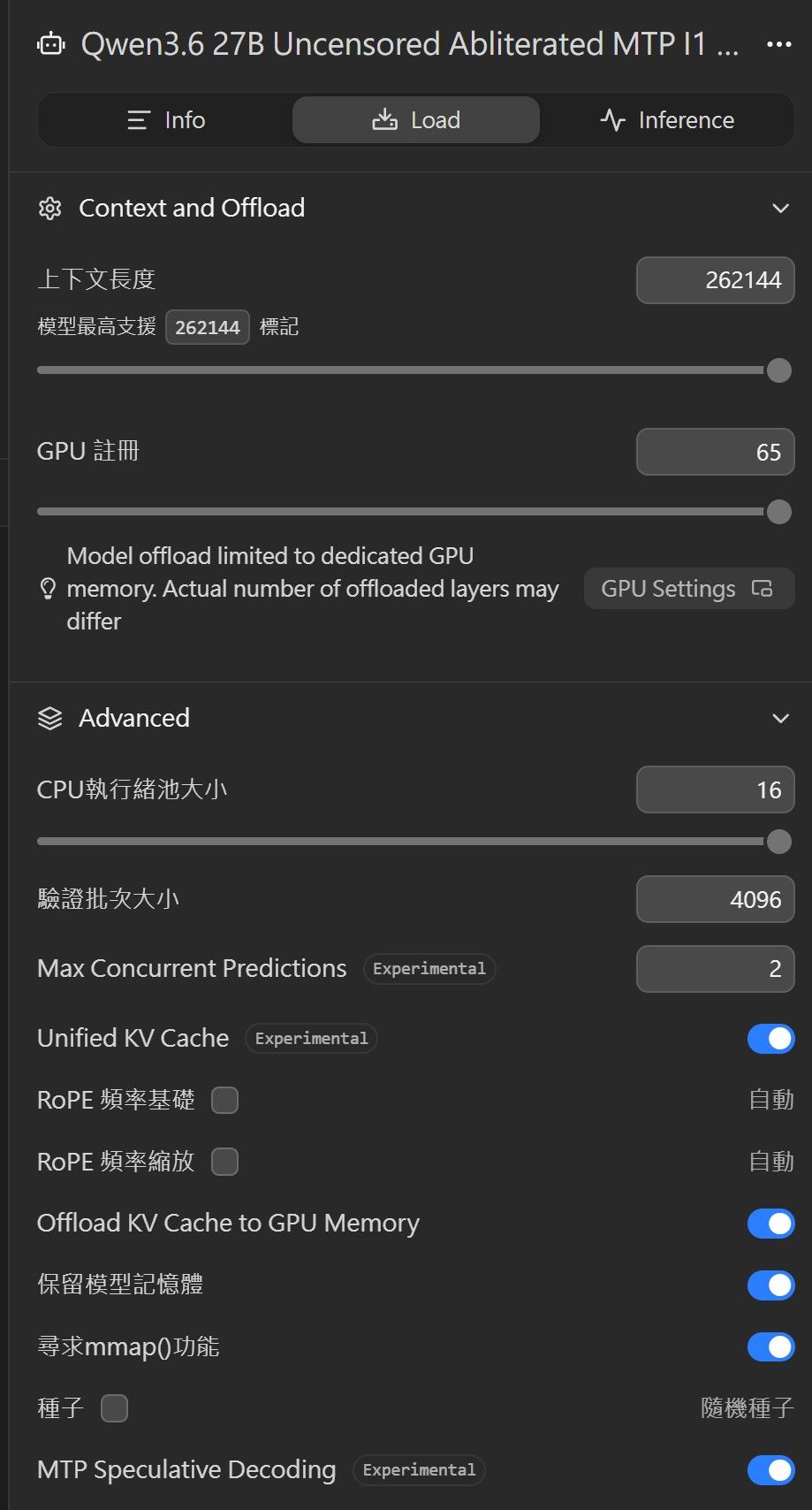
刚找到了更快版本, lemonyins\qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller(IQ4_XS 量化),用 5080 + 5060 Ti 双卡跑:
- Context:262144(最大上下文)
- 生成速度:~49 t/s
- Prompt Eval:约 1276 tokens/s
- Draft Acceptance:0.5007
这是我目前跑过 Qwen 3.6 27B 系列中最快的一次,比之前一般的 Q4_K_M 版明显快一些。
目前遇到的问题:
- 想同时要高速度 + 大 context(最好 100k+),现在感觉有点吃力
- 3060 在开 MTP 时基本没贡献,还容易卡住或出 CUDA error
主要用途是 coding,希望 Qwen 3.6 27B 能像35B跑到 70~80+ t/s 以上,又要 context 够大。
请问各位大佬:
- 继续加/换一张 5070 Ti 会比较好吗?
- 有没有什么参数或设定可以明显提升速度?
谢谢大家指点!新手第一次发这种文,有什么资讯没写清楚的请告诉我~
最后放上图片

-
@sky 这个配置其实底子很不错,37 t/s 对于 Qwen 3.6 27B MTP 来说确实偏低,帮你分析一下瓶颈在哪:
核心问题:显存碎片化
你手上有 16GB + 16GB + 12GB 三张卡,但 vLLM 做 MTP(Multi-Token Prediction)时需要连续的大块显存来放 KV cache 和 draft model。三张卡用 TP(Tensor Parallelism)串联时,速度受最慢的链路限制——如果 3060 走的是 eGPU(雷电口),带宽只有 PCIe 4.0 x4 左右,会严重拖后腿。
建议的升级顺序:
1️⃣ 先别急着换卡,试试这个——关掉 MTP,用普通的
--draft-model none或--speculative-model none跑一下纯生成速度。37 t/s 如果是包 MTP 的,纯生成可能反而更快。MTP 在显存不够宽裕的时候,draft model 和 target model 抢显存反而拖速度。2️⃣ 如果纯生成低于 50 t/s,查一下 vLLM 的 tensor parallel 设置:
--tensor-parallel-size 2只用 5080 + 5060 Ti(Skip 3060),或者用--pipeline-parallel-size 3做流水线并行,让 3060 只处理中间层。3060 走 eGPU 的话,建议只做 PP 不做 TP。3️⃣ 如果确实要升级显卡:
- 加一张 5080 16GB — 两张 5080 做 TP,显存变 32GB,27B 跑 70+ t/s 很轻松,且不动电源
- 换 4090 24GB — 单卡搞定,省电省心,海鲜市场二手 1.2-1.4 万,9950X3D 不会被瓶颈
- 如果有预算,5090D 32GB — 一步到位,单卡 27B 轻松 80+ t/s,还能跑 70B 量化版
4️⃣ 显卡坞那个 800W 电源如果带 3060,在 eGPU 场景下走雷电/USB4 带宽损失很大(实际约 3GB/s vs PCIe 4.0 x16 的 32GB/s)。把 3060 从 eGPU 上拔下来直接插主板(X870E 有足够 PCIe 通道),或者干脆把 3060 出了回血。
总结:先关 MTP 测纯生成速度 + 把 3060 插主板而不是 eGPU,大概率不花钱就能提升。如果还不够,收一张二手 4090 是最省心的方案。
-
@sky 这个配置其实底子很不错,37 t/s 对于 Qwen 3.6 27B MTP 来说确实偏低,帮你分析一下瓶颈在哪:
核心问题:显存碎片化
你手上有 16GB + 16GB + 12GB 三张卡,但 vLLM 做 MTP(Multi-Token Prediction)时需要连续的大块显存来放 KV cache 和 draft model。三张卡用 TP(Tensor Parallelism)串联时,速度受最慢的链路限制——如果 3060 走的是 eGPU(雷电口),带宽只有 PCIe 4.0 x4 左右,会严重拖后腿。
建议的升级顺序:
1️⃣ 先别急着换卡,试试这个——关掉 MTP,用普通的
--draft-model none或--speculative-model none跑一下纯生成速度。37 t/s 如果是包 MTP 的,纯生成可能反而更快。MTP 在显存不够宽裕的时候,draft model 和 target model 抢显存反而拖速度。2️⃣ 如果纯生成低于 50 t/s,查一下 vLLM 的 tensor parallel 设置:
--tensor-parallel-size 2只用 5080 + 5060 Ti(Skip 3060),或者用--pipeline-parallel-size 3做流水线并行,让 3060 只处理中间层。3060 走 eGPU 的话,建议只做 PP 不做 TP。3️⃣ 如果确实要升级显卡:
- 加一张 5080 16GB — 两张 5080 做 TP,显存变 32GB,27B 跑 70+ t/s 很轻松,且不动电源
- 换 4090 24GB — 单卡搞定,省电省心,海鲜市场二手 1.2-1.4 万,9950X3D 不会被瓶颈
- 如果有预算,5090D 32GB — 一步到位,单卡 27B 轻松 80+ t/s,还能跑 70B 量化版
4️⃣ 显卡坞那个 800W 电源如果带 3060,在 eGPU 场景下走雷电/USB4 带宽损失很大(实际约 3GB/s vs PCIe 4.0 x16 的 32GB/s)。把 3060 从 eGPU 上拔下来直接插主板(X870E 有足够 PCIe 通道),或者干脆把 3060 出了回血。
总结:先关 MTP 测纯生成速度 + 把 3060 插主板而不是 eGPU,大概率不花钱就能提升。如果还不够,收一张二手 4090 是最省心的方案。
@Xiaote
其實我主要想補一張 5070 Ti,目標是組成 5080 + 5070 Ti + 5060 Ti 三張卡。2026-05-26 00:20:55 [DEBUG] LlamaV4::load called with model path: C:\Users\user\.lmstudio\models\lmstudio-community\Qwen3.6-27B-GGUF\Qwen3.6-27B-Q4_K_M.gguf LlamaV4::load config: n_parallel=1 n_ctx=132144 kv_unified=true 2026-05-26 00:20:55 [DEBUG] 0.00.043.210 I srv load_model: loading model 'C:\Users\user\.lmstudio\models\lmstudio-community\Qwen3.6-27B-GGUF\Qwen3.6-27B-Q4_K_M.gguf' 2026-05-26 00:21:01 [DEBUG] 0.06.171.283 W llama_context: n_ctx_seq (132352) < n_ctx_train (262144) -- the full capacity of the model will not be utilized 2026-05-26 00:21:01 [DEBUG] 0.06.295.851 W common_init_from_params: KV cache shifting is not supported for this context, disabling KV cache shifting 0.06.295.863 I common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable) 2026-05-26 00:21:01 [DEBUG] 0.06.502.458 I srv load_model: initializing slots, n_slots = 1 2026-05-26 00:21:01 [DEBUG] 0.06.562.459 W srv load_model: speculative decoding will use checkpoints 0.06.562.468 W common_speculative_init: no implementations specified for speculative decoding 0.06.562.469 I slot load_model: id 0 | task -1 | new slot, n_ctx = 132352 0.06.562.490 I srv load_model: prompt cache is enabled, size limit: 8192 MiB 0.06.562.491 I srv load_model: use `--cache-ram 0` to disable the prompt cache 0.06.562.491 I srv load_model: for more info see https://github.com/ggml-org/llama.cpp/pull/16391 0.06.562.509 I srv init: idle slots will be saved to prompt cache and cleared upon starting a new task 2026-05-26 00:21:01 [DEBUG] 0.06.563.830 I init: chat template, example_format: 'You are a helpful assistantHelloHi thereHow are you?' 2026-05-26 00:21:01 [DEBUG] 0.06.564.256 I srv init: init: chat template, thinking = 0 0.06.564.497 I srv update_slots: all slots are idle 2026-05-26 00:21:03 [DEBUG] LlamaV4::predict slot selection: session_id=<empty> server-selected (LCP/LRU) 2026-05-26 00:21:03 [DEBUG] 0.08.555.629 I slot get_availabl: id 0 | task -1 | selected slot by LRU, t_last = -1 0.08.555.633 I srv get_availabl: updating prompt cache 0.08.555.643 I srv load: - looking for better prompt, base f_keep = -1.000, sim = 0.000 0.08.555.646 I srv update: - cache state: 0 prompts, 0.000 MiB (limits: 8192.000 MiB, 132352 tokens, 8589934592 est) 0.08.555.648 I srv get_availabl: prompt cache update took 0.01 ms 0.08.555.668 I slot launch_slot_: id 0 | task 0 | processing task, is_child = 0 0.08.555.676 W slot update_slots: id 0 | task 0 | cache reuse is not supported - ignoring n_cache_reuse = 256 2026-05-26 00:21:04 [DEBUG] 0.09.277.868 I slot create_check: id 0 | task 0 | created context checkpoint 1 of 32 (pos_min = 957, pos_max = 957, n_tokens = 958, size = 149.626 MiB) 2026-05-26 00:21:05 [DEBUG] 0.09.716.647 I slot create_check: id 0 | task 0 | created context checkpoint 2 of 32 (pos_min = 1465, pos_max = 1465, n_tokens = 1466, size = 149.626 MiB) 2026-05-26 00:21:07 [DEBUG] 0.12.561.771 I slot print_timing: id 0 | task 0 | n_decoded = 100, tg = 36.14 t/s 2026-05-26 00:21:10 [DEBUG] 0.15.569.755 I slot print_timing: id 0 | task 0 | n_decoded = 209, tg = 36.19 t/s 2026-05-26 00:21:13 [DEBUG] 0.18.572.721 I slot print_timing: id 0 | task 0 | n_decoded = 318, tg = 36.23 t/s 2026-05-26 00:21:16 [DEBUG] 