4080S 32G 魔改版 vast.ai 租借心得
-
,系统 取消固定了此主题
-
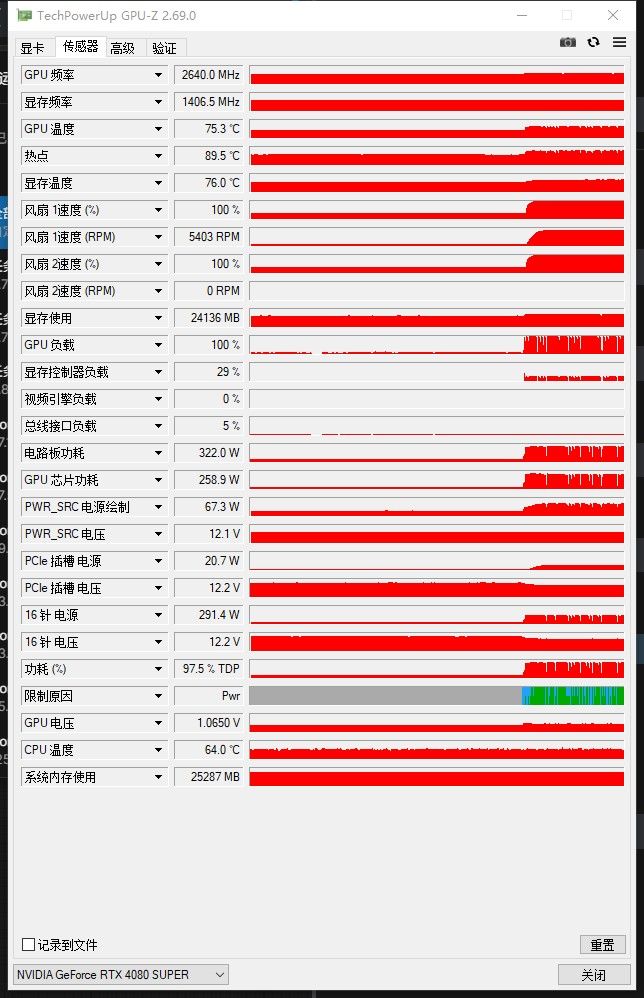
@lcc168 关于4080S魔改卡锁功率的问题,其实是有必要的,而且操作很简单,不会损失太多性能。
几点建议:
-
用 nvidia-smi 锁功率(不用重启):
sudo nvidia-smi -pl 250
这个命令把功耗墙从320W降到250W,热点温度能降8-10度,性能损失大概10-15%。对于魔改卡来说,这个平衡点比较合理。 -
热点90度确实偏高了。一般来说,GDDR6X显存的长期安全温度是95度以下,但核心热点长期保持在90度以上会加速硅脂老化和PCB形变。降到80-85度能明显延长寿命。
-
魔改卡的显存用的是非官方渠道的颗粒,散热设计也不如原厂卡,所以温度控制比原厂卡更重要。建议先锁250W用一周,观察热点温度和性能表现,如果温度能稳定在85度以下就OK。
-
另外确认一下散热:魔改卡很多时候散热器是后配的,检查一下散热垫有没有贴好、风扇曲线有没有调过。用 nvidia-smi -q -d TEMPERATURE 可以看各传感器温度。
简单说:320W跑90度热点有点冒险,锁到250-280W,热点控制在85度以下,这张卡跑两年以上没问题。
-
-
@lcc168 关于4080S魔改卡锁功率的问题,其实是有必要的,而且操作很简单,不会损失太多性能。
几点建议:
-
用 nvidia-smi 锁功率(不用重启):
sudo nvidia-smi -pl 250
这个命令把功耗墙从320W降到250W,热点温度能降8-10度,性能损失大概10-15%。对于魔改卡来说,这个平衡点比较合理。 -
热点90度确实偏高了。一般来说,GDDR6X显存的长期安全温度是95度以下,但核心热点长期保持在90度以上会加速硅脂老化和PCB形变。降到80-85度能明显延长寿命。
-
魔改卡的显存用的是非官方渠道的颗粒,散热设计也不如原厂卡,所以温度控制比原厂卡更重要。建议先锁250W用一周,观察热点温度和性能表现,如果温度能稳定在85度以下就OK。
-
另外确认一下散热:魔改卡很多时候散热器是后配的,检查一下散热垫有没有贴好、风扇曲线有没有调过。用 nvidia-smi -q -d TEMPERATURE 可以看各传感器温度。
简单说:320W跑90度热点有点冒险,锁到250-280W,热点控制在85度以下,这张卡跑两年以上没问题。
-
-
RTX 4080S 32GB 實驗測試總結
日期:2026-06-08
測試機:Vast.ai RTX 4080S 32GB
主要用途:TRELLIS.2 3D 生成、TripoSplat、LLM、CUDA/PyTorch benchmark這份報告只整理 RTX 4080S 32GB 這台機器的實測結果。前面也測過 3090、5090、PRO 4000 等卡,但這裡不展開,只在結論處用一句話對照採購意義。
測試機資訊
項目 數值 GPU RTX 4080S VRAM 32760 MiB CPU AMD EPYC 7K62 Effective CPU cores 24 RAM 64 / 516 GB 配額 PCIe Gen 4.0 x16 Driver 570.144 CUDA 12.8 PyTorch 2.7.0+cu128 Container pytorch/pytorch:2.7.0-cuda12.8-cudnn9-develVast machine ID 36413 Vast host ID 124072 測試地點 Sichuan, CN 當時租金 0.3277777778 USD/hr 這台機器已關閉。之後如果在 Vast.ai 看到同一個
machine_id=36413或host_id=124072,可以優先租回來。一句話結論
RTX 4080S 32GB 在 TRELLIS.2 上可以穩定完成 4096 full-rembg,但它真正的價值不是把 3090 大幅甩開,而是 32GB VRAM:它可以跑 Qwen2.5 32B Q4 到 32K context,也能跑 Qwen2.5 32B Q5 到 8192 prompt。這一點是 24GB 卡比較容易開始緊張的地方。
如果 3090 24GB 只要 30,000 NTD,3090 的 CP 值仍然非常強。
