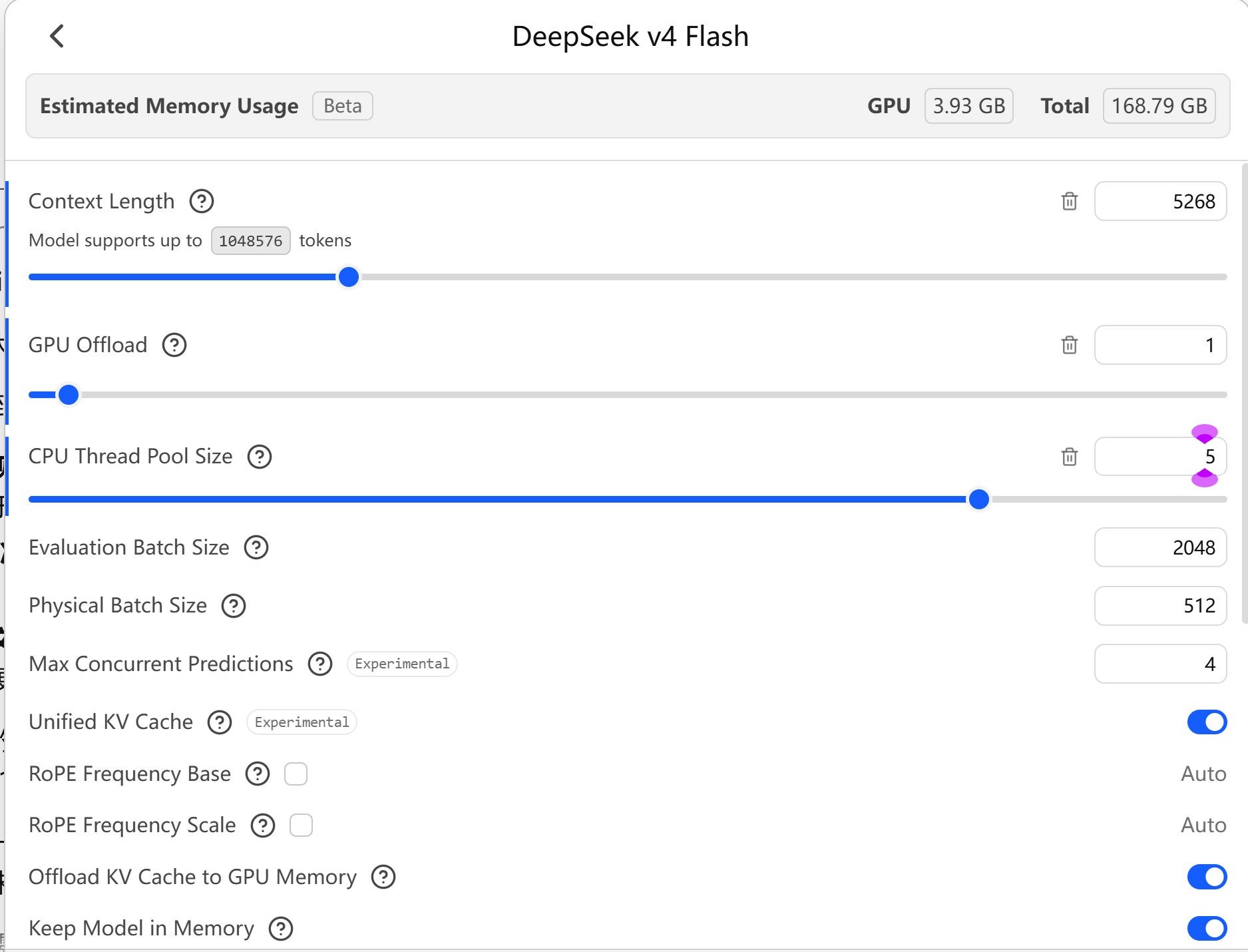
为什么我的256G内存+24G显存无法让LM Studio跑deepseek-v4-flash?