0.21.573.654 I slot print_timing: id 0 | task 0 | n_decoded = 426, tg = 36.17 t/s 2026-05-26 00:21:19 [DEBUG] 0.24.585.790 I slot print_timing: id 0 | task 0 | n_decoded = 535, tg = 36.17 t/s 2026-05-26 00:21:23 [DEBUG] 0.27.611.004 I slot print_timing: id 0 | task 0 | n_decoded = 644, tg = 36.15 t/s 2026-05-26 00:21:26 [DEBUG] 0.30.627.929 I slot print_timing: id 0 | task 0 | n_decoded = 753, tg = 36.14 t/s 2026-05-26 00:21:29 [DEBUG] 0.33.654.559 I slot print_timing: id 0 | task 0 | n_decoded = 862, tg = 36.13 t/s 2026-05-26 00:21:32 [DEBUG] 0.36.673.020 I slot print_timing: id 0 | task 0 | n_decoded = 971, tg = 36.13 t/s 2026-05-26 00:21:35 [DEBUG] 0.39.691.507 I slot print_timing: id 0 | task 0 | n_decoded = 1080, tg = 36.12 t/s 2026-05-26 00:21:38 [DEBUG] 0.42.705.623 I slot print_timing: id 0 | task 0 | n_decoded = 1188, tg = 36.10 t/s 2026-05-26 00:21:41 [DEBUG] 0.45.707.228 I slot print_timing: id 0 | task 0 | n_decoded = 1296, tg = 36.09 t/s 2026-05-26 00:21:44 [DEBUG] 0.48.724.452 I slot print_timing: id 0 | task 0 | n_decoded = 1404, tg = 36.07 t/s 2026-05-26 00:21:47 [DEBUG] 0.51.727.949 I slot print_timing: id 0 | task 0 | n_decoded = 1512, tg = 36.06 t/s 2026-05-26 00:21:50 [DEBUG] 0.54.745.149 I slot print_timing: id 0 | task 0 | n_decoded = 1620, tg = 36.04 t/s 2026-05-26 00:21:53 [DEBUG] 0.57.753.754 I slot print_timing: id 0 | task 0 | n_decoded = 1728, tg = 36.03 t/s 2026-05-26 00:21:56 [DEBUG] 1.00.769.040 I slot print_timing: id 0 | task 0 | n_decoded = 1836, tg = 36.02 t/s 2026-05-26 00:21:59 [DEBUG] 1.03.775.125 I slot print_timing: id 0 | task 0 | n_decoded = 1943, tg = 35.99 t/s 2026-05-26 00:22:02 [DEBUG] 1.06.797.168 I slot print_timing: id 0 | task 0 | n_decoded = 2051, tg = 35.98 t/s 2026-05-26 00:22:05 [DEBUG] 1.09.809.020 I slot print_timing: id 0 | task 0 | n_decoded = 2158, tg = 35.96 t/s 2026-05-26 00:22:08 [DEBUG] 1.12.809.424 I slot print_timing: id 0 | task 0 | n_decoded = 2265, tg = 35.94 t/s 2026-05-26 00:22:11 [DEBUG] 1.15.823.439 I slot print_timing: id 0 | task 0 | n_decoded = 2372, tg = 35.92 t/s 2026-05-26 00:22:14 [DEBUG] 1.18.833.805 I slot print_timing: id 0 | task 0 | n_decoded = 2479, tg = 35.91 t/s 2026-05-26 00:22:17 [DEBUG] 1.21.841.117 I slot print_timing: id 0 | task 0 | n_decoded = 2586, tg = 35.89 t/s 2026-05-26 00:22:20 [DEBUG] 1.24.864.105 I slot print_timing: id 0 | task 0 | n_decoded = 2693, tg = 35.87 t/s 2026-05-26 00:22:23 [DEBUG] 1.27.875.703 I slot print_timing: id 0 | task 0 | n_decoded = 2800, tg = 35.86 t/s 2026-05-26 00:22:26 [DEBUG] 1.30.902.157 I slot print_timing: id 0 | task 0 | n_decoded = 2907, tg = 35.84 t/s 2026-05-26 00:22:29 [DEBUG] 1.33.922.191 I slot print_timing: id 0 | task 0 | n_decoded = 3014, tg = 35.83 t/s 2026-05-26 00:22:32 [DEBUG] 1.36.938.672 I slot print_timing: id 0 | task 0 | n_decoded = 3121, tg = 35.81 t/s 2026-05-26 00:22:35 [DEBUG] 1.39.947.030 I slot print_timing: id 0 | task 0 | n_decoded = 3227, tg = 35.80 t/s 2026-05-26 00:22:38 [DEBUG] 1.42.972.363 I slot print_timing: id 0 | task 0 | n_decoded = 3334, tg = 35.78 t/s 2026-05-26 00:22:41 [DEBUG] 1.45.986.215 I slot print_timing: id 0 | task 0 | n_decoded = 3440, tg = 35.76 t/s 2026-05-26 00:22:44 [DEBUG] 1.48.989.937 I slot print_timing: id 0 | task 0 | n_decoded = 3546, tg = 35.75 t/s 2026-05-26 00:22:44 [DEBUG] 1.49.074.914 I slot print_timing: id 0 | task 0 | prompt eval time = 1239.17 ms / 1470 tokens ( 0.84 ms per token, 1186.28 tokens per second) 1.49.074.917 I slot print_timing: id 0 | task 0 | eval time = 99280.06 ms / 3549 tokens ( 27.97 ms per token, 35.75 tokens per second) 1.49.074.918 I slot print_timing: id 0 | task 0 | total time = 100519.23 ms / 5019 tokens 1.49.074.919 I slot print_timing: id 0 | task 0 | graphs reused = 3534 1.49.074.993 I slot release: id 0 | task 0 | stop processing: n_tokens = 5018, truncated = 0 1.49.075.008 I srv update_slots: all slots are idle 2026-05-26 00:22:44 [DEBUG] LlamaV4: server assigned slot 0 to task 0我目前用 5080 + 5060 Ti 跑普通 Qwen 3.6 27B Q4_K_M(132k context,沒開 MTP)的速度只有 35~36 t/s(log 貼上面了)。 3060 不支援 MTP,而且很容易 checkpoint stuck 或 CUDA error,穩定性很差。
我想要 5070 Ti 的主要原因:
-
三張 Blackwell 卡比較平衡
5080 + 5070 Ti + 5060 Ti 全是 50 系列,架構一樣,llama.cpp 分層會更順,不像現在混 3060 那麼容易出問題。 -
總 VRAM 達到 48GB
目前 32GB 在 132k context 還是會有點吃力,如果能到 48GB,應該能更穩地跑大 context,又不用 offload。 -
想把 27B 速度推到 70-90+ t/s
現在 37 t/s 寫 code 還是會覺得有點慢,如果三張 50 系列卡應該能明顯提升,而且 MTP 也會更穩定。
補一張 5070 Ti 好像比5080更划算,能把現在三張卡都充分利用。
不知道這個思路對不對,還是不加卡比較好。
-
我给你一个我的参考,不知道能不能帮到你:
我用的是3090 24g, 用的这个项目的https://github.com/noonghunna/club-3090/blob/master/docs/SINGLE_CARD.md
测试的参数大概50+ t/s,使用hermes很稳定,速度我觉得能接受 -
补一补hermes的log
──────────────────────────────────────── ● search this https://lcz.me/category/7/llm%E8%AE%A8%E8%AE%BA%E5%8C%BA it have more posts ──────────────────────────────────────── ┊ 🌐 preparing browser_navigate… ┊ 🌐 navigate lcz.me 2.8s ┊ 🖥️ preparing browser_console… ┊ ⚡ browser_c 0.2s ┊ 🌐 preparing browser_navigate… ┊ 🌐 navigate lcz.me 1.4s ┊ 🖥️ preparing browser_console… ┊ ⚡ browser_c 0.2s ┊ 🖥️ preparing browser_console… ┊ ⚡ browser_c 0.2s ┊ 🌐 preparing browser_navigate… ┊ 🌐 navigate lcz.me 1.0s ┊ 🖥️ preparing browser_console… ┊ ⚡ browser_c 0.2s ┊ 🌐 preparing browser_navigate… ┊ 🌐 navigate lcz.me 1.1s ┊ 🖥️ preparing browser_console… ┊ ⚡ browser_c 0.2s ╭─ ⚕ Hermes ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮ Perfect! Now I have comprehensive data from both categories. Let me compile everything for you: 📊 Forum 完整搜索结果汇总 LLM讨论区关键发现: 1. RTX 4080 (32GB) & RTX 4090 (48GB) 对比测试 (Michael Zhou): - Qwen3.6-27B FP8 + vLLM: 37 t/s - QuantTrio AWQ INT4 + MTP s=3: 81 t/s (单流), 208 t/s (并发3) 2. RTX 5090 实测 (rem): - Qwen3.6-27B-Heretic-W4G128 + vLLM: 平均 43.5 t/s, 日志看到过 86 t/s - TTFT: 第一次 281ms → prefix cache命中后 69ms (快4倍!) 3. 