
論 迷你電腦 配合 RTX Pro 4500 的簡單測試, 以及Blackwell架構下的一些嘗試 (僅限Dense模型)
-
TLDR
先上個實體圖
Beelink Ser 8 8745HS 用Oculink連接 RTX Pro 4500
跑在Ubuntu 26.04, Kernel 7.0
因爲Oculink的關係, 不會考慮使用MoE

啓動咒語, 注意這個是我在vLLM cu130 nightly (0.20)設立的, cu129 0.22估計會有更多優化, 我會試試看其他版本
docker run -d \ --name vllm-Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP \ --restart unless-stopped \ --ipc host \ --gpus '"device=0"' \ -p 0.0.0.0:7380:8000 \ -v "~/vllm/models:/models:ro" \ -v "~/vllm/.cache/huggingface:/root/.cache/huggingface" \ -e GPU_MEMORY_UTILIZATION="0.95" \ -e HF_HUB_OFFLINE="1" \ -e KV_CACHE_DTYPE="fp8" \ -e MAX_MODEL_LEN="230400" \ -e MODEL_PATH="/models/sakamakismile/Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP" \ -e PYTORCH_CUDA_ALLOC_CONF="expandable_segments:True" \ -e SERVED_MODEL_NAME="Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP" \ -e VLLM_ATTENTION_BACKEND="FLASHINFER" \ -e VLLM_EXTRA_ARGS='--quantization modelopt --trust-remote-code --enable-chunked-prefill --reasoning-parser qwen3 --tool-call-parser qwen3_coder --enable-auto-tool-choice --max-num-seqs 1 --max-num-batched-tokens 4096 --speculative-config {"method":"qwen3_5_mtp","num_speculative_tokens":3} --language-model-only --performance-mode interactivity --attention-backend flashinfer --skip-mm-profiling --enable-prefix-caching --no-disable-hybrid-kv-cache-manager' \ -e VLLM_LOGGING_LEVEL="INFO" \ -e VLLM_NVFP4_GEMM_BACKEND="flashinfer-cutlass" \ -e VLLM_USE_FLASHINFER_MOE_FP4="0" \ -e VLLM_USE_FLASHINFER_SAMPLER="1" \ --health-cmd 'curl -fsS http://localhost:8000/v1/models || exit 1' \ --health-timeout 5s \ --health-interval 30s \ --health-retries 5 \ --health-start-period 5m \ --entrypoint /bin/bash \ vllm/vllm-openai:cu130-nightly \ -lc 'exec vllm serve "$MODEL_PATH" --served-model-name "$SERVED_MODEL_NAME" --host 0.0.0.0 --port 8000 --max-model-len "$MAX_MODEL_LEN" --gpu-memory-utilization "$GPU_MEMORY_UTILIZATION" --kv-cache-dtype "$KV_CACHE_DTYPE" $VLLM_EXTRA_ARGS'llama-benchy benchmark
llama-benchy \ --base-url "http://localhost:7380/v1" \ --model "Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP" \ --tokenizer "$HOME/vllm/models/sakamakismile/Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP" \ --pp 2048 \ --tg 480 \ --depth 0 1000 5000 10000 20000 50000 100000 150000 200000 \ #(不同上下文長度) --latency-mode generation \ --skip-coherence \ --concurrency 1 \效果
| model | test | t/s | peak t/s | ttfr (ms) | est_ppt (ms) | e2e_ttft (ms) | |:-----------------------------------------|-----------------:|------------------:|-------------:|------------------:|------------------:|------------------:| | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 | 7741.01 ± 1375.30 | | 373.94 ± 54.49 | 274.26 ± 54.49 | 373.94 ± 54.49 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 | 68.87 ± 6.65 | 81.33 ± 3.68 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d1000 | 8136.73 ± 32.84 | | 474.32 ± 1.44 | 374.64 ± 1.44 | 474.32 ± 1.44 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d1000 | 67.73 ± 5.06 | 88.00 ± 5.72 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d5000 | 6615.23 ± 22.79 | | 1165.21 ± 3.86 | 1065.53 ± 3.86 | 1165.21 ± 3.86 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d5000 | 72.92 ± 3.56 | 89.33 ± 3.77 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d10000 | 6008.73 ± 10.16 | | 2104.88 ± 3.47 | 2005.20 ± 3.47 | 2104.88 ± 3.47 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d10000 | 65.25 ± 2.21 | 82.00 ± 4.32 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d20000 | 5152.21 ± 0.52 | | 4379.13 ± 0.52 | 4279.45 ± 0.52 | 4380.19 ± 0.46 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d20000 | 70.45 ± 1.27 | 89.67 ± 0.47 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d50000 | 3690.36 ± 5.88 | | 14203.66 ± 22.59 | 14103.98 ± 22.59 | 14205.86 ± 22.80 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d50000 | 67.03 ± 1.67 | 84.67 ± 0.47 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d100000 | 2528.58 ± 0.55 | | 40457.51 ± 8.72 | 40357.83 ± 8.72 | 40461.50 ± 8.69 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d100000 | 60.96 ± 0.75 | 78.33 ± 3.68 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d150000 | 1922.36 ± 0.98 | | 79194.84 ± 39.68 | 79095.17 ± 39.68 | 79201.49 ± 39.50 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d150000 | 62.53 ± 3.29 | 76.33 ± 1.89 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d200000 | 1556.00 ± 0.99 | | 129951.65 ± 82.49 | 129851.97 ± 82.49 | 129959.72 ± 82.53 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d200000 | 59.58 ± 1.31 | 69.67 ± 1.70 | | | |
碎碎唸, 講一下參數選擇邏輯
GPU_MEMORY_UTILIZATION => 0.95, Headless伺服器, 顯示輸出由iGPU負責 KV_CACHE_DTYPE => FP8, Ada架構以後基本統一FP8 MAX_MODEL_LEN => 230K, 之前有嘗試試過極限拉到240K左右, 但是會在部分長上下文出現OOM, 穩定點用230K PYTORCH_CUDA_ALLOC_CONF => Pytorch實驗性參數, 透過呼叫CUDA内核API整理VRAM碎塊, 降低OOM機會 VLLM_ATTENTION_BACKEND => FLASHINFER, 很奇怪的是vLLM是推薦用這個而不是Flash Attention, 理論上在NVFP4在sm 12X (Desktop Blackwell)還沒完善下的情況用FA估計會比較好, 在sm 10X (Datacenter Blackwell)則FLASHINFER比較好 quantization => modelopt, vllm會跑去讀hf_quant_config.json裏的quant_algo, 這個模型是nvfp4 enable-chunked-prefill => 必開不解釋, 優化VRAM避免Spike導致OOM speculative-config => 2 或者 3 都可, 激進點就用了3 skip-mm-profiling => 因爲這個模型只支持Text, 所以不需要multi model設定,省點VRAM enable-prefix-caching => 降低TTRT no-disable-hybrid-kv-cache-manager => 避免因爲Qwen模型的混合Attention導致挂掉 VLLM_NVFP4_GEMM_BACKEND => 叫vLLM 使用 FlashInfer/Cutlass NVFP4 kernels進行矩陣計算, Blackwell特點 VLLM_USE_FLASHINFER_MOE_FP4 (0) + VLLM_USE_FLASHINFER_SAMPLER (1) => 優化CUDA内核 -
@566656661 單卡25萬左右還是太硬了,我的微薄月薪還要先扣 ai 税,除非有額外的收入可以回本,我目前已經有一張 R9700 可以玩,目前是在考慮第二張可以選 R9700 或是 B70 或是捏一下上 Pro 4500
-
基準測試
vLLM cu130 nightly (0.20) -> v0.22.1 cu129, 其餘包括benchmark不變
之後測試如果沒再提及Docker Image變化請默認為 v0.22.1-cu129-ubuntu2404
打了瞌睡, 發現原來參數沒刪乾淨, 只能帶著舊參數 + 新docker image 跑了測試如下
| model | test | t/s | peak t/s | ttfr (ms) | est_ppt (ms) | e2e_ttft (ms) | | :--------------------------------------- | ---------------: | ----------------: | -----------: | -----------------: | -----------------: | -----------------: | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 | 4112.24 ± 2335.79 | | 1000.79 ± 713.91 | 882.88 ± 713.91 | 1000.79 ± 713.91 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 | 70.62 ± 0.93 | 90.67 ± 1.25 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d1000 | 6522.05 ± 180.65 | | 585.81 ± 13.00 | 467.90 ± 13.00 | 585.81 ± 13.00 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d1000 | 72.00 ± 4.34 | 87.00 ± 0.82 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d5000 | 5716.09 ± 781.76 | | 1377.22 ± 190.64 | 1259.31 ± 190.64 | 1377.22 ± 190.64 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d5000 | 71.20 ± 1.68 | 90.33 ± 3.40 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d10000 | 5791.35 ± 64.74 | | 2198.74 ± 23.28 | 2080.84 ± 23.28 | 2198.74 ± 23.28 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d10000 | 70.74 ± 7.93 | 86.67 ± 4.19 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d20000 | 5015.72 ± 8.10 | | 4513.90 ± 7.10 | 4395.99 ± 7.10 | 4515.13 ± 6.99 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d20000 | 68.54 ± 4.81 | 86.67 ± 3.68 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d50000 | 3643.75 ± 3.58 | | 14402.48 ± 14.02 | 14284.58 ± 14.02 | 14404.87 ± 13.87 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d50000 | 71.21 ± 6.44 | 86.67 ± 1.25 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d100000 | 2495.95 ± 3.04 | | 41003.94 ± 49.73 | 40886.04 ± 49.73 | 41008.28 ± 49.60 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d100000 | 61.24 ± 2.76 | 81.33 ± 3.86 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d150000 | 1898.18 ± 0.59 | | 80220.31 ± 24.93 | 80102.40 ± 24.93 | 80226.48 ± 24.91 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d150000 | 63.09 ± 4.07 | 80.67 ± 4.92 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d200000 | 1531.27 ± 1.25 | | 132066.32 ± 107.58 | 131948.41 ± 107.58 | 132076.34 ± 108.43 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d200000 | 58.89 ± 1.49 | 76.67 ± 3.77 | | | |GPT分析
指標 結論 pp2048/ prefill t/scu130-0.20全面較快短 context cu130-0.20優勢最大,純pp2048約快88%,d1000約快25%中長 context cu130-0.20仍較快,但差距逐步縮小d50000以上prefill 差距只剩約 1% - 2%ttfr/e2e_ttftcu130-0.20較低,代表首 token 等待時間較短tg480generation t/scu129-0.22平均略快,cu130-0.20約慢1.8% - 1.9%peak generation t/s cu129-0.22多數情況較高看起來cu130 nightly或者說整個cu130是有特別針對blackwell做優化, cu129估計是針對30跟40系優化
-
TLDR
先上個實體圖
Beelink Ser 8 8745HS 用Oculink連接 RTX Pro 4500
跑在Ubuntu 26.04, Kernel 7.0
因爲Oculink的關係, 不會考慮使用MoE
啓動咒語, 注意這個是我在vLLM cu130 nightly (0.20)設立的, cu129 0.22估計會有更多優化, 我會試試看其他版本
docker run -d \ --name vllm-Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP \ --restart unless-stopped \ --ipc host \ --gpus '"device=0"' \ -p 0.0.0.0:7380:8000 \ -v "~/vllm/models:/models:ro" \ -v "~/vllm/.cache/huggingface:/root/.cache/huggingface" \ -e GPU_MEMORY_UTILIZATION="0.95" \ -e HF_HUB_OFFLINE="1" \ -e KV_CACHE_DTYPE="fp8" \ -e MAX_MODEL_LEN="230400" \ -e MODEL_PATH="/models/sakamakismile/Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP" \ -e PYTORCH_CUDA_ALLOC_CONF="expandable_segments:True" \ -e SERVED_MODEL_NAME="Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP" \ -e VLLM_ATTENTION_BACKEND="FLASHINFER" \ -e VLLM_EXTRA_ARGS='--quantization modelopt --trust-remote-code --enable-chunked-prefill --reasoning-parser qwen3 --tool-call-parser qwen3_coder --enable-auto-tool-choice --max-num-seqs 1 --max-num-batched-tokens 4096 --speculative-config {"method":"qwen3_5_mtp","num_speculative_tokens":3} --language-model-only --performance-mode interactivity --attention-backend flashinfer --skip-mm-profiling --enable-prefix-caching --no-disable-hybrid-kv-cache-manager' \ -e VLLM_LOGGING_LEVEL="INFO" \ -e VLLM_NVFP4_GEMM_BACKEND="flashinfer-cutlass" \ -e VLLM_USE_FLASHINFER_MOE_FP4="0" \ -e VLLM_USE_FLASHINFER_SAMPLER="1" \ --health-cmd 'curl -fsS http://localhost:8000/v1/models || exit 1' \ --health-timeout 5s \ --health-interval 30s \ --health-retries 5 \ --health-start-period 5m \ --entrypoint /bin/bash \ vllm/vllm-openai:cu130-nightly \ -lc 'exec vllm serve "$MODEL_PATH" --served-model-name "$SERVED_MODEL_NAME" --host 0.0.0.0 --port 8000 --max-model-len "$MAX_MODEL_LEN" --gpu-memory-utilization "$GPU_MEMORY_UTILIZATION" --kv-cache-dtype "$KV_CACHE_DTYPE" $VLLM_EXTRA_ARGS'llama-benchy benchmark
