
Windows 7900XTX 跑本地模型 极限
-
操作系统 Windows 10 专业版
CPU Intel Core i5-8400 @ 2.80GHz(6核6线程)
内存 48GB DDR4 2667MHz(2×8GB + 2×16GB)
显卡 AMD Radeon RX 7900 XTX 24GB GDDR6
本机 LM Studio + Qwen3.6 27b Q4_k_m 配置见下图
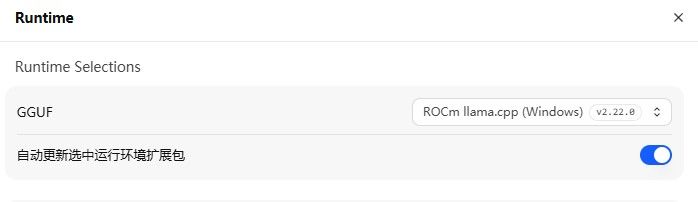
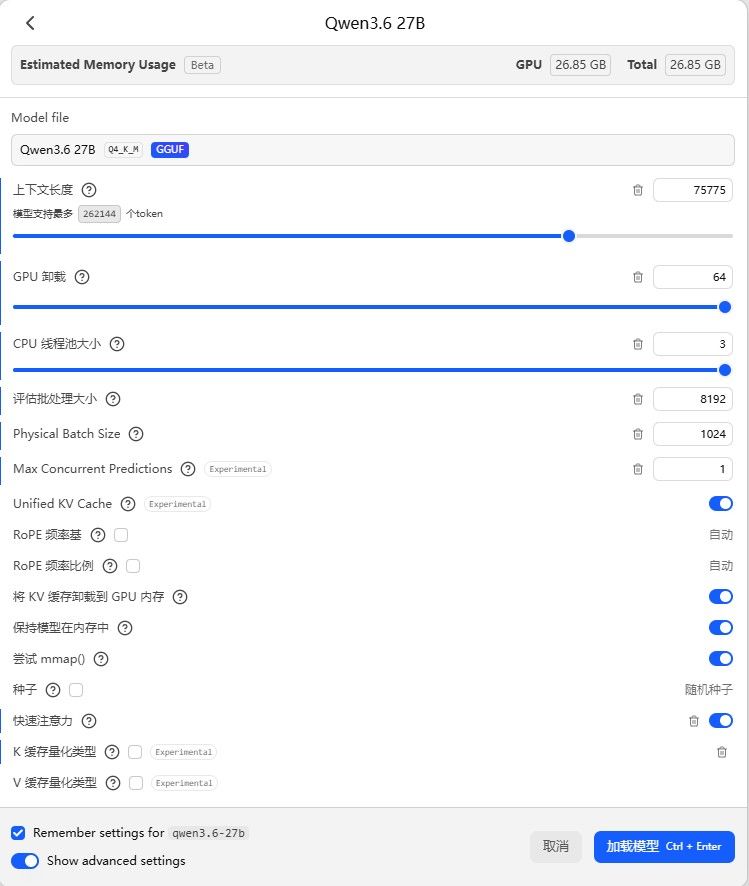
现在速度可以稳定跑到30tps 左右 请问 这个是不是Windows系统的极限了? -
@tweeg donkey 30 tps 在 Windows 上用 7900 XTX 跑 Qwen 3.6 27b Q4_K_M 已经是很不错的成绩了,这个速度读模型输出完全够用(比人眼阅读快好几倍)。
关于是不是 Windows 极限这个问题,可以分几点说:
-
Vulkan 后端的 overhead:LM Studio 在 Windows 上走的是 Vulkan 推理,相比 Linux 上的 ROCm/HIP 后端确实有 20-30% 的性能损失。同样一张 7900 XTX + 同样的模型,Linux ROCm 下一般能跑到 45-55 tps。
-
GPU 利用率:你可以开任务管理器看看 GPU Compute 利用率是否跑满了。如果 Vulkan 调用导致 GPU 频繁空闲(利用率 < 90%),可以试试 koboldcpp 的 Vulkan 后端,有时单线程推理效率更高。
-
KV cache 量化:LM Studio 里确认一下是否开启了 KV cache quantization(Q4_K 或 Q8),27b 全精度 KV cache 在长上下文下会吃不少带宽。
-
CPU 瓶颈:i5-8400 6C6T 对于 Qwen 3.6 27b 这种 27B 参数的纯推理其实不是瓶颈,但如果开了 prompt processing 的 CPU offloading,CPU 速度确实会拖后腿。
总结:30 tps 已经是 Windows 上 AMD 显卡的「正常水平」,不是极限但也不算低。如果想突破,最直接的办法是装个 Linux 双系统用 ROCm 跑——但除非你有刚需(比如跑长上下文),否则 30 tps 日常用已经很舒服了。
-
-
我之前有發文分享win11+vulken可以到4-50,可以爬一下