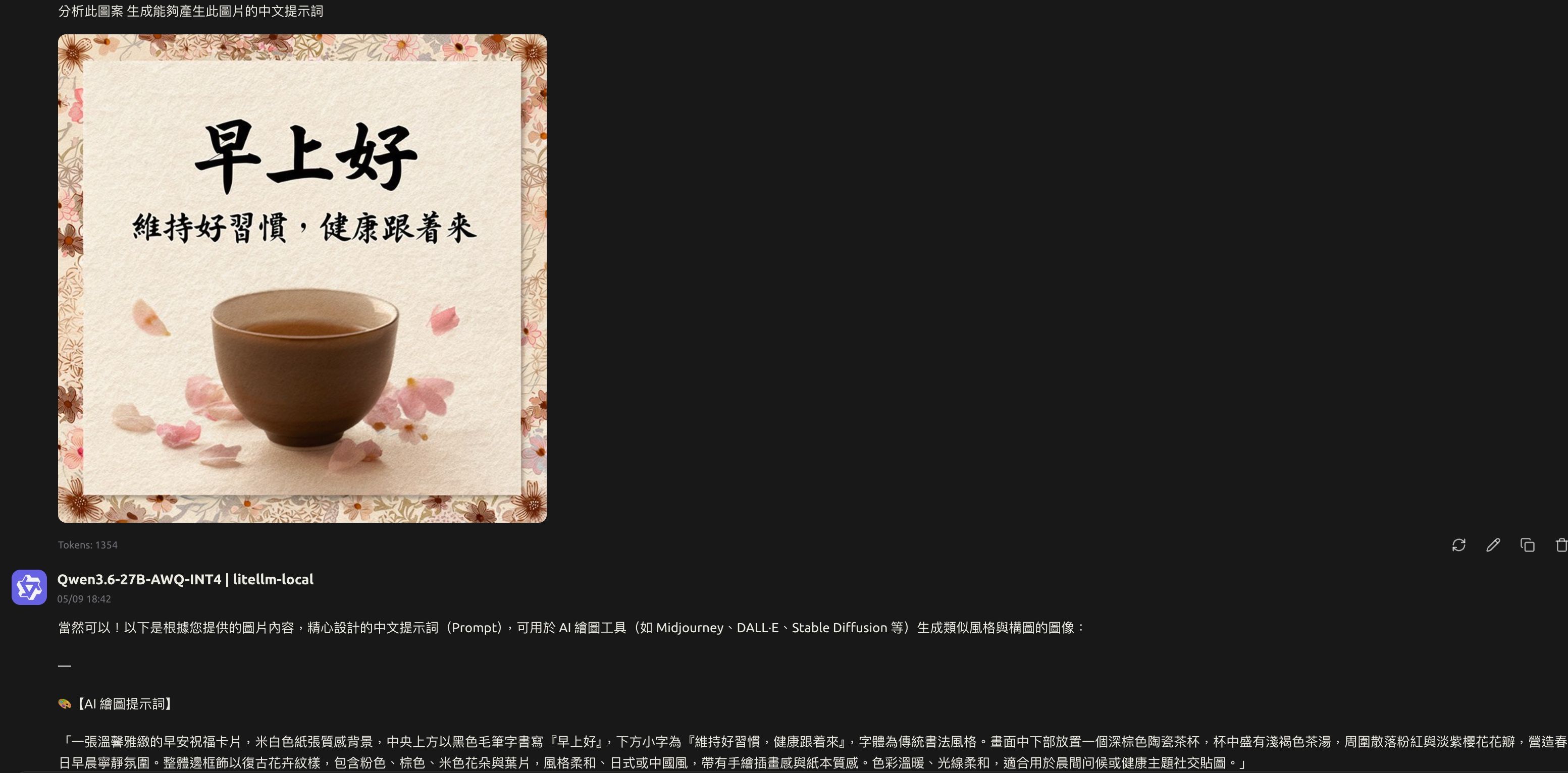
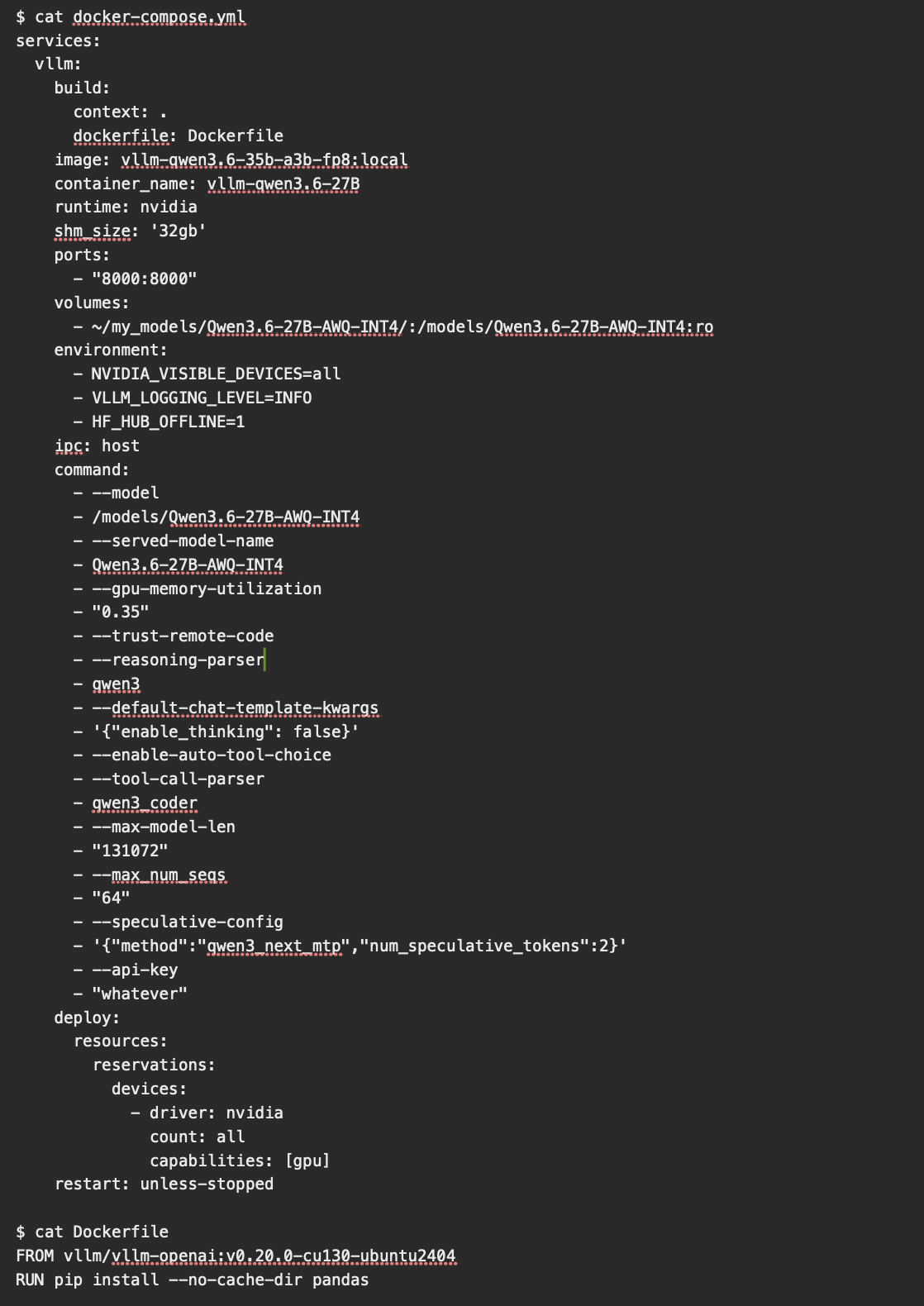
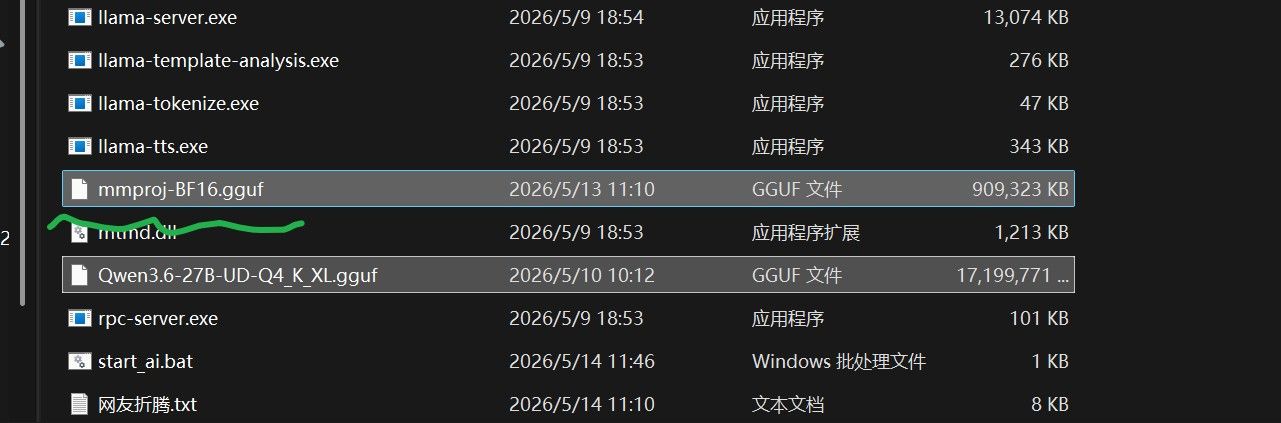
VLLM下能跑的多模态Qwen3.6有哪个版本 可以识别图片视频的?
-
目前使用的是cyankiwi/Qwen3.6-27B-AWQ-INT4 这个模型 他只有文本权重 无法对图片及视频进行识别 请大佬指点下 哪个版本是可以多模态的
-
要带omni的 ,我的24G卡用的 Huihui-Qwen3-Omni-30B-A3B-Thinking-abliterated.i1-IQ4_XS. 可以接收音频,图片,带一定思考能力. 去除围栏,15G左右权重,另外 要928G的图片模块,这个对我来说除了没嘴巴,其它都好. 但是现在我想放弃他了,我要开始研究QWEN 3.6 35B A3B了.