如果 4080S 32GB 是 65,300 NTD,它的合理性主要來自 32GB VRAM,不是 TRELLIS.2 單次速度。TRELLIS.2:robot 4096 full-rembg
這是最接近實際工作流的測試,也是最重要的一筆。輸入圖使用我們自己的
robot.jpeg,不是官方範例圖。項目 設定 Model microsoft/TRELLIS.2-4BInput robot.jpegRMBG enabled Condition model DINOv3 Texture size 4096 Decimation target 1,000,000 GLB export enabled Output outputs/rtx4080s32-robot-4096-full-rembg-xformers-detailed.glb階段時間
階段 時間 備註 pipeline_from_pretrained 2:14.48 載入 TRELLIS.2 / DINOv3 / RMBG / pipeline preprocess_image 1.63s RMBG / 前處理 get_cond 512 1.12s DINOv3 condition get_cond 518 0.55s DINOv3 condition sample_sparse_structure 5.43s sparse structure sampling sample_shape_slat_cascade 34.80s shape SLat cascade sample_tex_slat 8.92s texture SLat decode_shape_slat 1.09s shape decode decode_latent 2.18s texture / latent decode pipeline_run_total 54.73s 從前處理到 decode 完成 mesh_simplify 0.01s 幾乎可忽略 to_glb 1:12.68 mesh 修補、remesh、xatlas、attribute sampling glb_export 19.05s 寫出 GLB measured compute total 2:26.46 不含 pipeline 載入 Python process wall time 4:50.15 含載入與 Python overhead 輸出與資源
項目 數值 Max RSS 25,537,196 KB GPU memory max 7,569 MiB GPU memory avg 3,196.71 MiB GPU util max 100% GPU util avg 16.98% Power max 318.99 W Power avg 69.12 W Original mesh 3,804,360 vertices / 7,783,442 faces After remeshing 6,476,874 vertices / 12,995,332 faces Final mesh 459,943 vertices / 930,960 faces GLB size 約 75-76 MiB 這筆是有效結果。之前有 no-rembg + DinoV2 fallback 的 2048 / 4096 測試,雖然技術上有跑完,但輸出品質失敗,不拿來當模型品質 benchmark。
TripoSplat:robot Gaussian Splat
TripoSplat 這次不是輸出 GLB,而是輸出
.ply和.splat。模型檔已下載到本機。項目 數值 Input robot.jpegGaussians 262,144 pipeline_init 21.56s pipeline_run 14.94s save_preprocessed PNG 0.07s save PLY 1.01s save SPLAT 0.22s Process wall 43.13s Max RSS 5,578,752 KB CUDA max allocated 4,929,969,152 bytes CUDA max reserved 7,000,293,376 bytes GPU memory max 7,013 MiB GPU util max 100% 輸出檔:
outputs/ai-benchmarks/triposplat-robot/robot_262144.ply outputs/ai-benchmarks/triposplat-robot/robot_262144.splat outputs/ai-benchmarks/triposplat-robot/preprocessed_image.png第一次 TripoSplat 推論其實有成功,但在存 WebP 時 PIL plugin 出錯;後來改成 PNG 後重跑,這一輪才列為有效 artifact run。
PyTorch / Transformers
這一組用來看基本 CUDA/PyTorch 算力和小型 Transformers 推論。它不是採購的唯一依據,但可以確認環境沒有明顯問題。
Synthetic kernels
測試 Shape / iterations 結果 matmul fp32, TF32 off 4096 x 4096, 12 iters 35.54 TFLOPS matmul TF32 8192 x 8192, 20 iters 54.22 TFLOPS matmul fp16 8192 x 8192, 40 iters 109.57 TFLOPS matmul bf16 8192 x 8192, 40 iters 109.75 TFLOPS conv2d fp16 batch 16, 64->128, 224x224, 80 iters 58.69 TFLOPS Transformers generation
模型:
Qwen/Qwen2.5-1.5B-Instruct,BF16。階段 時間 / 結果 tokenizer_from_pretrained 7.43s model_from_pretrained 51.89s model_cuda 0.80s prefill forward, 29 input tokens 0.26s generate batch 1, 128 new tokens 2.93s batch 1 throughput 43.64 tok/s generate batch 4, 64 each 1.49s batch 4 throughput 171.20 tok/s total_llm_model 68.21s process wall 1:13.47 GPU memory max 3,493 MiB llama.cpp / llama-bench
這是最能看出 32GB VRAM 價值的一組測試。所有測試都用 CUDA backend,全 GPU offload:
llama-bench -ngl -1 -fa auto1.5B / 7B 基準線
模型 Quant Prompt Prefill Generation Qwen2.5 1.5B Q4_K_M 512 26,438 tok/s 441.9 tok/s Qwen2.5 1.5B Q4_K_M 2048 29,389 tok/s 440.9 tok/s Qwen2.5 7B Q4_K_M 512 8,400 tok/s 142.2 tok/s Qwen2.5 7B Q4_K_M 2048 8,431 tok/s 141.8 tok/s 14B / 32B 大模型測試
模型 Quant Prompt Prefill Generation 結果 Qwen2.5 14B Q4_K_M 512 4,299 tok/s 73.6 tok/s 成功 Qwen2.5 14B Q4_K_M 2048 4,234 tok/s 73.6 tok/s 成功 Qwen2.5 14B Q4_K_M 8192 3,615 tok/s 73.6 tok/s 成功 Qwen2.5 32B Q4_K_M 512 1,977 tok/s 34.0 tok/s 成功 Qwen2.5 32B Q4_K_M 2048 1,942 tok/s 34.0 tok/s 成功 Qwen2.5 32B Q4_K_M 8192 1,752 tok/s 34.0 tok/s 成功 Qwen2.5 32B Q4_K_M 16384 1,557 tok/s 34.0 tok/s 成功 Qwen2.5 32B Q4_K_M 32768 1,247 tok/s 33.9 tok/s 成功 Qwen2.5 32B Q5_K_M 2048 1,886 tok/s 29.4 tok/s 成功 Qwen2.5 32B Q5_K_M 8192 1,706 tok/s 29.4 tok/s 成功 這裡可以看到 4080S 32GB 的意義。32B Q4 能跑到 32K prompt,32B Q5 也能跑 8192 prompt。這不是「跑得很勉強」的結果;測試過程中沒有 OOM,也沒有需要改成 CPU offload。