llama-benchy \ --base-url "http://localhost:7380/v1" \ --model "Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP" \ --tokenizer "$HOME/vllm/models/sakamakismile/Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP" \ --pp 2048 \ --tg 480 \ --depth 0 1000 5000 10000 20000 50000 100000 150000 200000 \ #(不同上下文長度) --latency-mode generation \ --skip-coherence \ --concurrency 1 \效果
| model | test | t/s | peak t/s | ttfr (ms) | est_ppt (ms) | e2e_ttft (ms) | |:-----------------------------------------|-----------------:|------------------:|-------------:|------------------:|------------------:|------------------:| | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 | 7741.01 ± 1375.30 | | 373.94 ± 54.49 | 274.26 ± 54.49 | 373.94 ± 54.49 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 | 68.87 ± 6.65 | 81.33 ± 3.68 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d1000 | 8136.73 ± 32.84 | | 474.32 ± 1.44 | 374.64 ± 1.44 | 474.32 ± 1.44 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d1000 | 67.73 ± 5.06 | 88.00 ± 5.72 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d5000 | 6615.23 ± 22.79 | | 1165.21 ± 3.86 | 1065.53 ± 3.86 | 1165.21 ± 3.86 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d5000 | 72.92 ± 3.56 | 89.33 ± 3.77 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d10000 | 6008.73 ± 10.16 | | 2104.88 ± 3.47 | 2005.20 ± 3.47 | 2104.88 ± 3.47 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d10000 | 65.25 ± 2.21 | 82.00 ± 4.32 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d20000 | 5152.21 ± 0.52 | | 4379.13 ± 0.52 | 4279.45 ± 0.52 | 4380.19 ± 0.46 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d20000 | 70.45 ± 1.27 | 89.67 ± 0.47 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d50000 | 3690.36 ± 5.88 | | 14203.66 ± 22.59 | 14103.98 ± 22.59 | 14205.86 ± 22.80 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d50000 | 67.03 ± 1.67 | 84.67 ± 0.47 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d100000 | 2528.58 ± 0.55 | | 40457.51 ± 8.72 | 40357.83 ± 8.72 | 40461.50 ± 8.69 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d100000 | 60.96 ± 0.75 | 78.33 ± 3.68 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d150000 | 1922.36 ± 0.98 | | 79194.84 ± 39.68 | 79095.17 ± 39.68 | 79201.49 ± 39.50 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d150000 | 62.53 ± 3.29 | 76.33 ± 1.89 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d200000 | 1556.00 ± 0.99 | | 129951.65 ± 82.49 | 129851.97 ± 82.49 | 129959.72 ± 82.53 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d200000 | 59.58 ± 1.31 | 69.67 ± 1.70 | | | |
碎碎唸, 講一下參數選擇邏輯
GPU_MEMORY_UTILIZATION => 0.95, Headless伺服器, 顯示輸出由iGPU負責 KV_CACHE_DTYPE => FP8, Ada架構以後基本統一FP8 MAX_MODEL_LEN => 230K, 之前有嘗試試過極限拉到240K左右, 但是會在部分長上下文出現OOM, 穩定點用230K PYTORCH_CUDA_ALLOC_CONF => Pytorch實驗性參數, 透過呼叫CUDA内核API整理VRAM碎塊, 降低OOM機會 VLLM_ATTENTION_BACKEND => FLASHINFER, 很奇怪的是vLLM是推薦用這個而不是Flash Attention, 理論上在NVFP4在sm 12X (Desktop Blackwell)還沒完善下的情況用FA估計會比較好, 在sm 10X (Datacenter Blackwell)則FLASHINFER比較好 quantization => modelopt, vllm會跑去讀hf_quant_config.json裏的quant_algo, 這個模型是nvfp4 enable-chunked-prefill => 必開不解釋, 優化VRAM避免Spike導致OOM speculative-config => 2 或者 3 都可, 激進點就用了3 skip-mm-profiling => 因爲這個模型只支持Text, 所以不需要multi model設定,省點VRAM enable-prefix-caching => 降低TTRT no-disable-hybrid-kv-cache-manager => 避免因爲Qwen模型的混合Attention導致挂掉 VLLM_NVFP4_GEMM_BACKEND => 叫vLLM 使用 FlashInfer/Cutlass NVFP4 kernels進行矩陣計算, Blackwell特點 VLLM_USE_FLASHINFER_MOE_FP4 (0) + VLLM_USE_FLASHINFER_SAMPLER (1) => 優化CUDA内核@566656661 大神 看你用oclink 也有這個tks 我用底座 beelink pci 5.0 更加定了
就買4500 吧
 ️
️
數據實測結果十分好,都肯定兩張R9700也達不到身心錢包都要痛了

-
@566656661 我記得你好像有張 5090 ,PRO 4500 價位也差不多,你有比較過差異跟 CP 值嗎?
