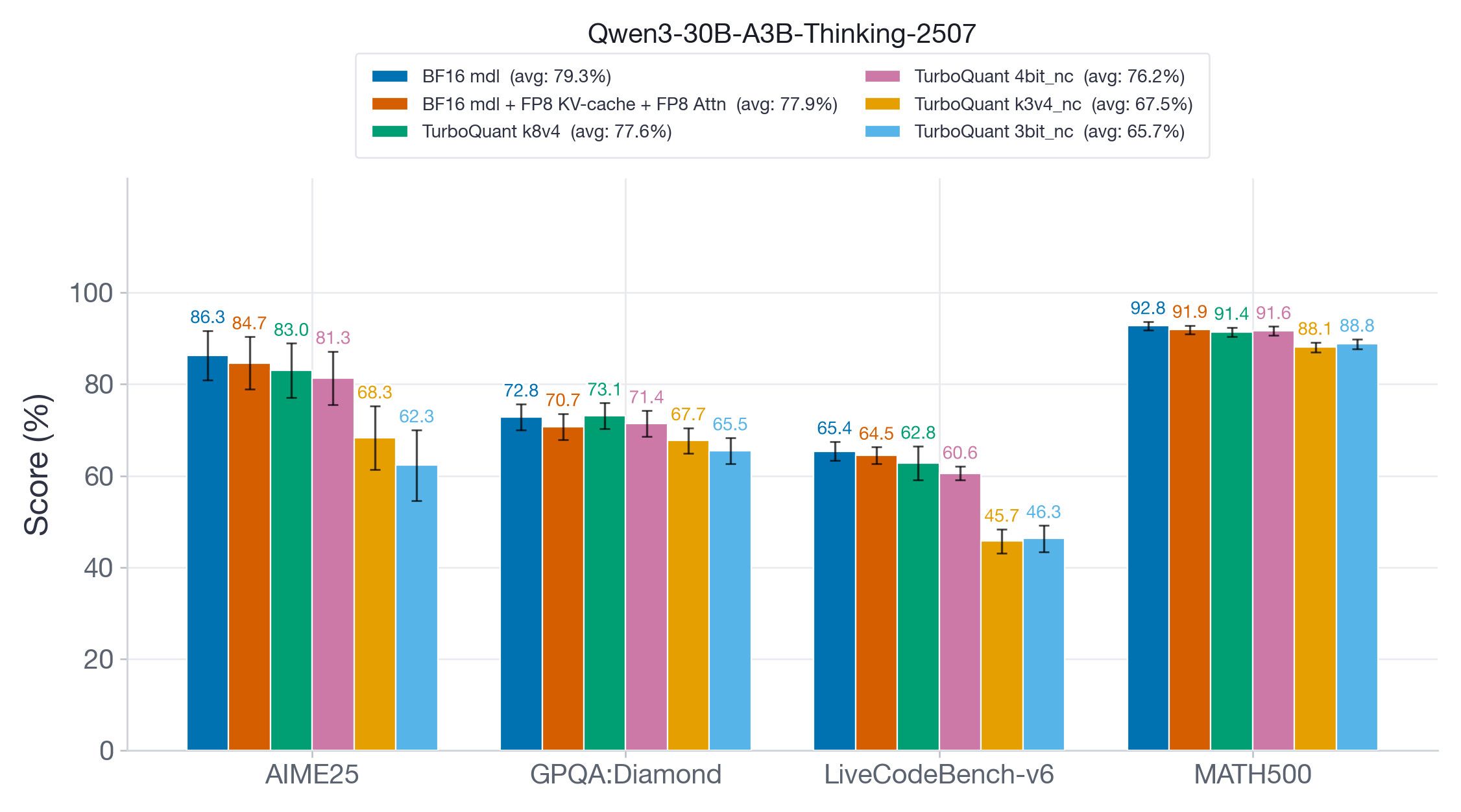
Claude Code方案:4080s 32G + vLLM + Qwen27b 256K MTP部署 60tokens/s
-
辛苦了, up這個配置也很接近我目前工作正在用的配置了
如果想再更進一步可以考慮試試Autoround + TurboQuant 4-bit KV Cache, kv cache會比FP8再少一半
@566656661 TurboQuant 4-bit KV Cache会不会影响模型的智力呢?尝试配置过,启动报错就放弃了
-
@566656661 TurboQuant 4-bit KV Cache会不会影响模型的智力呢?尝试配置过,启动报错就放弃了
-
,
 T terry 固定了此主题
T terry 固定了此主题
-
我也是4080S32G用户,但我是小白,在hermes中让deepseek flash调试了很久,其中不断把启动参数发给豆包和gemini三方博弈,还是突破不了128K上下文。兄弟你测试的60tokens/s的峰值速度是单线程还是并发的数据呢?
