
Throughput on RTX 3090 (Qwen3.6-27B AWQ-Marlin BF16, BF16 KV, ctx=2048)
-
很有价值。谢谢。claude 选的什么版本?现在 open AI 5.5 有人使用调试成功了。claude 这是也站起来了。
个人主页:xlkj.org Telegram https://t.me/xlkjorg
-
很有价值。谢谢。claude 选的什么版本?现在 open AI 5.5 有人使用调试成功了。claude 这是也站起来了。
@williamlouis claude就用的opus 4.7,3090感觉目前跑不了qwen 3.6 27b sglang
-
@terry 4090 48g应该跑得下来,3090 24g sglang目前估计够呛,需要两张卡
-
@williamlouis claude就用的opus 4.7,3090感觉目前跑不了qwen 3.6 27b sglang
@Larry-Wang 价格放哪了。opus 4.7 造价不菲啊。建议重点调试用。或试试国产。
-
@williamlouis claude就用的opus 4.7,3090感觉目前跑不了qwen 3.6 27b sglang
-
@Larry-Wang opus 4.7 比 deepseek 4.0 pro 到底好在哪呢?
-
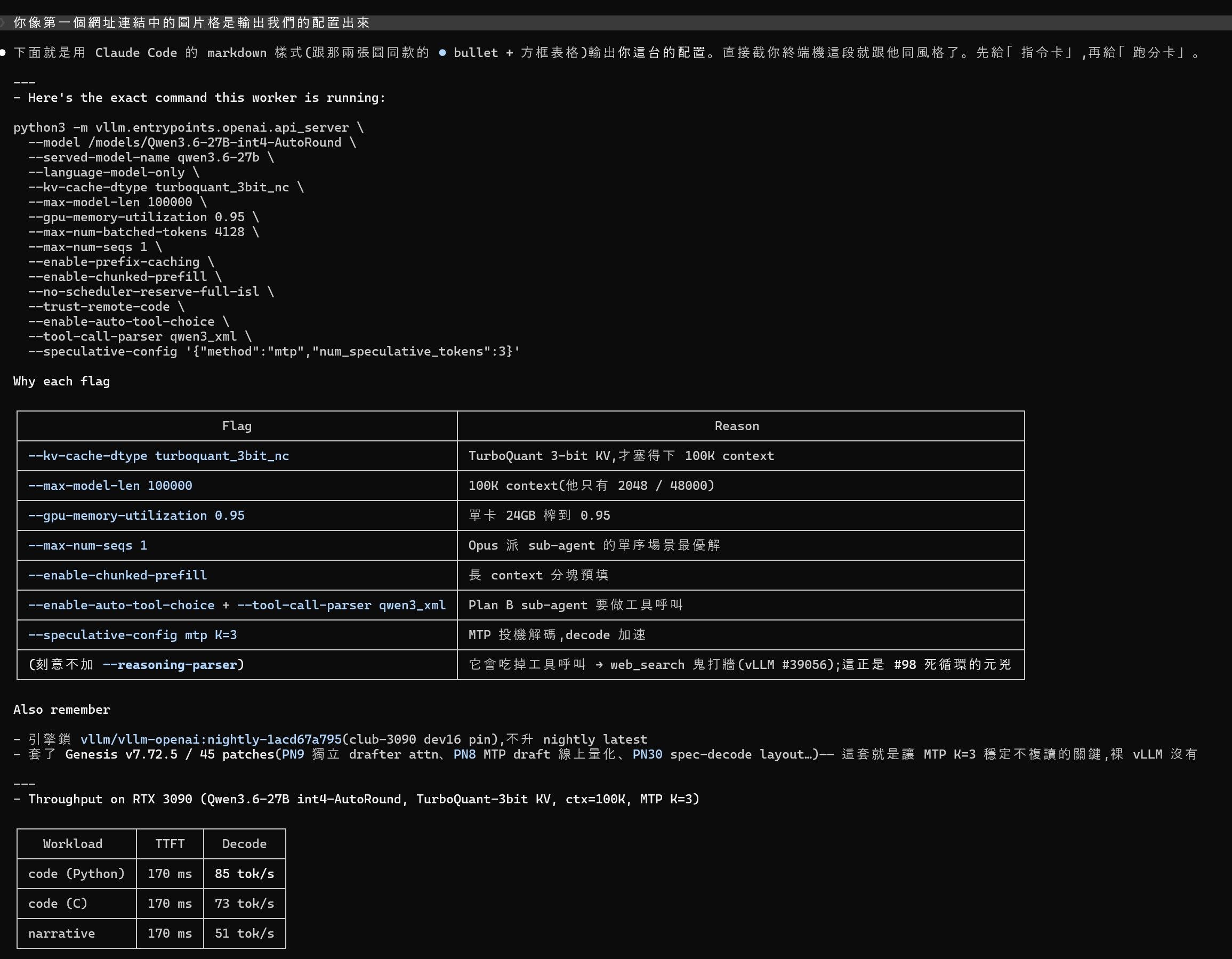
我也是用claude架的,這是我的配置 -
vLLM 可以運行 32k 上下文,對於Agent用途來說還不錯,MTP速度為 50~60 tk/s @250w
--model ~/AiModel/int4-AutoRound
--gpu-memory-utilization 0.95
--max-model-len 32768
--enable-auto-tool-choice
--tool-call-parser qwen3_coder 0
--language-model-only
--host 0.0.0.0 --port 8000
--kv-cache-dtype fp8_e5m2
--max-num-seqs 1
--max-num-batched-tokens 4128
--trust-remote-code
--dtype bfloat16
--enable-prefix-caching
--enable-chunked-prefill
--no-scheduler-reserve-full-isl
--speculative-config '{"method":"mtp","num_speculative_tokens":3}'