-
@566656661 大神 看你用oclink 也有這個tks 我用底座 beelink pci 5.0 更加定了
就買4500 吧️
數據實測結果十分好,都肯定兩張R9700也達不到身心錢包都要痛了
-
-
@566656661 5090D 能送去華強北魔改嗎?
-
基準測試
vLLM cu130 nightly (0.20) -> v0.22.1 cu129, 其餘包括benchmark不變
之後測試如果沒再提及Docker Image變化請默認為 v0.22.1-cu129-ubuntu2404
打了瞌睡, 發現原來參數沒刪乾淨, 只能帶著舊參數 + 新docker image 跑了測試如下
| model | test | t/s | peak t/s | ttfr (ms) | est_ppt (ms) | e2e_ttft (ms) | | :--------------------------------------- | ---------------: | ----------------: | -----------: | -----------------: | -----------------: | -----------------: | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 | 4112.24 ± 2335.79 | | 1000.79 ± 713.91 | 882.88 ± 713.91 | 1000.79 ± 713.91 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 | 70.62 ± 0.93 | 90.67 ± 1.25 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d1000 | 6522.05 ± 180.65 | | 585.81 ± 13.00 | 467.90 ± 13.00 | 585.81 ± 13.00 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d1000 | 72.00 ± 4.34 | 87.00 ± 0.82 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d5000 | 5716.09 ± 781.76 | | 1377.22 ± 190.64 | 1259.31 ± 190.64 | 1377.22 ± 190.64 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d5000 | 71.20 ± 1.68 | 90.33 ± 3.40 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d10000 | 5791.35 ± 64.74 | | 2198.74 ± 23.28 | 2080.84 ± 23.28 | 2198.74 ± 23.28 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d10000 | 70.74 ± 7.93 | 86.67 ± 4.19 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d20000 | 5015.72 ± 8.10 | | 4513.90 ± 7.10 | 4395.99 ± 7.10 | 4515.13 ± 6.99 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d20000 | 68.54 ± 4.81 | 86.67 ± 3.68 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d50000 | 3643.75 ± 3.58 | | 14402.48 ± 14.02 | 14284.58 ± 14.02 | 14404.87 ± 13.87 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d50000 | 71.21 ± 6.44 | 86.67 ± 1.25 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d100000 | 2495.95 ± 3.04 | | 41003.94 ± 49.73 | 40886.04 ± 49.73 | 41008.28 ± 49.60 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d100000 | 61.24 ± 2.76 | 81.33 ± 3.86 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d150000 | 1898.18 ± 0.59 | | 80220.31 ± 24.93 | 80102.40 ± 24.93 | 80226.48 ± 24.91 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d150000 | 63.09 ± 4.07 | 80.67 ± 4.92 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d200000 | 1531.27 ± 1.25 | | 132066.32 ± 107.58 | 131948.41 ± 107.58 | 132076.34 ± 108.43 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d200000 | 58.89 ± 1.49 | 76.67 ± 3.77 | | | |GPT分析
指標 結論 pp2048/ prefill t/scu130-0.20全面較快短 context cu130-0.20優勢最大,純pp2048約快88%,d1000約快25%中長 context cu130-0.20仍較快,但差距逐步縮小d50000以上prefill 差距只剩約 1% - 2%ttfr/e2e_ttftcu130-0.20較低,代表首 token 等待時間較短tg480generation t/scu129-0.22平均略快,cu130-0.20約慢1.8% - 1.9%peak generation t/s cu129-0.22多數情況較高看起來cu130 nightly或者說整個cu130是有特別針對blackwell做優化, cu129估計是針對30跟40系優化