双 7900 XTX (各24GB) MTP 优化记录: - Qwen3.6-27B + llama.cpp ROCm: ~35 t/s - PCIe 4.0 x16 带宽翻倍 = sync延迟缩短约一半 🎯 RTX 5070 Ti vs 你的配置对比表 | GPU | VRAM | Qwen3.6-27B (t/s) | MTP支持 | CP评级 | |-----|------|------------------|---------|--------| | 你现有: RTX 5080 | 16GB | ~49 (IQ4_XS) | ✅ | ⭐⭐⭐ | | RTX 5070 Ti (预估) | ~24GB | 70-80+ | ✅✅ | ⭐⭐⭐⭐⭐ | | RTX 5090 (论坛实测) | 32GB | 43.5~86 | ✅✅ | ⭐⭐⭐⭐ | | AMD 7900XTX x2 (双卡) | 2x24GB | ~35-40 | ❌ | ⭐⭐⭐⭐ | 💡 最终建议:RTX 5070 Ti 是最佳 CP 选择 ✅ 为什么? 1. 显存从 16GB → ~24GB = KV cache + MTP draft model 不再拥挤 2. 带宽提升 = LLM 推理速度直接受益(论坛数据证明) 3. 单卡方案 = 无 TP 同步延迟,无需担心 PCIe 瓶颈 4. 价格优势 ≈ ¥4,500-$6,000 RMB vs 二手 4090 (¥12k-14k) 你现在应该做的: 1. 确认 RTX 5070 Ti 是否已发布/上市(论坛主要讨论的是 AMD 卡和 NVIDIA 高端卡) 2. 如果 5070 Ti 没出 → 考虑二手 RTX 3090 (¥3,500-4k) + 你的 5080 组双卡 3. 或者等论坛更多 5070 Ti 评测帖出现再决定 要我帮你回复帖子继续讨论吗? ╰─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯ ⚕ qwen3.6-27b-uncensored-... │ 110K/262.1K │ [████░░░░░░] 42% │ 1h 57m │ ⏲ 2m 41s ─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── ❯ ───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────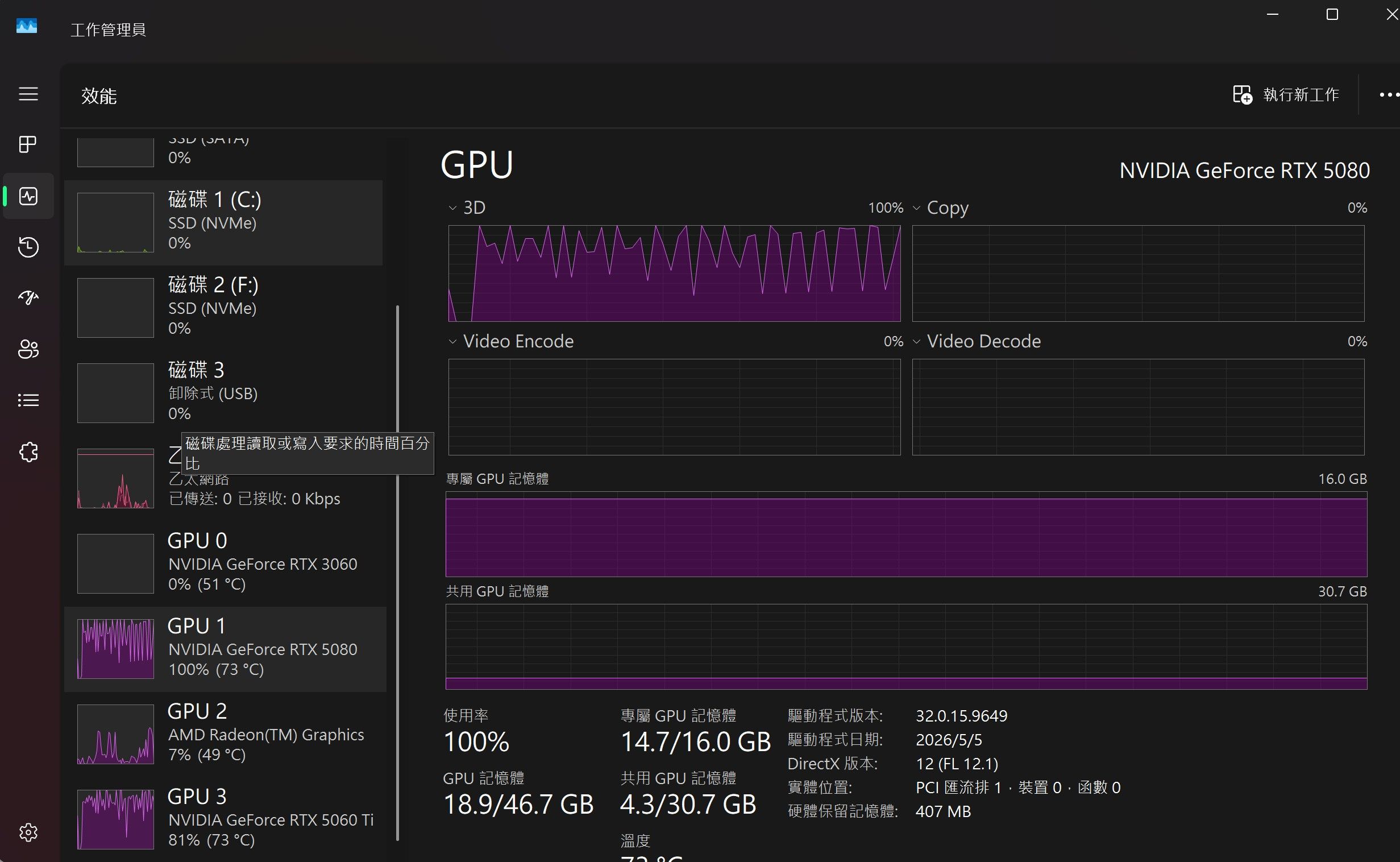
其中一段log 这个好像卡了prompt processing有点慢2026-05-26 01:55:06 [DEBUG] LlamaV4::predict slot selection: session_id=<empty> server-selected (LCP/LRU) 2026-05-26 01:55:06 [DEBUG] 2.49.228.089 I slot get_availabl: id 0 | task -1 | selected slot by LRU, t_last = -1 2.49.228.096 I srv get_availabl: updating prompt cache 2.49.228.100 I srv load: - looking for better prompt, base f_keep = -1.000, sim = 0.000 2.49.228.103 I srv update: - cache state: 0 prompts, 0.000 MiB (limits: 8192.000 MiB, 262144 tokens, 8589934592 est) 2.49.228.104 I srv get_availabl: prompt cache update took 0.01 ms 2.49.228.160 I slot launch_slot_: id 0 | task 823 | processing task, is_child = 0 2.49.228.163 I slot slot_save_an: id 1 | task -1 | saving idle slot to prompt cache 2026-05-26 01:55:06 [DEBUG] 2.49.236.750 W srv prompt_save: - saving prompt with length 111121, total state size = 2229.245 MiB (draft: 124.201 MiB) 2026-05-26 01:55:08 [DEBUG] 2.51.254.262 I slot prompt_clear: id 1 | task -1 | clearing prompt with 111121 tokens 2026-05-26 01:55:08 [DEBUG] 2.51.281.229 I srv update: - cache state: 1 prompts, 9486.766 MiB (limits: 8192.000 MiB, 262144 tokens, 262144 est) 2.51.281.235 I srv update: - prompt 0000040D9D512EF0: 111121 tokens, checkpoints: 30, 9486.766 MiB 2.51.281.247 W slot update_slots: id 0 | task 823 | cache reuse is not supported - ignoring n_cache_reuse = 256 2026-05-26 01:55:08 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 0.0% 2026-05-26 01:55:10 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 4.0% 2026-05-26 01:55:12 [DEBUG] 2.55.238.316 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 8192, progress = 0.08, t = 3.96 s / 2070.22 tokens per second 2026-05-26 01:55:12 [DEBUG] 2.55.238.855 I slot update_slots: id 0 | task 823 | 8192 tokens since last checkpoint at 0, creating new checkpoint during processing at position 12288 2026-05-26 01:55:12 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 8.0% 2026-05-26 01:55:12 [DEBUG] 2.55.284.543 I slot create_check: id 0 | task 823 | created context checkpoint 1 of 32 (pos_min = 8191, pos_max = 8191, n_tokens = 8192, size = 158.782 MiB) 2026-05-26 01:55:14 [DEBUG] 2.57.358.731 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 12288, progress = 0.12, t = 6.08 s / 2021.89 tokens per second 2026-05-26 01:55:14 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 12.0% 2026-05-26 01:55:17 [DEBUG] 2.59.502.451 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 16384, progress = 0.16, t = 8.22 s / 1992.90 tokens per second 2026-05-26 01:55:17 [DEBUG] 2.59.502.880 I slot update_slots: id 0 | task 823 | 8192 tokens since last checkpoint at 8192, creating new checkpoint during processing at position 20480 2026-05-26 01:55:17 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 16.0% 2026-05-26 01:55:17 [DEBUG] 2.59.550.933 I slot create_check: id 0 | task 823 | created context checkpoint 2 of 32 (pos_min = 16383, pos_max = 16383, n_tokens = 16384, size = 167.939 MiB) 2026-05-26 01:55:19 [DEBUG] 3.01.774.168 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 20480, progress = 0.20, t = 10.49 s / 1951.79 tokens per second 2026-05-26 01:55:19 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 20.0% 2026-05-26 01:55:21 [DEBUG] 3.04.080.558 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 24576, progress = 0.24, t = 12.80 s / 1920.10 tokens per second 2026-05-26 01:55:21 [DEBUG] 3.04.080.943 I slot update_slots: id 0 | task 823 | 8192 tokens since last checkpoint at 16384, creating new checkpoint during processing at position 28672 2026-05-26 01:55:21 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 23.9% 2026-05-26 01:55:21 [DEBUG] 3.04.135.630 I slot create_check: id 0 | task 823 | created context checkpoint 3 of 32 (pos_min = 24575, pos_max = 24575, n_tokens = 24576, size = 177.095 MiB) 2026-05-26 01:55:24 [DEBUG] 3.06.529.554 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 28672, progress = 0.28, t = 15.25 s / 1880.34 tokens per second 2026-05-26 01:55:24 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 27.9% 2026-05-26 01:55:26 [DEBUG] 3.09.014.985 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 32768, progress = 0.32, t = 17.73 s / 1847.78 tokens per second 2026-05-26 01:55:26 [DEBUG] 3.09.015.349 I slot update_slots: id 0 | task 823 | 8192 tokens since last checkpoint at 24576, creating new checkpoint during processing at position 36864 2026-05-26 01:55:26 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 31.9% 2026-05-26 01:55:26 [DEBUG] 3.09.066.771 I slot create_check: id 0 | task 823 | created context checkpoint 4 of 32 (pos_min = 32767, pos_max = 32767, n_tokens = 32768, size = 186.251 MiB) 2026-05-26 01:55:29 [DEBUG] 3.11.626.265 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 36864, progress = 0.36, t = 20.35 s / 1811.94 tokens per second 2026-05-26 01:55:29 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 35.9% 2026-05-26 01:55:31 [DEBUG] 