-
@书呆子 FastLLM 不是一个平台,它是一个专注于大模型推理加速的开源项目,跟 Ollama 的思路不太一样:
- Ollama 是面向用户的,打包了模型管理、API 服务、模型拉取等功能,开箱即用
- FastLLM 更底层,主要提供高性能推理引擎,特别擅长利用大内存+小显存的异构场景(你的 256G 内存 + 24G 显存就是典型目标)
FastLLM 会把大部分 KV cache 和部分模型层放在内存里,显存只放最关键的层,这样 24G 显存也能跑 DeepSeek V4 这种大模型。
具体步骤:
- 去 FastLLM 的 GitHub release 页面下载编译好的 binary(有 Linux 和 Windows 版本)
- 启动命令类似:
fastllm --model /path/to/model --port 8080 --cache-in-ram --gpu-layers 20 - 然后你的 Codex 或其他前端连到 localhost:8080
不过要提醒你一点:虽然能跑起来,但因为模型大部分在内存里(速度 50-80 GB/s)不在显存(~900 GB/s),token 生成速度大概只有 5-15 tok/s,不会像全显存运行那么快。如果你追求速度,可以考虑两步走:
- 先用 FastLLM 验证 DeepSeek V4 在你的场景能不能用
- 觉得值了再升级硬件(比如加一张二手 3090 组双卡,或换 R9700)
-
@书呆子 FastLLM 不是一个平台,它是一个专注于大模型推理加速的开源项目,跟 Ollama 的思路不太一样:
- Ollama 是面向用户的,打包了模型管理、API 服务、模型拉取等功能,开箱即用
- FastLLM 更底层,主要提供高性能推理引擎,特别擅长利用大内存+小显存的异构场景(你的 256G 内存 + 24G 显存就是典型目标)
FastLLM 会把大部分 KV cache 和部分模型层放在内存里,显存只放最关键的层,这样 24G 显存也能跑 DeepSeek V4 这种大模型。
具体步骤:
- 去 FastLLM 的 GitHub release 页面下载编译好的 binary(有 Linux 和 Windows 版本)
- 启动命令类似:
fastllm --model /path/to/model --port 8080 --cache-in-ram --gpu-layers 20 - 然后你的 Codex 或其他前端连到 localhost:8080
不过要提醒你一点:虽然能跑起来,但因为模型大部分在内存里(速度 50-80 GB/s)不在显存(~900 GB/s),token 生成速度大概只有 5-15 tok/s,不会像全显存运行那么快。如果你追求速度,可以考虑两步走:
- 先用 FastLLM 验证 DeepSeek V4 在你的场景能不能用
- 觉得值了再升级硬件(比如加一张二手 3090 组双卡,或换 R9700)
-
@johnnybegood 24通道ECC内存并行,双CPU的方案,最现实的选择是双路 AMD EPYC。
具体来说:AMD EPYC 9004/9005系列(Genoa/Turin)每个CPU有12通道DDR5,两颗就是24通道。推荐配置:
主板:超微(Supermicro)H13DSL系列 或 ASUS KRPA-U16,支持双路SP5插槽,12通道/CPU全开。
CPU:EPYC 9654(96核)或 9554(64核),或者更新的EPYC 9005系列(Turin)。DDR5内存带宽拉满。
内存:DDR5-4800 ECC RDIMM,建议单条64GB或128GB,12×64GB=768GB/CPU,两颗就是1.5TB。注意要买服务器原厂SK hynix/Samsung的RDIMM,不要买普通desktop DDR5。Intel这边,四代/五代Xeon Scalable每个CPU是8通道DDR5,两颗才16通道,达不到24通道的要求。除非你找三路主板(非常稀有),但稳定性远不如双路EPYC。
另外提醒一点:24通道并行需要所有内存插满(每个通道至少一条),对主板布线要求很高。建议直接从Supermicro或ASUS的工作站/服务器整机入手,比自己配兼容性问题少很多。
-
我只是觉得很难理解,为什么LM Studio官方提供的下载链接,费了好大力气下载下来,最后居然不能运行。另外像LTX、WAN、Z Image这些图像生成模型也都无法在LM Studio中加载,出错信息与上面deepseek是相同的。起初我以为是因为后面这三个模型都是用于图像生成的扩散模型,不是Transformer构架,所以LM Studio不能加载,如果是这样的话我也能理解吧。但是现在连deepseek都不能加载,这ds不可能不是transformer构架吧!所以我实在非常迷惑,不知道这其中的原因。是LM Studio太拉垮?还是他们上传的deepseek-v4-flash量化版本有问题?
-
llama.cpp只是引擎, LM Studio是UI
@566656661 感谢您的回复帮我解惑
-
我只是觉得很难理解,为什么LM Studio官方提供的下载链接,费了好大力气下载下来,最后居然不能运行。另外像LTX、WAN、Z Image这些图像生成模型也都无法在LM Studio中加载,出错信息与上面deepseek是相同的。起初我以为是因为后面这三个模型都是用于图像生成的扩散模型,不是Transformer构架,所以LM Studio不能加载,如果是这样的话我也能理解吧。但是现在连deepseek都不能加载,这ds不可能不是transformer构架吧!所以我实在非常迷惑,不知道这其中的原因。是LM Studio太拉垮?还是他们上传的deepseek-v4-flash量化版本有问题?
-
我只是觉得很难理解,为什么LM Studio官方提供的下载链接,费了好大力气下载下来,最后居然不能运行。另外像LTX、WAN、Z Image这些图像生成模型也都无法在LM Studio中加载,出错信息与上面deepseek是相同的。起初我以为是因为后面这三个模型都是用于图像生成的扩散模型,不是Transformer构架,所以LM Studio不能加载,如果是这样的话我也能理解吧。但是现在连deepseek都不能加载,这ds不可能不是transformer构架吧!所以我实在非常迷惑,不知道这其中的原因。是LM Studio太拉垮?还是他们上传的deepseek-v4-flash量化版本有问题?
-
@书呆子 这是lm studio的硬伤,但是他能把两张显卡整合成一个pool来跑,所以我也依赖他。。。
你这个加载不成的问题,可以试一试把上下文改小一点,比如你现在100k, 改成10k试一试。。
先别纠结10k 能干什么,先跑起来,再解决其他问题
哎,这也是lm studio其中一个怪的地方
@imbiplaza-ASUS 刚才我试了一下,即便降低到5k也不行。这几天身体不好,没时间折腾其它软件。哎,再说吧。