v0.22.1-cu129-ubuntu2404
VLLM_NVFP4_GEMM_BACKEND 因爲deprecated, 將由linear-backend自動選擇
VLLM_USE_FLASHINFER_MOE_FP4 因爲deprecated, 將由moe-backend自動選擇
測試結果
| model | test | t/s | peak t/s | ttfr (ms) | est_ppt (ms) | e2e_ttft (ms) | | :--------------------------------------- | ---------------: | ----------------: | -----------: | -----------------: | -----------------: | -----------------: | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 | 3815.72 ± 2638.08 | | 1066.49 ± 675.13 | 946.43 ± 675.13 | 1066.49 ± 675.13 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 | 71.54 ± 3.67 | 89.33 ± 1.70 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d1000 | 7097.86 ± 469.13 | | 551.38 ± 27.36 | 431.33 ± 27.36 | 551.38 ± 27.36 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d1000 | 72.91 ± 1.96 | 86.67 ± 2.05 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d5000 | 6293.28 ± 200.29 | | 1241.33 ± 35.85 | 1121.28 ± 35.85 | 1241.33 ± 35.85 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d5000 | 71.79 ± 1.34 | 90.00 ± 0.82 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d10000 | 5764.98 ± 66.54 | | 2210.31 ± 24.36 | 2090.26 ± 24.36 | 2210.31 ± 24.36 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d10000 | 71.77 ± 5.24 | 86.00 ± 5.35 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d20000 | 5020.15 ± 9.69 | | 4512.04 ± 8.31 | 4391.99 ± 8.31 | 4513.21 ± 8.16 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d20000 | 74.68 ± 1.77 | 94.00 ± 2.16 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d50000 | 3634.37 ± 3.95 | | 14441.41 ± 15.57 | 14321.36 ± 15.57 | 14444.10 ± 15.13 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d50000 | 65.42 ± 5.26 | 83.33 ± 7.41 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d100000 | 2500.68 ± 0.47 | | 40928.48 ± 7.63 | 40808.42 ± 7.63 | 40933.15 ± 7.29 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d100000 | 73.40 ± 4.21 | 85.00 ± 2.45 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d150000 | 1900.32 ± 1.39 | | 80132.00 ± 58.27 | 80011.94 ± 58.27 | 80138.64 ± 57.60 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d150000 | 67.87 ± 1.65 | 79.67 ± 3.30 | | | | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | pp2048 @ d200000 | 1535.79 ± 1.74 | | 131680.08 ± 149.90 | 131560.02 ± 149.90 | 131688.59 ± 149.41 | | Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP | tg480 @ d200000 | 56.88 ± 2.29 | 73.33 ± 2.05 | | | |GPT結論
結論
cu130-0.20的主要優勢在 prefill throughput 和 TTFT,特別是短到中等 context 的 prompt processing。更新後的
cu129-0.22在 token generation / decode throughput 上比之前更強,平均tg480generation t/s 約比cu130-0.20高4.6%。整體而言,若 workload 偏 prompt-heavy、RAG、長 prompt prefill,
cu130-0.20較合適;若 workload 偏長時間生成 token,cu129-0.22較合適。 -
@566656661 可以許願 https://microsoft.github.io/TRELLIS.2/ 測試嗎?