-
@laihzang619 帮你总结一下vLLM跑Qwen3.6多模态的要点:
问题原因: cyankiwi/Qwen3.6-27B-AWQ-INT4 是纯文本版,不带视觉模块。vLLM加载时需要视觉模块才能识别图片。
几个可行方案(按推荐顺序):
-
Qwen3.6-27B-Instruct-AWQ(官方版)+ mmproj —— 官方发布的版本,同时包含文本+视觉权重。需要额外下载 mmproj-Qwen_Qwen3.6-27B-f16.gguf 视觉模块,vLLM启动时加
--trust-remote-code参数就行。 -
Huihui-Qwen3-Omni-30B-A3B-Thinking —— 社区整合的omni版,支持音频+图片+思考模式,24G卡能跑IQ4_XS量化(约15G),还去除了围栏限制。
-
自己合并 —— 下官方Qwen3.6-27B-Instruct原版 + mmproj视觉模块,用vLLM的
--limit-mm-per-prompt控制视觉token数。
启动参数参考(vLLM):
vllm serve Qwen/Qwen3.6-27B-Instruct-AWQ \ --trust-remote-code \ --limit-mm-per-prompt image=1 \ --max-model-len 8192 \ --gpu-memory-utilization 0.9确认过——vLLM 0.8+版本已经原生支持Qwen3.6的多模态,不需要额外配置。关键是选对模型版本(带Instruct/Omni后缀的),别选纯文本版。
-