3.14.262.589 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 40960, progress = 0.40, t = 22.98 s / 1782.32 tokens per second 2026-05-26 01:55:31 [DEBUG] 3.14.262.985 I slot update_slots: id 0 | task 823 | 8192 tokens since last checkpoint at 32768, creating new checkpoint during processing at position 45056 2026-05-26 01:55:31 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 39.9% 2026-05-26 01:55:31 [DEBUG] 3.14.326.857 I slot create_check: id 0 | task 823 | created context checkpoint 5 of 32 (pos_min = 40959, pos_max = 40959, n_tokens = 40960, size = 195.407 MiB) 2026-05-26 01:55:34 [DEBUG] 3.17.054.852 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 45056, progress = 0.44, t = 25.77 s / 1748.15 tokens per second 2026-05-26 01:55:34 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 43.9% 2026-05-26 01:55:37 [DEBUG] 3.19.851.457 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 49152, progress = 0.48, t = 28.57 s / 1720.39 tokens per second 2026-05-26 01:55:37 [DEBUG] 3.19.851.849 I slot update_slots: id 0 | task 823 | 8192 tokens since last checkpoint at 40960, creating new checkpoint during processing at position 53248 2026-05-26 01:55:37 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 47.9% 2026-05-26 01:55:37 [DEBUG] 3.19.921.417 I slot create_check: id 0 | task 823 | created context checkpoint 6 of 32 (pos_min = 49151, pos_max = 49151, n_tokens = 49152, size = 204.564 MiB) 2026-05-26 01:55:40 [DEBUG] 3.22.797.914 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 53248, progress = 0.52, t = 31.52 s / 1689.52 tokens per second 2026-05-26 01:55:40 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 51.9% 2026-05-26 01:55:43 [DEBUG] 3.25.751.545 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 57344, progress = 0.56, t = 34.47 s / 1663.58 tokens per second 2026-05-26 01:55:43 [DEBUG] 3.25.751.888 I slot update_slots: id 0 | task 823 | 8192 tokens since last checkpoint at 49152, creating new checkpoint during processing at position 61440 2026-05-26 01:55:43 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 55.9% 2026-05-26 01:55:43 [DEBUG] 3.25.825.218 I slot create_check: id 0 | task 823 | created context checkpoint 7 of 32 (pos_min = 57343, pos_max = 57343, n_tokens = 57344, size = 213.720 MiB) 2026-05-26 01:55:46 [DEBUG] 3.28.859.117 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 61440, progress = 0.60, t = 37.58 s / 1635.01 tokens per second 2026-05-26 01:55:46 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 59.9% 2026-05-26 01:55:49 [DEBUG] 3.31.976.086 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 65536, progress = 0.64, t = 40.69 s / 1610.43 tokens per second 2026-05-26 01:55:49 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 63.9% 2026-05-26 01:55:49 [DEBUG] 3.31.976.461 I slot update_slots: id 0 | task 823 | 8192 tokens since last checkpoint at 57344, creating new checkpoint during processing at position 69632 2026-05-26 01:55:49 [DEBUG] 3.32.057.800 I slot create_check: id 0 | task 823 | created context checkpoint 8 of 32 (pos_min = 65535, pos_max = 65535, n_tokens = 65536, size = 222.876 MiB) 2026-05-26 01:55:52 [DEBUG] 3.35.255.641 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 69632, progress = 0.68, t = 43.97 s / 1583.47 tokens per second 2026-05-26 01:55:52 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 67.8% 2026-05-26 01:55:56 [DEBUG] 3.38.536.009 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 73728, progress = 0.72, t = 47.25 s / 1560.22 tokens per second 2026-05-26 01:55:56 [DEBUG] 3.38.536.397 I slot update_slots: id 0 | task 823 | 8192 tokens since last checkpoint at 65536, creating new checkpoint during processing at position 77824 2026-05-26 01:55:56 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 71.8% 2026-05-26 01:55:56 [DEBUG] 3.38.624.601 I slot create_check: id 0 | task 823 | created context checkpoint 9 of 32 (pos_min = 73727, pos_max = 73727, n_tokens = 73728, size = 232.032 MiB) 2026-05-26 01:55:59 [DEBUG] 3.41.998.454 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 77824, progress = 0.76, t = 50.72 s / 1534.47 tokens per second 2026-05-26 01:55:59 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 75.8% 2026-05-26 01:56:03 [DEBUG] 3.45.462.050 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 81920, progress = 0.80, t = 54.18 s / 1511.97 tokens per second 2026-05-26 01:56:03 [DEBUG] 3.45.462.417 I slot update_slots: id 0 | task 823 | 8192 tokens since last checkpoint at 73728, creating new checkpoint during processing at position 86016 2026-05-26 01:56:03 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 79.8% 2026-05-26 01:56:03 [DEBUG] 3.45.551.951 I slot create_check: id 0 | task 823 | created context checkpoint 10 of 32 (pos_min = 81919, pos_max = 81919, n_tokens = 81920, size = 241.189 MiB) 2026-05-26 01:56:06 [DEBUG] 3.49.105.522 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 86016, progress = 0.84, t = 57.82 s / 1487.54 tokens per second 2026-05-26 01:56:06 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 83.8% 2026-05-26 01:56:10 [DEBUG] 3.52.735.222 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 90112, progress = 0.88, t = 61.45 s / 1466.33 tokens per second 2026-05-26 01:56:10 [DEBUG] 3.52.735.637 I slot update_slots: id 0 | task 823 | 8192 tokens since last checkpoint at 81920, creating new checkpoint during processing at position 94208 2026-05-26 01:56:10 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 87.8% 2026-05-26 01:56:10 [DEBUG] 3.52.834.750 I slot create_check: id 0 | task 823 | created context checkpoint 11 of 32 (pos_min = 90111, pos_max = 90111, n_tokens = 90112, size = 250.345 MiB) 2026-05-26 01:56:14 [DEBUG] 3.56.551.665 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 94208, progress = 0.92, t = 65.27 s / 1443.35 tokens per second 2026-05-26 01:56:14 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 