剛剛跑 ROCm版堪用,但踩雷不少,等下也丟上來
https://lcz.me/post/5275 -
 T terry 于 将此主题固定
T terry 于 将此主题固定
-
以下是研究途中的碎碎唸, 不感興趣的可以不看
碎碎唸1
看了蠻多文件跟大神文章, 有幾個值得留意的地方
Blackwell架構分成了Consumer Blackwell (sm 12x) 跟 Data Center Blackwell (sm 10x) 所有Geforce, RTX Pro, DGX Spark, RTX Spark都歸屬在Consumer Blackwell 其中最大的分別就是在於sm 12x缺少了tcgen05, 這也是Flash Attention 4裏面的核心技術 底層MMA邏輯裏用的還是SM8X, 也就是目前的Flash Attention 2 好家夥, 老黃這算不算是在欺詐啊...https://docs.vllm.ai/en/stable/configuration/env_vars/ v0.22 cu129可以在--linear-backend (前身VLLM_NVFP4_GEMM_BACKEND)使用flashinfer-b12x而不是flashinfer-cutlass MoE模型 (Qwen 3.6 35BA3B 跟 Gemma 4 26BA4B) 可以通過在--moe-backend 設置flashinfer_b12x 這個是特意為sm 12x架構優化的GEMM内核 約有30%throughput增長, https://github.com/vllm-project/vllm/pull/39634 這個我有點興趣先再試試看
碎碎唸2 (
