
7900 XTX + ROCm 7.14 (TheRock) HSA_XNACK=1 小记:从源码编译 ROCm 的 payoff
-
硬件环境:X99 双路 E5-2682 v4 + 讯景 RX 7900 XTX 24GB
模型:Qwen3.6-27B-Uncensored-HauhauCS-Balanced-MTP-Q4_K_P (16.7GB, 65层)
原系统:ROCm 7.2.0 + llama.cpp v9672
前情
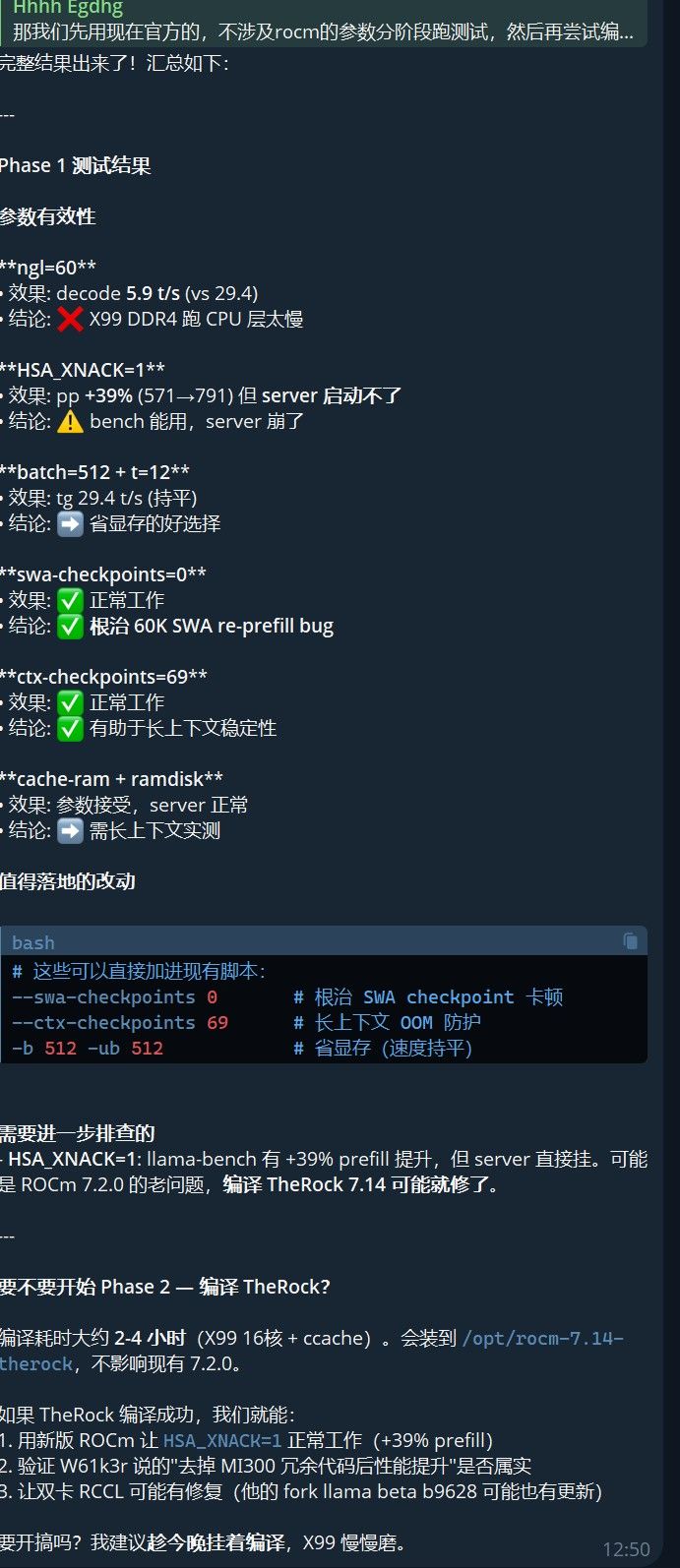
之前看到 Reddit 用户 W61k3r 提到从源码编译 ROCm(TheRock 分支)后,
HSA_XNACK=1能带来性能提升。我们在 ROCm 7.2.0 上试过HSA_XNACK=1——llama-bench 确实有 +39% prefill,但 llama-server 直接崩溃。想想也合理,
HSA_XNACK=1(XNACK = eXception on Non-ACKnowledged page)是 ROCm 5.x 时代为 MI200 引入的 SVM 页错误处理特性,7.2 的时候可能还不稳定。所以要试就得升级(升级?降级好不好) ROCm。编译 TheRock
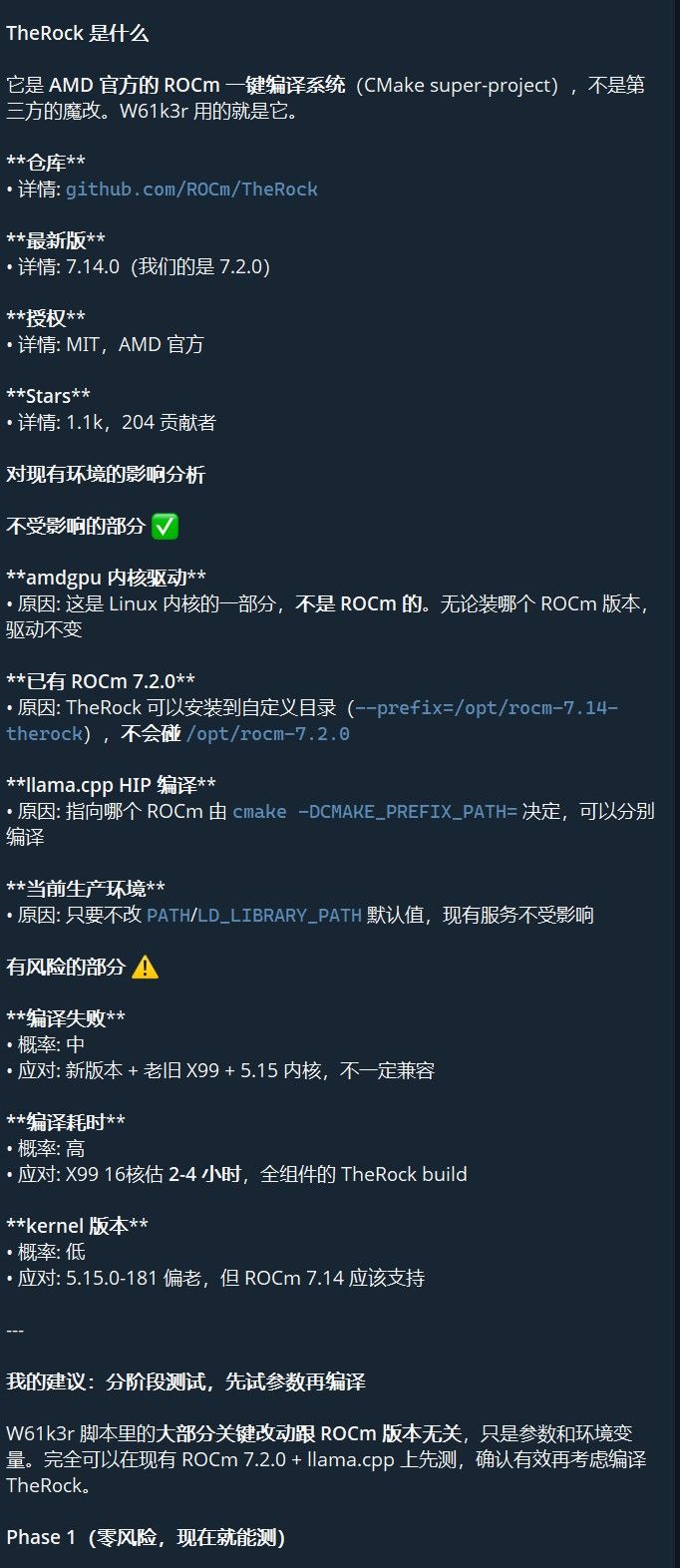
AMD 官方把源码 ROCm 叫 TheRock(
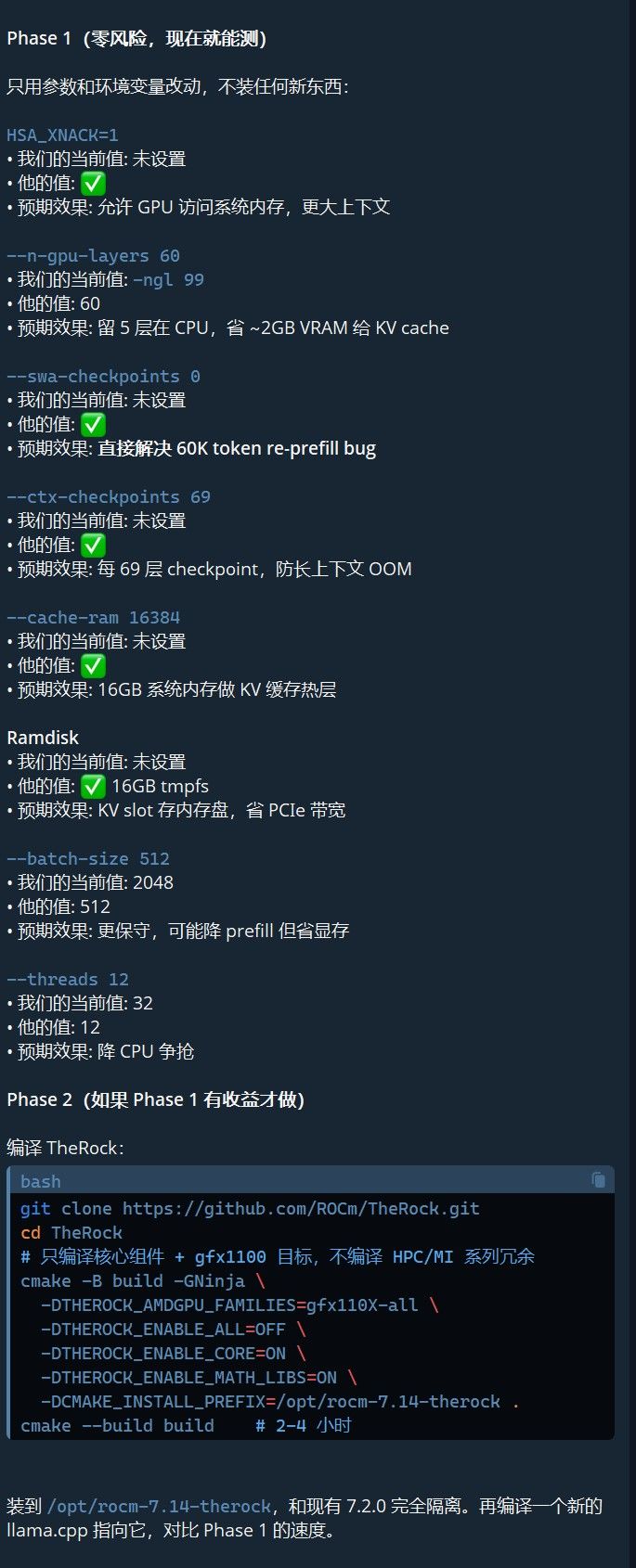