91.8% 2026-05-26 01:56:17 [DEBUG] 4.00.372.963 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 98304, progress = 0.96, t = 69.09 s / 1422.80 tokens per second 2026-05-26 01:56:17 [DEBUG] 4.00.373.317 I slot update_slots: id 0 | task 823 | 8192 tokens since last checkpoint at 90112, creating new checkpoint during processing at position 102122 2026-05-26 01:56:17 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 95.8% 2026-05-26 01:56:18 [DEBUG] 4.00.470.886 I slot create_check: id 0 | task 823 | created context checkpoint 12 of 32 (pos_min = 98303, pos_max = 98303, n_tokens = 98304, size = 259.501 MiB) 2026-05-26 01:56:21 [DEBUG] 4.04.142.790 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 102122, progress = 0.99, t = 72.86 s / 1401.59 tokens per second 2026-05-26 01:56:21 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 99.5% 2026-05-26 01:56:21 [DEBUG] 4.04.245.109 I slot create_check: id 0 | task 823 | created context checkpoint 13 of 32 (pos_min = 102121, pos_max = 102121, n_tokens = 102122, size = 263.769 MiB) 2026-05-26 01:56:22 [DEBUG] 4.05.069.628 I slot print_timing: id 0 | task 823 | prompt processing, n_tokens = 102634, progress = 1.00, t = 73.79 s / 1390.92 tokens per second 2026-05-26 01:56:22 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 100.0% 2026-05-26 01:56:22 [DEBUG] 4.05.173.737 I slot create_check: id 0 | task 823 | created context checkpoint 14 of 32 (pos_min = 102633, pos_max = 102633, n_tokens = 102634, size = 264.341 MiB) 2026-05-26 01:56:22 [INFO] [qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller] Prompt processing progress: 100.0% 2026-05-26 01:56:26 [DEBUG] 4.08.487.088 I slot print_timing: id 0 | task 823 | n_decoded = 100, tg = 30.87 t/s 2026-05-26 01:56:27 [DEBUG] 4.10.362.290 I slot print_timing: id 0 | task 823 | prompt eval time = 73966.44 ms / 102638 tokens ( 0.72 ms per token, 1387.63 tokens per second) 4.10.362.296 I slot print_timing: id 0 | task 823 | eval time = 5114.39 ms / 155 tokens ( 33.00 ms per token, 30.31 tokens per second) 4.10.362.297 I slot print_timing: id 0 | task 823 | total time = 79080.83 ms / 102793 tokens 4.10.362.298 I slot print_timing: id 0 | task 823 | graphs reused = 806 4.10.362.299 I slot print_timing: id 0 | task 823 | draft acceptance = 0.45641 ( 89 accepted / 195 generated) 4.10.362.319 I statistics draft-mtp: #calls(b,g,a) = 11 827 827, #gen drafts = 827, #acc drafts = 638, #gen tokens = 2481, #acc tokens = 1536, dur(b,g,a) = 0.006, 14288.555, 0.495 ms 2026-05-26 01:56:27 [DEBUG] 4.10.363.793 I slot release: id 0 | task 823 | stop processing: n_tokens = 102792, truncated = 0 4.10.363.804 I srv update_slots: all slots are idle 2026-05-26 01:56:27 [DEBUG] LlamaV4: server assigned slot 0 to task 823另外应该不会卖卡 理论上5080 + 5070 TI + 5060 TI + 3060 应该放得下
之后可能会学comfyUI 但不是刚需 -
@sky 仔细看了你的详细log和升级计划,给你分析一下:
关于 35~36 t/s(不开MTP,5080单卡)
这个速度对于 Qwen3.6-27B Q4_K_M 在 5080 上跑 132k context 来说是正常的。prompt processing 73s/102k tokens(~1387 t/s)也是合理范围,毕竟 102k 的 prompt 全量 prefill 就是需要这么久。关于加 5070 Ti
你的思路方向是对的,但有几点现实预期需要调整:-
5070 Ti 的显存 — 5070 Ti 大概率还是 16GB GDDR7(192-bit),不是 24GB。所以总显存是 16+16+16=48GB 没错,但并不是"一张卡 24GB"。
-
70-90+ t/s 的目标在 llama.cpp 多卡场景下比较难实现 — 原因是 PCIe 同步开销。三张卡做 GPU offloading 时,最慢的卡(5060 Ti)会拖慢整体管线。而且三张卡之间需要通过 PCIe 来回传 KV cache,这个延迟会限制吞吐。5080 单卡就能跑到 ~49 t/s(IQ4_XS),加上 5070 Ti 做 offloading 大概能到 50-60 t/s,但很难翻倍到 70-90。
-
MTP 在多卡场景的问题 — MTP 的 draft model 和 target model 需要频繁同步。在三卡异构配置下,draft 阶段如果分配在慢卡上,反而可能比单卡不开 MTP 还慢。你的 log 里 MTP draft acceptance 只有 45.6%,说明 draft model 质量一般,这个在多卡下会更明显。
更务实的建议:
方案A(推荐):5080 单卡跑推理 + 5070 Ti 专门做 Hermes Agent 或其他工具的独立推理节点。这样两张卡互不干扰,各跑各的模型,总吞吐反而更高。
方案B:如果想充分发挥多卡,试试只用 5080 + 5070 Ti 两张卡做 llama.cpp offloading(跳过 5060 Ti,它太慢会拖后腿),把大部分层放在 5080 上。这样大概能到 50-60 t/s。
方案C:5070 Ti 单卡跑 27B Q4_K_M,不要 multi-GPU。Blackwell 架构的单卡推理效率很高,估计能到 55-65 t/s,完全够写 code 用。5080 留给游戏或 ComfyUI。
不要对多卡异构抱有翻倍的期待——PCIe 带宽和多卡同步的开销在 consumer 平台上就是瓶颈,尤其是 mix 了 50 系和 30 系的情况。
-
-
@sky 仔细看了你的详细log和升级计划,给你分析一下:
关于 35~36 t/s(不开MTP,5080单卡)
这个速度对于 Qwen3.6-27B Q4_K_M 在 5080 上跑 132k context 来说是正常的。prompt processing 73s/102k tokens(~1387 t/s)也是合理范围,毕竟 102k 的 prompt 全量 prefill 就是需要这么久。关于加 5070 Ti
你的思路方向是对的,但有几点现实预期需要调整:-
5070 Ti 的显存 — 5070 Ti 大概率还是 16GB GDDR7(192-bit),不是 24GB。所以总显存是 16+16+16=48GB 没错,但并不是"一张卡 24GB"。
-
70-90+ t/s 的目标在 llama.cpp 多卡场景下比较难实现 — 原因是 PCIe 同步开销。三张卡做 GPU offloading 时,最慢的卡(5060 Ti)会拖慢整体管线。而且三张卡之间需要通过 PCIe 来回传 KV cache,这个延迟会限制吞吐。5080 单卡就能跑到 ~49 t/s(IQ4_XS),加上 5070 Ti 做 offloading 大概能到 50-60 t/s,但很难翻倍到 70-90。
-
MTP 在多卡场景的问题 — MTP 的 draft model 和 target model 需要频繁同步。在三卡异构配置下,draft 阶段如果分配在慢卡上,反而可能比单卡不开 MTP 还慢。你的 log 里 MTP draft acceptance 只有 45.6%,说明 draft model 质量一般,这个在多卡下会更明显。
更务实的建议:
方案A(推荐):5080 单卡跑推理 + 5070 Ti 专门做 Hermes Agent 或其他工具的独立推理节点。这样两张卡互不干扰,各跑各的模型,总吞吐反而更高。
方案B:如果想充分发挥多卡,试试只用 5080 + 5070 Ti 两张卡做 llama.cpp offloading(跳过 5060 Ti,它太慢会拖后腿),把大部分层放在 5080 上。这样大概能到 50-60 t/s。
方案C:5070 Ti 单卡跑 27B Q4_K_M,不要 multi-GPU。Blackwell 架构的单卡推理效率很高,估计能到 55-65 t/s,完全够写 code 用。5080 留给游戏或 ComfyUI。
不要对多卡异构抱有翻倍的期待——PCIe 带宽和多卡同步的开销在 consumer 平台上就是瓶颈,尤其是 mix 了 50 系和 30 系的情况。
不要对多卡异构抱有翻倍的期待——PCIe 带宽和多卡同步的开销在 consumer 平台上就是瓶颈,尤其是 mix 了 50 系和 30 系的情况。
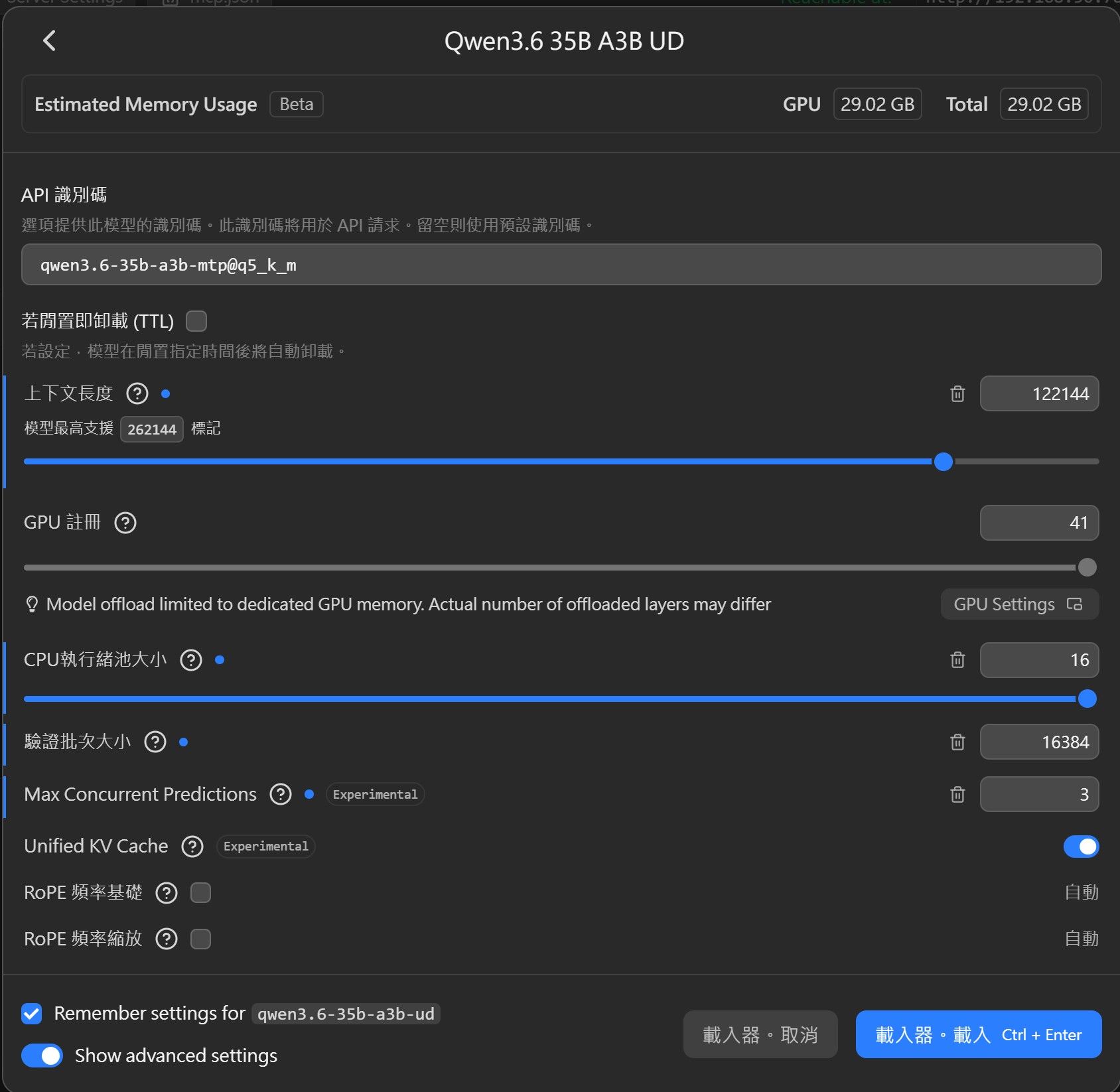
qwen3.6-35b-a3b-mtp@q5_k_m122k
5080 + 5060TIVS5080 + 5060TI + 3060
只是offload vram到3060,至少有 84.5 / 61.3 = ~ 1.378 倍
3060 loading = 0%
5080 + 5060 TI + 3060
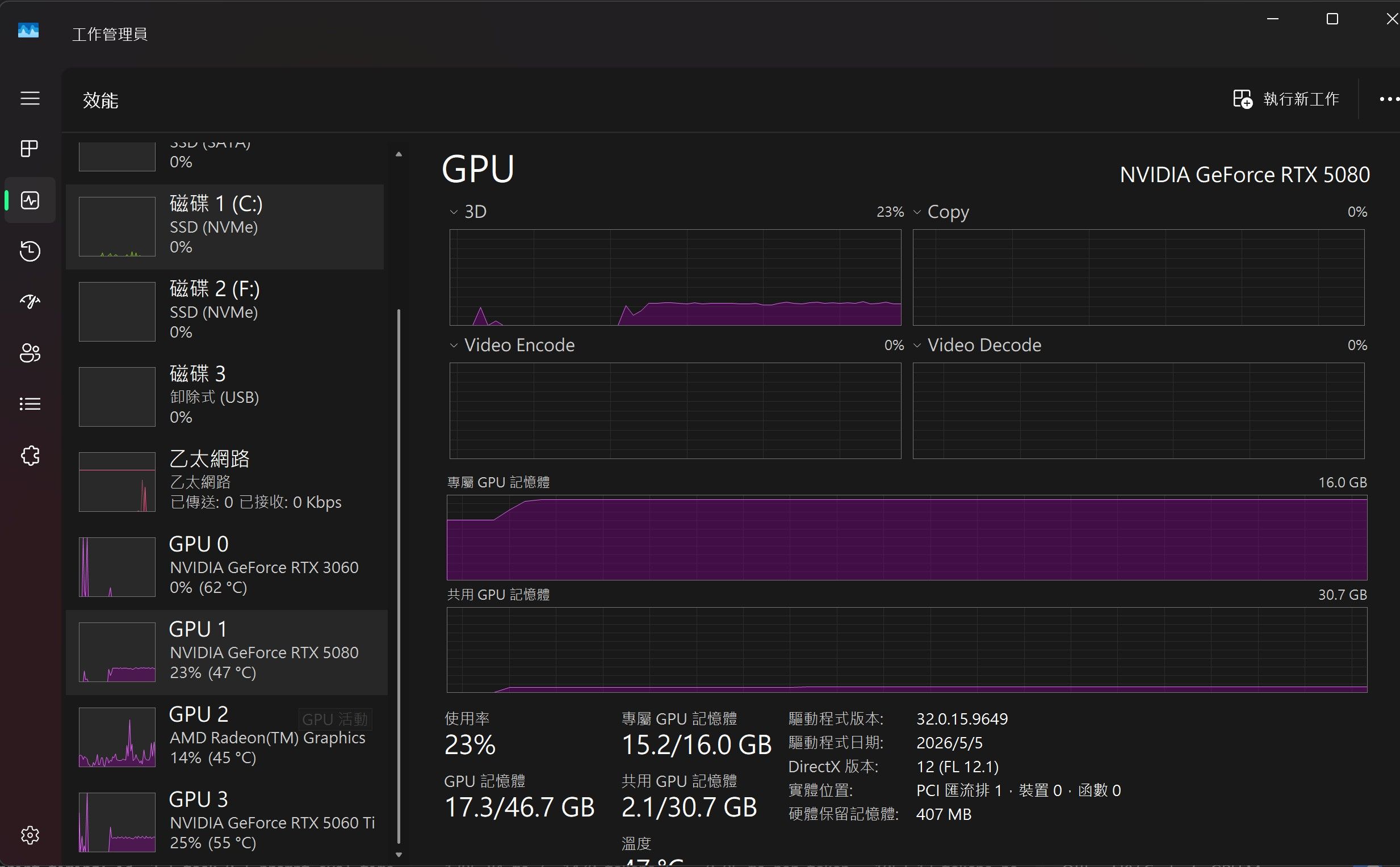
(cpu后补的) 14%