吐槽)在一邊看vLLM文件一邊跑去問了Gemini, 講明了是Blackwell架構,居然還給了個
VLLM_MXFP4_BACKEND=marlin, 先不説直接無視掉NVFP4, marlin是給沒有FP4硬件加速的啊... (NVFP4或者MXFP4都可用)VLLM_FLASHINFER_MOE_BACKEND還給了throughput這個預設參數, 也沒改成--moe-backend flashinfer_cutlass(雖然這個在27b 模型沒用到)錯誤示範, 不要學
docker run -d \ --name vllm-Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP \ (中間省略) -e SERVED_MODEL_NAME="Huihui-Qwen3.6-27B-abliterated-NVFP4-MTP" \ -e VLLM_ATTENTION_BACKEND="FLASHINFER" \ -e VLLM_MXFP4_BACKEND="marlin" \ -e VLLM_FLASHINFER_MOE_BACKEND="throughput" \ -e VLLM_USE_FLASHINFER_SAMPLER="1" \ -e VLLM_EXTRA_ARGS= (以下省略)
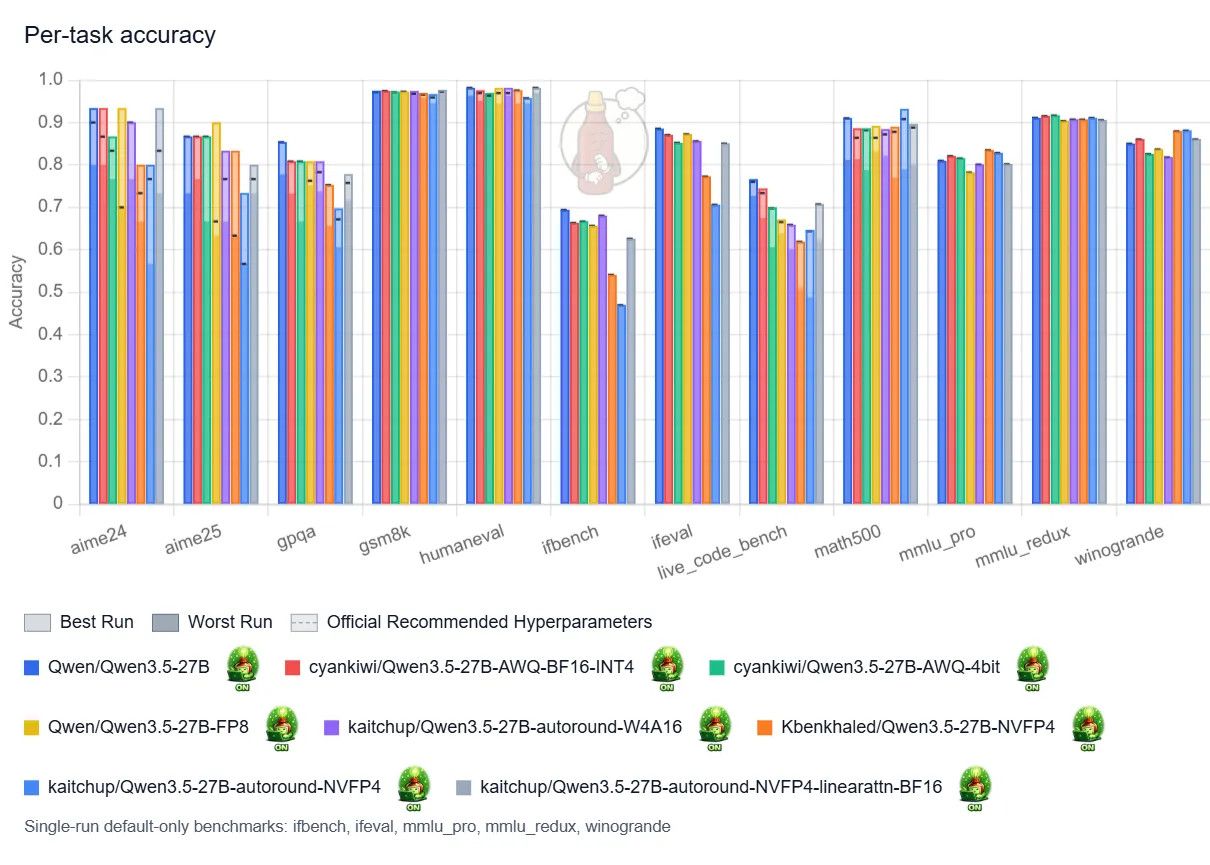
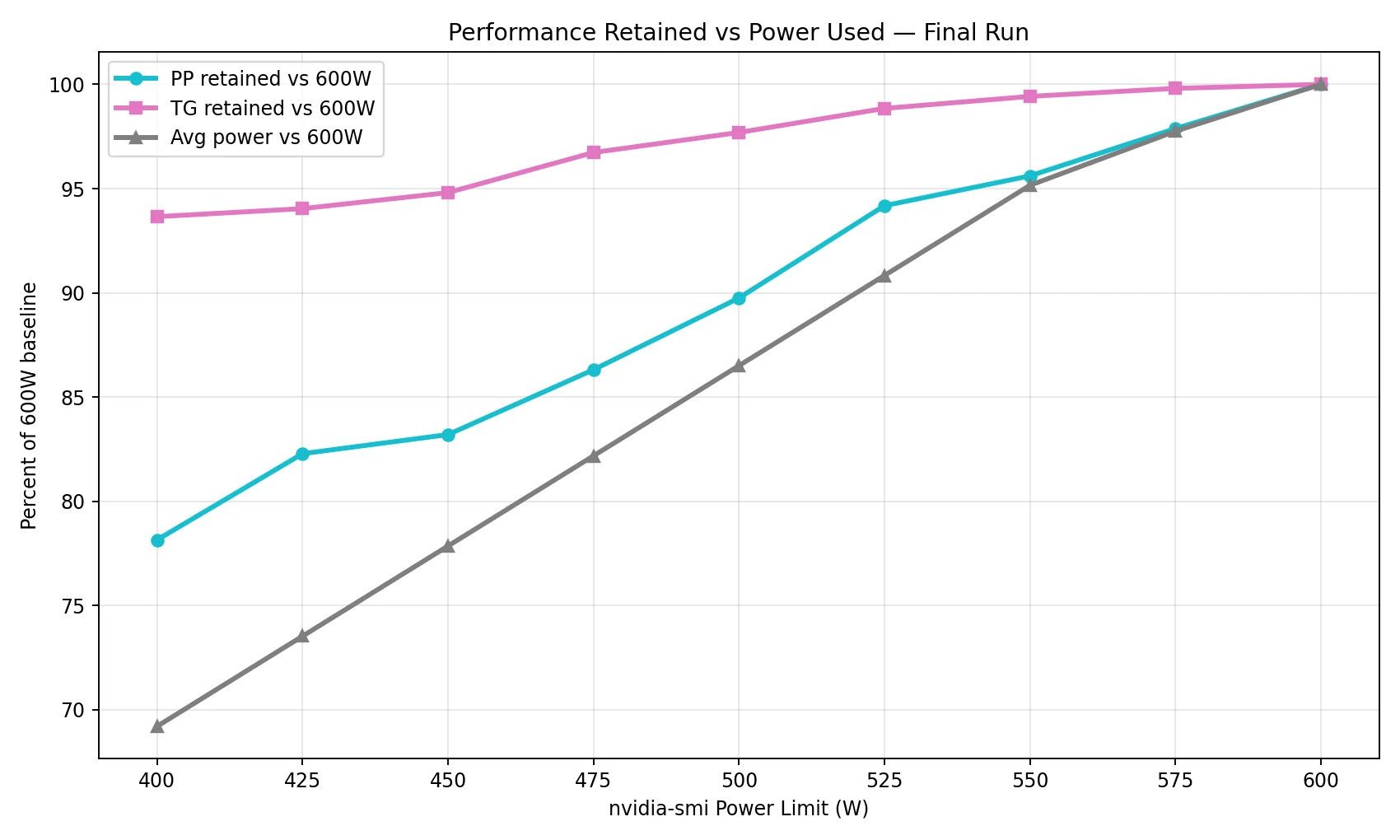
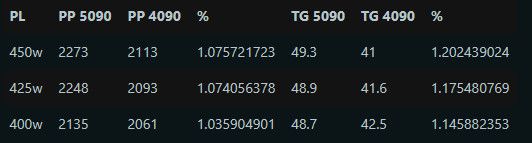
 兩張R9700 都不如一張4500 效能
兩張R9700 都不如一張4500 效能