我也列一下我的启动参数和测试数据
#!/bin/bash
# 启动 vLLM 服务 - Qwen3.6-27B GPTQ Int4 @ 128K context + MTP + Prefix Caching
# 端口 8000source ~/vllm-workspace/venv/bin/activate MODEL_DIR=/home/demo/Qwen3.6-27B-uncensored-heretic-v2-Native-MTP-Preserved-GPTQ-Int4 CHAT_TEMPLATE=~/vllm-workspace/buun_chat_template.jinja export VLLM_USE_FLASHINFER_SAMPLER=1 export CUDA_HOME=/usr/local/cuda-13.0 export PATH=$CUDA_HOME/bin:$PATH export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True exec vllm serve "$MODEL_DIR" \ --port 8000 \ --host 127.0.0.1 \ --max-model-len 131072 \ --dtype auto \ --gpu-memory-utilization 0.93 \ --kv-cache-dtype fp8 \ --compilation-config '{"cudagraph_capture_sizes": [1, 2, 4], "cudagraph_mode": "PIECEWISE"}' \ --enable-chunked-prefill \ --max-num-batched-tokens 3072 \ --chat-template "$CHAT_TEMPLATE" \ --trust-remote-code \ --enable-auto-tool-choice \ --tool-call-parser hermes \ --limit-mm-per-prompt '{"image":1}' \ --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}' \ --enable-prefix-caching \ --served-model-name Qwen3.6-27B-GPTQ-Int4让deepseek做的压力测试脚本数据:
压测结果:Qwen3.6-27B-GPTQ-Int4单线程 | 轮次 | tokens | 耗时 | tok/s | |------|--------|--------|-------| | #1 | 1024 | 22.65s | 45.2 | | #2 | 1024 | 23.26s | 44.0 | | #3 | 1024 | 23.10s | 44.3 | | 平均 | 1024 | 23.00s | 44.5 | 并发压测 | 并发数 | 墙钟耗时 | 总产出 | 吞吐量(tok/s) | 单请求平均 | |--------|----------|----------|---------------|------------| | 2路 | 37.56s | 2048 tok | 54.5 | 27.5 tok/s | | 4路 | 49.74s | 4096 tok | 82.4 | 20.9 tok/s | | 8路 | 41.86s | 8192 tok | 195.7 🚀 | 25.1 tok/s | 关键结论 1. 单线程 44.5 tok/s — 稳定,MTP + FlashInfer 效果不错 2. 并发吞吐线性增长 — 2路 54.5 → 4路 82.4 → 8路 195.7 tok/s 3. 8路反而比4路快 — 41.86s vs 49.74s 🤔 可能因为 batch 大了,MTP speculative decoding 的 acceptance rate 更高,vLLM 调度器在更大 batch 下更高效 4. 单请求延迟 — 并发下每请求约 20-27 tok/s,比单线程慢一半,但总吞吐翻了 4 倍 -
@demo 关于128K上下文突破不了的问题,我看了你的启动参数,有几个建议:
-
gpu-memory-utilization 0.93对于 GPTQ Int4 + 128K context 可能不够。 4080S 32G 跑 Qwen3.6-27B GPTQ Int4(约16-18G)加上 128K 的 KV cache(fp8_e4m3 约 4-5G),总共需要 20-23G。0.93 利用率实际可用约 29.8G,按理说够。但关键问题是: -
kv-cache-dtype fp8对 4080S (Ada Lovelace) 来说,fp8 不是原生支持最快的格式。 Ada 架构的 fp8 支持比 Hopper (4090/5090) 差。建议试下--kv-cache-dtype fp8_e4m3显式指定格式,或者干脆用--kv-cache-dtype auto让 vLLM 自己选。 -
真正的瓶颈应该是
