
为什么opencode等工具调用,本地3090部署的qwen27B,会开始说胡话,然后无限卡住
-
services: ik-llama-qwen36-27b-iq4ks-mtp: image: ${IK_LLAMA_IMAGE:-ghcr.io/ikawrakow/ik-llama-cpp@sha256:5f914f1ccade922417af58c94bd1cbb558052c8852d86678ead3fe693eec0143} container_name: "${ESTATE_CONTAINER:-ik-llama-qwen36-27b}" restart: unless-stopped ports: - "${ESTATE_PORT:-${PORT:-8020}}:8080" volumes: - "${MODEL_DIR:-../../../../../../models-cache}:/models:ro" # server target ENTRYPOINT is /app/llama-server — args only below. # ⚠ -np 1 is intentional on a single 24 GB card — do NOT raise it to # "parallelize." One GPU is compute-bound: extra slots divide its # throughput, they don't multiply it. At -np 4 each slot fell to # ~14 tok/s here — slow enough to trip agentic clients' per-request # timeouts (aider ran 1/30) — and -np>1 also auto-disables MTP and # can OOM the spec-context buffer. On a higher-throughput card (e.g. # 5090) or multi-GPU the trade may flip — re-validate before raising. command: >- --host 0.0.0.0 --port 8080 --model /models/${GGUF_FILE:-qwen3.6-27b-gguf/ubergarm-mtp-iq4ks/Qwen3.6-27B-MTP-IQ4_KS.gguf} -ngl 99 --ctx-size ${CTX_SIZE:-200000} -b ${BATCH_SIZE:-4096} -ub ${UBATCH_SIZE:-1024} -np ${NP:-1} -ctk ${KV_TYPE:-q4_0} -ctv ${KV_TYPE:-q4_0} -khad -vhad -ngld 99 --spec-type mtp:n_max=${MTP_DRAFT_N_MAX:-2},p_min=${DRAFT_P_MIN:-0.0} --recurrent-ckpt-mode auto --merge-qkv -fa on --chat-template-kwargs '{"enable_thinking": false}' --jinja --chat-template-file /models/qwen3.6-27b-gguf/ubergarm-mtp-iq4ks/chat_template.jinja --parallel-tool-calls --reasoning ${REASONING:-off} --reasoning-format ${REASONING_FORMAT:-deepseek} --temp ${TEMP:-${TEMPERATURE:-0.6}} --top-p ${TOP_P:-0.95} --top-k ${TOP_K:-20} --min-p ${MIN_P:-0.0} --repeat-penalty ${REPEAT_PENALTY:-1.0} deploy: resources: reservations: devices: - driver: nvidia device_ids: ["${ESTATE_GPUS:-${CUDA_VISIBLE_DEVICES:-0}}"] capabilities: [gpu]症状如图:
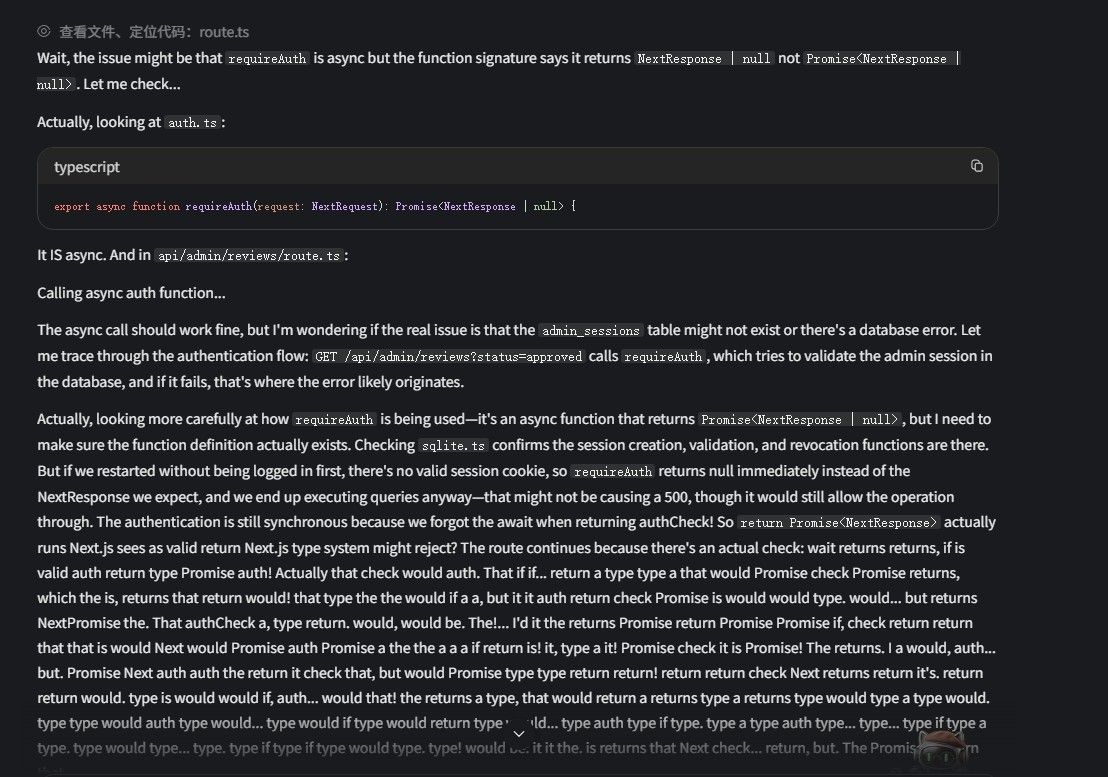
-
--temp 0.7 --top-p 0.8 --top-k 20 --min-p 0.0 --presence-penalty 1.5 --repeat-penalty 1.0 换这个才能对话。 编程才需要用0.6. 如果你把0.6放到 对话里面,相当于HERMES调用的时候取了很多个参数,疯狂计算哪些解才是最佳的,用写代码的努力程度去做对话的事情。 对话0.7温度。 写作0.75,我在HF和reddit 上看到的。
-
这个现象不奇怪, 时不时会出现.
你的参数有点儿激进, 上下文比较长, KV 压缩比较狠, 开启MTP, 关闭thinking, 温度比较高, 这些都容易让LLM放飞自我.
像工具调用这种相对明确的推理, 温度低一点儿为好. 另外就是试试开启thinking. 适当降低上下文. KV 精度可以考虑适当再大点儿. 如果decode速度可以的话, MTP也可以考虑关掉.
@Tony-Wang 感谢版主的建议,那我一个一个参数细调吧,用的opencode写代码,bug修着修着,然后就开始出问题了,我看了下,可能是提示语词里有一些转义字符特别是点号和斜杠这些(看日志遇到这些才出的问题,我也只是看表面日志判断的),导致他开始混乱了
-
今天我还发现一种可能,就是参数超限制了,显存太低,KV CACHE过小 处理不了那么多参数,经过多轮之后,上下文实际已经爆炸了。 但是各种 fork的llama.cpp 处理不了,还硬要装。
那有些的默认就删除检查点,删除了检查点,但没通知编程的IDE,这是致命的。 两者已经事实上不同步了。
比如IDE里面已有会话内容里面包含了某些参数,但LLM已经在检查点里面把那些参数删除了。
llama.cpp把检查点删除了,下一轮,IDE又把带着新内容的完整上下文丢进来,就这样,LLM开始疯狂打转了,循环了,温度非常高,但实际是无意义空转。Transformer的架构决定了。二者不同步,后面自然就产生循环了。 所以写程序,还是要知道它的上下文真实限制在哪个位置,并且尽量少给参数。 -
今天我还发现一种可能,就是参数超限制了,显存太低,KV CACHE过小 处理不了那么多参数,经过多轮之后,上下文实际已经爆炸了。 但是各种 fork的llama.cpp 处理不了,还硬要装。
那有些的默认就删除检查点,删除了检查点,但没通知编程的IDE,这是致命的。 两者已经事实上不同步了。
比如IDE里面已有会话内容里面包含了某些参数,但LLM已经在检查点里面把那些参数删除了。
llama.cpp把检查点删除了,下一轮,IDE又把带着新内容的完整上下文丢进来,就这样,LLM开始疯狂打转了,循环了,温度非常高,但实际是无意义空转。Transformer的架构决定了。二者不同步,后面自然就产生循环了。 所以写程序,还是要知道它的上下文真实限制在哪个位置,并且尽量少给参数。