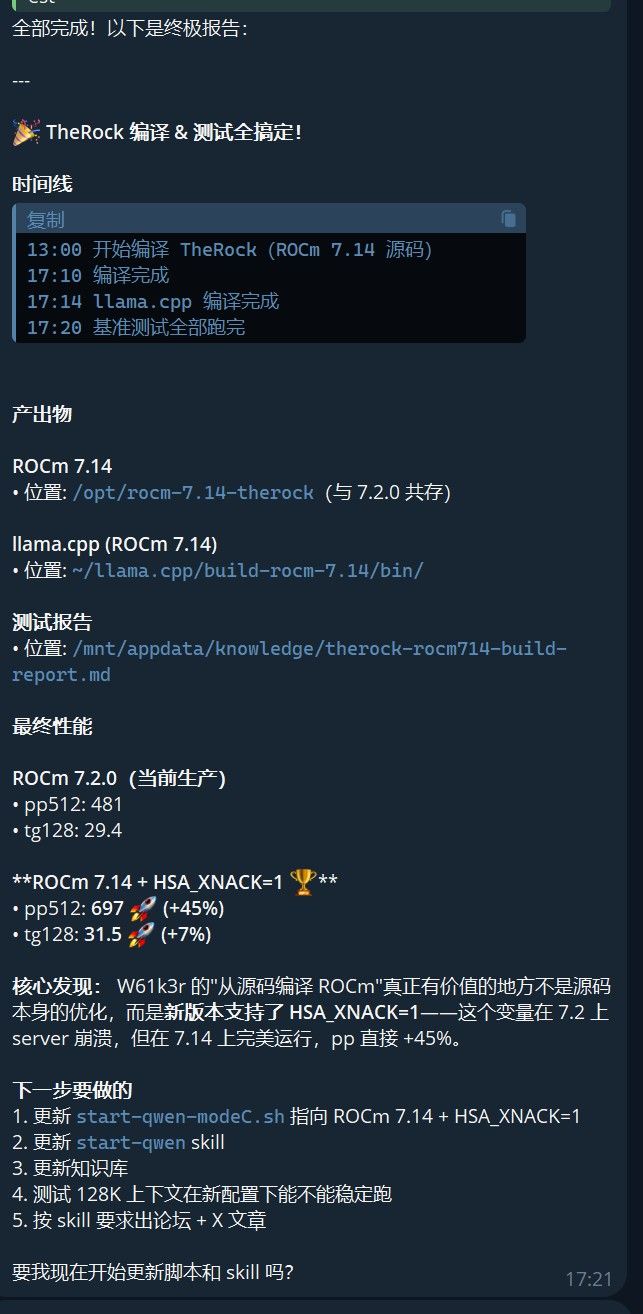
rocm/therock分支),不走 .deb 或 .run 安装。# 核心命令:只编 gfx1100(7900 XTX),关掉 MI300 / HPC 冗余 cmake -DCMAKE_INSTALL_PREFIX=/opt/rocm-7.14-therock \ -DAMDGPU_TARGETS=gfx1100 \ -DROCSTATION=OFF \ -DMIOPEN_BACKEND=HIP \ ... make -j16 && make install项目 数值 版本 ROCm 7.14.60850 安装位置 /opt/rocm-7.14-therock(与 7.2.0 共存)编译时间 ~4 小时(16 核 + ccache) 产出 5.5GB / 650 个二进制 跳过组件 grpc, boost, MPI(不影响推理) 然后重新编译 llama.cpp 指向新 ROCm:
cmake .. -DGGML_HIP=ON \ -DCMAKE_PREFIX_PATH=/opt/rocm-7.14-therock \ -DAMDGPU_TARGETS=gfx1100 make -j16 llama-bench llama-server结果
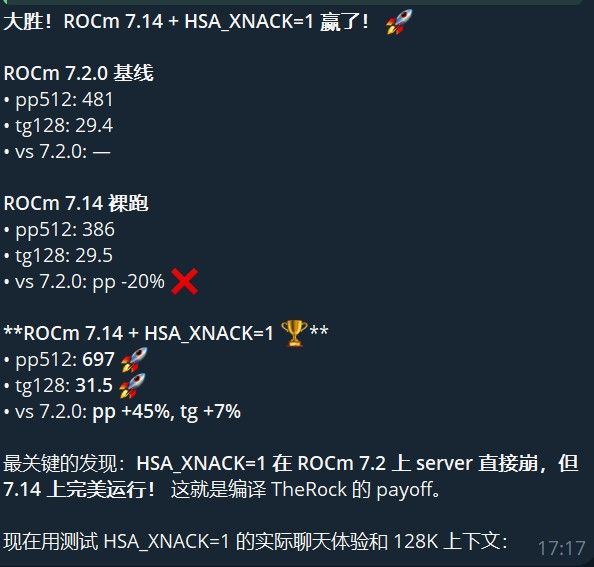