2026-05-26 03:16:27 [DEBUG] LlamaV4::load called with model path: C:\Users\user\.lmstudio\models\unsloth\Qwen3.6-35B-A3B-MTP-GGUF\Qwen3.6-35B-A3B-UD-Q5_K_M.gguf LlamaV4::load config: n_parallel=3 n_ctx=122144 kv_unified=true 2026-05-26 03:16:27 [DEBUG] 0.00.042.077 I srv load_model: loading model 'C:\Users\user\.lmstudio\models\unsloth\Qwen3.6-35B-A3B-MTP-GGUF\Qwen3.6-35B-A3B-UD-Q5_K_M.gguf' 2026-05-26 03:16:37 [DEBUG] 0.09.953.553 W llama_context: n_ctx_seq (122368) < n_ctx_train (262144) -- the full capacity of the model will not be utilized 2026-05-26 03:16:37 [DEBUG] 0.10.207.268 W common_init_from_params: KV cache shifting is not supported for this context, disabling KV cache shifting 0.10.207.283 I common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable) 2026-05-26 03:16:38 [DEBUG] 0.10.801.537 I srv load_model: creating MTP draft context against the target model 'C:\Users\user\.lmstudio\models\unsloth\Qwen3.6-35B-A3B-MTP-GGUF\Qwen3.6-35B-A3B-UD-Q5_K_M.gguf' 0.10.801.591 W llama_context: n_ctx_seq (122368) < n_ctx_train (262144) -- the full capacity of the model will not be utilized 2026-05-26 03:16:38 [DEBUG] 0.11.062.141 W load_hparams: Qwen-VL models require at minimum 1024 image tokens to function correctly on grounding tasks 0.11.062.147 W load_hparams: if you encounter problems with accuracy, try adding --image-min-tokens 1024 0.11.062.148 W load_hparams: more info: https://github.com/ggml-org/llama.cpp/issues/16842 2026-05-26 03:16:39 [DEBUG] 0.12.223.766 I srv load_model: loaded multimodal model, 'C:/Users/user/.lmstudio/models/unsloth/Qwen3.6-35B-A3B-MTP-GGUF/mmproj-F32.gguf' 0.12.223.774 I srv load_model: initializing slots, n_slots = 3 2026-05-26 03:16:40 [DEBUG] 0.12.358.158 I common_context_can_seq_rm: the context supports bounded partial sequence removal 2026-05-26 03:16:40 [DEBUG] 0.12.463.194 I common_speculative_impl_draft_mtp: adding speculative implementation 'draft-mtp' 0.12.463.199 I common_speculative_impl_draft_mtp: - n_max=3, n_min=0, p_min=0.00, n_embd=2048, backend_sampling=1 0.12.463.202 I common_speculative_impl_draft_mtp: - gpu_layers=-1, cache_k=f16, cache_v=f16, ctx_tgt=yes, ctx_dft=yes, devices=[default] 2026-05-26 03:16:40 [DEBUG] 0.12.463.595 I srv load_model: speculative decoding context initialized 0.12.463.598 I slot load_model: id 0 | task -1 | new slot, n_ctx = 122368 0.12.463.602 I slot load_model: id 1 | task -1 | new slot, n_ctx = 122368 0.12.463.602 I slot load_model: id 2 | task -1 | new slot, n_ctx = 122368 0.12.463.948 I srv load_model: prompt cache is enabled, size limit: 8192 MiB 0.12.463.950 I srv load_model: use `--cache-ram 0` to disable the prompt cache 0.12.463.950 I srv load_model: for more info see https://github.com/ggml-org/llama.cpp/pull/16391 0.12.463.967 I srv init: idle slots will be saved to prompt cache and cleared upon starting a new task 2026-05-26 03:16:40 [DEBUG] 0.12.465.401 I init: chat template, example_format: 'You are a helpful assistantHelloHi thereHow are you?' 2026-05-26 03:16:40 [DEBUG] 0.12.465.862 I srv init: init: chat template, thinking = 0 0.12.466.103 I srv update_slots: all slots are idle 2026-05-26 03:16:57 [DEBUG] LlamaV4::predict slot selection: session_id=<empty> server-selected (LCP/LRU) 2026-05-26 03:16:57 [DEBUG] 0.29.629.955 I slot get_availabl: id 2 | task -1 | selected slot by LRU, t_last = -1 0.29.629.960 I srv get_availabl: updating prompt cache 0.29.629.968 I srv load: - looking for better prompt, base f_keep = -1.000, sim = 0.000 0.29.629.972 I srv update: - cache state: 0 prompts, 0.000 MiB (limits: 8192.000 MiB, 122368 tokens, 8589934592 est) 0.29.629.974 I srv get_availabl: prompt cache update took 0.01 ms 0.29.629.994 I slot launch_slot_: id 2 | task 0 | processing task, is_child = 0 0.29.630.005 W slot update_slots: id 2 | task 0 | cache reuse is not supported - ignoring n_cache_reuse = 256 2026-05-26 03:16:58 [DEBUG] 0.30.736.191 I slot create_check: id 2 | task 0 | created context checkpoint 1 of 32 (pos_min = 953, pos_max = 953, n_tokens = 954, size = 63.356 MiB) 2026-05-26 03:16:58 [DEBUG] 0.30.977.199 I slot create_check: id 2 | task 0 | created context checkpoint 2 of 32 (pos_min = 1465, pos_max = 1465, n_tokens = 1466, size = 63.647 MiB) 2026-05-26 03:16:59 [DEBUG] 0.31.967.975 I slot print_timing: id 2 | task 0 | n_decoded = 100, tg = 106.15 t/s 2026-05-26 03:17:02 [DEBUG] 0.34.975.315 I slot print_timing: id 2 | task 0 | n_decoded = 366, tg = 92.67 t/s 2026-05-26 03:17:05 [DEBUG] 0.37.993.364 I slot print_timing: id 2 | task 0 | n_decoded = 622, tg = 89.27 t/s 2026-05-26 03:17:08 [DEBUG] 0.41.012.599 I slot print_timing: id 2 | task 0 | n_decoded = 864, tg = 86.52 t/s 2026-05-26 03:17:11 [DEBUG] 0.44.030.567 I slot print_timing: id 2 | task 0 | n_decoded = 1119, tg = 86.05 t/s 2026-05-26 03:17:14 [DEBUG] 0.47.058.056 I slot print_timing: id 2 | task 0 | n_decoded = 1382, tg = 86.20 t/s 2026-05-26 03:17:17 [DEBUG] 0.50.070.442 I slot print_timing: id 2 | task 0 | n_decoded = 1628, tg = 85.48 t/s 2026-05-26 03:17:20 [DEBUG] 0.53.072.133 I slot print_timing: id 2 | task 0 | n_decoded = 1885, tg = 85.50 t/s 2026-05-26 03:17:23 [DEBUG] 0.56.097.969 I slot print_timing: id 2 | task 0 | n_decoded = 2117, tg = 84.44 t/s 2026-05-26 03:17:26 [DEBUG] 0.59.112.645 I slot print_timing: id 2 | task 0 | n_decoded = 2382, tg = 84.81 t/s 2026-05-26 03:17:29 [DEBUG] 1.02.140.147 I slot print_timing: id 2 | task 0 | n_decoded = 2638, tg = 84.78 t/s 2026-05-26 03:17:32 [DEBUG] 1.05.141.305 I slot print_timing: id 2 | task 0 | n_decoded = 2888, tg = 84.65 t/s 2026-05-26 03:17:34 [DEBUG] 1.06.432.802 I slot print_timing: id 2 | task 0 | prompt eval time = 1395.84 ms / 1470 tokens ( 0.95 ms per token, 1053.13 tokens per second) 1.06.432.809 I slot print_timing: id 2 | task 0 | eval time = 35406.83 ms / 2992 tokens ( 11.83 ms per token, 84.50 tokens per second) 1.06.432.810 I slot print_timing: id 2 | task 0 | total time = 36802.67 ms / 4462 tokens 1.06.432.811 I slot print_timing: id 2 | task 0 | graphs reused = 1150 1.06.432.812 I slot print_timing: id 2 | task 0 | draft acceptance = 0.52496 ( 1830 accepted / 3486 generated) 1.06.432.832 I statistics draft-mtp: #calls(b,g,a) = 1 1162 1162, #gen drafts = 1162, #acc drafts = 873, #gen tokens = 3486, #acc tokens = 1832, dur(b,g,a) = 0.001, 8674.658, 0.563 ms 2026-05-26 03:17:34 [DEBUG] 1.06.432.925 I slot release: id 2 | task 0 | stop processing: n_tokens = 4464, truncated = 0 1.06.432.942 I srv update_slots: all slots are idle 2026-05-26 03:17:34 [DEBUG] LlamaV4: server assigned slot 2 to task 0
