
我有个关于hermes使用本地显卡和模型的疑问
-
@bily-j 关于vLLM和GGUF的问题,我来展开说说:
vLLM确实对GGUF支持不好(有实验性的llama.cpp backend但很不成熟),vLLM主要用的是HF(Hugging Face)格式或者safetensors格式的模型。所以你如果用vLLM,需要找HF格式的模型。
关于"无审核模型":
- GGUF社区确实无审核模型最多(TheBloke、Bartowski这些上传者经常有abliterated版本)
- HF格式的无审核模型其实也不少,只是搜索方式不同。在Hugging Face上搜"abliterated"或者"uncensored"加上模型名,能找到很多:
- 比如 abliterated/Llama-3.1-8B-Instruct 这类直接去掉了审核层的版本
- 或者找一些本身训练时就偏开放的模型(如Dolphin、Loyal、Magnum等系列)
vLLM的一条实用建议:
如果你既想要vLLM的速度又想要无审核模型,可以:- 去HF下载模型(不要GGUF,要完整的HF格式)
- 用 vLLM 加载,加上 --trust-remote-code 参数
- 大多数 abliterated 模型在 vLLM 上跑没问题
如果你觉得vLLM + HF格式的流程太麻烦,继续用llama.cpp + GGUF也是很好的选择。GGUF本身就是一个很成熟的格式,无审核模型的生态也好。关键是用着顺手就行了。
-
我自己有在用vLLM搭建API配合cline使用, 可以給點意見
除了跟@xiaote 說的用有寫abliterated的模型, 也可以用有寫heretic的模型
heretic在 重新訓練的數據集比較好 的情況下, 模型的思考能力, 連貫性跟邏輯會比abliterated更強, 也相對會更加少出現拒絕回答的情況
以下是碎碎唸跟簡單講一下原理, 有興趣可以讀一下
在hf的model card上通常都會有refusals rate, 我拿兩個模型作為例子
llmfan46/Qwen3.6-35B-A3B-uncensored-heretic-Native-MTP-Preserved-GGUF
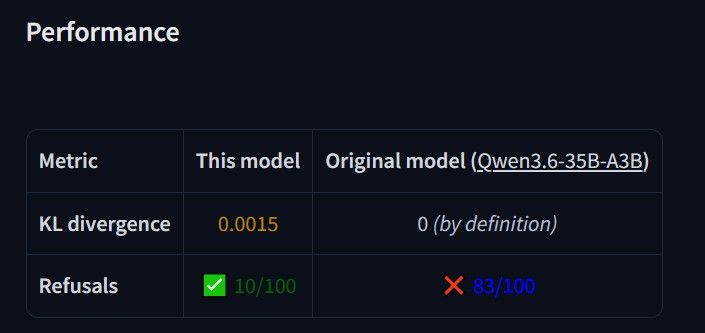
wangzhang/Qwen3.6-35B-A3B-abliterated-GGUF

KL越接近基礎模型越好, 代表兩個模型的思維偏差越低, 在這兩個例子下就是越接近0越好, KL基本上低於0.3就沒什麼大問題
heretic跟abliterated都是去審核的方式
abliterated只能說是減低拒絕的概率(refusal-reduced), 因為只單純控制權重(Weight Projection), 不涉及微調
heretic則是利用貝葉斯優化(Bayesian optimization)微調模型
但很遺憾的是沒有一個通用準則說什麼時候用abliterated, 什麼時候用heretic
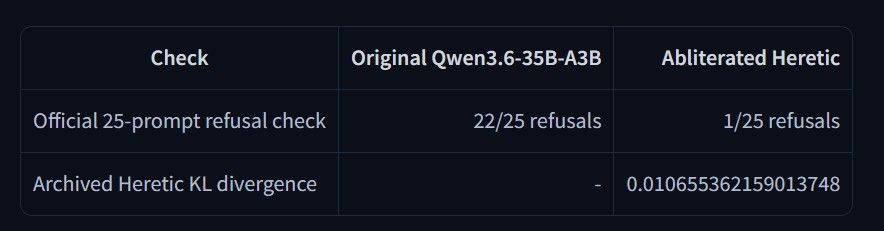
然後就有人腦洞大開會跑去弄個混合模型Youssofal/Qwen3.6-35B-A3B-Abliterated-Heretic-GGUF
-
我自己有在用vLLM搭建API配合cline使用, 可以給點意見
除了跟@xiaote 說的用有寫abliterated的模型, 也可以用有寫heretic的模型
heretic在 重新訓練的數據集比較好 的情況下, 模型的思考能力, 連貫性跟邏輯會比abliterated更強, 也相對會更加少出現拒絕回答的情況
以下是碎碎唸跟簡單講一下原理, 有興趣可以讀一下