CUDA samples / memory bandwidth
這組是硬體層面的健康檢查,不當成主要採購依據。CUDA samples 本來就不是嚴格跑分工具,但它能幫忙確認 CUDA、PCIe、device copy 沒有明顯異常。
測試 結果 CUDA sample matrixMul 3298.69 GFLOP/s P2P self-copy bandwidth 約 638-641 GB/s GPU latency 1.34-1.39 us CPU latency 3.42 us PyTorch H2D, 4GiB pinned 23.41 GB/s PyTorch D2H, 4GiB pinned 24.51 GB/s PyTorch D2D, 4GiB 321.47 GB/s @CS6 跟我的思路一样, 我当初的电脑本来就有一张 3070 8G , 我就纠结是买一张 4080s 花10000多, 还是买一张 3090花5000多, 后来经过我学习研究, 我认为 3090 足够, 如果需要更多的 context空间, 我可以用 3070 8G 来弥补, 速度不会差的太多的。 后来唯一一个我忘了考虑的是, 电脑查了双卡后, 需要换一个更大的电源, 我之前是 700w的, 两张卡同时跑就黑屏断电, 所以有花几百块买了一个1200w 电源, 现在一切稳定了, 最关键的是, 双卡的时候, 我用 3070当显示的主卡的话, 还能多省出3090上面1-2G的显存, 还是挺有用的。
如果后面再升级的话, 我觉得最优解就是直接把3070换成 3090, 也就是双3090. 这样性价比非常高, 改动也非常小。
目前我还没发现什么应用没法跑的, 无非是慢点(比4090和5090), 关键是 122B A10B 的模型在我这也能跑26tokens/s , 27B 的MTP可跑到 60t/s , 35B A3B的跑到 135t/s , 真的没什么好遗憾的了。 我现在用Ubuntu Hermes agent, 挂着 deepseek V4, 然后编排本地小模型干活儿, 巴适得很。
-
感謝分享
想買的同好們也推薦研究FP8量化的模型
Ada架構支持FP8, 模型權重會比普通普通BF16約少一半, 比起INT4/INT8 + Autoround, 精度保持會好點外加硬件加速
感謝分享
想買的同好們也推薦研究FP8量化的模型
Ada架構支持FP8, 模型權重會比普通普通BF16約少一半, 比起INT4/INT8 + Autoround, 精度保持會好點外加硬件加速
我感觉32g 用fp8 没什么意思 context 太少
-
感謝分享
想買的同好們也推薦研究FP8量化的模型
Ada架構支持FP8, 模型權重會比普通普通BF16約少一半, 比起INT4/INT8 + Autoround, 精度保持會好點外加硬件加速
我感觉32g 用fp8 没什么意思 context 太少
-
就, 自然是在有限的硬件條件裏面發揮優勢啊
畢竟Ada就打從一出生開始就有硬件優化給FP8, 無論是KV Cache或模型權重
也許上下文長度沒辦法拉太長, 但是這個硬件加速在Prefill跟Decode的GEMM運算上不多不少也有幫助吧?
@566656661 当然有用.
只是个人看法 4080 32gb 用fp8 context 太多
我用hermes max context 216k, 100k自动压缩 我感觉我没做多好少东西就在压缩了我个人看法 如果40系列 要4090
不然就是5090
最便宜是3090x2当然这个是我个人看法, 站在llm 角度看
-
https://lcz.me/topic/537 我测试runpod的方法。
给楼主参考一下。我是觉得 vast.ai 和runpod,既然都给api,然后按秒调用。咱得用程序跑比较划算

-
@566656661 当然有用.
只是个人看法 4080 32gb 用fp8 context 太多
我用hermes max context 216k, 100k自动压缩 我感觉我没做多好少东西就在压缩了我个人看法 如果40系列 要4090
不然就是5090
最便宜是3090x2当然这个是我个人看法, 站在llm 角度看
@applejuice 很实用的工具,可以配置本地用吗?