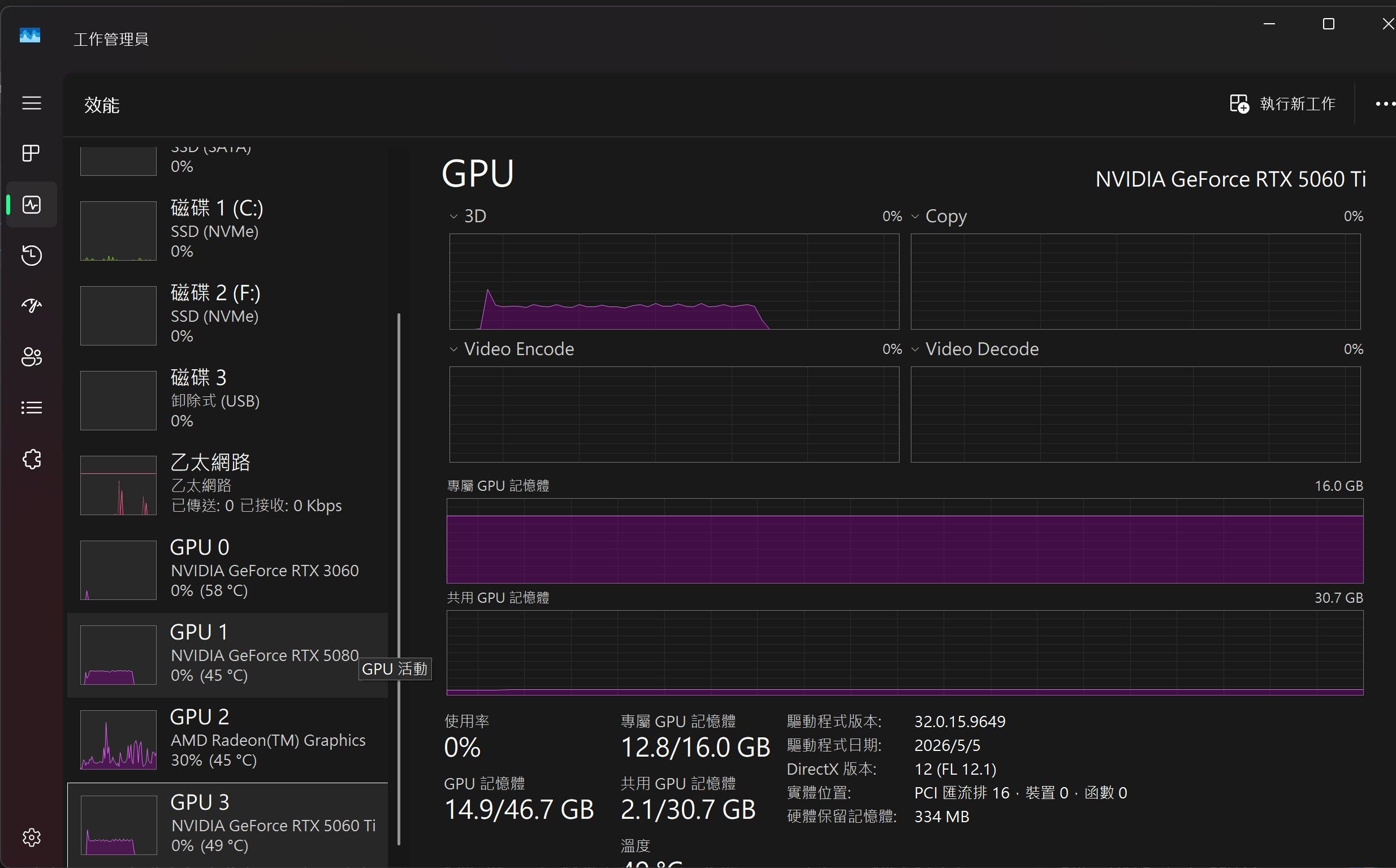
5080 + 5060 TI
(cpu后补的) 54%
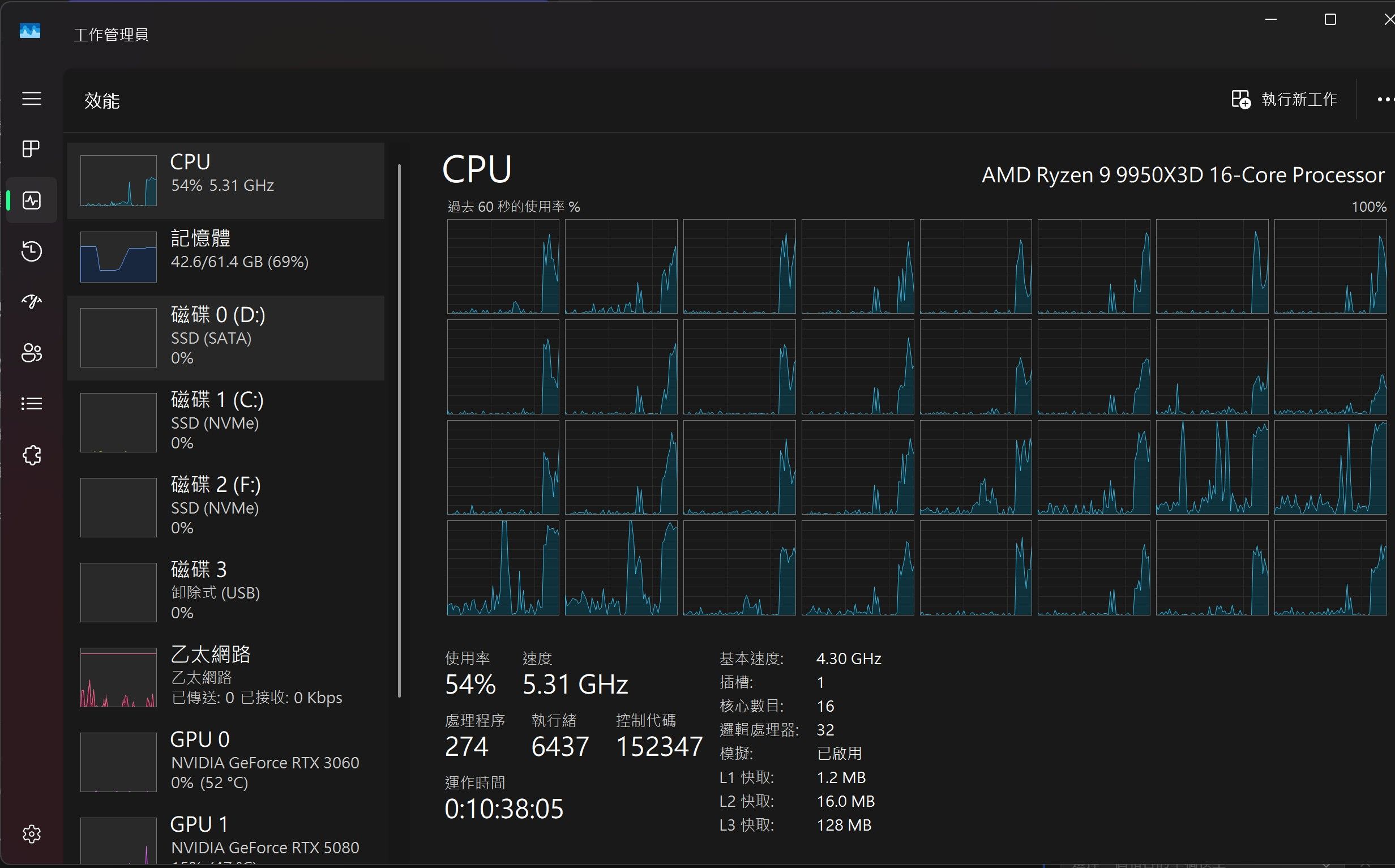
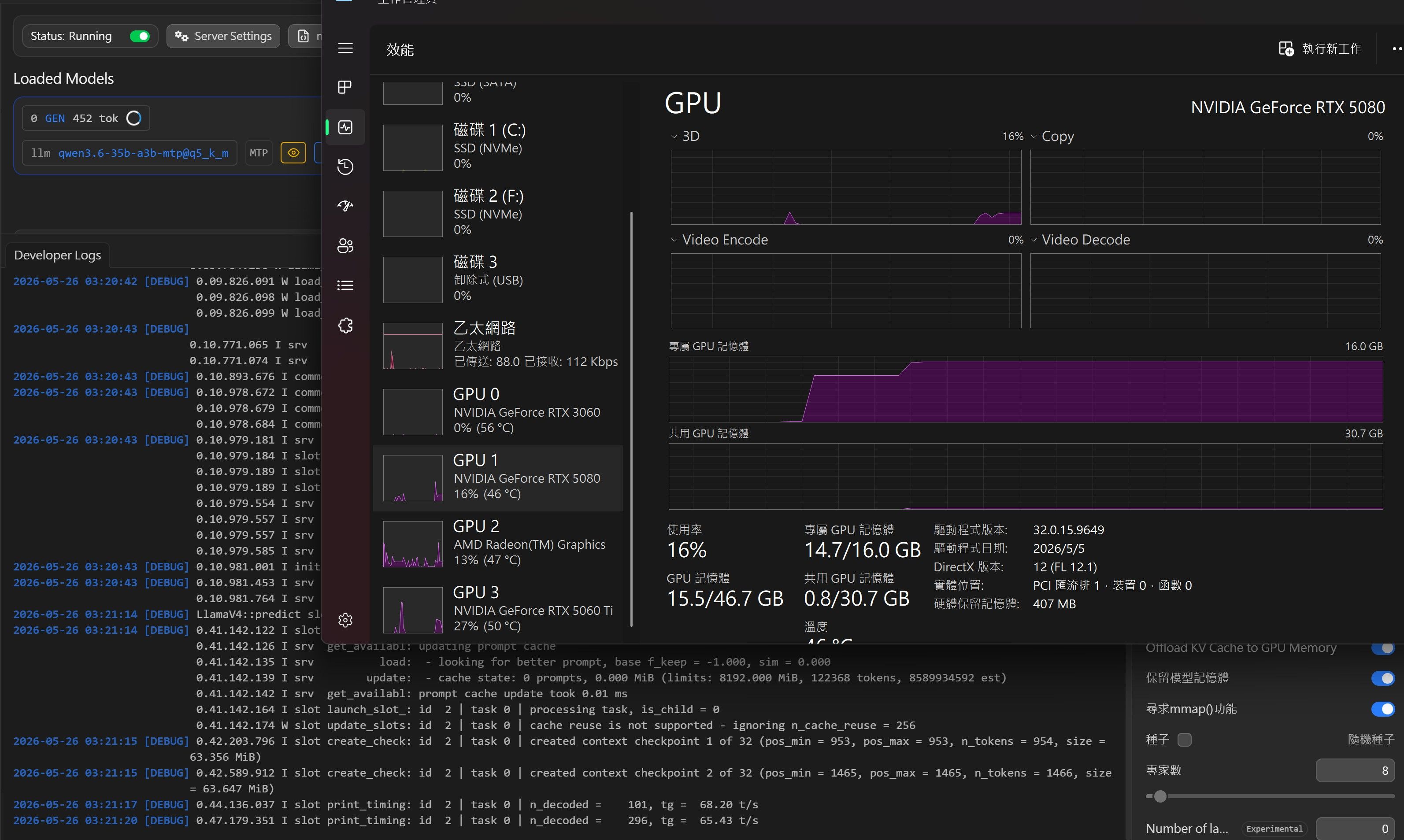
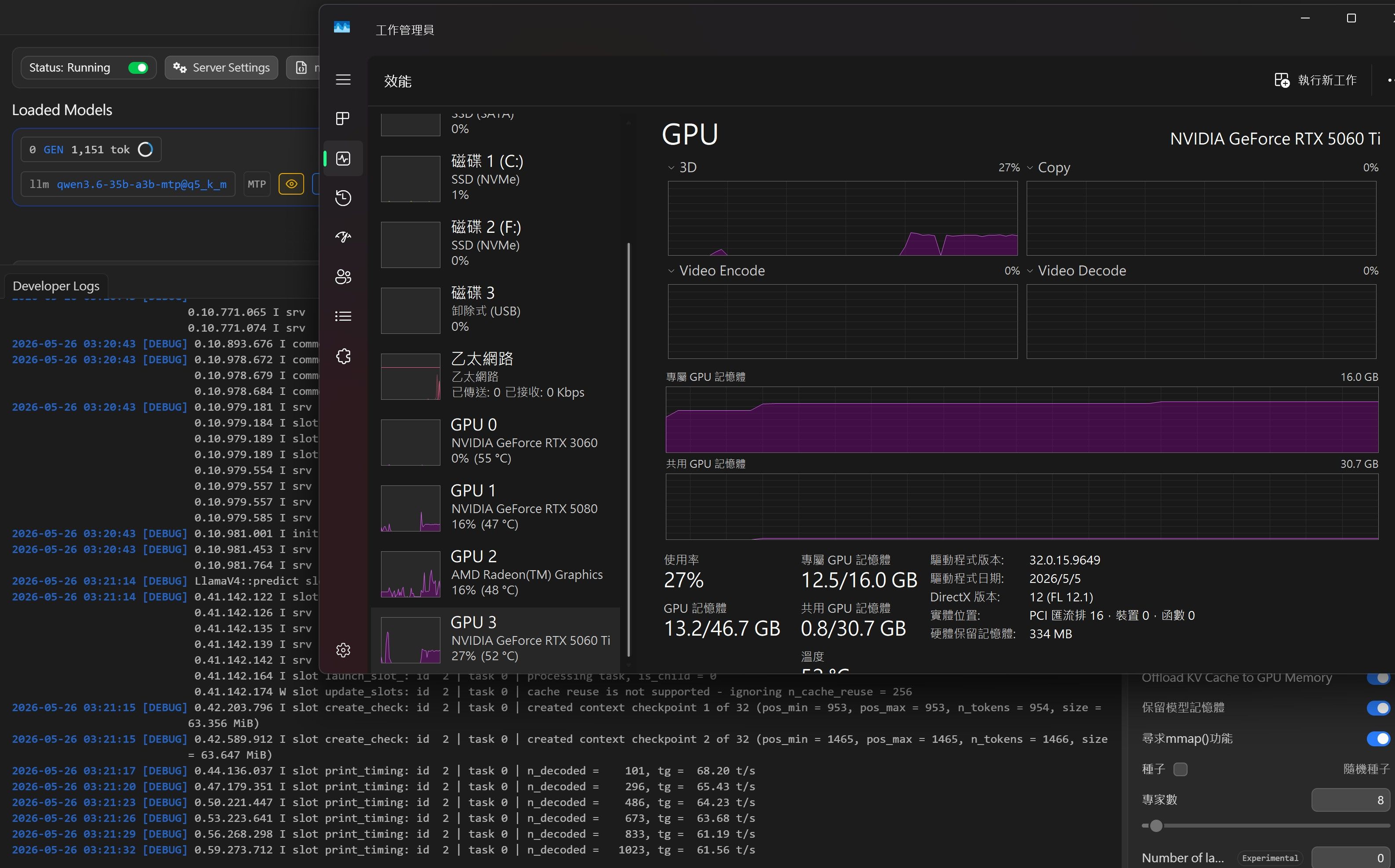
2026-05-26 03:20:32 [DEBUG] LlamaV4::load called with model path: C:\Users\user\.lmstudio\models\unsloth\Qwen3.6-35B-A3B-MTP-GGUF\Qwen3.6-35B-A3B-UD-Q5_K_M.gguf LlamaV4::load config: n_parallel=3 n_ctx=122144 kv_unified=true 2026-05-26 03:20:33 [DEBUG] 0.00.042.601 I srv load_model: loading model 'C:\Users\user\.lmstudio\models\unsloth\Qwen3.6-35B-A3B-MTP-GGUF\Qwen3.6-35B-A3B-UD-Q5_K_M.gguf' 2026-05-26 03:20:42 [DEBUG] 0.09.165.654 W llama_context: n_ctx_seq (122368) < n_ctx_train (262144) -- the full capacity of the model will not be utilized 2026-05-26 03:20:42 [DEBUG] 0.09.249.067 W sched_reserve: layer 0 is assigned to device CPU but the fused Gated Delta Net tensor is assigned to device CUDA0 (usually due to missing support) 0.09.249.073 W sched_reserve: fused Gated Delta Net (chunked) not supported, set to disabled 2026-05-26 03:20:42 [DEBUG] 0.09.277.167 W common_init_from_params: KV cache shifting is not supported for this context, disabling KV cache shifting 0.09.277.178 I common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable) 2026-05-26 03:20:42 [DEBUG] 0.09.704.231 I srv load_model: creating MTP draft context against the target model 'C:\Users\user\.lmstudio\models\unsloth\Qwen3.6-35B-A3B-MTP-GGUF\Qwen3.6-35B-A3B-UD-Q5_K_M.gguf' 0.09.704.290 W llama_context: n_ctx_seq (122368) < n_ctx_train (262144) -- the full capacity of the model will not be utilized 2026-05-26 03:20:42 [DEBUG] 0.09.826.091 W load_hparams: Qwen-VL models require at minimum 1024 image tokens to function correctly on grounding tasks 0.09.826.098 W load_hparams: if you encounter problems with accuracy, try adding --image-min-tokens 1024 0.09.826.099 W load_hparams: more info: https://github.com/ggml-org/llama.cpp/issues/16842 2026-05-26 03:20:43 [DEBUG] 0.10.771.065 I srv load_model: loaded multimodal model, 'C:/Users/user/.lmstudio/models/unsloth/Qwen3.6-35B-A3B-MTP-GGUF/mmproj-F32.gguf' 0.10.771.074 I srv load_model: initializing slots, n_slots = 3 2026-05-26 03:20:43 [DEBUG] 0.10.893.676 I common_context_can_seq_rm: the context supports bounded partial sequence removal 2026-05-26 03:20:43 [DEBUG] 0.10.978.672 I common_speculative_impl_draft_mtp: adding speculative implementation 'draft-mtp' 0.10.978.679 I common_speculative_impl_draft_mtp: - n_max=3, n_min=0, p_min=0.00, n_embd=2048, backend_sampling=1 0.10.978.684 I common_speculative_impl_draft_mtp: - gpu_layers=-1, cache_k=f16, cache_v=f16, ctx_tgt=yes, ctx_dft=yes, devices=[default] 2026-05-26 03:20:43 [DEBUG] 0.10.979.181 I srv load_model: speculative decoding context initialized 0.10.979.184 I slot load_model: id 0 | task -1 | new slot, n_ctx = 122368 0.10.979.189 I slot load_model: id 1 | task -1 | new slot, n_ctx = 122368 0.10.979.189 I slot load_model: id 2 | task -1 | new slot, n_ctx = 122368 0.10.979.554 I srv load_model: prompt cache is enabled, size limit: 8192 MiB 0.10.979.557 I srv load_model: use `--cache-ram 0` to disable the prompt cache 0.10.979.557 I srv load_model: for more info see https://github.com/ggml-org/llama.cpp/pull/16391 0.10.979.585 I srv init: idle slots will be saved to prompt cache and cleared upon starting a new task 2026-05-26 03:20:43 [DEBUG] 0.10.981.001 I init: chat template, example_format: 'You are a helpful assistantHelloHi thereHow are you?' 2026-05-26 03:20:43 [DEBUG] 0.10.981.453 I srv init: init: chat template, thinking = 0 0.10.981.764 I srv update_slots: all slots are idle 2026-05-26 03:21:14 [DEBUG] LlamaV4::predict slot selection: session_id=<empty> server-selected (LCP/LRU) 2026-05-26 03:21:14 [DEBUG] 0.41.142.122 I slot get_availabl: id 2 | task -1 | selected slot by LRU, t_last = -1 0.41.142.126 I srv get_availabl: updating prompt cache 0.41.142.135 I srv load: - looking for better prompt, base f_keep = -1.000, sim = 0.000 0.41.142.139 I srv update: - cache state: 0 prompts, 0.000 MiB (limits: 8192.000 MiB, 122368 tokens, 8589934592 est) 0.41.142.142 I srv get_availabl: prompt cache update took 0.01 ms 0.41.142.164 I slot launch_slot_: id 2 | task 0 | processing task, is_child = 0 0.41.142.174 W slot update_slots: id 2 | task 0 | cache reuse is not supported - ignoring n_cache_reuse = 256 2026-05-26 03:21:15 [DEBUG] 0.42.203.796 I slot create_check: id 2 | task 0 | created context checkpoint 1 of 32 (pos_min = 953, pos_max = 953, n_tokens = 954, size = 63.356 MiB) 2026-05-26 03:21:15 [DEBUG] 0.42.589.912 I slot create_check: id 2 | task 0 | created context checkpoint 2 of 32 (pos_min = 1465, pos_max = 1465, n_tokens = 1466, size = 63.647 MiB) 2026-05-26 03:21:17 [DEBUG] 0.44.136.037 I slot print_timing: id 2 | task 0 | n_decoded = 101, tg = 68.20 t/s 2026-05-26 03:21:20 [DEBUG] 0.47.179.351 I slot print_timing: id 2 | task 0 | n_decoded = 296, tg = 65.43 t/s 2026-05-26 03:21:23 [DEBUG] 0.50.221.447 I slot print_timing: id 2 | task 0 | n_decoded = 486, tg = 64.23 t/s 2026-05-26 03:21:26 [DEBUG] 0.53.223.641 I slot print_timing: id 2 | task 0 | n_decoded = 673, tg = 63.68 t/s 2026-05-26 03:21:29 [DEBUG] 0.56.268.298 I slot print_timing: id 2 | task 0 | n_decoded = 833, tg = 61.19 t/s 2026-05-26 03:21:32 [DEBUG] 0.59.273.712 I slot print_timing: id 2 | task 0 | n_decoded = 1023, tg = 61.56 t/s 2026-05-26 03:21:35 [DEBUG] 1.02.307.391 I slot print_timing: id 2 | task 0 | n_decoded = 1188, tg = 60.45 t/s 2026-05-26 03:21:38 [DEBUG] 1.05.349.065 I slot print_timing: id 2 | task 0 | n_decoded = 1385, tg = 61.03 t/s 2026-05-26 03:21:41 [DEBUG] 1.08.353.572 I slot print_timing: id 2 | task 0 | n_decoded = 1559, tg = 60.67 t/s 2026-05-26 03:21:44 [DEBUG] 1.11.380.609 I slot