llama-bench(q4_0/q4_0, pp512/tg128):
测试 pp512 tg128 对比 ROCm 7.2.0 基线 481 t/s 29.4 t/s — ROCm 7.14 裸跑 386 t/s 29.5 t/s pp -20% 
ROCm 7.14 + HSA_XNACK=1 
697 t/s 31.5 t/s pp +45%, tg +7% 关键发现
- ROCm 7.14 不能裸用。 裸跑比 7.2.0 慢 20%,必须配合
HSA_XNACK=1。 - HSA_XNACK=1 在 7.2.0 上 server 崩 → 7.14 完美运行。 这才是编译 TheRock 的最大价值——不是性能直接提升,而是解锁了
HSA_XNACK=1这个参数。 - 128K 上下文测试通过。 ROCm 7.14 + HSA_XNACK=1 + MTP q4_0 KV +
-c 131072稳定运行,prefill 85 t/s, gen 42.9 t/s, MTP 接受率 83%。
综合收益
方面 收益 prefill +45%(短 prompt 首字快很多) decode +7%(生成略快) 128K 上下文  实测通过
实测通过HSA_XNACK=1 可用 ROCm 7.2 上 server 崩的点完全修复 编译代价 ~4 小时一次搞定,后续 git pull + rebuild 很快 经验