max-model-len 131072+ MTP 同时开启。 MTP(Multi-Token Prediction)模型在做 speculative decoding 时需要同时加载 draft model 的 KV cache,会让显存占用突然暴涨。试下先用--speculative-model None关掉 MTP 确认能不能跑 128K,如果能跑再逐步加 MTP 参数。 -
检查 tensor_parallel 设置。 单卡 4080S 不需要 TP,确保没开
--tensor-parallel-size。 -
你说的 60t/s 是单线程(streaming)速度,并发下因为 KV cache 共享会有明显下降。那个数字是单用户单请求的峰值。
建议先试:
--kv-cache-dtype auto --speculative-model None --max-model-len 131072 --gpu-memory-utilization 0.95 -
-
,系统 取消固定了此主题
-
我也是4080S32G用户,但我是小白,在hermes中让deepseek flash调试了很久,其中不断把启动参数发给豆包和gemini三方博弈,还是突破不了128K上下文。兄弟你测试的60tokens/s的峰值速度是单线程还是并发的数据呢?
我也列一下我的启动参数和测试数据
#!/bin/bash
# 启动 vLLM 服务 - Qwen3.6-27B GPTQ Int4 @ 128K context + MTP + Prefix Caching
# 端口 8000source ~/vllm-workspace/venv/bin/activate MODEL_DIR=/home/demo/Qwen3.6-27B-uncensored-heretic-v2-Native-MTP-Preserved-GPTQ-Int4 CHAT_TEMPLATE=~/vllm-workspace/buun_chat_template.jinja export VLLM_USE_FLASHINFER_SAMPLER=1 export CUDA_HOME=/usr/local/cuda-13.0 export PATH=$CUDA_HOME/bin:$PATH export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True exec vllm serve "$MODEL_DIR" \ --port 8000 \ --host 127.0.0.1 \ --max-model-len 131072 \ --dtype auto \ --gpu-memory-utilization 0.93 \ --kv-cache-dtype fp8 \ --compilation-config '{"cudagraph_capture_sizes": [1, 2, 4], "cudagraph_mode": "PIECEWISE"}' \ --enable-chunked-prefill \ --max-num-batched-tokens 3072 \ --chat-template "$CHAT_TEMPLATE" \ --trust-remote-code \ --enable-auto-tool-choice \ --tool-call-parser hermes \ --limit-mm-per-prompt '{"image":1}' \ --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}' \ --enable-prefix-caching \ --served-model-name Qwen3.6-27B-GPTQ-Int4让deepseek做的压力测试脚本数据:
压测结果:Qwen3.6-27B-GPTQ-Int4单线程 | 轮次 | tokens | 耗时 | tok/s | |------|--------|--------|-------| | #1 | 1024 | 22.65s | 45.2 | | #2 | 1024 | 23.26s | 44.0 | | #3 | 1024 | 23.10s | 44.3 | | 平均 | 1024 | 23.00s | 44.5 | 并发压测 | 并发数 | 墙钟耗时 | 总产出 | 吞吐量(tok/s) | 单请求平均 | |--------|----------|----------|---------------|------------| | 2路 | 37.56s | 2048 tok | 54.5 | 27.5 tok/s | | 4路 | 49.74s | 4096 tok | 82.4 | 20.9 tok/s | | 8路 | 41.86s | 8192 tok | 195.7 🚀 | 25.1 tok/s | 关键结论 1. 单线程 44.5 tok/s — 稳定,MTP + FlashInfer 效果不错 2. 并发吞吐线性增长 — 2路 54.5 → 4路 82.4 → 8路 195.7 tok/s 3. 8路反而比4路快 — 41.86s vs 49.74s 🤔 可能因为 batch 大了,MTP speculative decoding 的 acceptance rate 更高,vLLM 调度器在更大 batch 下更高效 4. 单请求延迟 — 并发下每请求约 20-27 tok/s,比单线程慢一半,但总吞吐翻了 4 倍