在hf的model card上通常都會有refusals rate, 我拿兩個模型作為例子
llmfan46/Qwen3.6-35B-A3B-uncensored-heretic-Native-MTP-Preserved-GGUF
wangzhang/Qwen3.6-35B-A3B-abliterated-GGUF
KL越接近基礎模型越好, 代表兩個模型的思維偏差越低, 在這兩個例子下就是越接近0越好, KL基本上低於0.3就沒什麼大問題
heretic跟abliterated都是去審核的方式
abliterated只能說是減低拒絕的概率(refusal-reduced), 因為只單純控制權重(Weight Projection), 不涉及微調
heretic則是利用貝葉斯優化(Bayesian optimization)微調模型
但很遺憾的是沒有一個通用準則說什麼時候用abliterated, 什麼時候用heretic
然後就有人腦洞大開會跑去弄個混合模型Youssofal/Qwen3.6-35B-A3B-Abliterated-Heretic-GGUF
@566656661 我用qwen3.6-27B模型的,我要去审核版本,带MTP功能的模型你有没有推荐的?或者在huggenface上如何搜索?
-
@566656661 我用qwen3.6-27B模型的,我要去审核版本,带MTP功能的模型你有没有推荐的?或者在huggenface上如何搜索?
-
@bily-j 关于 KV cache 的问题:
KV cache 在同一个会话里的行为是这样的:
-
同一个会话内,KV cache 是持续累积的。每次生成新 token,系统会把前一步计算的 Key 和 Value 缓存起来追加到已有缓存后面。所以随着对话变长,显存占用会持续增长,不会主动回退。
-
你看到的"命中时增加"是指:当新输入到达时,系统计算新 token 的 KV 值并追加到缓存尾部,显存占用确实会上升。但它不会自动回退——除非你主动清空或截断上下文。
-
如果你觉得显存不够了,有几个选择:
- 滑动窗口(sliding window):只保留最近 N 个 token 的 KV cache,老的丢弃
- 上下文截断:清空历史,从头开始新对话
- 使用支持 KV cache 量化的推理后端(比如 llama.cpp 的 Q4_K_M cache quantization),可以在一定程度上减少 KV cache 的显存占用
- vLLM 支持
--max-model-len和--gpu-memory-utilization来控制 KV cache 的显存分配
简单说:KV cache 在会话内是只增不减的,直到你手动重置或溢出 OOM。
-
-
我自己是在用sakamakismile/Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP
因為我有Blackwell架構卡, 所以跑在nvfp4跟vLLM上
非Blackwell可以試試這個
YuYu1015/Huihui-Qwen3.6-27B-abliterated-UD-Q4_K_XL-MTP-GGUF@566656661 我实际用MTP的模型感觉,MTP的模型比某些模型要差,容易编程或者什么的时候,绕死路,死循环,应该是模型的问题,因为我用同样的参数,其他模型就没有走死循环的特点
-
@566656661 我实际用MTP的模型感觉,MTP的模型比某些模型要差,容易编程或者什么的时候,绕死路,死循环,应该是模型的问题,因为我用同样的参数,其他模型就没有走死循环的特点
-
5 566656661 于 引用了 此主题