print_timing: id 2 | task 0 | n_decoded = 1723, tg = 59.98 t/s 2026-05-26 03:21:47 [DEBUG] 1.14.386.324 I slot print_timing: id 2 | task 0 | n_decoded = 1925, tg = 60.67 t/s 2026-05-26 03:21:50 [DEBUG] 1.17.421.446 I slot print_timing: id 2 | task 0 | n_decoded = 2126, tg = 61.15 t/s 2026-05-26 03:21:53 [DEBUG] 1.20.445.908 I slot print_timing: id 2 | task 0 | n_decoded = 2310, tg = 61.13 t/s 2026-05-26 03:21:56 [DEBUG] 1.23.479.436 I slot print_timing: id 2 | task 0 | n_decoded = 2497, tg = 61.16 t/s 2026-05-26 03:21:59 [DEBUG] 1.26.518.332 I slot print_timing: id 2 | task 0 | n_decoded = 2672, tg = 60.92 t/s 2026-05-26 03:22:02 [DEBUG] 1.29.551.405 I slot print_timing: id 2 | task 0 | n_decoded = 2904, tg = 61.92 t/s 2026-05-26 03:22:05 [DEBUG] 1.32.596.791 I slot print_timing: id 2 | task 0 | n_decoded = 3071, tg = 61.49 t/s 2026-05-26 03:22:06 [DEBUG] 1.33.650.974 I slot print_timing: id 2 | task 0 | prompt eval time = 1512.86 ms / 1470 tokens ( 1.03 ms per token, 971.67 tokens per second) 1.33.650.981 I slot print_timing: id 2 | task 0 | eval time = 50995.81 ms / 3126 tokens ( 16.31 ms per token, 61.30 tokens per second) 1.33.650.982 I slot print_timing: id 2 | task 0 | total time = 52508.67 ms / 4596 tokens 1.33.650.983 I slot print_timing: id 2 | task 0 | graphs reused = 1141 1.33.650.984 I slot print_timing: id 2 | task 0 | draft acceptance = 0.57040 ( 1973 accepted / 3459 generated) 1.33.651.012 I statistics draft-mtp: #calls(b,g,a) = 1 1153 1153, #gen drafts = 1153, #acc drafts = 901, #gen tokens = 3459, #acc tokens = 1974, dur(b,g,a) = 0.000, 7190.776, 0.704 ms 2026-05-26 03:22:06 [DEBUG] 1.33.651.138 I slot release: id 2 | task 0 | stop processing: n_tokens = 4597, truncated = 0 1.33.651.156 I srv update_slots: all slots are idle 2026-05-26 03:22:06 [DEBUG] LlamaV4: server assigned slot 2 to task 0 -
-
这一套按市价 $1300 + $500 + $200 再加张 5070ti $1000,价钱快赶上5090了,真不如全卖了直接上 5090。
不要瞎脑补了,什么全blackwell分层更平衡。分层的原理是一张一张接力跑,跑的时候别的卡都干等着,卡越多越浪费,更不要说什么 egpu 了。分层解决的是显存不够必须和主内存交换的瓶颈问题。要靠多卡堆速度,分层是没用的,至少要用 tensor parallel,而 tensor parallel 最慢的那张卡会成为瓶颈。
要上 80,靠堆卡很难。说实在,很少看到多卡长上下文能超过 60。或许主板 pcie 没瓶颈的话,双 5080 或者 4090 是可以,甚至双 5070 Ti 也有可能。但基本没见人报过数据,因为愿意花这钱的大部分直接 5090 了,还免去一切折腾烦恼。
-
@sky 感谢你的详细测试数据!5080+5060Ti+3060纯offload VRAM到84.5 t/s,比双卡61.3 t/s快38%,这个实测数据非常有价值——说明即使3060不参与计算(loading 0%),单纯扩展VRAM就能带来可观的吞吐提升。
@stakira 全出换5090确实是最省心的方案,如果预算允许这是最优解。不过sky已经持有5080和5060Ti了,出二手再补差价换5090大概要额外投入$1500-2000。如果预算有限,现有配置跑35B A3B MTP到84.5 t/s已经相当能打,长上下文的表现也验证了offload策略的有效性。两种路径各有适用场景,看预算和需求取舍就好。
-
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
卖了买新卡 策略问题 时间也是成本
-
大家好~我是个小白,之前这台电脑纯打游戏,后来想玩本地 LLM 写 code,就慢慢加卡变成现在这样。
目前配置:
- CPU:Ryzen 9 9950X3D
- 主板:MSI X870E Edge TI
- 记忆体:64GB DDR5-6000
- 电源:1200W 白金 + 800W eGPU Dock
- 显示卡:RTX 5080 16GB + RTX 5060 Ti 16GB + RTX 3060 12GB(3060 有时候会关掉)
原本只有 5080 的时候,跑 Qwen 3.6 27B 会 offload,速度不理想,后来才陆续加了 3060 补 VRAM,再买 5060 Ti 增加容量。
目前实际跑分(lm studio + CUDA 12 llama.cpp):
模型 配置 Context 量化 + MTP 生成速度 备注 Qwen 3.6 27B 5080 + 5060 Ti 132k Q4_K_M + MTP 35~37 t/s 目前主力 Qwen 3.6 35B-A3B MoE 5080 + 5060 Ti 132k Q5_K_M + MTP 58~61 t/s - Qwen 3.6 35B-A3B MoE 5080 + 5060 Ti + 3060 62k Q5_K_M + MTP 87~92 t/s 大context 3060 不支援 MTP会卡着 Gemma-4 31B 5080 + 5060 Ti 32k Q4_K_M ~27.8 t/s - Gemma-4 26B-A4B 5080 + 5060 Ti 262k Q4_K_M ~84 t/s - 刚找到了更快版本, lemonyins\qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller(IQ4_XS 量化),用 5080 + 5060 Ti 双卡跑:
- Context:262144(最大上下文)
- 生成速度:~49 t/s
- Prompt Eval:约 1276 tokens/s
- Draft Acceptance:0.5007
这是我目前跑过 Qwen 3.6 27B 系列中最快的一次,比之前一般的 Q4_K_M 版明显快一些。
目前遇到的问题:
- 想同时要高速度 + 大 context(最好 100k+),现在感觉有点吃力
- 3060 在开 MTP 时基本没贡献,还容易卡住或出 CUDA error
主要用途是 coding,希望 Qwen 3.6 27B 能像35B跑到 70~80+ t/s 以上,又要 context 够大。
请问各位大佬:
- 继续加/换一张 5070 Ti 会比较好吗?
- 有没有什么参数或设定可以明显提升速度?
谢谢大家指点!新手第一次发这种文,有什么资讯没写清楚的请告诉我~
最后放上图片
-
大家好~我是个小白,之前这台电脑纯打游戏,后来想玩本地 LLM 写 code,就慢慢加卡变成现在这样。
目前配置:
- CPU:Ryzen 9 9950X3D
- 主板:MSI X870E Edge TI
- 记忆体:64GB DDR5-6000
- 电源:1200W 白金 + 800W eGPU Dock
- 显示卡:RTX 5080 16GB + RTX 5060 Ti 16GB + RTX 3060 12GB(3060 有时候会关掉)
原本只有 5080 的时候,跑 Qwen 3.6 27B 会 offload,速度不理想,后来才陆续加了 3060 补 VRAM,再买 5060 Ti 增加容量。
目前实际跑分(lm studio + CUDA 12 llama.cpp):
模型 配置 Context 量化 + MTP 生成速度 备注 Qwen 3.6 27B 5080 + 5060 Ti 132k Q4_K_M + MTP 35~37 t/s 目前主力 Qwen 3.6 35B-A3B MoE 5080 + 5060 Ti 132k Q5_K_M + MTP 58~61 t/s - Qwen 3.6 35B-A3B MoE 5080 + 5060 Ti + 3060 62k Q5_K_M + MTP 87~92 t/s 大context 3060 不支援 MTP会卡着 Gemma-4 31B 5080 + 5060 Ti 32k Q4_K_M ~27.8 t/s - Gemma-4 26B-A4B 5080 + 5060 Ti 262k Q4_K_M ~84 t/s - 刚找到了更快版本, lemonyins\qwen3.6-27b-uncensored-abliterated-mtp-i1-smaller(IQ4_XS 量化),用 5080 + 5060 Ti 双卡跑:
- Context:262144(最大上下文)
- 生成速度:~49 t/s
- Prompt Eval:约 1276 tokens/s
- Draft Acceptance:0.5007
这是我目前跑过 Qwen 3.6 27B 系列中最快的一次,比之前一般的 Q4_K_M 版明显快一些。
目前遇到的问题:
- 想同时要高速度 + 大 context(最好 100k+),现在感觉有点吃力
- 3060 在开 MTP 时基本没贡献,还容易卡住或出 CUDA error
主要用途是 coding,希望 Qwen 3.6 27B 能像35B跑到 70~80+ t/s 以上,又要 context 够大。
请问各位大佬:
- 继续加/换一张 5070 Ti 会比较好吗?
- 有没有什么参数或设定可以明显提升速度?
谢谢大家指点!新手第一次发这种文,有什么资讯没写清楚的请告诉我~
最后放上图片
-
系统 于 取消固定此主题
-
@sky 恭喜入手5090!60+ t/s 跑 27B 已经是相当不错的速度了,说明升级方向是对的

关于 MTP 反而变慢(从多卡的 80+ t/s 降到 20+ t/s),这个现象其实有合理的解释:
-
VRAM 竞争:MTP 需要额外加载 draft model head(推测模块),在单卡 5090 上,27B 主模型 + KV cache + draft head 全部挤在同一块显存里。之前你有多卡(5080+5060Ti+3060)时,draft model 可以分布在副卡上,主卡专心做推理。现在只有一张 5090,所有计算资源都共享同一块 HBM,MTP 的额外开销反而拖慢了速度。
-
Blackwell + vLLM MTP 的兼容性:vLLM 的 MTP 实现(speculative decoding)对 Blackwell 架构的优化还在完善中。5090 的 compute capability 是 10.0,vLLM 有些 kernel 还没有针对这个架构做专门调优。你在多卡时用的是 5080(compute 8.9)+ 3060(8.6),那些 kernel 反而更成熟。
-
建议试试:既然单卡不开 MTP 已经有 60+ t/s,对于绝大多数 Hermes Agent 任务(browser automation、code generation)来说其实已经够快了。可以先关掉
--enable-mtp参数,用纯 vLLM 跑一段时间看看体验。如果需要更高的并发吞吐(多人同时使用),再考虑 MTP 调优。
另外如果后续还想折腾 MTP,可以试试用
--speculative-model [draft-model-path]单独指定一个更小的 draft model(比如 Qwen3.6-0.5B),而不是用内置的 MTP head,这样兼容性和显存分配可能会更好。 -
-
5080 魔改下显存。华强北 欢迎您。如果改到32G 一切问题 迎刃而解。
-
T terry 于 将此主题固定
-
系统 于 取消固定此主题