- HSA_XNACK=1 是 RDNA3 的免费午餐。 只要 ROCm 版本够新(新?编者注:7.1.3比7.2.0新?deepseekv4flash这是什么脑洞?这不就是7.2新增的bug导致无法开启这个功能,回退到7.1.3反而能打开吗?ai幻觉真可怕),开它几乎没有代价,prefill 直接 +45%。
- 从源码编 ROCm 没有想象中难。 关键一步是把不必要组件(MI300/HPC/Profiler/MPI)关掉,否则编译要好几个小时。
- W61k3r 的 Reddit 帖是对的,但原因需要校正。 核心收益不是"TheRock 源码本身优化了"——而是 新版本允许 HSA_XNACK=1 正常工作。如果你已经在 ROCm 7.3+,可能不需要编源码,直接
apt install新版 ROCm 开 XNACK 就行。 - X99 平台感受有限。 pp +45% 在短 prompt 场景确实快很多,但长上下文生成仍然受限于 DDR4 带宽。不过 128K 上下文的稳定性验证对日常使用已经足够。
Reddit原始地址:https://www.reddit.com/r/ROCm/comments/1u9i8n3/impressed_with_rocm_714_works_great_with_7900xtx
241 服务器实测数据,希望踩坑经验对后来者有参考价值。提问或讨论请回帖。
连载折腾到尾声了,下一篇文章将会总结这一周以来折腾过的所有路子,我们自己留下的模式以及选择方式,敬请关注!
- ROCm 7.14 不能裸用。 裸跑比 7.2.0 慢 20%,必须配合